
Agentic Topic Modeling: Embedding Pipelines, LLMs, and Human-in-the-Loop Engineering Trade-offs#
“Topics” over large corpora are no longer the exclusive domain of LDA bag-of-words era. Vector search, RAG, and agent toolchains have pushed document-level embeddings to center stage, yet operations still need browsable, filterable, iterable topic-layer metadata—supporting analysts reading reports and serving as a coarse index at million-document scale. Recent discussions often place agentic topic modeling alongside TopicGPT and BERTopic; stripping away podcast narrative, the core tension is a three-way trade-off among static embedding clustering, LLMs maintaining topic tables and assigning documents, and human-in-the-loop steering of granularity in natural language. Below is organized by engineering themes; evidence follows official docs and papers. Figures and product throughput not found in primary sources are labeled speaker/host view.
Problem space: what role topics play in the RAG stack#
Why: Pure document-embedding retrieval is already strong semantically, but users still ask “what are these complaints mainly about?” and “what new issues appeared last quarter?”—that needs mid-level structure between full text and single sentences. A well-built topic layer can act as metadata partitions on a vector store or as the first hop in two-stage retrieval; a poor one introduces wrong priors and is worse than none.
Mechanisms/constraints: “Topic” has no unique form—it may be BERTopic c-TF-IDF keyword lists, or natural-language labels and descriptions in the TopicGPT style. Speaker view: presentation is highly subjective; there is no universally “correct topic.”
How to proceed: Architecturally decouple topic production from downstream consumers—first define consumers (analyst UI, retrieval router, evaluation pipeline), then choose representation (word weights vs LLM summaries vs hierarchy).
Common pitfall: Equating “topic” with “one LLM-generated headline”; without comparable scores, the eye over-trusts fluent wording (see Evaluation below).
Modular embedding pipeline: swappable building blocks#
Why: Embedding models, clusterers, and dimensionality reducers iterate quickly; if topic modeling is bound to one stack, every swap of SentenceTransformer or density clusterer rewrites the pipeline.
Mechanisms/constraints: The BERTopic algorithm page describes five steps: Embeddings → Dimensionality Reduction → Clustering → Tokenizer → c-TF-IDF (class-based TF-IDF) → optional Representation. Each step is replaceable; arXiv:2203.05794 likewise states: cluster document embeddings, then generate topic representations with class-based TF-IDF.
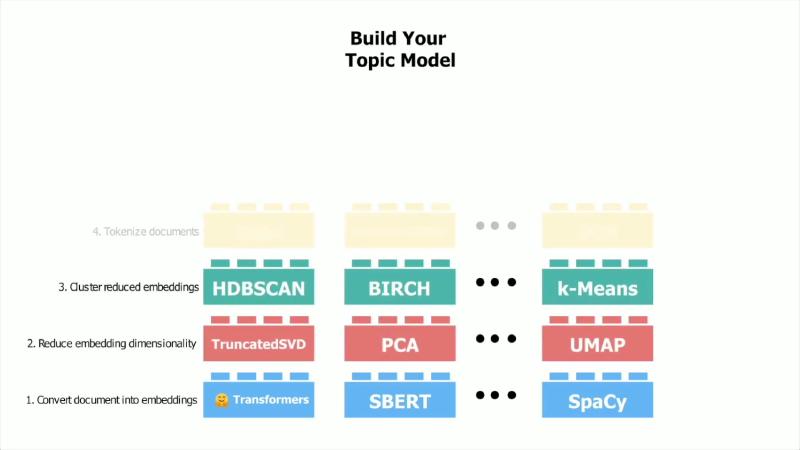
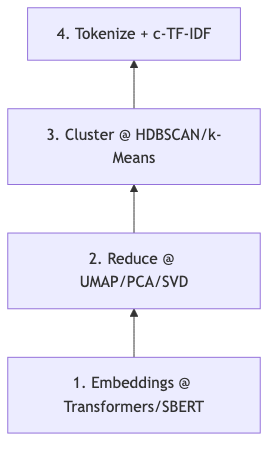
How to proceed (minimal example, aligned with official defaults):
from bertopic import BERTopic
from umap import UMAP
import hdbscan
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric="cosine")
hdbscan_model = hdbscan.HDBSCAN(min_cluster_size=15)
topic_model = BERTopic(umap_model=umap_model, hdbscan_model=hdbscan_model)
topics, probs = topic_model.fit_transform(docs)
Common pitfall: Treating presentation 2D scatter plots as the true clustering space. Official examples use n_components=5; 5–10 dimensions is the guest’s experience range, not UMAP’s documented default (UMAP parameters). 2D DataMapPlot suits narrative; when explaining cluster composition, return to high-dimensional space, word weights, and sample documents.
