
How Generic Code Gets Fast on the JVM: Erasure, Profiling, and Climbing Back After the Cliff#
After type erasure at the language level, Java generics still share one bytecode body at runtime. Whether performance can approach C++ machine code that statically expands each (container, Comparator) pair depends on whether HotSpot can complete devirtualization, inlining, and constant propagation under a stable profile. This article uses median-of-three QuickSort as a yardstick to walk through the machinery between the “good days” and the megamorphic “cliff,” and explains research-oriented repair ideas such as Hidden Class cloning and forced inlining via MethodHandles. Microsecond figures and speedup multiples are labeled speaker opinion unless reproduced locally with JMH. Statements about Project Valhalla and Project Leyden are roadmap vision, not current JDK product commitments.

One bytecode body vs template expansion: where the performance problem comes from#
Why: Applications need shareable library implementations (one sort(T[], Comparator)) while still wanting throughput on hot paths close to hand-written int[] or C++ vector<int> with full static specialization. The language specification only guarantees compile-time erasure; it does not promise zero virtual calls. C++ takes the heterogeneous translation path — vector<int> and vector<float> are different types, each able to generate its own code.
Mechanism and constraints: After erasure, the JVM still profiles receiver types through bytecode such as invokeinterface and aastore. Compared with C++ templates “expanded at compile time,” specialization happens in running C2, and is constrained by profile width and inlining budgets (see TypeProfileWidth below).
How (conceptual comparison):
// Java: one generic entry point
public static <T> void sort(T[] a, Comparator<? super T> c) { /* ... */ }
// C++: each comparator can be separately instantiated (see cppreference Templates)
template<typename Cmp> void quick_sort(int* a, int n, Cmp cmp);
Common misconception: Treating “erasure” as “runtime must be slow” — what is slow is virtual calls and boxing paths when a stable monomorphic profile has not formed, not erasure itself.
Benchmark matrix: same algorithm, different data and call shapes#
Why: You must separate “same algorithm” from “representation + call shape” to explain later performance gaps of 2×–5× or larger.
Mechanism and constraints: On JDK 25 + JMH + AArch64, the speaker gave approximate anchors for sorting 1000 random int values (speaker opinion): hand-written IntQS/int[] ~10.5µs; boxed generic QS/Integer[] roughly 3× slower; reflective unified path ReflQS on flat int[] can return to ~10µs, while a saturated profile can stretch to ~70µs. C++ vector<int> with full static specialization (clang -O3) is in the same ballpark as hand-written Java primitives; if the comparator degrades to std::function, the analogy is JVM megamorphism (speaker comparison — not verified against a single normative page).
How (JMH skeleton):
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class SortBench {
@Benchmark public void intQS(int[] a) { IntQuickSort.sort(a); }
@Benchmark public void genericQS(Integer[] a) {
GenericQuickSort.sort(a, Integer::compare);
}
}
Common misconception: Comparing only “generic vs not,” while ignoring Integer[] boxing bandwidth and whether the Comparator implementation class is stable at the call site.
Reflective arrays: paving the way to unify flat and boxed#
Why: Under Project Valhalla, the same API may face multiple layouts (flat value arrays vs boxed reference arrays). The talk used ReflectiveQuickSort with Array.get / Array.set for unified access, probing how far the optimizer can go with “one algorithm, many layouts.”
Mechanism and constraints: Boxing trades a 4-byte int for a 16–24 byte object representation (pointer + header + payload) — speaker opinion; object headers and compressed pointers vary by VM. Boxing buys full polymorphism but raises footprint and array traversal bandwidth cost. Primitive arrays still mix poorly with today’s generic erasure (“yet…”).


