
From REST to GraphQL: Contracts, Resolvers, and Real-Time Push on the Spring Stack#
A DJ console must show the current mix session, track list, artist details, audience votes, and live status on screen at once. REST can do it—one GET that returns the whole JSON tree—but the DJ screen often needs only a subset of fields while the voting page needs another; if live state relies on polling, latency and load both suffer. At Spring I/O 2026, Frederieke Scheper and Peter Eijgermans used the Disc Jockey Console to walk through migrating from a REST mindset to a schema-driven API on Spring GraphQL with Angular and Apollo. The sections below break down the mechanics; this is not a verbatim transcript. Demo class names come from the speakers’ code; framework behavior follows official documentation and the GraphQL specification (October 2021).
When to Stay on REST and When GraphQL Is Worth Evaluating#
Why: The GraphQL language specification states that clients use selection sets to fetch only the fields they need, avoiding over-fetching and under-fetching. REST costs less when the domain is simple CRUD, stable, and consumers are fixed; the speakers summarized (speaker’s view) that a single consumer, existing OpenAPI / Swagger investment, and strong reliance on HTTP caching often make staying on REST the safer bet. On the other hand, the DJ console needs sessions, tracks, songs, artists, and other shapes, plus live updates—the spec defines subscription as a long-lived request that pushes data on events, which contrasts architecturally with REST polling.
Mechanism and constraints: On the Spring side, Query and Mutation default to HTTP POST at /graphql with a JSON body (see Spring GraphQL — Transports). That differs from the common “REST GET + URL-level CDN cache” pattern—this is not a claim that GraphQL cannot be cached at all (normalized client cache, persisted queries, and other paths exist), but under the default POST single-endpoint model, HTTP-layer caching is not as turnkey as REST GET resources.
How: Before adopting GraphQL, document consumer count, field variance, whether you need push, and team learning cost; if only one internal service exists with a stable contract, do not adopt GraphQL for its own sake.
Common pitfalls: Treating “REST caches, GraphQL does not” as absolute law while ignoring persisted queries, field-level CDN, and similar supplements. Turning the choice into a religious war—the speakers closed with “REST isn’t wrong / GraphQL isn’t magic” (speaker’s view).
If you maintain internal systems in large organizations such as Dutch police or rail (speaker background, speaker’s view), GraphQL often appears at the seam where multiple teams and UIs share one backend; but if there is only one batch consumer and the contract has not changed in a decade, the marginal benefit of schema plus WebSocket infrastructure may be negative. A pragmatic approach is a table of “field variance × consumer count × need for push × team skill,” then decide whether to introduce GraphQL at new boundaries rather than replacing every REST endpoint at once.
| Dimension | REST is a better fit | GraphQL is worth evaluating |
|---|---|---|
| Consumers | Single, fixed contract | Multiple front ends, diverging field needs |
| Data shape | Stable CRUD | Nested aggregation, fields on demand |
| Real time | Polling is acceptable | Subscription needed |
| Caching | Strong ETag / CDN reliance | Application- and client-level cache strategies acceptable |
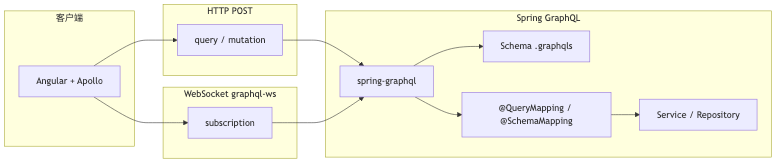
Schema as the Single Contract and Transport Split#
Why: Multiple micro-frontends (the speaker scenario includes Module Federation remote components—front-end architecture, not covered by Spring docs) each maintaining their own REST aggregation endpoints lets contracts drift. A GraphQL schema is a single contract at the type-system level; clients can consume the same shape via introspection (often disabled in production) and the toolchain.
Mechanism and constraints:
- Query / Mutation: HTTP (Spring’s
GraphQlHttpHandler, POST/graphql). - Subscription: WebSocket; Spring builds on graphql-ws (subprotocol
graphql-transport-ws); the oldersubscriptions-transport-wsis no longer active.
How: Place .graphqls under src/main/resources/graphql/ (Boot loads them by default; see Spring Boot — GraphQL Schema). Align Query field names with Java method names (e.g. currentMixSession).
