
Hyperscale Java Platform: From Federated GraphQL to JVM Defaults#
Netflix’s streaming business splits “discovering content” from “playing content” into two technical paths: the former uses federated GraphQL as the outward data plane; the latter goes through dedicated stacks such as Open Connect (speaker opinion—not expanded in this article). What is more useful as a reference for Java engineers is the former—thousands of Spring Boot services, the open-source DGS framework, and the practice of making GC, virtual threads, and framework upgrades platform defaults rather than something each team figures out on its own.
This article does not recap the conference agenda. Instead it unpacks decisions you can transplant: how protocols divide responsibility, how the platform converges behavior on Boot, how testing and migration control context size, how the JVM links tail latency with call timeouts, and how Gen AI embeds into existing Spring services without handing off orchestration. Items marked speaker opinion (application scale, internal starter coordinates, Gutenberg/Hollow runtime, millisecond-level IPC configuration, and similar) cannot be reproduced in a public environment; items marked verifiable cite official documentation, JEPs, or open-source repositories.

Figure: Opening slide titled “How Netflix uses Java” with “2026 edition”.
Federated GraphQL: layering gateway, DGS, and gRPC#
Why#
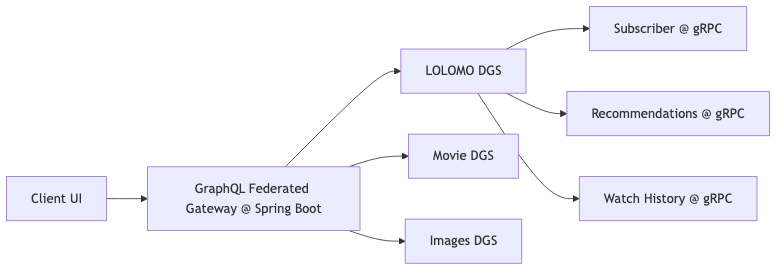
Clients need one request to assemble home-page data (Lolomo), title metadata, images, and other multi-domain fields; domain teams must still ship independently. Federated composition merges multiple subgraphs into a unified supergraph, with the gateway owning query planning and fan-out (Apollo Federation overview). Speaker opinion: Netflix uses GraphQL between the gateway and each DGS (Domain Graph Service); DGS then fans out over gRPC to subscription, recommendation, watch history, and other backends. The playback path is not on this stack.
Mechanism and constraints#
- Outward contract: GraphQL Over HTTP requires servers to accept POST; clients may negotiate
application/graphql-response+jsonandapplication/jsonviaAccept. - Domain boundaries: each DGS owns its schema fragment; federation stitches fields through mechanisms such as
_entities(representations: …)(slide example). - Service-to-service: gRPC models
.protoservice/rpc; clients may set a deadline (gRPC Core concepts).
How to (minimal example)#
POST /graphql HTTP/1.1
Content-Type: application/json
Accept: application/graphql-response+json, application/json;q=0.9
{"query":"query Home($id: ID!) { lolomo(profileId: $id) { rails { id } } }","variables":{"id":"..."}}
@DgsComponent
public class LolomoDatafetcher {
@DgsQuery
public List<Rail> lolomo(@InputArgument String profileId) {
return catalogClient.railsForProfile(profileId);
}
}
Common misconceptions#
Treating the federated gateway as a universal BFF and writing business logic in the gateway; or letting a DGS talk to too many downstreams and causing fan-out explosions. Federation’s value is schema ownership and composable query plans, not aggregating all SQL in one place. A subtler issue: when client query depth is uncontrolled, the gateway’s query plan may fetch the same entity repeatedly across subgraphs—you need to constrain N+1 in schema design and @key / @requires usage, not just scale thread pools harder.
Figure: Architecture diagram with “GraphQL Federated Gateway”, LOLOMO / Movie / Images DGS, and gRPC downstream.
Paved Road: platform capabilities on top of Spring Boot#
Why#
Speaker opinion: roughly 3,000–4,000 Java applications share open-source Spring Boot, layered with internal Spring Boot Netflix modules. If every team integrates security, dynamic configuration, observability, and gRPC clients on its own, the platform cannot upgrade uniformly and the blast radius of incidents stays fragmented.
Mechanism and constraints#
Spring Boot Starters conventionally use the spring-boot-starter-* naming pattern; third parties should use forms like thirdparty-spring-boot-starter. The platform injects behavior through auto-configuration; complex cases add EnvironmentPostProcessor and BeanFactoryPostProcessor (speaker opinion, e.g. gRPC client registration). Paved Road in the slides refers to a shared set of products, practices, and standards that providers and consumers align on.
