
Agentic AI in the Java Ecosystem: How Three Frameworks Clarify Orchestration Differences Through One Use Case#
When enterprises wire LLMs into Java services, the real disagreement is usually not “can we call OpenAI?” but who decides the next step: application code, a framework DSL, or the model self-routing within a tool set. At Spring I/O 2026, Timo Salm and Sandra Ahlgrimm used the same AI nutrition weekly plan scenario to compare Spring AI, LangChain4j’s langchain4j-agentic, and Embabel built on Spring AI. The sections below distill that comparison into actionable selection and implementation guidance. On-stage comparison tables and subjective ratings are the speakers’ views; where public documentation does not endorse each cell, that is called out separately.
From RAG to Agentic: Tool Surfaces and Protocol Layers#
LLM applications typically evolve along a capability ladder: standalone models and prompt engineering → RAG grounded in business data → tool calling and code interpreters → multimodal input → orchestration, memory, planning, and standardized tool protocols. The key shift in the agentic stage is that as tool/RAG paths multiply, routing decisions move increasingly to the model, while the application side must provide predictable tool contracts and observability.
Model Context Protocol (MCP) is maintained by the community as an open standard (current governance in LF Projects stewardship) to connect data sources, tools, and workflows to AI applications in a uniform way; Agent2Agent (A2A) targets cross-vendor agent interoperability. Java teams already on Spring Boot can use Spring AI’s MCP annotations and starters to expose methods such as @McpTool as MCP tools without rewriting RPC shapes for every integration.

Why: Java backends often already have security, transactions, and observability stacks; if every Copilot integration defines its own tool schema and transport, integration cost grows exponentially. MCP pulls “what tools look like” out of business code; A2A answers “how do multiple autonomous agents exchange tasks and results”—the two complement each other rather than being an either/or choice.
How (minimal server side): After enabling the MCP Server Starter in Spring Boot, annotate existing service methods with @McpTool; the framework generates JSON schema and mounts it on the MCP endpoint. On the client side, use McpClient to fetch the tool list and hand it to ChatClient’s tool-calling loop (see MCP Overview).
Common pitfalls: Treating “we connected MCP” as “we already have a controllable agent system.” The protocol standardizes connectivity; task decomposition, validation loops, and cost caps still need explicit modeling at the application or framework layer. When describing MCP externally, distinguish “early push by Anthropic” from “current LF Projects governance” (per the governance page) to avoid conflating stewardship with the original sponsor.
Workflow vs. Pure Agent: Set Orchestration Philosophy First#
Anthropic’s engineering post distinguishes two system types: Workflows orchestrate LLMs and tools through predefined code paths; Agents let the LLM dynamically decide process and tool use. In enterprise settings, workflows are usually more predictable, testable, and easier to cap for latency and token cost; pure agents suit open tasks whose steps cannot be enumerated upfront but need stronger guardrails and testing investment (speaker’s view, consistent with Anthropic’s experiential judgment in that post).

| Dimension | Workflow (predefined path) | Pure Agent (model self-routing) |
|---|---|---|
| Testability | High: clear step boundaries | Low: non-deterministic paths |
| Cost / latency | Relatively easy to cap | Tends to grow with rounds |
| Fit | Nutrition plans, approval flows, ETL-style AI | Exploratory research, open-domain assistants |
Common pitfalls: Defaulting to a fully autonomous agent to “look advanced.” If business steps can be drawn as a flowchart, prefer workflow and use model decisions only locally within substeps.
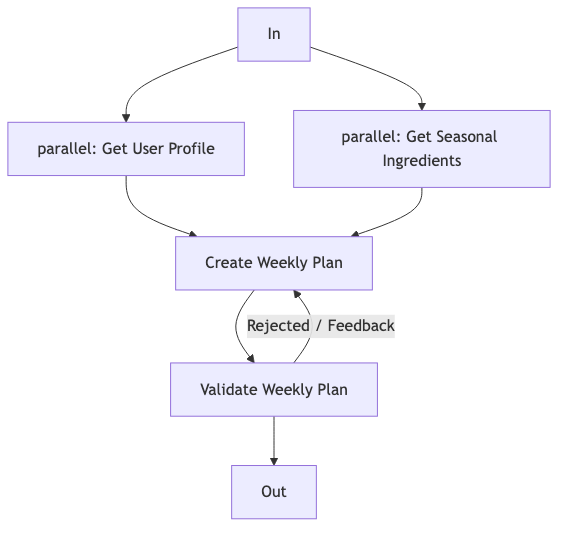
Nutrition Weekly Plan: Parallelization + Evaluator–Optimizer#
The comparison demo deliberately combines two workflow patterns Anthropic summarizes (names per the official source):
- Parallelization: fetch user profile and seasonal ingredients in parallel;
- Evaluator–Optimizer: generate weekly plan → validate against allergy/calorie rules → retry with feedback on failure.