LLM-native topic discovery: TopicGPT and TnT-LLM#
Why: Clustering + c-TF-IDF topic words skew toward “statistically salient,” not necessarily business language; LLMs can emit readable labels and hierarchical taxonomies directly.
Mechanisms/constraints:
- TopicGPT (arXiv:2311.01449): prompt framework using LLMs to discover latent topics (natural-language labels + descriptions); README includes
generate_topic_lvl1,refine_topics,assign_topics, etc.—generation and assignment separated. - TnT-LLM (arXiv:2403.12173): two-phase—phase one generates/refines a label taxonomy, phase two trains a lightweight classifier with LLM labels for scale assignment.
Speaker view: Repeated per-document LLM calls over the full corpus are wasteful; safer is embedding pre-clustering + LLM for guidance or top-level summaries. If inference cost nears zero, a full-corpus LLM inspector is logically plausible—then embeddings may retreat to visualization and hierarchical analysis (conditional forward look, no benchmark).
How to proceed: Export the LLM topic table as label vector y, plug into BERTopic supervised/semi-supervised paths (next section), rather than starting over.
Common pitfall: Assuming TopicGPT and BERTopic are structurally incompatible; the guest argues TopicGPT topics can be fed back into BERTopic for inference and visualization (interview workflow; capability supported by Supervised / Semi-supervised).
Decoupling assignment and generation#
Why: Rewriting the representation layer over the full corpus with LLMs is expensive; “split 100k documents into 200 clusters” and “write one human-readable title per cluster” have different compute shapes.
Mechanisms/constraints: BERTopic does assignment (clustering) first, then generation (c-TF-IDF and optional Representation models). TopicGPT / TnT-LLM also separate topic generation from assignment. Speaker view: iterating representation touches only topic-count volume—cheap vs full-corpus LLM—“~1% of data” is order-of-magnitude intuition, no primary formula; do not cite as paper data.
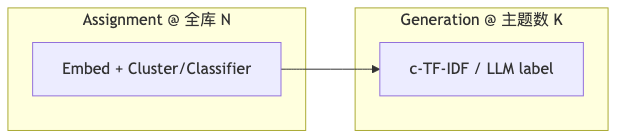
How to proceed: After fixing assignment, only replace representation_model or rerun c-TF-IDF; avoid recomputing UMAP/HDBSCAN.
Common pitfall: One end-to-end prompt for both assignment and naming, preventing separate evaluation of “assignment correct?” vs “name sounds good.”
“Agentic”: tool use, human-in-the-loop, and granularity#
Why: In enterprise settings the biggest friction is often not the algorithm but granularity—too coarse misses sub-issues, too fine fails to align with retrieval agents.
Mechanisms/constraints: In this episode, agentic topic modeling ≈ tool calling + human-in-the-loop + natural-language steer, not a formal definition from a generic agent framework (interview view). Speaker view: the flow remains user-driven; stronger models still will not guess the granularity you want. Host adds: too much choice causes choice overload—humans excel at limited options (e.g. “merge Topic 3 and 7,” “only 12 top-level topics”).
How to proceed: Design agent interfaces as propose–confirm loops: system outputs candidate topics and sample documents → user issues structured merge/split/rename instructions → trigger semi-supervised re-clustering or representation-only rerun.
Common pitfall: Equating “LLM that can call APIs” with “automatically converges to business-satisfying topics”; ignoring hierarchy vs single-layer retrieval agents—speaker view: retrieval can ignore hierarchy and use fine-grained topic metadata; host argues hierarchy adds interface complexity with query agents (no unified conclusion from either).