How to (illustrative)#
dependencies {
// Internal coordinates not public; structure follows official starter pattern
implementation("com.netflix.spring:netflix-spring-boot-starter-security")
implementation("com.netflix.spring:netflix-spring-boot-starter-observability")
}
spring:
application:
name: my-service
Common misconceptions#
Copying Beans that platform starters already provide into business modules; or bypassing the paved road with unaudited HTTP/security stacks that cannot be migrated in bulk on upgrade. Platform teams also hit an anti-pattern: making “optional extension points” silently override default Beans so applications behave differently on minor upgrades—externally this should work like official starters, with conditional annotations and configuration properties that make the activation boundary explicit.

Figure: Slide “The paved road” and explanation of shared standards and engineering leverage.
Integration testing: balancing full-stack realism and startup cost#
Why#
If the path from GraphQL DataFetcher to the database is mocked only, regressions miss serialization, transaction, and authorization combinations. Speaker opinion: the mainstream approach is integration tests with @SpringBootTest, explicitly narrowing what gets loaded.
Mechanism and constraints#
classesattribute: load only listed@Configuration/ components (Javadoc).- Official test slices (e.g.
@WebMvcTest) bootstrap only a Web-layer subset. - Netflix side:
@EnableDgsTest,@EnableJooqTest(not found in public repos—treat as internal slice), Testcontainers for external dependencies (speaker opinion).
@SpringBootTest(classes = {IncidentsDatafetcher.class, JooqRepository.class})
@EnableDgsTest
@EnableJooqTest
class IncidentsDatafetcherTest {
@Autowired DgsQueryExecutor queryExecutor;
}
Common misconceptions#
Using @SpringBootTest on every case without classes, so full-context caching stays slow; or asserting security-filter behavior in slice tests that never loaded those filters.

Figure: “Testing with Spring Boot”—@SpringBootTest(classes=…) and @EnableDgsTest example.
Boot 2→3: Jakarta rewrite at dependency resolution time#
Why#
Spring Boot 3.0 moves to Jakarta EE (e.g. Servlet 6.0). The ecosystem still has legacy JARs with only javax.*, creating a “libraries wait for apps, apps wait for libraries” deadlock.
Mechanism and constraints#
Gradle Artifact Transforms rewrite artifacts at the end of dependency resolution. Netflix’s open-source Nebula Jakarta EE Migration Plugin (plugin ID: com.netflix.nebula.jakartaee-migration, verifiable) migrates package names on legacy JARs during resolution, using tomcat-jakartaee-migration underneath. Source and build scripts use OpenRewrite UpgradeSpringBoot_3_0. Speaker opinion: migration to Boot 3 took roughly two years and is largely complete org-wide; slides state “Fully on Spring Boot 3 now”.
plugins {
id("com.netflix.nebula.jakartaee-migration") version "2.0.1" // confirm version on Portal
}
Verification note: The public plugin ID is
com.netflix.nebula.jakartaee-migration, which differs from some oral references tocom.netflix.jakarta-transform. Use the Gradle Plugin Portal as the source of truth.
Common misconceptions#
Treating bytecode rewrite as “never need to change source again”; API semantic changes, build scripts, and test container images still need OpenRewrite or manual work. Transforms suit JARs where only package names change and behavior is unchanged.

Figure: “Spring Boot 2 -> 3”—Gradle transform, OpenRewrite, and “Fully on Spring Boot 3 now”.
API shapes: data, methods, and edge REST#
Why#
The same organization must serve clients that need flexible data fetching and service-to-service calls with fixed contracts and low latency. One protocol for everything forces excessive compromise on one side.
Mechanism and constraints (speaker opinion + public technical comparison)#
| Scenario | Choice | Mental model |
|---|---|---|
| Outward / BFF-like | Federated GraphQL + DGS | Think in data |
| Service-to-service RPC | gRPC | Think methods |
| Minimal, short-lived exposure | REST | Slides use a tombstone—“REST IN PEACE”—organizational policy, not a normative conclusion |
service Catalog {
rpc GetShow(GetShowRequest) returns (Show);
}
Common misconceptions#
Wrapping gRPC services in GraphQL “for easier debugging” without schema governance; or using REST for long-lived domain APIs that fragment into version sprawl.

