
Agentic RAG: When Retrieval Pipelines Grow a Planning-and-Tools Loop#
When engineering teams push RAG from demo to production, they often hit three tensions: latency (users want sub-second answers), controllability (failures must be locatable), and coverage (a single vector store cannot hold Slack, the web, and the warehouse). Around 2024, vendors such as Weaviate used Agentic RAG to name a class of designs: on top of retrieval, add an LLM plan → act → observe loop, use function calling to pick tools, and decide whether to keep fetching data. This article separates what is verifiable in public docs and papers from what remains architectural speculation in frontline interviews—without claiming one architecture rules them all.

Problem space: where agents, compound AI, and RAG meet#
Why talk about agents alongside RAG#
The Weaviate blog describes an agent as an LLM system with a role and task, using tools and short/long-term memory, able to plan, act, and adapt. That is not the same abstraction layer as Lewis et al.’s RAG model structure (parametric + non-parametric memory): the former is orchestration semantics, the latter generation architecture. When terms are mixed, teams argue in reviews whether something “counts as an agent” while skipping what actually must be decided: termination conditions, tool boundaries, and observability granularity.
Mechanisms and constraints: open loop vs fixed pipeline#
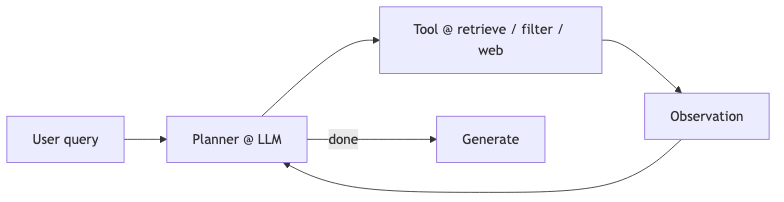
One implementation is a function calling loop: the model reads tool output → decides whether the task is done (often called an agent in interviews). Another is a compound AI system: prompts and tool order are fixed in the pipeline. Industry usage can swap the names; boundaries stay fuzzy (speaker opinion). For selection, fixed pipelines are usually easier to test for latency and regression; open loops are more flexible, but failure modes include multi-round idle spinning or stopping too early.
How to do it (minimal example)#
On an OpenAI-compatible stack, register vector search as a tool and let the model decide whether to call it—aligned with the blog’s “tool use, multi-step retrieval, and validation” direction:
tools = [{"type": "function", "function": {
"name": "search_weaviate",
"description": "Hybrid search over internal docs",
"parameters": {"type": "object", "properties": {"query": {"type": "string"}}},
}}]
# Loop: completion → if tool_calls → execute → append results to messages
Common pitfalls#
- Equating “can call APIs” with “has autonomy”—unregistered sources (e.g. Slack) will not be accessed automatically; the blog explicitly requires “use an API to retrieve … from Slack channels”.
- Debating nouns instead of SLOs: define p95 latency and max tool rounds first.
Vanilla RAG vs Agentic RAG: one-shot retrieval vs multi-step validation#
Why a single-shot pipeline is not enough#
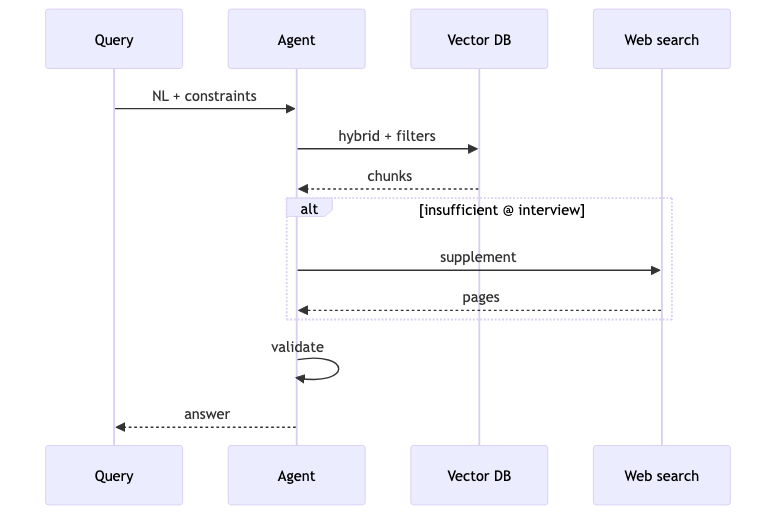
Weaviate FAQ (page JSON-LD) states: “Vanilla RAG is typically one-shot retrieval with limited tool access”; the article contrasts agentic behavior with “retrieve, evaluate, re-retrieve, and validate”. Common pain points: one semantic retrieval cannot fetch fragments with time/object constraints (e.g. “conversation with someone on 2024-01-10”), or the store is stale and needs web supplementation.
