
Shipping Java Kernels to the GPU with Code Reflection: An Engineering Slice of HAT and Project Babylon#
For parallel work on the JVM, the usual paths are parallelStream or structured concurrency—both remain bounded by CPU thread count. To run the same business logic across tens of thousands of GPU threads, the traditional approach is hand-written CUDA/OpenCL plus JNI glue. For Java teams that means a second language, a second build, and obvious platform lock-in. Project Babylon’s Code Reflection and HAT (Heterogeneous Accelerator Toolkit) take a different route: keep Java as the authoring language, generate a transformable SSA code model at compile time, run it through multi-stage IR transforms, and hand the result to pluggable backends (OpenCL, CUDA, pure Java sequential execution, and others).
This article unpacks two engineering threads from an implementation perspective: (1) semantic fidelity—obtaining transformable IR between AST and bytecode; (2) device consumability—lowering array access, inter-procedural calls, and buffer read/write patterns to invoke and access types that backends and FFI can understand. Performance figures, IR equivalence claims, and similar statements are marked with boundaries unless backed by official benchmarks; APIs follow the OpenJDK incubator draft and the code-reflection branch of openjdk/babylon.

Why a code model between AST and bytecode is needed#
ASTs retain too much syntactic noise for cross-language lowering; bytecode is tuned for JVM execution and loses much source-level semantics (loops become goto, narrow types are widened, and so on). JEP draft 8361105 and the Code Models article position the code model as an immutable tree with fidelity “between AST and bytecode”: elements are operation / body / block, in SSA, influenced by MLIR/LLVM-style compilers. Only methods or lambdas annotated with @Reflect (incubator module jdk.incubator.code) have their models written into the class file by javac; at runtime you retrieve the root CoreOp.FuncOp via APIs such as Op.ofMethod, then transform to produce a new model that can be written back as bytecode.
Mechanism and constraints: Every block must end with a terminating op (return, branches, etc.); ops reference SSA results with %n. Transformation means “walk the old model + build a new model with a block builder”; the model itself is immutable.
Minimal example (same family as the JEP 8361105 example):
import jdk.incubator.code.Op;
import jdk.incubator.code.Reflect;
import jdk.incubator.code.dialect.core.CoreOp;
@Reflect
static int squareKernel(int i, int[] array) {
array[i] = array[i] * array[i];
return 0;
}
// Runtime: Optional<CoreOp.FuncOp> m = Op.ofMethod(Square.class.getDeclaredMethod("squareKernel", ...));
// m.ifPresent(f -> f.transform(transformer));
Traversal and construction: For an existing FuncOp, use elements() to stream over block/body/op; for new logic, append ops with Block.Builder and ensure each block ends with a terminating op. Printing SSA text (func @"squareit" (%0 : ...) -> { %1 = var.load ...; return %7; }) is the most readable way to debug transforms; it does not map line-for-line to Java source in the IDE.
Common pitfalls: Treating the code model as a drop-in AST or bytecode disassembly substitute; Op.ofMethod returns empty when @Reflect is missing, so downstream graph construction fails immediately; mutating old nodes inside a transform—always produce a new FuncOp.
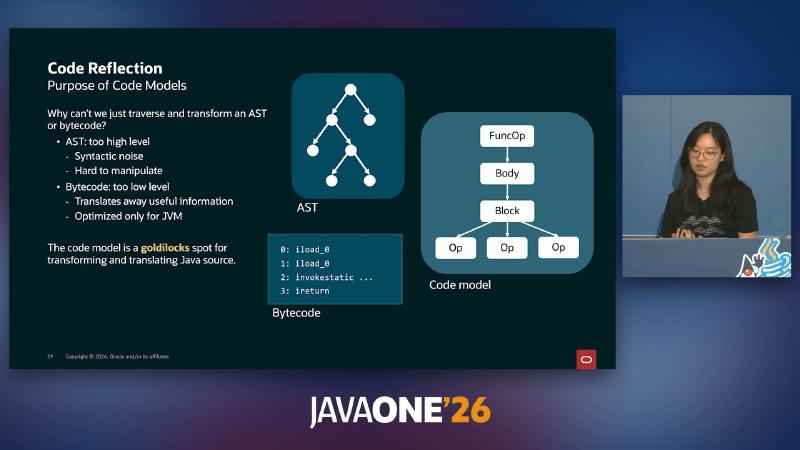



The HAT stack: Panama memory, code reflection, and pluggable backends#
HAT uses the Panama Foreign Function & Memory API (MemorySegment, MemoryLayout) to describe off-heap buffers, uses Babylon code reflection to read/transform the kernel’s FuncOp, and dispatches NDRange work through Accelerator / ComputeContext to concrete backends. The official HAT README and matmul article list run backends including ffi-opencl, ffi-cuda, java-seq (CPU sequential, useful for debugging), and others; build artifacts look like hat-backend-ffi-opencl-1.0.jar. PTX and SPIR-V appear in Babylon roadmap material as GPU code-generation explorations; standalone SPIR-V/HIP run backends are not listed in the README/Config we verified—if you hear of a HIP backend, treat it as an unverified extension name.