Figure: “DGS - GraphQL” contrasting GraphQL and gRPC mental models; REST marked as deprecated direction (speaker opinion).
DGS and Spring for GraphQL: one execution pipeline#
Why#
Maintaining two GraphQL execution stacks increases migration cost and test divergence. DGS documentation states internal integration with Spring for GraphQL: query execution is handled by ExecutionGraphQLService, with DgsQueryExecutor as a delegate (DGS Spring GraphQL Integration).
Mechanism and constraints#
- Production:
@DgsQuery,@InputArgument, and related annotations remain available (verifiable + slide OCR). - Testing:
@EnableDgsTest+DgsQueryExecutor, withexecuteAndExtractJsonPath(Query Execution Testing). Speaker opinion: sub-second feedback without a full Boot startup.
@DgsQuery
public List<Show> search(@InputArgument SearchFilter filter) {
return showsRepository.allShows().stream()
.filter(s -> s.getTitle().toLowerCase()
.startsWith(filter.getTitle().toLowerCase()))
.toList();
}
@SpringBootTest(classes = {LolomoDatafetcher.class, ShowsRepository.class, ArtworkService.class})
@EnableDgsTest
class LolomoDatafetcherTest {
@Autowired DgsQueryExecutor dgsQueryExecutor;
}
Common misconceptions#
Mixing Spring GraphQL and DGS programming models (official docs explicitly discourage this); or loading the full application in @EnableDgsTest while claiming “lightweight tests”.
Figure: Slide “Now fully integrated with Spring for GraphQL” with @EnableDgsTest / DgsQueryExecutor code.
JDK baseline and Generational ZGC#
Why#
Speaker opinion: company minimum JDK 17; most services run 21 or 25 (exact mix not public). On large heaps with very short IPC timeouts, G1 can produce ~1.5s STW pauses that trigger timeouts, retries, and cluster load amplification; switching to Generational ZGC materially reduced pauses and IPC client errors, and it is now the default GC policy (speaker opinion; aligned with OpenJDK defaultization below).
Mechanism and constraints (verifiable)#
- JEP 439 (JDK 21):
-XX:+UseZGC -XX:+ZGenerational. - JEP 474 (JDK 23): Generational ZGC is the default ZGC mode.
- JEP 490 (JDK 24): non-generational ZGC removed.
# JDK 21
java -XX:+UseZGC -XX:+ZGenerational -jar app.jar
# JDK 23+ generational is default with -XX:+UseZGC only (see JEP 474)
java -XX:+UseZGC -jar app.jar
Cannot verify: millisecond-level IPC settings on slides; whether Netflix defaults ZGC everywhere. JEP 439 notes G1 pauses can range from milliseconds to seconds when comparing to G1—that is consistent with a “tail-latency-sensitive + short timeout” narrative, but does not replace causal proof from Netflix internal monitoring curves.
Common misconceptions#
Looking only at average pause while ignoring P99; or changing GC alone without adjusting timeout and retry policy, then blaming retry storms on “unstable downstream.” After moving to ZGC, CPU usage and allocation rate may shift—capacity planning should regress heap size and flags such as -XX:SoftMaxHeapSize together, not only pause curves.

Figure: “Generational ZGC: The new default”—G1 ~1.5s pause linked to IPC timeouts and retries (speaker opinion).
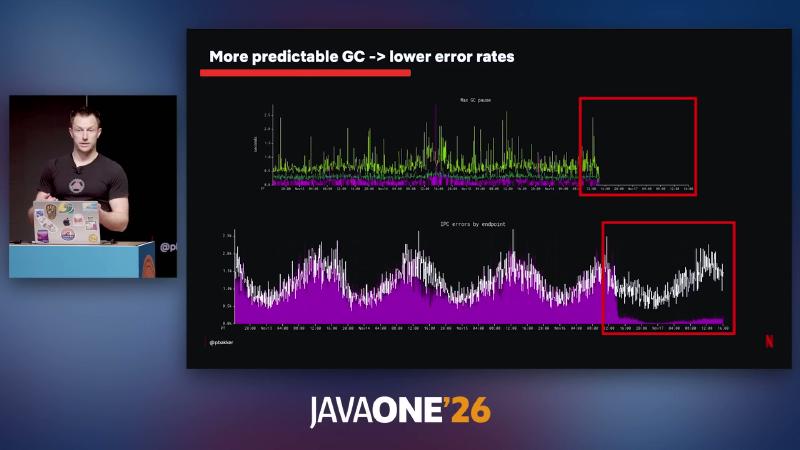
Figure: “More predictable GC -> lower error rates”—time series of max GC pause and IPC errors by endpoint.