Common pitfalls: Saying “GraphQL WebSocket” without naming the protocol; letting multiple teams extend mutations before the schema is stable without an additive evolution and @deprecated strategy.
A minimal schema fragment (field names must match controllers) can look like:
type Query {
currentMixSession: MixSession
}
type Mutation {
crowdCheered(id: ID!): MixSession
}
type Subscription {
mixSessionUpdated(id: ID!): MixSession
}
With spring.graphql.graphiql.enabled=true (development), GraphiQL helps validate the contract against resolvers. spring.graphql.schema.locations and file-extensions can become classpath*:graphql/**/ in multi-module setups (Schema Resources).
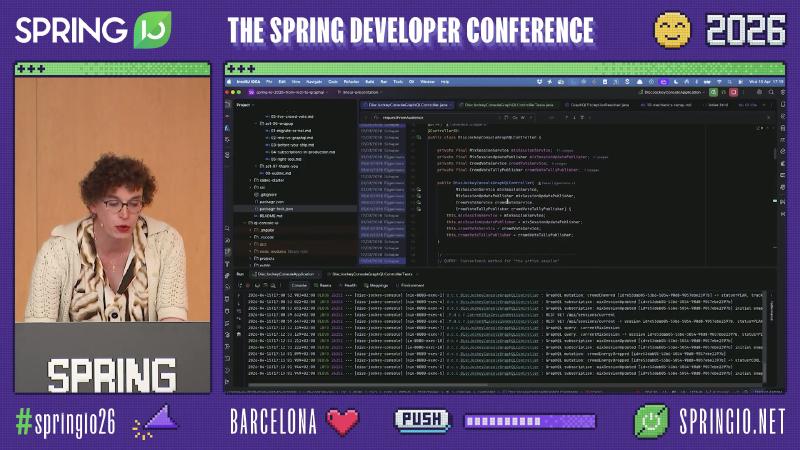
Annotated Controllers: Map by Field, Not by URL#
Why: REST often assigns @GetMapping / @PostMapping per resource; GraphQL’s entry is usually one HTTP endpoint, with dispatch by operation and schema field. Spring provides @QueryMapping, @MutationMapping, and @SubscriptionMapping as shortcuts for @SchemaMapping (Annotated Controllers).
Mechanism and constraints: AnnotatedControllerConfigurer registers annotated methods as DataFetchers; when the annotation does not declare a name, the Java method name maps to the field name by default. @Argument binds GraphQL arguments.
How (demo structure; class names from the session):
@Controller
public class DiscJockeyConsoleGraphQLController {
@QueryMapping
public MixSession currentMixSession() {
return mixSessionService.getCurrentSession();
}
@MutationMapping
public MixSession crowdCheered(@Argument UUID id) {
return mixSessionService.applyCrowdCheered(id);
}
}
Common pitfalls: URL-path thinking inside GraphQL controllers; stuffing one mutation with cross-aggregate side effects instead of pushing them into domain services.
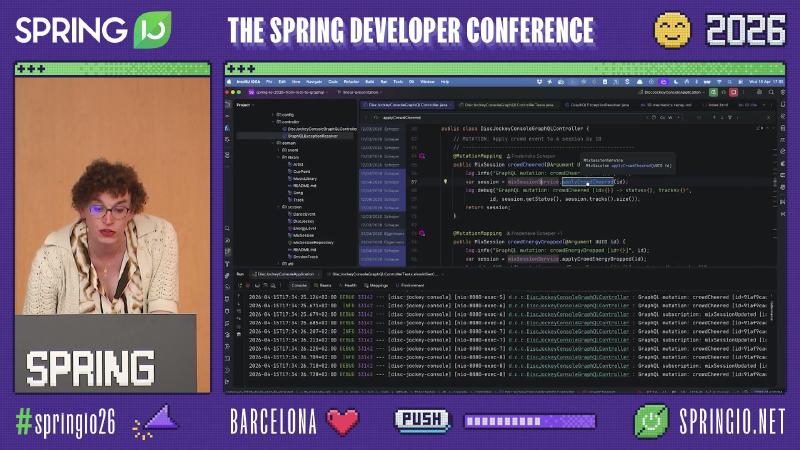
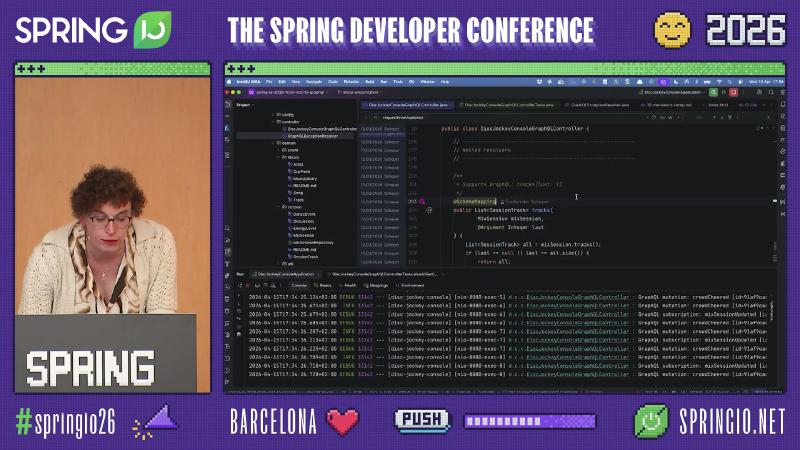
Field-Level @SchemaMapping and List Arguments#
Why: Even when clients omit fields via selection sets, DJ lists can still be long; adding MixSession.tracks(last: Int) on the schema lets the server return only the last N tracks, easing rendering and transfer.