Why: Decouple “what to write” from “where to run,” so each project does not rewrite JNI plus vendor runtime glue.
How (reproducible on the code-reflection branch):
cd hat
java @.bld
java @.run java-seq life
java @.run ffi-opencl life
The underlying JVM typically needs: --enable-preview --add-modules=jdk.incubator.code --enable-native-access=ALL-UNNAMED (see README).
The bld target in hat.java compiles hat-core, hat-optkl, each hat-backend-ffi-*, and triggers cmake native wrapper builds; terminal OCR repeatedly showing We will need jextract to create jextracted backends points at OpenCL/OpenGL-style header binding paths. That is unrelated to kernel IR algorithms but can block the expectation of “clone once and run the demo immediately.”
Common pitfalls: Assuming a backend switch is only a string change without rebuilding native dependencies; omitting preview/incubator module flags so Op classes are missing; reading Config PTX options as a separate “PTX backend”—they mean the CUDA path can pass PTX instead of C99 source (see Config comments).
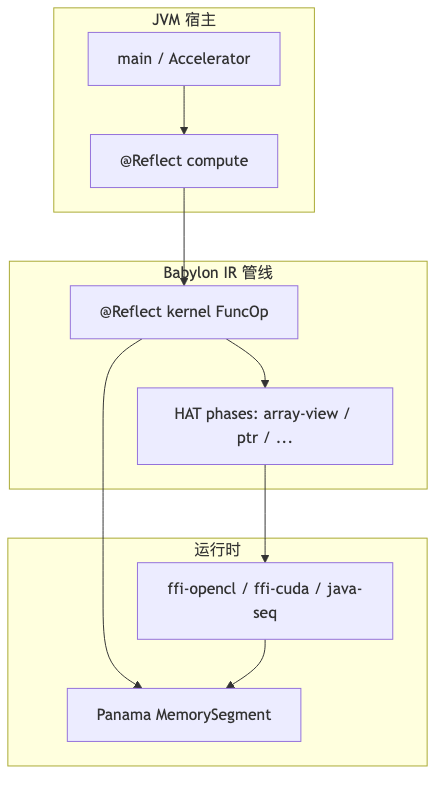
Three layers: Kernel, Compute, and host#
| Layer | Responsibility | @Reflect (current implementation) |
|---|---|---|
| Kernel | Per-thread logic; thread coordinates via gix/giy on KernelContext | Required |
| Compute | dispatchKernel over an NDRange | Required (ComputeContext throws if Op.ofMethod is empty at construction) |
| Host | Allocate buffers, create Accelerator, I/O | Usually not required |
Speaker opinion claims Compute “usually does not need @Reflect”—that does not match current ComputeContext.java and Life/matmul examples on the code-reflection branch; any path that builds a compute graph via accelerator.compute(...) requires @Reflect on the Compute entry. Docs also emphasize @Reflect on compute to inspect reachable kernels and data flow.
Minimal skeleton (concept merged from README and Life example):
@Reflect static void squareKernel(int i, @RW S32Array a) {
a.array(i, a.array(i) * a.array(i));
}
@Reflect static void squareCompute(ComputeContext cc, @RW S32Array a) {
cc.dispatchKernel(NDRange.of1D(a.length()), (KernelContext kc, @RW S32Array buf) ->
squareKernel((int) kc.gix(), buf));
}
Parameter annotations @RO / @RW / @WO (MappableIface) express programmer intent; after inlining, the automatic buffer tagger compares or supplements with AccessType inferred from invoke for FFI host-side staging. Kernels should keep only translatable arithmetic, branches, and buffer access; host-semantics objects such as Control in the Life example are passed as read-only context and are not written back on device.
Common pitfalls: @Reflect only on the kernel but not on compute; heavy I/O inside compute expecting device translation; treating informal “no Reflect needed” as the current API contract.
Array views: lowering array.load to buffer invoke#
Device backends naturally understand “invoke getter/setter on some interface,” not continuous Java array.load chains on multidimensional arrays. HAT’s array view phase (HATArrayViewPhase) matches JavaOp.ArrayAccessOp.ArrayLoadOp / ArrayStoreOp in SSA, conv indices to long, then replaces them with invoke on hat.buffer.* (e.g. S32Array::array(long):int).