Virtual threads: framework switches and pinning rollback#
Why#
When blocking I/O dominates, platform thread pools become the bottleneck. JEP 444 Virtual Threads map many blocking calls onto lightweight threads. Speaker opinion: an earlier rollout caused production deadlocks from thread pinning on older JDKs and was rolled back at scale; after fixes, enabling moved to the framework layer—Tomcat, Spring default executors, DGS DataFetchers—with zero business-code changes (no post-rollout quantitative performance data yet).
Mechanism and constraints#
- Spring Boot 3.2+:
spring.threads.virtual.enabled=true(DGS Virtual Threads). - DGS:
dgs.graphql.virtualthreads.enabled=trueruns user DataFetchers on new virtual threads. - Pinning: JEP 491 ships in JDK 24, reducing pinning from
synchronized(verifiable). Slides say “JDK 25”—inconsistent with JEP 491’s Release field; follow your target JDK release notes for rollout.
Common misconceptions#
Enabling virtual threads fleet-wide on JDKs where pinning is not yet mitigated; or ignoring DGS documentation warnings about ThreadLocal (tracing, MDC, security context).

Figure: “Virtual Threads (JDK 25)”—Tomcat connectors, @DefaultExecutor, DGS data fetchers, and “Needs context propagation!”.
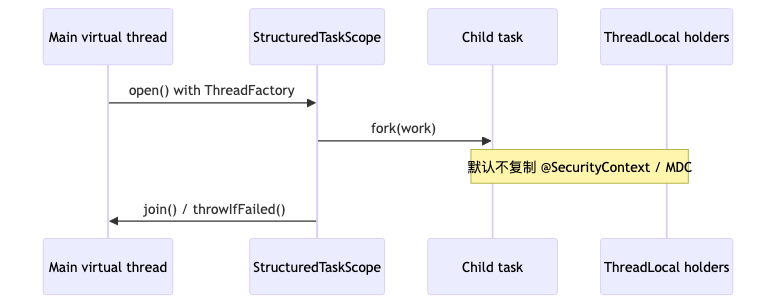
Structured concurrency and context propagation#
Why#
Above virtual threads, parallel StructuredTaskScope forks do not by default copy ThreadLocal-backed context such as Spring Security and Micrometer (speaker opinion). Code looks correct while auth and tracing disappear in child tasks.
Mechanism and constraints#
- JEP 505 (JDK 25 preview): APIs such as
StructuredTaskScope.open()require--enable-preview. - JDK API supports
Configuration.withThreadFactory(ThreadFactory); Scoped Values are ideal but hard to migrate for existing frameworks (speaker opinion). - Practical direction: Micrometer Context Propagation
ThreadLocalAccessorand similar, copied in a customThreadFactory(engineering direction verifiable; Netflix implementation not public).
// JEP 505 style example; inheritContext is speaker pseudocode, not a standard JDK API
try (var scope = StructuredTaskScope.open(
StructuredTaskScope.Configuration.newBuilder()
.withThreadFactory(ctxAwareFactory)
.build())) {
scope.fork(() -> downstreamClient.call());
scope.join();
}
Common misconceptions#
Treating fork like ordinary ExecutorService.submit without failure propagation; or assuming Scoped Values automatically replace all ThreadLocal libraries.
Production-embedded Gen AI: controlled agentic workflows#
Why#
“Using AI to write code” and “production Java services calling LLMs” are different problems. The latter needs auditable, rate-limited orchestration with predictable steps (speaker opinion). Slide Agentic Workflows stresses: engineers keep control of the workflow; the LLM participates only in some steps, preserving determinism and control while introducing AI (compare Anthropic — Building effective agents).
Mechanism and constraints#
Spring AI provides ChatClient, Tool Calling, Model Context Protocol (MCP), and related building blocks; “agentic workflow” is not a Spring AI-defined term.
@RestController
class OpsAiController {
private final ChatClient chatClient;
@PostMapping("/internal/ai/summarize")
String summarize(@RequestBody Incident incident) {
return chatClient.prompt()
.user("Summarize mitigations for: " + incident)
.call().content();
}
}
Common misconceptions#
Connecting a coding agent directly to production write paths; or exposing tool calls without permission boundaries and timeouts, spreading LLM uncertainty into the data plane.