Why: A single prompt struggles to satisfy both structured output and hard constraints; staged calls make it easier to insert programmatic validation and observable spans.
Mechanism / constraints: Each LLM round consumes context; feedback on validation failure accumulates in later prompts—set maxAttempts / maxIterations to prevent runaway cost (all three framework implementations reflect this constraint, speaker’s view).
How (logical skeleton shared by all three implementations):
Phase1: parallel(fetchProfile, fetchSeasonalIngredients)
Phase2: createWeeklyPlan(profile, ingredients, request)
Phase3: loop until nutritionRulesPass(plan) or maxAttempts
The nutrition demo UI asks users to check meals for the week, enter a country ISO code, and constraints such as “complete within 30 minutes”; generated results need ingredient grams, nutrition tables, and cooking steps—this strong structure + hard rules scenario is where evaluator–optimizer beats a single call().content().
Common pitfalls: Leaving all “validation” to the same LLM for self-assessment without executable rule functions (e.g., sodium limits, allergen enums); or sharing mutable objects across the parallel phase without thread-safe isolation.
Spring AI: Hand-Rolled Parallelism + Advisor Validation Loop#
Parallel phase: demo-level Workflow.parallel, not a framework API#
The Spring AI reference does not document Workflow.parallel; the on-stage Workflow.java is a demo utility wrapped with CompletableFuture and a fixed thread pool—semantically “standard Java concurrency running two Suppliers” (aligned with speaker narration and document search, speaker’s view).
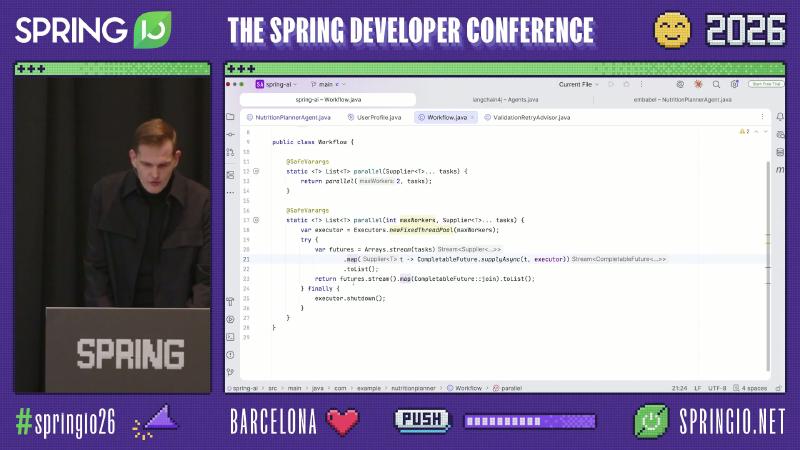
// Demo repo utility + Spring AI ChatClient (not a built-in Spring AI API)
var result = Workflow.parallel(
() -> fetchUserProfileForUser(name),
() -> fetchSeasonalIngredients(request));
var userProfile = (UserProfile) result.getFirst();
var seasonalIngredients = (SeasonalIngredients) result.getLast();
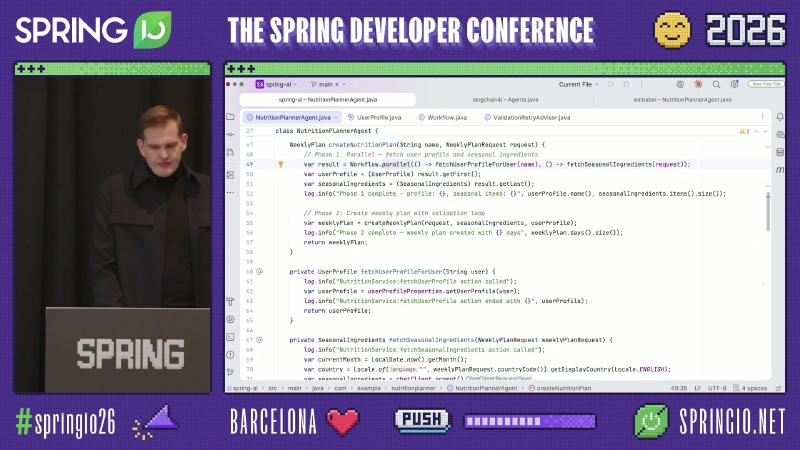
The MCP entry can expose the same business capability via @McpTool integrated with Spring Security (read the current user from SecurityContextHolder and delegate to internal methods—demo logic).