How:
static void reflectiveSort(Object a, int lo, int hi, Comparator<?> cmp) {
Object pivot = Array.get(a, hi);
for (int i = lo; i < hi; i++)
if (cmp.compare(Array.get(a, i), pivot) < 0)
swapReflect(a, i, /* ... */);
}
Common misconception: Assuming “reflection is always an order of magnitude slower” — on flat int[], if C2 can specialize Array.get to machine code equivalent to iaload, it can still approach the hand-written version (speaker measurement; verify locally).
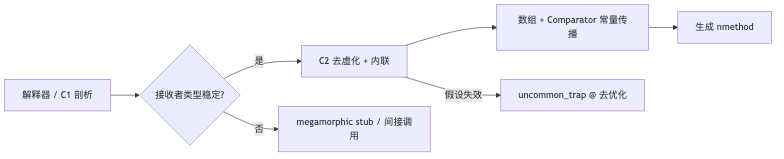
HotSpot’s JIT loop: profile → devirtualize → inline#
Why: After erasure, generic methods are still virtual at the bytecode level. To constant-fold Comparator.compare together with array element access, you usually need a credible type profile first, then inline into a single IR for register allocation and instruction selection.
Mechanism and constraints: PerformanceTechniques describes how the interpreter/C1 record receiver types at call sites (often related to TypeProfileWidth; JDK 25 default width is 2). C2 performs optimistic checks when “historically one or two types” appear; on failure it deoptimizes or takes vtable/itable paths. GraphKit::uncommon_trap comments state: bail out to the interpreter mid-flight — matching b.ne uncommon_trap in assembly. For generic sorting, array component type and Comparator receiver type are two independent profiling channels: store-check elimination on aastore/aaload and inlining of compare align in the same optimization round only when both narrow in the IR; if either channel saturates, the other may remain monomorphic yet still stall the whole loop (speaker synthesis — implementation observation, not a JLS clause).
How (favor forming a monomorphic profile):
Comparator<Integer> cmp = Integer::compare;
GenericQuickSort.sort(keys, cmp);
Common misconception: In a microbenchmark, using a fresh lambda class on every iteration while expecting stable optimization like Integer::compare — an unstable receiver class breaks the loop.
“Good days” assembly: guards outside the loop, direct compares inside#
Why: Reading generated AArch64 (or your host ISA) tells you whether performance is stuck on guards or on the hot loop body.
Mechanism and constraints: When the comparator has seen only 1–2 types in the method’s history, C2 can load cmp.class outside the loop and compare against constant metadata; failure goes to uncommon_trap; success inlines compare inside the loop as ldr/cmp on array elements (speaker assembly reading — confirm locally with PrintAssembly + hsdis).

How:
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly \
-XX:CompileCommand=print,*QuickSort* -jar bench.jar
Common misconception: Treating uncommon_trap as an “exception” — it is the normal deoptimization path when speculation fails; frequent triggers hurt throughput.
The megamorphic cliff: what happens after profile saturation#
Why: Pluggable comparators, multi-tenant shared sort kernels, or benchmarks that rotate multiple Comparator implementations make one call site see many receiver types; the optimizer loses the signal of “which one to bet on.”
Mechanism and constraints: The talk describes “≥3 comparator types” as a saturated profile; the hot loop falls back to indirect calls and heavy spill/setup (slides claim 10×+ instructions per iteration vs the benign path — speaker opinion). Versus a clean monomorphic case, slides give roughly a 2×–5× megamorphic penalty band (speaker opinion, not independently verified). The HotSpot Wiki also notes that inline caches may enter megamorphic state and use vtable/itable stubs when seeing a second receiver — “third-type saturation” in casual speech may refer to different subsystems (TypeProfileWidth vs IC state machine); when reading assembly, trust your local profile. Turning off -XX:UseTypeProfile makes C2 rely more on other paths for type information; the talk used it to show that “caller-side constant propagation” can partly replace profiling, but the flag is on by default and should not be disabled casually in production.