Mechanism and constraints: @SchemaMapping binds a method to a type’s field DataFetcher; the first parameter is the source (parent object), and @Argument injects field arguments (documentation). subList inside the method is application-layer slicing; the spec does not mandate this kind of parameterization, but it is a valid design. The talk did not cover DataLoader or N+1—evaluate nested lists separately in production.
How:
@SchemaMapping
public List<SessionTrack> tracks(MixSession mixSession, @Argument Integer last) {
List<SessionTrack> all = mixSession.tracks();
if (last == null || last >= all.size()) return all;
return all.subList(all.size() - last, all.size());
}
Common pitfalls: Doing all list trimming in resolvers instead of paging at the persistence layer; N+1 from nested field loops (not demonstrated here).
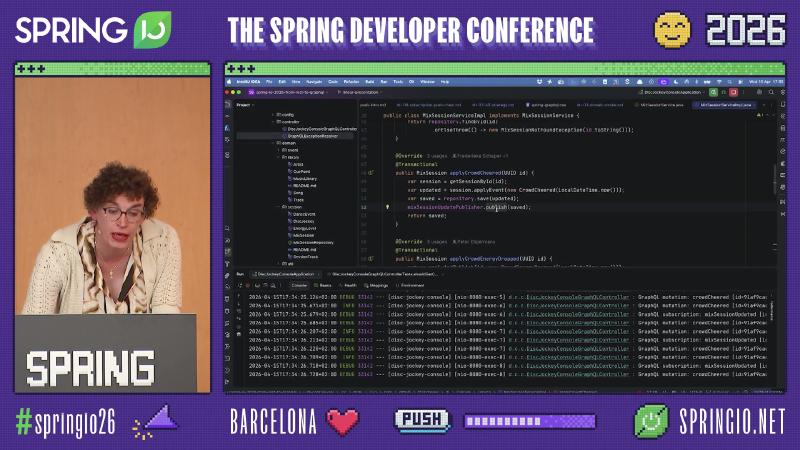
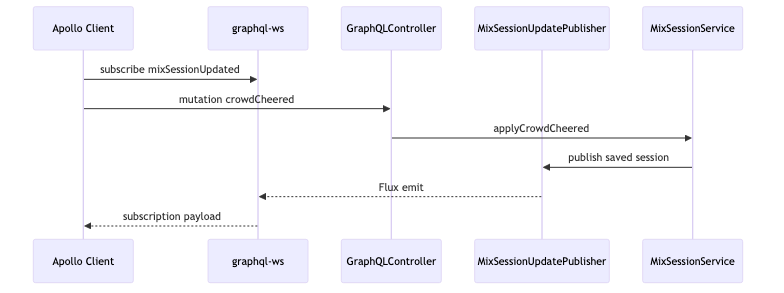
Mutation, Domain Services, and Subscription Broadcast#
Why: Audience actions such as “CROWD CHEERED” must persist domain state and notify subscribed DJ screens and dashboards. GraphQL mutations should be thin orchestration; state changes and transaction boundaries belong in domain services.