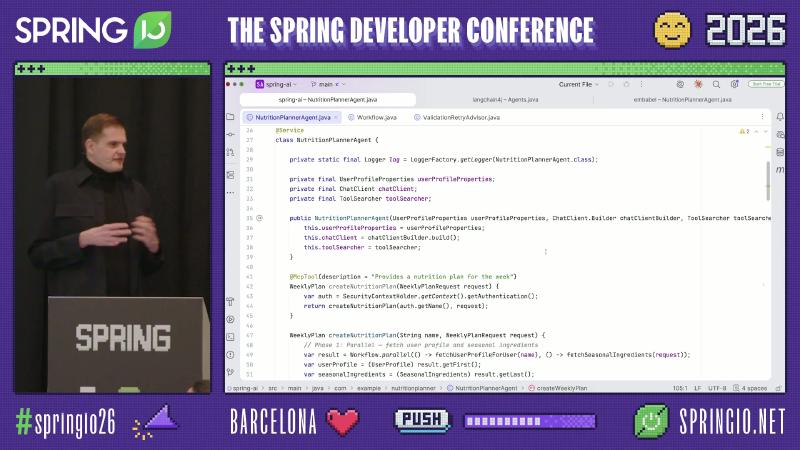
Evaluator–Optimizer: Recursive Advisors#
Spring AI’s Advisor chain can intercept ChatClient calls. The official StructuredOutputValidationAdvisor retries via callAdvisorChain.copy(this) when JSON schema validation fails. The on-stage ValidationRetryAdvisor is a demo class name with the same pattern: validate WeeklyPlan business rules and send feedback back to the model on failure.
// Demo pattern; in production prefer StructuredOutputValidationAdvisor.builder()
var advisor = new ValidationRetryAdvisor<>(
WeeklyPlan.class,
plan -> validateWeeklyPlan(plan, userProfile));
WeeklyPlan plan = chatClient.prompt()
.advisors(advisor)
.user(/* ... */)
.call()
.entity(WeeklyPlan.class);
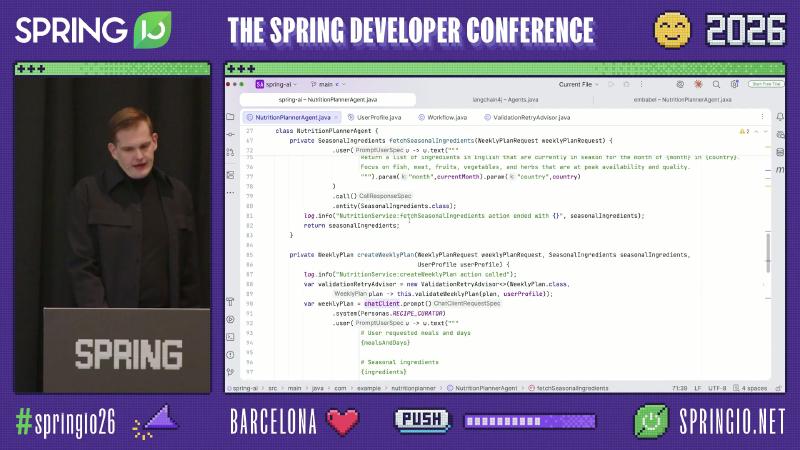
Why an Advisor chain: When nutrition plan validation fails, you need to send business feedback (e.g., “Wednesday sodium over limit”) back to the model for regeneration, not simply retry the same prompt. ChatClient advisors share the call chain with ToolCallAdvisor, aligning spans in Micrometer / OpenTelemetry without hand-rolling another HTTP client in validation logic.