Clustering choices: HDBSCAN, k-means, and parameter trial#
Why: Density clustering finds arbitrary shapes and labels noise, but hyperparameters are opaque; k-means fixes K, easing comparison of neighboring clusters with LLMs.
Mechanisms/constraints: HDBSCAN min_cluster_size is the smallest grouping still treated as a cluster; increasing it tends toward larger, fewer clusters, but total cluster count still needs experiments—not a direct “I want K topics” knob. Speaker view: min_cluster_size is hard to set a priori—main enterprise friction; some switch to k-means + post-hoc density filtering (preference statement; HDBSCAN docs do not discuss this).
How to proceed:
import hdbscan
clusterer = hdbscan.HDBSCAN(min_cluster_size=30, min_samples=10)
labels = clusterer.fit_predict(reduced_embeddings)
For k-means, LLMs can read keyword differences between adjacent clusters to help pick K (interview idea, not verified against k-LLM-means or similar).
Common pitfall: Recursive HDBSCAN on sub-clusters yields stable hierarchy—guest finds sub-cluster parameters sensitive and hard to maintain in practice (speaker view).
c-TF-IDF: cluster contrast and readable scores#
Why: A single LLM headline lacks cross-topic comparable scores; analysts struggle to judge “how much does this word belong to this topic?”
Mechanisms/constraints: ClassTfidfTransformer treats each cluster as one “class document,” l1-normalized term frequency × IDF, highlighting words unique to this cluster vs others; the paper calls it a class-based variation of TF-IDF (arXiv:2203.05794). Speaker view: analogous to simple “contrastive learning”; opposes word clouds—font size misleads human weight perception, so BERTopic visualization omits word clouds (product behavior matches oral account; official page does not literally say “opposes word clouds”).
How to proceed: Expose term score ranked lists in UI, not area-encoded word clouds alone.
Common pitfall: Stopping at a fluent LLM topic name without reading representative documents.
Evaluation: automated coherence vs “topics users want”#
Why: Offline metrics screen models, but classic topic coherence on neural/embedding topic models may diverge from human judgment.
Mechanisms/constraints:
- Are Neural Topic Models Broken? (arXiv:2210.16162): neural topic models may trail classic LDA on stability and alignment with human categories.
- Is Automated Topic Model Evaluation Broken? (arXiv:2107.02173): automated coherence disagrees with topic rating / word intrusion.
- Revisiting Automated Topic Model Evaluation with LLMs (arXiv:2305.12152): LLM judges correlate with humans more than some traditional automatic metrics.
The podcast’s spoken title “are neural topic modeling evaluation metrics broken?” does not match the exact arXiv titles above—cite arXiv titles in writing. On-screen overlay ProxAnn: Use-Oriented Evaluations… aligns with use-oriented evaluation; distinct from O’Reilly Hands-On Large Language Models (Jay Alammar & Maarten Grootendorst).

Speaker view: coherent + diverse may still miss business-relevant dimensions; add user constraints (minimum topic count, must cover a class, banned words).
Common pitfall: Model selection from a single NPMI/coherence leaderboard; no human document reading or task-oriented (use-oriented) evaluation.

Retrieval acceleration: two-stage and IVF analogy#
Why: Million documents × full-corpus vector ANN is costly; if documents carry topic IDs, shrink the candidate set first.
Mechanisms/constraints: Speaker view: retrieve Top-K topic embeddings first, then document-level search within relevant topics; semantic overlap with pure embedding search may exist, but speed is the clear benefit. Host verbally estimates ~5% of documents enter stage two—no benchmark, unverified. Analogous to FAISS IndexIVF coarse quantization; Weaviate vector index docs list HNSW / flat, not IVF as primary framing—state the analogy explicitly.
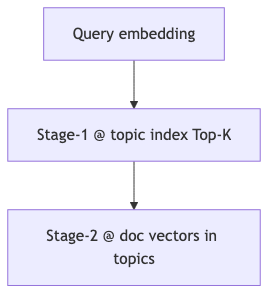
How to proceed: Build a separate embedding index for topic labels/descriptions; write topic_id metadata on document objects; measure two-stage recall on a held-out query set.