Mechanism and constraints: @MutationMapping methods call Spring beans such as MixSessionServiceImpl; @Transactional and repository.save belong to the demo domain model (class names not verified against official docs). After save, MixSessionUpdatePublisher.publish emits into a Reactor stream for @SubscriptionMapping consumers. Spring documentation states subscription responses are Reactive Streams Publishers on the GraphQL Java side (Transports).
How:
@Transactional
public MixSession applyCrowdCheered(UUID id) {
var session = getSessionById(id);
var updated = session.applyEvent(new CrowdCheered(LocalDateTime.now()));
var saved = repository.save(updated);
mixSessionUpdatePublisher.publish(saved);
return saved;
}
Common pitfalls: Repositories directly in resolvers, making tests and ArchUnit layering hard to enforce; mutation succeeds but no publish, so subscribers never receive events.
Subscription: Sinks, Flux, and WebSocket#
Why: Replace polling currentMixSession with push when mix sessions or vote tallies change.
Mechanism and constraints:
@SubscriptionMappingcan returnFlux<T>(Controllers).- The demo uses
Sinks.many().multicast().onBackpressureBuffer()andtryEmitNext(Reactor Sinks API) for in-process broadcast; multi-instance, sticky sessions, and auth are outside Spring GraphQL docs and are operational topics. - Filter by session
id:sink.asFlux().filter(...). The speakers mentionedFlux.concatto push a current snapshot then follow with updates (demo technique, not a framework requirement).
How:
public class MixSessionUpdatePublisher {
private final Sinks.Many<MixSession> sink =
Sinks.many().multicast().onBackpressureBuffer();
public void publish(MixSession s) { sink.tryEmitNext(s); }
public Flux<MixSession> streamForSession(UUID id) {
return sink.asFlux().filter(s -> s.id().value().equals(id));
}
}
@SubscriptionMapping
public Flux<MixSession> mixSessionUpdated(@Argument UUID id) {
return mixSessionUpdatePublisher.streamForSession(id);
}
Common pitfalls: Treating in-memory Sinks as cross-Pod broadcast; ignoring EmitResult failures and backpressure; pushing sensitive sessions over unauthenticated WebSockets. The speakers said production subscriptions are “difficult / you skip it” (speaker’s view)—consistent with documentation on protocol complexity, but not a ban on subscriptions in the spec. If you only need occasional refresh, SSE or short polling can be cheaper than a graphql-ws cluster—an engineering trade-off, not a spec ruling.
Error Model: HTTP 2xx and JSON errors#
Why: When a session does not exist, the front end (Apollo) needs stable business errors, not only HTTP 4xx checks.
Mechanism and constraints:
- GraphQL spec — Errors: responses may contain both
dataanderrors; with field errors,datamay still be present (partial result). The spec does not mandate HTTP status codes. - GraphQL.org — Serving over HTTP: when non-null
dataexists, even witherrors, JSON responses should return 2xx (partial success). So “HTTP is often 200” is common practice; gateways that rewrite status codes need their own validation. - Spring: extend
DataFetcherExceptionResolverAdapterand attacherrorCodeviaGraphqlErrorBuilderextensions(Exceptions).
How:
@Component
class GraphQLExceptionResolver extends DataFetcherExceptionResolverAdapter {
@Override
protected GraphQLError resolveToSingleError(Throwable ex, DataFetchingEnvironment env) {
if (ex instanceof DJConsoleException dce) {
return GraphqlErrorBuilder.newError(env)
.message(ex.getMessage())
.extensions(Map.of("errorCode", dce.getCode()))
.build();
}
return super.resolveToSingleError(ex, env);
}
}
Service-layer orElseThrow(() -> new MixSessionNotFoundException(...)) flows through that resolver chain.
Common pitfalls: Assuming all GraphQL errors are HTTP 200; parse failures and missing data can still yield 4xx. REST-style response.ok checks without reading errors[0].extensions.
With curl against local /graphql, a query for a non-existent id (replace with actual schema fields) typically looks like:
curl -s -X POST http://localhost:8080/graphql \
-H 'Content-Type: application/json' \
-d '{"query":"query { currentMixSession { id } }"}'
The body may contain both "data": null and "errors": [{ "message": "...", "extensions": { "errorCode": "..." } }]; under default Spring Boot configuration HTTP status is often 200, but verify against your gateway and spring.graphql version—do not extrapolate to deployments not reproduced here.