Figure: “Agentic Workflows”—“You keep control of the workflow” and “Adding AI while keeping control and determinism”.
Startup profiling: from slow Beans to actionable remediation#
Why#
When Spring startup is slow, listing slow Beans alone is often not actionable for third-party libraries. Speaker opinion: an internal startup analysis service layers agentic workflows on profiling data, combining library source to suggest “problem class / Maven coordinates / should this be async,” implemented on Spring + Spring AI.
Mechanism and constraints (speaker opinion + slide OCR)#
Console UI (OCR shows com.netflix.gusto.Gusto; product name not confirmed orally) displays Startup Analysis Report and Top Recurring Bean Bottlenecks (Application Starts). Typical entries:
evoMetadataCachedClient— Evolution Metadata Client;gutenbergSubscriber.startSubscriber()runs synchronously in the constructor (speaker opinion: connects to Gutenberg for metadata).AssetArrivalDatesClientImpl— blocks on Netflix Hollow / Cinder consumerbuildAsync().join()to load and index.
Hollow is publicly positioned as high-performance read-only in-memory dataset propagation (com.netflix.hollow:hollow). Typical duration 12s–58s (speaker opinion; higher as outliers).
@Bean
@Lazy
EvoMetadataCachedClient evoMetadataClient(EvoMetadataProperties p) {
return new EvoMetadataCachedClient(p); // avoid constructor sync full fetch
}
Common misconceptions#
Applying @Lazy to every slow Bean without fixing synchronous initialization inside libraries; or conflating startup profiling with runtime hot paths.
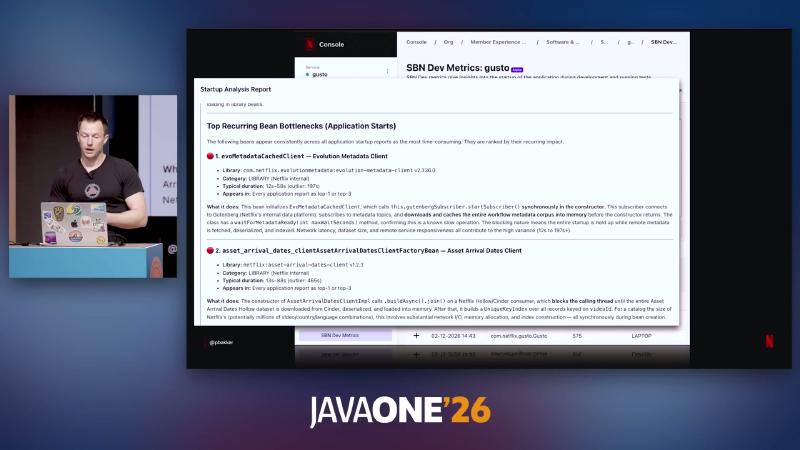
Figure: “Top Recurring Bean Bottlenecks (Application Starts)”—rank #1 evoMetadataCachedClient — Evolution Metadata Client.
Boot 4 and platform-side upgrade orchestration (scope note)#
Speaker opinion: the next hop to Spring Boot 4 is planned as a platform-driven headless run of Claude Code, with a custom workflow engine (multi-segment prompts, independent subagent per step, checkpointing to preserve git and conversation state). Claude Code CLI -p (print / non-interactive) and Checkpointing support the “non-interactive” concept but do not equal Netflix internal implementations such as netflix-upgrade-runner (unverified). Slide background shows “Boot 4.0 / Spring Fra…”; details await official release notes.
Not covered: the talk only previewed Project Leyden / AOT for a colleague’s session—this article does not speculate on Netflix adoption.
References and further reading#
- GraphQL introduction
- GraphQL Over HTTP draft (POST and media types)
- Apollo Federation repository (subgraphs and gateway)
- gRPC core concepts (service/rpc/deadline)
- Netflix DGS documentation
- DGS and Spring for GraphQL integration
- Spring Boot application testing (including test slices)
- Spring Boot 3.0 release notes (Jakarta EE)
- Nebula Jakarta EE Migration Gradle plugin
- OpenRewrite: Upgrade to Spring Boot 3.0 recipe
- JEP 439: Generational ZGC
- JEP 444: Virtual Threads
- JEP 491: Pinning elimination for virtual threads (JDK 24)
- DGS: virtual threads and ThreadLocal caveats
- Spring AI reference (ChatClient / MCP)