How (deliberately manufacturing saturation in experiments — not production style):
Comparator<Integer>[] variants = {
Integer::compare, Comparator.reverseOrder(), (a, b) -> a - b
};
for (var c : variants) GenericQuickSort.sort(copy(arr), c);
Common misconception: Believing int[] is always safer than Integer[] — the talk notes that under bimorphic layout profiles, flat primitive arrays can show a steeper cliff than saturation (“flat data is Valhalla challenge” — speaker opinion). The Valhalla era needs per-layout code species; you cannot assume primitives always win.
Structural constraints: one optimization package and future species#
Why: If one Java method has roughly one optimized machine code body at any moment (speaker description of today — no verbatim official document found), then int/long/Short and other type profiles crowd into the same nmethod and amplify pollution.
Mechanism and constraints: The Valhalla project page lists Parametric JVM — specializing and optimizing parameterized generic classes/methods at runtime. Speaker term species means “QuickSort::<Integer>sort routes to an algorithm copy that serves only Integer + a specific comparator” — vision, not current Java syntax. JEP 515 and JEP 483 let Leyden training runs persist profiles and code into an AOT cache — aligned with “keeping dynamic compilation gains,” but not equivalent to persisting arbitrary C++-style templates.


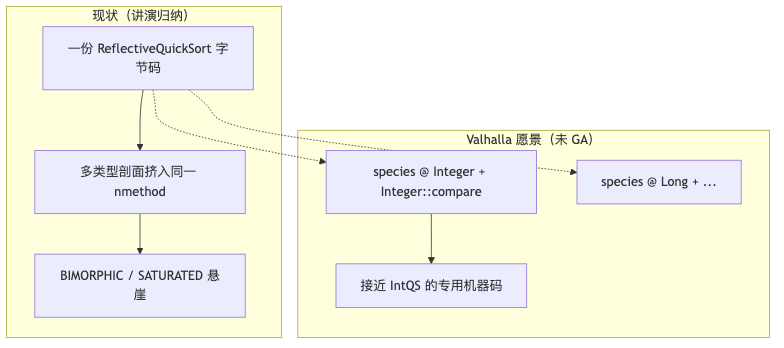
Common misconception: Treating Leyden AOT as “train once, C++ speed forever” — training coverage, cache invalidation, and later deoptimization policies still apply.
Repair prototype A: Hidden Class clone for a fresh profile#
Why: When the VM cannot yet support per-callsite species, libraries can use a new class identity to isolate polluted MethodData.
Mechanism and constraints: JEP 371 Lookup.defineHiddenClass derives a class from classfile bytes that normal discovery cannot load. Speaker experiment: read template ReflectiveQuickSort.class → define hidden class → invoke via MethodHandle so the optimizer accumulates a fresh monomorphic profile on the new class, claiming ~70µs pulled back to ~12µs (speaker experiment; Javadoc does not promise profile isolation). Limits: nested classes / multiple classfiles are hard to clone; wastes code cache (speaker acknowledged).
How:
byte[] tpl = Sort.class.getResourceAsStream("ReflectiveQuickSort.class").readAllBytes();
Class<?> species = MethodHandles.lookup().defineHiddenClass(tpl, true).lookupClass();
MethodHandle sort = MethodHandles.privateLookupIn(species, MethodHandles.lookup())
.findStatic(species, "sort", MethodType.methodType(void.class, Object.class, Comparator.class));
sort.invokeExact(array, comparator);
Common misconception: Treating the demo as a framework default — hidden classes are not normal API link targets, and cloning does not solve all nested/helper class dependencies.
Repair prototype B: MethodHandles forced inlining and type propagation#
Why: When the callee profile is saturated, the caller can drive C2 type propagation with a narrower MethodType and a constant comparator, reducing reliance on UseTypeProfile (speaker experiment).