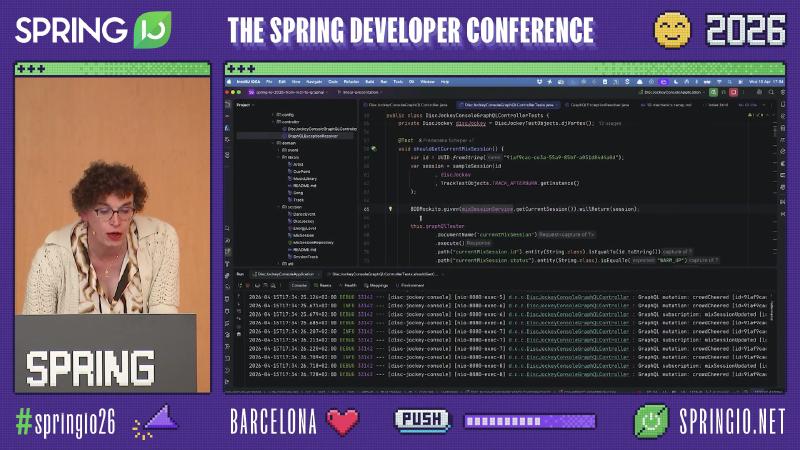
Testing and Layering: GraphQlTester and ArchUnit#
Why: Assert field paths without starting full HTTP/WebSocket; keep GraphQL types out of domain packages.
Mechanism and constraints:
@GraphQlTest(spring-boot-graphql-test) slices controller tests;GraphQlTesterdocumentNameloads.graphqldocuments from the classpath (e.g.graphql-test/).- Spring for GraphQL builds on GraphQL Java.
- ArchUnit package rules are demo constraints (Layer Checks), not built into Spring.
How:
@GraphQlTest(DiscJockeyConsoleGraphQLController.class)
class DiscJockeyConsoleGraphQLControllerTests {
@Autowired GraphQlTester graphQlTester;
@MockitoBean MixSessionService mixSessionService;
@Test void shouldGetCurrentMixSession() {
given(mixSessionService.getCurrentSession()).willReturn(session);
graphQlTester.documentName("currentMixSession").execute()
.path("currentMixSession.status").entity(String.class)
.isEqualTo("WARM_UP");
}
}
Common pitfalls: Only HTTP integration tests, no resolver paths; service modules importing org.springframework.graphql and silencing ArchUnit with @SuppressWarnings.
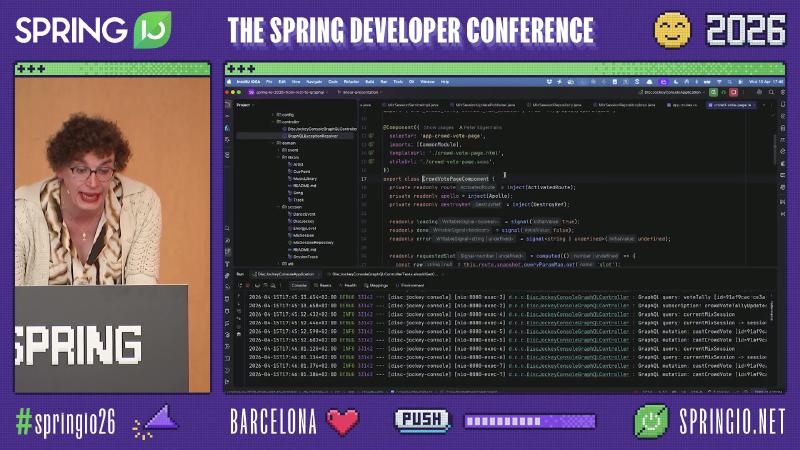
Front End: Micro-Frontends, Apollo, and One-Shot Vote Flow#
Why: The audience scans a QR code to open remote component CrowdVotePageComponent, reads slot from query params, loads the current session, then runs a vote mutation; stale cached sessions cause votes for the wrong slot.
Mechanism and constraints: Apollo Client fetchPolicy: 'no-cache' always hits the network and does not write to the Apollo cache (similar to network-only but ignores external cache updates). Route app-crowd-vote-page, mutation CAST_CROWD_VOTE, and exhaustMap / takeUntilDestroyed are demo code (binding to the voting scenario not verified from a single apollo-angular page).