Why: Programmers can write cellGrid.cell(idx) or array(i) in matmul; IR uniformly uses analyzable invoke, aligned with the Interface Mapper.
Mechanism: For 2dArray[kc.gix][kc.giy], the code model before transformation expands into multiple pointer/array load steps (speaker opinion: higher dimension means longer chains). The transform must recognize which load yields the final scalar, collect indices along operands (slide entry.transform + switch on ArrayLoadOp).



Slide pseudocode aligns with the sealed hierarchy in JavaOp: case ArrayLoadOp, walk operands %12, %14, etc., decide patterns like “the second load returns the int scalar,” resolve the correct getter signature via core reflection, and rewire uses to the new %r = invoke ... result. Store paths are symmetric. Skipping conv can make long indices inconsistent with layout assumptions on device.
Common pitfalls: Assuming the interface method is always named array() for every buffer type—Life’s CellGrid generates cell(long), alongside F32Array.array(long); follow the concrete Iface mapping; hardcoding device API strings in a transform instead of the Iface mapping table.
HAT dialect and multidimensional IR compression#
After array view, HAT introduces custom ops (e.g. HATPtrOp) forming the HAT dialect, executed in multiple stages by HATPhase (including memory, vector, etc.). Speaker opinion: after array view and pointer folding, generated device code can be semantically equivalent to code without view—not verified by IR diff in this article’s environment.
How (transform entry shape, same as JEP FuncOp.transform):
entry.transform(entry.funcName(), (bb, op) -> {
switch (op) {
case JavaOp.ArrayAccessOp.ArrayLoadOp alop -> {
// Recognize final scalar load, collect indices, emit pointer / invoke
}
default -> { /* copy or fold */ }
}
});
KernelCallGraph calls HATTier.transform(HATTier.KernelPhases, ...) after inlining, chaining array view, memory, vector, and other phases into a fixed pipeline rather than letting application code assemble phases ad hoc. For maintainers, a new device target is usually a backend module plus lowering, not forking the entire Java front end.
Common pitfalls: Hand-writing device code strings inside a transform—lowering should preserve semantics at IR, then hand off to backends; running pointer op folding before array view because phase order was skipped.
Inlining and buffer tagging: inter-procedural tracking reduced to a single pass#
Host–device buffer copies are often more expensive than the kernel itself. HAT needs read-only / write-only / read-write per parameter (AccessType) to shrink transfers. If a kernel calls helper(buf), mapping formal parameters to buffers across calls gets complex quickly.
Strategy (KernelCallGraph, aligned with the talk): SSA.transform first, then loop Inliner.inline until no more inlinable InvokeOp; run BufferTagger on the single inlined FuncOp; finally execute HATTier.KernelPhases.
Inlining constraint: A callee with multiple return sites cannot be spliced directly—you must merge to a single return block inside the callee model, replacing return with branch (official Inliner Javadoc states the same).


Buffer tagger rules (verified against source logic):
- Getter
invokewith a return value → read (RO or upgraded to RW) - Void setter
invoke→ write - Same buffer read then write → RW


Typical inliner flow for return (consistent with incubator Inliner): walk callee body ops; on ReturnOp that exits the current method, compute merge blocks for multiple returns if needed, optionally create a return block with block parameters, replace the original return with branch; otherwise append the op to the caller’s Block.Builder. The buffer tagger then sees a single linear invoke sequence, not a cross-function virtual call graph.
BufferTagger.getAccessList returns an AccessType list in the same order as inlined entry block formals, for optkl/FFI mapping to OpenCL/CUDA parameter qualifiers. Getter with return value counts as read; void setter counts as write; read-then-write on the same IfaceValue upgrades to RW; paths such as isReference avoid mis-tagging “reference pass-through only” as read.
Common pitfalls: Hand @RW on every parameter that contradicts actual IR access; expecting the tagger to propagate across call edges without inlining helpers; merging different SSA slots (e.g. %4 vs %5) that represent different buffer instances.