Mechanism / constraints: Recursive Advisors copy downstream via CallAdvisorChain.copy(after); StructuredOutputValidationAdvisor targets JSON schema; the demo’s ValidationRetryAdvisor targets WeeklyPlan domain rules—the two can stack, but watch maxRepeatAttempts and total token budget. The talk noted Spring AI’s internal structured output already uses a similar retry loop (speaker’s view), consistent with public documentation direction.
How: Use Java concurrency or Spring @Async for parallelism; for the validation loop prefer StructuredOutputValidationAdvisor.builder() with a custom CallAdvisor wrapping business rules. If exposing MCP, keep HTTP controllers and @McpTool entry points calling the same orchestration method to avoid logic drift.
Common pitfalls: Documenting “Spring AI has built-in Workflow.parallel”; treating the demo’s ValidationRetryAdvisor as a GA type. 2.0.0-M6 is still milestone—roadmap items such as tool search were not verified in this document pass and should not be written as GA. Also: advisor chains so deep that one user request triggers dozens of nested LLM calls—explicitly list “worst-case call count” in design review.
LangChain4j-agentic: Declarative sequence / loop#
The langchain4j-agentic module (tutorial marks it experimental) wires sub-agents and validation loops via @Agent, AgenticServices.agentBuilder, sequenceBuilder, and loopBuilder, reducing hand-written orchestration.
var validationLoop = AgenticServices.loopBuilder()
.subAgents(nutritionGuard, reviserAgent)
.maxIterations(3)
.exitCondition(scope -> {
var r = scope.readState("validationResult", null);
return r != null && r.allPassed();
})
.build();
var planner = AgenticServices.sequenceBuilder(Agents.NutritionPlanner.class)
.subAgents(seasonalAgent, weeklyPlanCreator, validationLoop)
.outputKey("weeklyPlan")
.listener(/* AgentListener / AgentMonitor */)
.build();
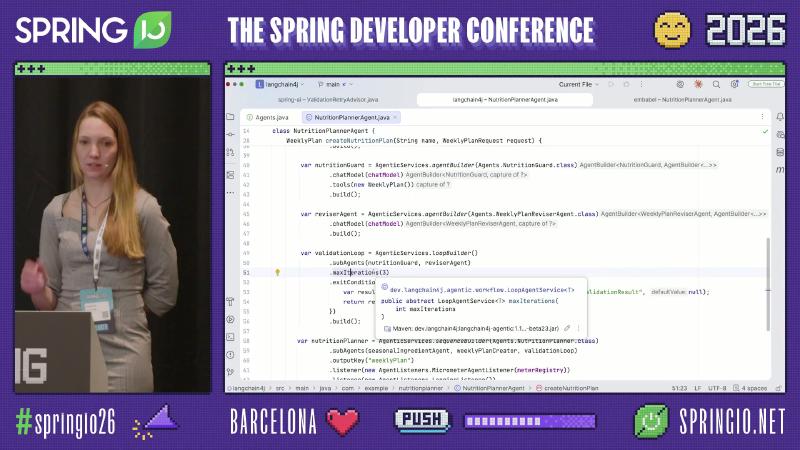
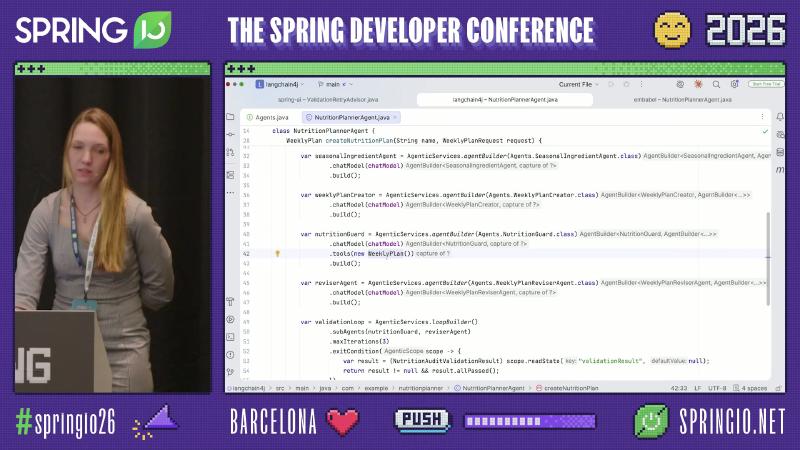
Why: When the step graph is stable and sub-agent boundaries are clear, a DSL reads better than scattered hand-written loops and AgenticScope shares state across steps.