How (structural sketch):
const slot = Number(this.route.snapshot.queryParamMap.get('slot'));
this.apollo.query({ query: CURRENT_MIX_SESSION, fetchPolicy: 'no-cache' })
.pipe(
take(1),
map(r => r.data?.currentMixSession),
filter((s): s is MixSession => !!s),
exhaustMap(session => this.apollo.mutate({
mutation: CAST_CROWD_VOTE,
variables: { id: session.id, slot },
})),
takeUntilDestroyed(this.destroyRef),
).subscribe();
Common pitfalls: Default cache-first on the vote page returning the previous session; mutation HTTP success without handling the GraphQL errors array.
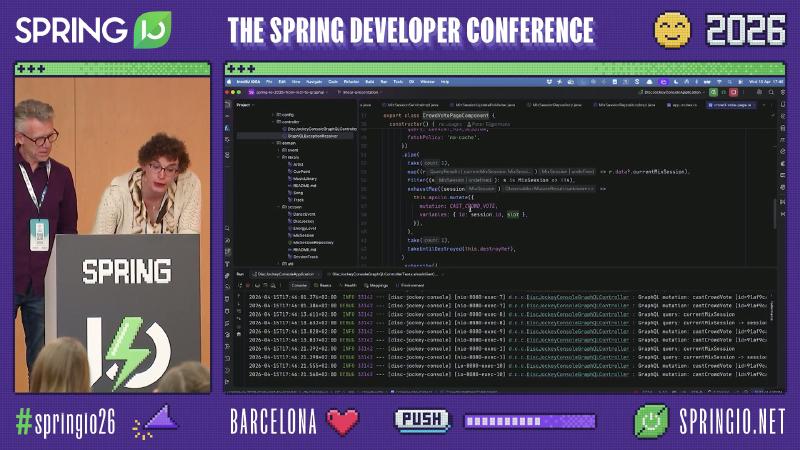
Before You Ship: Harden Subscriptions, Pagination, and Security Gaps#
Why: A working demo is not production survival. The speakers’ checklist (mostly speaker’s view, partly aligned with documentation spirit) includes: need HTTP caching → lean REST; no team learning time → do not force GraphQL; many consumers and additive schema → lean GraphQL; production pain points in subscription / pagination / @PreAuthorize—Spring Security was not demonstrated.
Mechanism and constraints (slides Before You Ship cross-checked with subtitles; verify items with your team):
- Subscription hardening: WebSocket auth after handshake often uses
connectionParamsfor tokens; reconnect needs graphql-ws plus snapshot replay (e.g.Flux.concat) to avoid stale UI; frame-level metrics need explicit instrumentation (e.g. Micrometer). - Pagination: Long lists should use cursors (
first/after); Spring GraphQL offersScrollSubrange,Window<T>, and related APIs (see references); the talk did not include an end-to-end example.

Closing#
GraphQL on Spring is about chaining schema contract, per-field DataFetchers, HTTP versus graphql-ws split, and a testable resolver layer; REST is not obsolete, especially where a single consumer and HTTP caching still win. If your case is multiple front ends, nested aggregation, and live push, Spring GraphQL offers a more consistent path than “one more BFF REST aggregate,” but subscription operations, pagination, security, and N+1 still need explicit design—left out of this demo on purpose, not solved automatically by the framework.
Unverified boundaries (explicit): The demo repository’s public Git URL was not in the verification materials; class and method names here come from on-site OCR/subtitle cross-check and may differ from a final open-source branch. DataLoader, cursor pagination, @PreAuthorize, and multi-replica Sinks broadcast were not implemented in the talk; copying demo code to production requires separate load, security, and contract-evolution review. REST Accept / vendor media-type versioning was not discussed in this session, so content negotiation for REST is not covered here.
References and Further Reading#
- Spring GraphQL reference documentation
- Spring Boot — Spring for GraphQL
- Spring GraphQL — Annotated Controllers
- Spring GraphQL — Transports (HTTP POST and WebSocket)
- Spring GraphQL — Exceptions and DataFetcherExceptionResolver
- Spring GraphQL — Testing and GraphQlTester
- GraphQL specification (October 2021)
- GraphQL specification — Field Deprecation
- GraphQL.org — Serving over HTTP (status codes and partial success)
- graphql-ws protocol (graphql-transport-ws)
- Reactor Core — Sinks API
- Apollo Client — Queries and fetchPolicy