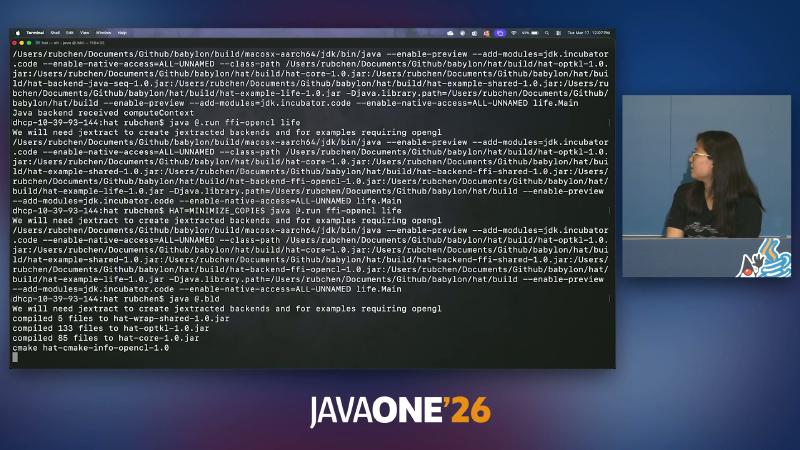
Runtime: HAT=MINIMIZE_COPIES and backend selection#
Config.MINIMIZE_COPIES (alias MC) is read from the HAT environment variable or system properties; comments state it mainly affects the FFI path to reduce copies. In the demo, Game of Life on java-seq is very slow; ffi-opencl is clearly faster; with HAT=MINIMIZE_COPIES the speaker claimed roughly 2× vs the previous OpenCL run—live demo opinion, no official benchmark table.
export HAT=MINIMIZE_COPIES
java @.run ffi-opencl life
Note: hat.java help text once showed -DHAT=MINIMIZE_BUFFERS, which does not match Config; use MINIMIZE_COPIES.
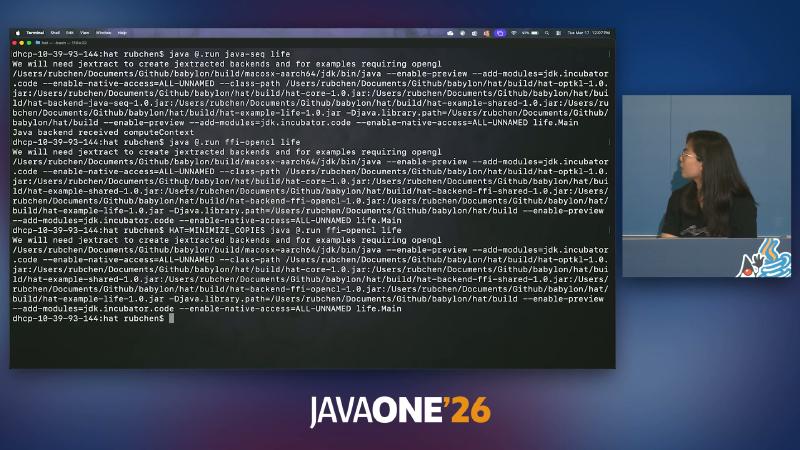
The demo terminal running java @.run java-seq life may print Java backend received computeContext (that string was not located in the source snapshot verified for this article). java-seq’s value is validating IR and logic on the same @Reflect kernel, not serving as a performance baseline; OpenCL plus MINIMIZE_COPIES is what tests “tagging → fewer copies.”
Common pitfalls: Expecting copy optimization on java-seq; minimizeCopies() targets FFI; treating demo speedup as a general SLA; using the help spelling MINIMIZE_BUFFERS.
Game of Life: same rules, two surface syntaxes#
Conway B3/S23 in the HAT example life/Main.java is implemented in ComputeLife as lifePerIdx counting eight neighbors then
((count == 3) || ((count == 2) && (cell == ALIVE))) ? ALIVE : DEAD
The demo can start with a val(cellGrid, ...) helper for access, then move to the more intuitive cellGrid.cell(...) / array view style; speaker opinion says recompiled behavior is identical, meaning the transform pipeline absorbs syntactic differences. The repository today centers on cell(long) and embedded codeLifePerIdx OpenCL fragments; two equivalent paths are not kept side by side in source for diff.