| Dimension | Vanilla (doc/interview summary) | Agentic (doc/interview summary) |
|---|---|---|
| Retrieval count | Usually once | Multi-step, can re-retrieve |
| Tools | Limited | Web, Slack API, warehouse, etc. must be registered explicitly |
| Query | Hard to auto metadata-filter | NL → filter + semantic (agent behavior: interview opinion) |
Mechanisms: what docs support vs what interviews add#
Verified: external tools include “web searches”; agents can use “routing/looping logic”. Not literal in the blog: a conditional “vector store insufficient → trigger web” branch (speaker opinion).
How to do it#
Weaviate Filters support including/excluding objects by property; Python v4 example:
filters = Filter.byProperty("round").equal("Double Jeopardy!")
Having an agent parse natural-language timestamps into Filter.byProperty("timestamp").greater_than(...) is a reasonable product path, but specific NL→filter behavior is not in the Agentic RAG blog body—write integration tests on your schema before deploy.
Common pitfalls#
- Equating Lewis et al.’s RAG model with a “retrieve–augment–generate three-step pipeline”—the paper is dense retrieval + generator, not product pipeline terminology.
- Assuming hybrid-search phrasing only hits blog chunks (interview demo path, not a doc guarantee).
Planning paradigms: CoT, ReAct, and Tree of Thoughts#
Why planning style shapes the cost curve#
The ReAct paper abstract notes models generate reasoning traces and task-specific actions in an interleaved way, tying reasoning and action together rather than as separate research threads. By contrast, Tree of Thoughts stresses “considering multiple different reasoning paths” and backtracking—on Game of 24 and similar tasks, large gains over CoT (paper reports CoT 4% vs ToT 74%, task-specific).
Mechanisms: literature wording vs colloquial split#
| Claim | Evidence |
|---|---|
| ReAct interleaves reasoning and action | ReAct abstract verified |
| CoT prone to hallucination; ReAct can correct via environment feedback | ReAct abstract verified |
| “CoT = initial decomposition, ReAct = iterative loop” | Interview summary; papers do not use those labels |
| ToT too heavy for online RAG | Speaker opinion; no RAG latency benchmark |
Host forcing thought in function schema ≈ ReAct | Unverifiable (no public schema) |
Both papers list Shunyu Yao among authors (checkable via arXiv metadata). The guest speculates OpenAI o1’s intermediate steps “look like ReAct” and mentions ReAct authors moving to OpenAI—guest’s own “it could be a theory” (unconfirmed).
How to do it#
ReAct prompt traces often use Thought / Action / Observation; in production you can require a rationale field before each tool call—spiritually similar to ReAct, not a paper algorithm reproduction.
Common pitfalls#
- Defaulting to ToT/MCTS in RAG: search trees are costly early; interviews favor ReAct “fix when wrong” as lighter (no benchmark numbers).
- Treating RL analogies (action = function call, next state = tool return) as validated RAG training—mostly heuristic architecture talk (speaker opinion).
Multi-agent: orchestration, parallelism, and heterogeneous models#
Why one agent cannot carry multi-domain knowledge#
The Weaviate blog has a Multi-agent RAG Systems section on single-agent limits. The dominant interview shape (speaker opinion): a top orchestrator schedules sub-agents in parallel by collection/topic/tool; sub-agents can bind smaller LLMs (e.g. Llama 3 8B per store, GPT-4o/o1 for synthesis). Blog HTML has no “parallel” string, only “orchestrate its components”—parallel scheduling is interview architecture advice.