Mechanism / constraints: maxIterations(3) caps tokens directly; exitCondition must be decidable to avoid infinite loops. MicrometerAgentListener in on-stage OCR was not found by name in the upstream repo—official types are AgentListener / AgentMonitor (unverified whether the demo wraps them).
Why: Timo hand-wrote parallel and loop on the Spring AI branch while LangChain4j expresses the same graph with builders—teams already using LangChain4j AiServices can extend the “sub-agent = method with @Agent” mental model and treat AgenticScope as key-value storage across steps.
Mechanism / constraints: parallelBuilder and sequenceBuilder sit side by side in AgenticServices; loop exitCondition reads state sub-agents must write (e.g., validationResult). The module opens by declaring experimental—APIs may change across minor versions.
How: Split “seasonal ingredients agent,” “weekly plan agent,” and “validate + revise loop” into separate @Agent methods, then chain with sequenceBuilder; for observability prefer official AgentListener / AgentMonitor, wrapping for Micrometer if needed (on-stage MicrometerAgentListener unverified as an upstream class name).
Common pitfalls: Ignoring experimental status for production; exitCondition exiting early because readState defaults are unhandled; unbounded reviser agent inside the loop inflating token bills (the talk tied maxIterations(3) to cost, speaker’s view).
Embabel: Planner + domain types + progressive tool exposure#
Embabel builds on the Spring ecosystem (README cites JVM/Spring), registering methods as agent steps via @Action, @Agent, etc.; default planning is GOAP (Goal Oriented Action Planning) with replanning after each step (README). The talk mentioned A* while the public README’s default algorithm differs—implementation details should follow the repository.
@Action
SeasonalIngredients fetchSeasonalIngredients(
WeeklyPlanRequest request, Ai ai) {
return ai.withAutoLlm()
.createObject(prompt.formatted(month, country),
SeasonalIngredients.class);
}
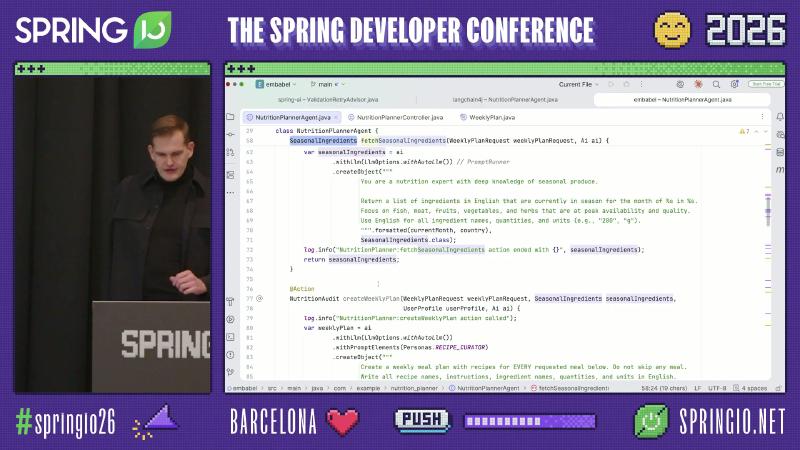
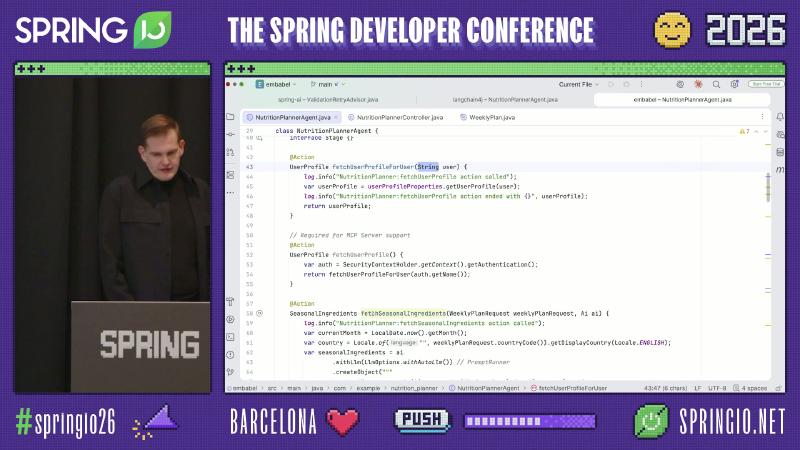
@UnfoldingTools: shrink tool metadata by category#
When MCP/business tool counts are large, registering everything at once blows context. Embabel’s @UnfoldingTools with @LlmTool carrying category enables progressive disclosure: expose an entry tool first, then expand by category (a different mechanism from tool search mentioned on the Spring AI roadmap—comparison is speaker’s view).