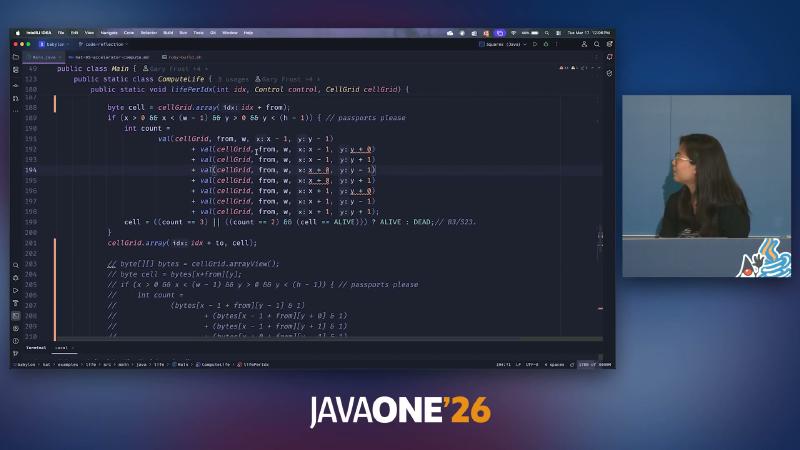
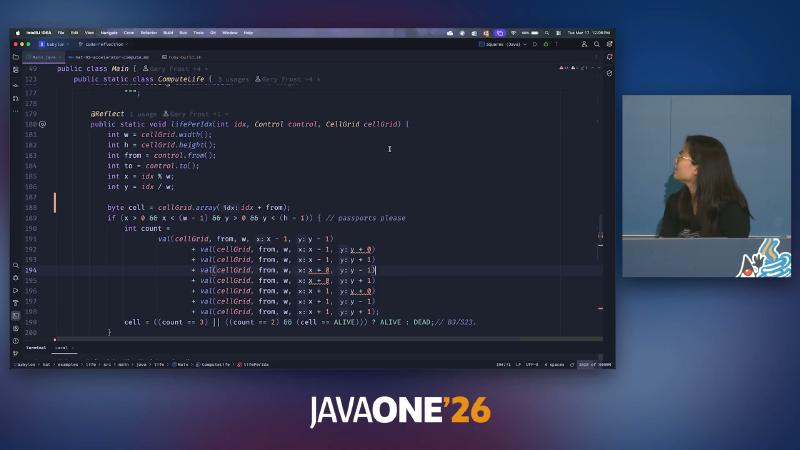
life(KernelContext kc, ...) calls lifePerIdx per gix on the NDRange; eight-neighbor reads can expand in source to many cellGrid.cell(...) or val(CLWrapCellGrid, ...) strings (compare with embedded codeLifePerIdx); after compilation they should converge to the same device access pattern. Speaker opinion says both styles behave the same after recompile—if you want to verify, run golden grid comparison locally for each source variant rather than relying on slide narration.
The IDE shows ComputeLife nested class, @Reflect, and hat-05-accelerator-compute.md documentation together, indicating the example serves both “Accelerator compute model” teaching and IR experiments; production integration should pin a Babylon JDK build, not the system default JDK.
Common pitfalls: Treating val(...) as a runtime function left on the device path; keeping non-inlinable JDK library calls inside the kernel; switching array view syntax without rebuilding hat-example-life-1.0.jar.
Closing: where code reflection sits in HAT#
HAT is not a toy that “compiles Java to CUDA strings”; it is a verifiable engineering chain: @Reflect gate → SSA FuncOp → array view / HAT dialect → inlining + buffer tagger → pluggable FFI backends, on top of Panama’s memory model. For teams, the value is one Java kernel source for CPU debugging (java-seq) and OpenCL/CUDA acceleration, with MINIMIZE_COPIES connecting RO/RW facts in IR to the transfer layer—provided you accept incubator APIs, preview features, and local native build cost.
If you are evaluating whether to adopt this stack, self-check in order: (1) Can your local Babylon JDK load jdk.incubator.code? (2) Does java @.bld produce the hat-backend-ffi-* you need? (3) Does java-seq run your target example? (4) Then switch to ffi-opencl and HAT=MINIMIZE_COPIES for transfer-layer comparison. When the first three steps fail, check jextract/cmake before changing kernel algorithms.
Unverified boundaries at a glance: ≈2× speedup is demo narration only; HIP backend and the log string Java backend received computeContext were not located in captured source; device code equivalence with vs without array view is speaker opinion; Compute without @Reflect conflicts with current ComputeContext. Before production adoption, run hat examples and tests (e.g. TestArrayView) on your target JDK branch against the JEP and openjdk/babylon tags.
References and further reading#
- Project Babylon project page
- JEP draft 8361105: Code reflection (Incubator)
- Code Models — code model and SSA design
- JEP 454: Foreign Function & Memory API
- Optimizing GPU Programs from Java using Babylon and HAT (matmul)
- openjdk/babylon — HAT directory on
code-reflectionbranch - HAT README — build, backends, and full examples
- ComputeContext.java — compute graph and hard
@Reflectrequirement - KernelCallGraph.java — inlining and buffer tagging order
- Inliner.java — merging multiple returns into branch
- BufferTagger.java — RO/RW/WO inference from invoke
- HATArrayViewPhase.java — array.load to invoke transform phase
- Config.java —
MINIMIZE_COPIESenvironment variable semantics - life/Main.java — Game of Life example source
- JavaOp.ArrayAccessOp — array access ops in the incubator module