Analogy to DSPy: multiple roles like signatures limiting “only this slice” (not formal equivalence). When OpenAI Swarm is named, note the README says the project was superseded by the OpenAI Agents SDK—experimental/educational; a Nov 2024 recording may still discuss Swarm.
How to do it#
Three logical layers suffice for a first validation:
- Router agent: decompose sub-questions (see LlamaIndex Sub Question Query Engine—docs say it “breaks down the complex query into sub questions”).
- Worker agents: each bound to one tool set + one collection.
- Synthesizer: merge sub-answers and check consistency.
Common pitfalls#
- Multi-agent = stacking full system prompts → cost and conflict grow exponentially; share a trace id.
- Naming CrewAI/AutoGen as Weaviate’s official recommended stack (this episode has no benchmark data).
Memory: Letta, vector stores, and “memory as tool vs substrate”#
Why RAG is not enough for identity and role changes#
Letta (formerly MemGPT) targets hierarchical memory and “virtual context management”, supporting remember/reflect/evolve across sessions. The interview distinguishes: short-term in the prompt (including tool returns); long-term updated by Letta in dialogue (identity/role-change scenarios: speaker opinion). Versus DSPy optimizing prompts/weights, Letta leans on runtime memory block evolution (Memory concepts lists Archival memory, Context hierarchy, etc.—read dedicated docs for write mechanics).
Open architecture (speaker opinion, Nov 2024 context): is the vector store long-term memory storage or a tool the agent calls? The host leans toward Agentic RAG on the agent’s internal memory; Weaviate × Letta integration was still incomplete.
Common pitfalls#
- Dumping all history into a vector store as “long-term memory”—without layering and eviction, retrieval quality collapses.
- Assuming Letta and Weaviate are one-click integrated (product integration not finished).
Observability and evaluation: traces before “feels fine”#
Why agent systems must be traceable first#
Agent chains are slow and multi-step; without a “still running” signal, ops and users assume a hang. Arize Phoenix documents receiving OTLP traces via OpenTelemetry and LLM-as-a-judge evaluators. Google Vertex AI Agent Builder covers Observability, Unified Trace Viewer, etc.—partially aligned with the podcast’s “decomposed steps UX” (specific UI not frame-by-frame verified).
Mechanisms: minimal observability set#
Per user request, at least log: plan_id, tool_name, latency_ms, retrieved_ids, token_usage, final_stop_reason. That matches the blog’s “validation” loop—otherwise you cannot answer whether failure was retrieval or generation.
Common pitfalls#
- Watching answer BLEU/ROUGE only, not which step returned empty tool output.
- Treating demo step bars as production-grade traces (interview UX opinion).
LLM-as-Judge and “More Agents”: what papers actually support#
Why judge models are unreliable (interview side)#
The guest argues the industry overestimates LLM-as-judge: temperature often unset, same prompt drifts across runs (engineering observation, no primary paper). The host cites Nils Reimers: using OpenAI to score Cohere introduces model bias; GPT-4o can detect same-family style (secondhand, not reproduced).
More Agents Is All You Need (arXiv:2402.05120)#
Verified: proposes sampling-and-voting (AgentForest codebase), tasks include GSM, MATH, MMLU, Chess, HumanEval; performance ties to task difficulty (intrinsic difficulty, reasoning steps, prior probability, etc.).
Unverified / inconsistent with interview:
| Interview claim | Paper reality |
|---|---|
| ~25 samples | Analysis uses sampling 40 times, etc.; no universal “25” recommendation |
| easy/hard chemistry/physics | Paper has no chemistry/physics keywords |
| More sampling useless for hard problems with judge | Paper is not an LLM-as-judge setup |
| ~20 samples steadier in judge scenarios | Interview opinion |
Do not cite the paper for chemistry/physics easy-hard unless you have another source. The guest sees diminishing returns on agent count (speaker opinion; paper discusses scaling, not judge-specific curves).