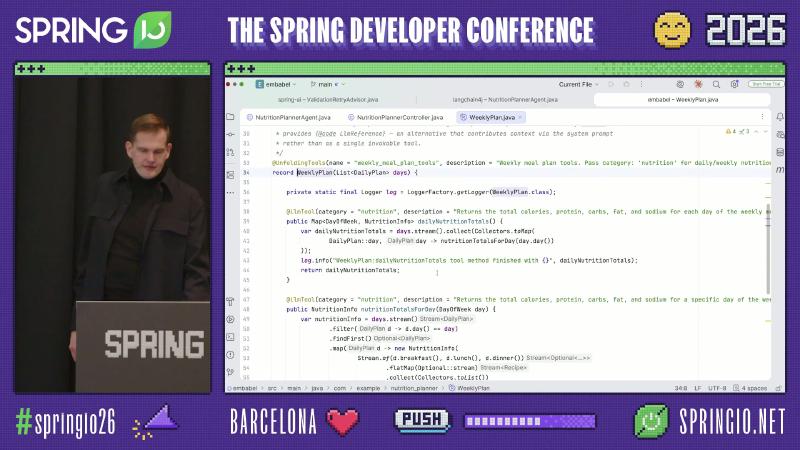
Unified entry: AgentInvocation#
HTTP, MCP, or Shell can trigger the same agent run via AgentInvocation:
@PostMapping("/plan")
WeeklyPlan create(@AuthenticationPrincipal Principal p,
@RequestBody WeeklyPlanRequest request) {
var invocation = AgentInvocation.builder(agentPlatform)
.build(WeeklyPlan.class);
return invocation.invoke(Map.of(
"user", p.getName(),
"request", request));
}
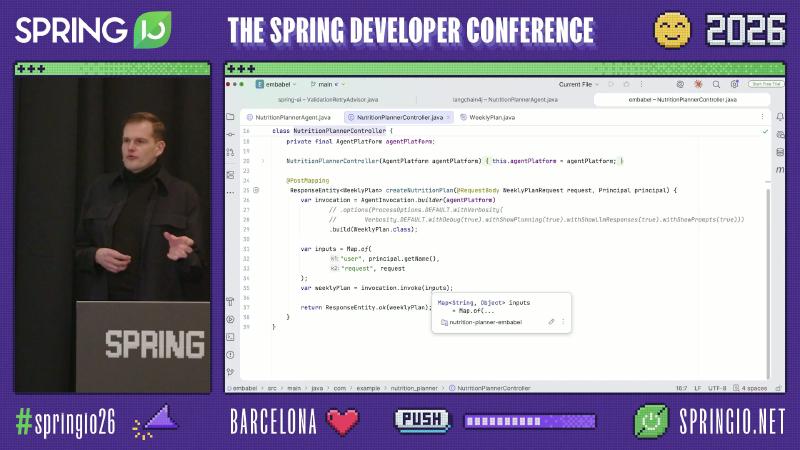
Why: Hand-written if/else for “fetch profile then generate plan” becomes hard to maintain as steps grow. Embabel uses GOAP to infer the next step from current state and @Action method signatures; missing method parameters fail planning, moving precondition checks from prompts into the type system (speaker demo framing).
Mechanism / constraints: README states planning steps are pluggable and replan after each step—unlike pure prompt orchestration. Ai wraps Spring AI ChatClient capabilities; createObject handles structured extraction. For tools, @UnfoldingTools gives the model a “gate” tool first, then expands @LlmTool by category, easing metadata pressure when registering hundreds of MCP tools at once.