Common pitfall: Shipping without measuring two-stage recall loss; treating 5% as a universal speedup ratio.
Hybrid pipelines: Supervised and Semi-supervised BERTopic#
Why: When TopicGPT labels or a business taxonomy already exist, HDBSCAN need not “rediscover” from scratch.
Mechanisms/constraints:
- Supervised BERTopic: skip dimensionality reduction, use a classifier instead of clustering, then run c-TF-IDF on labels. Speaker view: called a “hack,” but simple and effective.
- Semi-supervised: partial labels drive semi-supervised UMAP, then HDBSCAN;
fit(docs, y=...), unlabeled may use -1. - Serialization:
safetensorsdoes not save clustering/dimensionality weights; inference can rely on topic embeddings; Dynamic Topic Modeling can slide c-TF-IDF per time slice without re-running clustering.
How to proceed:
# External labels already available (e.g. TopicGPT output)
topic_model = BERTopic(umap_model=None, hdbscan_model=your_classifier)
topic_model.fit(docs, y=labels)
topic_model.save("model_dir", serialization="safetensors")
Semi-supervised: pass y for known-topic documents so UMAP supervised guides the manifold, then cluster.
Common pitfall: Expecting supervised mode to “fix wrong labels”—it assumes assignment is given and only rebuilds representation and inference interface.

Unresolved tensions (no need to force unity)#
| Axis | Common approach | Other pole in guest/discussion | Evidence status |
|---|---|---|---|
| Main route | Embed → UMAP → HDBSCAN → c-TF-IDF | Full-corpus LLM TopicGPT-style assignment | Embedding route has official docs; full-corpus LLM cost argument is interview |
| Hierarchy vs single layer | Hierarchical BERTopic / TopicGPT lvl2 | Single layer + fine-grained metadata for retrieval | Both sides’ views, no experimental comparison |
| Evaluation | NPMI / coherence | LLM-as-judge + human | See 2107.02173, 2305.12152 |
| Agent definition | Fixed DAG workflow | Tool use + human-in-the-loop | Interview view |

If you are shipping this#
- Define consumers first: analysts reading reports, retrieval router, or offline evaluation—then choose “word-weight topics” vs “LLM label topics”; avoid end-to-end black boxes.
- Default to modular BERTopic: start with
n_components=5(official example); 2D plots for narrative only; QA with c-TF-IDF scores + sample documents, not LLM titles alone. - Put LLMs on generation or guidance: after TopicGPT/TnT-LLM produce
y, plug in via Supervised/Semi-supervised; estimate cost before repeated full-corpus assign. - Layer task constraints on evaluation: beyond coherence critique and LLM judging, add business rules like “must cover class,” “minimum topic count”; cite papers by exact arXiv titles.
- Measure recall before two-stage retrieval: topic Top-K cascaded with document ANN needs held-out query validation; do not use unverified 5% document share for capacity planning.
References and further reading#
- BERTopic official documentation — modular topic modeling entry point
- BERTopic algorithm overview — five-step pipeline and default components
- BERTopic paper arXiv:2203.05794 — class-based TF-IDF and clustering flow
- TopicGPT arXiv:2311.01449 — prompt-based topic discovery and assignment
- TnT-LLM arXiv:2403.12173 — two-phase taxonomy and lightweight classifier
- Supervised BERTopic — external labels skip clustering
- Semi-supervised BERTopic — label-guided UMAP then clustering
- BERTopic safetensors serialization — inference without saving reduction/clustering weights
- UMAP supervised dimensionality reduction —
yandtarget_metric - HDBSCAN parameter selection —
min_cluster_sizesemantics - Are Neural Topic Models Broken? arXiv:2210.16162 — neural topic model stability and alignment
- Is Automated Topic Model Evaluation Broken? arXiv:2107.02173 — coherence vs human judgment mismatch
- Revisiting Topic Model Evaluation with LLMs arXiv:2305.12152 — LLM-as-judge vs human correlation
- ProxAnn arXiv:2507.00828 — use-oriented topic model evaluation
- Hands-On Large Language Models (O’Reilly) — Jay Alammar & Maarten Grootendorst