Common pitfalls#
- Equating “multiple samples for scoring” with HumanEval pass@k without reading task definitions.
- Using one judge model across vendors without human label baselines.
Long tasks, synthetic data, and the generative feedback loop#
Why some workloads accept multi-hour waits#
Q&A hybrid search fits second-scale RAG; STORM (“researches a topic and generates a full-length report with citations”) and multi-layer DSPy pipelines (interview: research→outline→content→title) are slow paths—many tool steps, self-checks, citations. Interview GFL (generative feedback loop): agents loop between web + Weaviate producing synthetic data/labels, with autonomy possibly beating “RAG-only generation” (no controlled experiment; Weaviate Agentic RAG blog has no GFL mention).
The host proposes “nested GFL”: paper-style tasks write code/experiment results back to the store while the agent relies on GFL for intermediate state (architecture proposal, not a product commitment). The guest stresses human-in-the-loop and being able to “pull the plug”—echoing 2023 Auto-GPT backlash (speaker opinion).
Common pitfalls#
- Expecting chatbot latency from STORM-class report systems.
- Treating a four-layer DSPy stack as paper-mandated stages (interview demo summary; the DSPy paper emphasizes compiling declarative LM calls and self-improving pipelines, not that four-stage blog program).

Techniques for Building Better Agent Systems, evaluate_agents(, type="AI", scope="Agent Systems", Erika Cardenas, Arize / LlamaIndex / AutoGen logos (not mid-episode architecture slides).
If you are shipping this#
- Pin the tool list and privacy boundary first: register only allowed sources; define schema with Filters, then let the planner emit filters—and write regression cases for NL→filter (the blog does not guarantee automatic agent parsing).
- Set loop budgets: max tool rounds, p95 latency, stop conditions (empty results, repeated queries, confidence thresholds); land traces in Phoenix or an OTLP backend.
- Tier by workload: second-scale Q&A via one-shot / light hybrid; multi-step research via ReAct + validation; use ToT sparingly unless offline compute and eval sets prove benefit.
- Split evaluation layers: retrieval (MRR, nDCG) vs end-to-end (human + sampling); if using LLM-as-judge, fix temperature, log judge model version, do not copy More Agents’ chemistry/physics narrative.
- Validate multi-agent serially before parallel: the blog does not promise parallelism; heterogeneous small-model sub-agents are a cost play—prove with your own QPS and quality curves.
References and further reading#
- Weaviate — What Is Agentic RAG? — Agentic vs vanilla, multi-agent, tool loop anchor
- Weaviate — Query Filters — Property filter API and examples
- Lewis et al. — Retrieval-Augmented Generation (arXiv:2005.11401) — Foundational RAG (model-level definition)
- ReAct — Synergizing Reasoning and Acting (arXiv:2210.03629) — Interleaved reasoning and action
- Tree of Thoughts (arXiv:2305.10601) — Multiple paths and backtracking
- LlamaIndex — Sub Question Query Engine — Sub-question decomposition retrieval
- OpenAI — Function calling guide — Tool schema and loop integration
- DSPy — Compiling Declarative LM Calls (arXiv:2310.03714) — Declarative pipelines and optimization
- MemGPT — arXiv:2310.08560 — Hierarchical memory and virtual context
- Letta — GitHub — MemGPT successor
- Letta — Memory concepts — Memory blocks / Archival memory
- STORM — stanford-oval/storm — Long cited report generation
- More Agents Is All You Need — arXiv:2402.05120 — Sampling-and-voting / Agent Forest
- Agent Forest — GitHub — Paper reference implementation
- Arize Phoenix — LLM Traces — OTLP and OpenTelemetry
- Google Cloud — Vertex AI Agent Builder overview — Agent platform and observability
Product capabilities and paper conclusions change with versions; interview items such as parallel orchestration, NL→filter trigger chains, GFL, and o1–ReAct speculation should be re-tested on your data and traces before deploy.