Mechanism and constraints: asType narrows to Integer[], insertArguments binds the comparator, dropArguments keeps the signature; with hidden-class-triggered MH customization (forceCustomize — non-public API; symbol not found in local JDK) and -XX:InlineSmallCode=1g (java man page entry: controls size of compiled methods eligible for inlining; default 2500 — demo value, use with care in production), the talk reached ~24–28µs with -XX:-UseTypeProfile (IterQS/Integer[] — speaker opinion).

How:
Class<?> ac = Integer[].class;
MethodHandle mh = baseMh.asType(methodType(void.class, ac, ac, Comparator.class));
mh = MethodHandles.insertArguments(mh, 1, comparator);
mh = MethodHandles.dropArguments(mh, 1, Comparator.class);
// forceCustomize(mh); // speaker experiment helper
java -XX:-UseTypeProfile -XX:InlineSmallCode=1g -jar force-inline-demo.jar
java -XX:+PrintFlagsFinal -version 2>&1 | grep -E 'InlineSmallCode|UseTypeProfile'
Common misconception: Disabling UseTypeProfile or setting InlineSmallCode huge in production — that changes global inlining heuristics; not the same as the talk’s controlled microbenchmark.
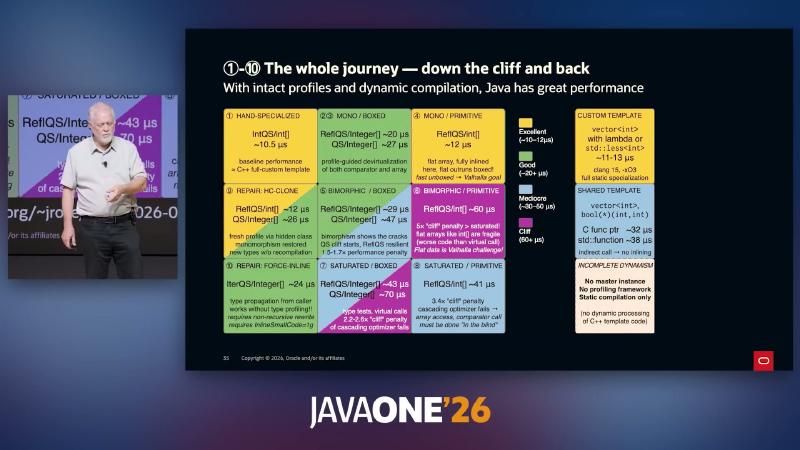
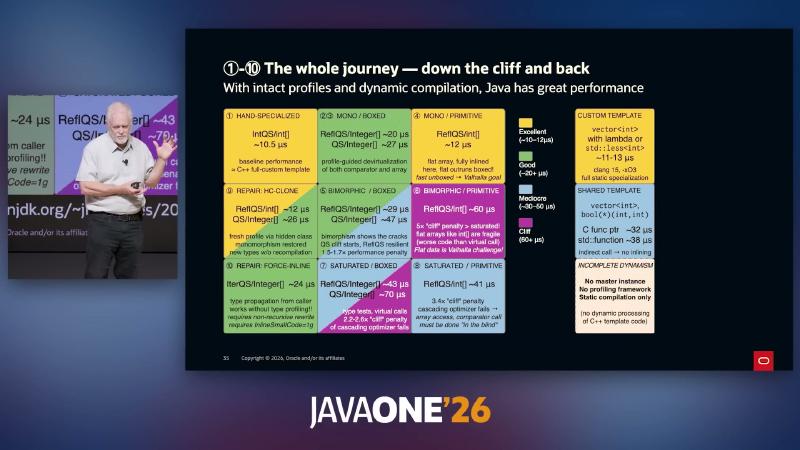
Journey overview: falling off the cliff, climbing back, and C++’s “incomplete dynamics”#
Why: Architecture choices trade “static waterfall builds” against a “static–dynamic feedback loop.” The JVM keeps the classfile master copy plus online JIT; C++ lacks an equivalent recompilation and profiling framework when comparator types are not visible (speaker argument).