How: One @Action per external capability; inject Ai ai where LLM sub-steps are needed; domain return types (UserProfile, SeasonalIngredients, WeeklyPlan) drive whether later steps can run. Use AgentInvocation at the HTTP layer; MCP/Shell share the same AgentPlatform (MCP details for the nutrition demo were not verified line-by-line against official pages).
Common pitfalls: Treating a comparison table of all green cells as production maturity; the talk stated Embabel is not yet GA (speaker’s view). Writing spoken A* into architecture docs—the public README default is GOAP, follow the repo. Call LLMs with ai.withAutoLlm() (Ai.kt), not LlmOptions.withAutoLlm().
How the three frameworks divide labor (concept matrix)#
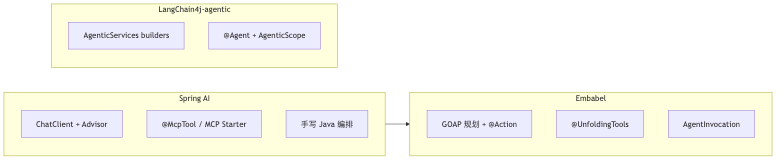
| Framework | Typical role | Orchestration expression | Maturity note (May 2026 doc snapshot) |
|---|---|---|---|
| Spring AI | LLM integration, Advisors, MCP/A2A | Code + Advisor chain; parallelism self-built | 1.1.x reference + 2.0.0-M6 |
| LangChain4j-agentic | Community agentic DSL | sequence / loop / parallel builders | Module experimental |
| Embabel | Higher orchestration on Spring | Type-driven steps + planner | SNAPSHOT / not GA (speaker’s view) |

The on-stage slide marked LangChain4j’s MCP cell No HTTP Server (unverified whether that covers Quarkus community extensions or only the core library HTTP server). Selection should validate “required MCP transport (stdio / HTTP)” rather than copying a single cell color.
How (selection checklist):
- Deep Spring Boot usage, minimal-deps LLM + MCP → evaluate Spring AI + hand-written workflow first;
- Want a Java DSL for subagent / loop and accept experimental → LangChain4j-agentic;
- Need GOAP-style step preconditions and progressive tool exposure, willing to track SNAPSHOT → Embabel (still compare against Spring AI capabilities).
Observability and testing (cross-cutting): All three can attach Micrometer-style metrics at different abstraction layers—Spring AI on advisor / ChatClient chain; LangChain4j on AgentListener; Embabel on AgentPlatform and invocation lifecycle. Unit tests for deterministic workflows should assert step order and validation branches, not LLM verbatim output; model output deserves schema + business-rule double assertions (aligned with the P04 demo). On-stage matrix yellow/green mixes for Testing and Observability reflect a snapshot in time, not a long-term roadmap (speaker’s view).
Common pitfalls: Replacing your own PoC with the on-stage matrix; ignoring differences between LangChain4j MCP tutorial and Spring AI MCP docs on client/server roles; mixing Embabel SNAPSHOT with Spring AI 2.0-M6 without locking BOM versions. Frameworks such as Koog (JetBrains) were not covered in this material—do not infer “only three Java options” from one conference session.
The same nutrition weekly plan appears in three code shapes: Spring AI keeps orchestration in Java + Advisors while the framework supplies LLM/MCP foundations; LangChain4j-agentic expresses sequence/loop with builders; Embabel uses a planner and type-driven steps with built-in progressive tool exposure. There is no absolute winner—only a fit with team skill stack, acceptable experimental risk, and whether “workflow share” matches your problem. If you already run one stack in production, the pragmatic path is often to add parallel and evaluator–optimizer loops on what you have, then evaluate higher-level DSLs as needed—rather than migrating to whichever column was all green on the comparison slide.
References and further reading#
- Anthropic — Building effective agents
- Model Context Protocol — Getting started
- Model Context Protocol — Governance and stewardship
- Agent2Agent (A2A) — What is A2A
- Spring AI reference (1.1.x)
- Spring AI 2.0.0-M6 documentation index
- Spring AI — Advisors API
- Spring AI — Recursive Advisors
- Spring AI — MCP overview
- Spring AI — @McpTool server annotations
- LangChain4j — Agents and Agentic AI
- LangChain4j — agents.md source
- LangChain4j — MCP tutorial
- Embabel Agent — README
- Embabel — @UnfoldingTools source