Mechanism and constraints: With intact profiling, Java can reach HAND-SPECIALIZED / MONO territory (~10.5µs, comparable to C++ custom template); sliding BIMORPHIC → SATURATED shows ~1.5–6× cliffs; HC-CLONE and FORCE-INLINE are two speaker “climb back” prototypes. Author material Dynamic/Static interplay PDF is reachable (HTTP 200), but slide µs figures should still be validated with local JMH.
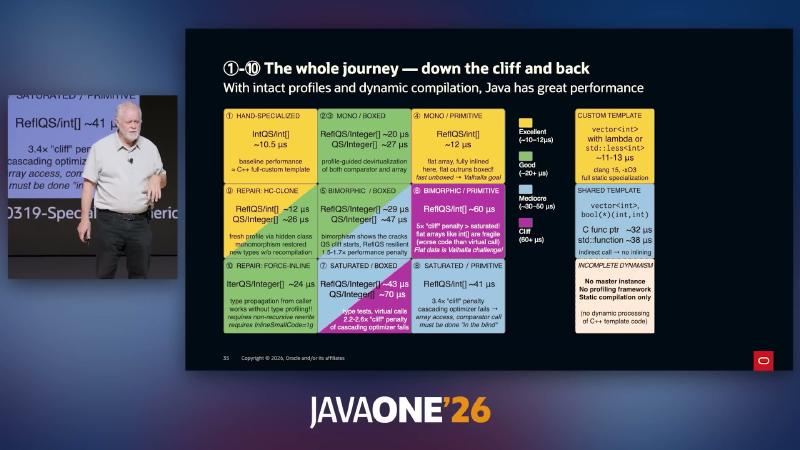

| Region (speaker labels) | Typical conditions | Approx. time (speaker) |
|---|---|---|
| HAND-SPECIALIZED | int[] + stable comparator | ~10.5µs |
| MONO / PRIMITIVE | reflection + flat int[] | ~10–12µs |
| MONO / BOXED | Integer[] + monomorphic profile | ~20µs |
| SATURATED | multiple comparator classes | ~70µs range |
| REPAIR: HC-CLONE | hidden class refreshes profile | ~12µs (reflective path) |
| REPAIR: FORCE-INLINE | MH type propagation | ~24–28µs |
Common misconception: Using one microbenchmark to guide multi-tenant production sorting — splitting comparator strategies at the application layer and isolating hot-path class loaders is often more reliable than hoping the VM “guesses right.”
Actionable diagnosis order (without talk-specific flags): use -XX:+PrintCompilation to confirm hotspots are C2-compiled; if throughput is off, enable PrintAssembly on suspect methods and check for class-check guards outside the loop vs invokeinterface still inside. When A/B testing mixed Comparator implementation classes, fix warmup rounds and heap size — do not treat an unstable profile as a regression. That aligns with JMH fork/warmup requirements, but online services also depend on class loading order and JIT queue delay; the two are not interchangeable.
References and further reading#
- JLS §4.6 Type Erasure
- JLS §4.8 Raw Types and Erasure Supplements
- OpenJDK Project Valhalla (including Parametric JVM direction)
- Valhalla design notes: homogeneous vs heterogeneous translation
- OpenJDK Project Leyden
- JEP 483: Ahead-of-Time Class Loading & Linking
- JEP 515: Ahead-of-Time Method Profiling
- JEP 371: Hidden Classes
- JEP 401: Value Classes and Objects (Preview)
- HotSpot Wiki — PerformanceTechniques (profiling, inlining, deoptimization)
- HotSpot Wiki — PrintAssembly (assembly diagnostics)
- HotSpot Wiki — RangeCheckElimination (array bounds-check optimization)
java.lang.reflect.ArrayAPI documentationjava.lang.invokepackage overview- OpenJDK JMH README
- John Rose — Dynamic/Static interplay (PDF, 2025-08)
- cppreference — C++ templates


