
Engineering Trade-offs in Retrieval Embeddings: Leaderboards, Training, and Production Constraints via Arctic Embed#
Vector retrieval quality is often largely decided at the step of swapping embeddings—at least that is how bluntly engineers on both the Snowflake and Weaviate sides put it in public discussion. This article, centered on the Snowflake Arctic Embed family (including the Arctic Embed 2.0 technical report), covers how to read leaderboards, what contrastive pre-training and fine-tuning each solve, how Matryoshka representation learning (MRL) lands at billion-scale indexes, and the fracture between multilingual benchmarks and proprietary distributions. Numbers are aligned first with arXiv and official READMEs where possible; internal benchmarks, cost estimates, and some experiential conclusions are labeled speaker opinion, with boundaries noted where independent reproduction is not possible.
Problem space: where embeddings sit in RAG#
Why: In retrieval-augmented generation (RAG) and agent tool chains, a common path is query → dense (or hybrid) retrieval → reranking → context assembly → LLM. Embeddings compress text into fixed-dimension vectors; the index side recalls candidates with approximate nearest-neighbor structures such as HNSW. Once vector semantics misalign with business phrasing, downstream cross-encoder reranking can only rank within the wrong candidate set.
Mechanism / constraints: Snowflake uses Arctic Embed in its own Cortex Search and aligns open weights with that stack; Weaviate lists hosted options including Snowflake/snowflake-arctic-embed-m-v1.5 and Snowflake/snowflake-arctic-embed-l-v2.0 on its Cloud Embeddings models page. Product motivation: third-party embedding API rate limits, dimensions, and billing models are tightly coupled to vector-database index parameters.
How to (minimal example): When a Weaviate collection uses a hosted Arctic model as vectorizer, vectorIndexConfig dimension must match model output; if you plan MRL truncation, agree on the same prefix dimension on both ingest and query (see below).
Common pitfall: Treating “swap in a bigger LLM” as the main lever for retrieval quality. Speaker opinion (early Snowflake internal search tuning): tuning synonyms, fusion, and rerankers helps, but changing the embedding often has the largest impact—that claim cannot be verified with public Cortex Search A/B tables; treat it as a hypothesis, not a theorem.

Leaderboard literacy: what MTEB, BEIR, and MIRACL each measure#
Why: Engineers often scan the MTEB leaderboard when choosing models. MTEB spans eight task families including classification, clustering, and retrieval; the average across all tasks is not equivalent to “our system only does passage retrieval.” The Snowflake team repeatedly stresses: if your workload is BEIR-style in-task retrieval, watch nDCG@10 on MTEB Retrieval (often written MTEB-R), not the overall average.
Mechanism / constraints:
| Benchmark | Typical metric | Distribution traits | When reading the board |
|---|---|---|---|
| BEIR | nDCG@10, etc. | Heterogeneous zero-shot IR, cross-domain | Originally to test cross-domain generalization; the community now often mixes MS MARCO, NQ, and other training sets (speakers criticize: easy to become “fitting the test set”) |
| MTEB-R | nDCG@10 | Retrieval subset overlapping BEIR | Arctic papers report mainly this column |
| MIRACL | nDCG@10, 18 languages | Wikipedia passages | 2.0 authors note training also used MIRACL-related data; do not treat as the sole multilingual truth |
How to: Align evaluation scripts with the paper—e.g. Arctic Embed 2.0 Large full-dimension MTEB-R 0.556, 256-d truncation 0.547 (Table 1, about 98.4% retained). Colloquial “98% recall” in the literature is actually retention of MTEB-R nDCG@10 relative to full dimension, not recall@k.
Common pitfalls:
- Picking a model by MIRACL 18-language average but deploying on out-of-domain corpora—news, tickets, codebases—where 2.0’s gap on out-of-domain sets such as CLEF relative to MIRACL is described in the paper as suggesting potential overfitting, not an accusation of cheating.
- Treating 1–2 point leaderboard gaps without checking whether prompt templates, pooling, and normalization match the paper (speaker opinion: apples-to-oranges comparisons are common).
Pre-training: E5-style contrastive learning and batch engineering#
Why: Generic sentence vectors trained only with token-level MLM are weakly aligned for retrieval. The E5 line uses weakly supervised InfoNCE + in-batch negatives on query–document pairs; Arctic 1.0/2.0 describe closely replicating that paradigm; the README cites on the order of 400 million pre-training pairs.
Mechanism / constraints (verifiable parts):
- Batch size: 2.0 reports 32,768, 32×H100 data parallel (§2 / Appendix); interview phrasing “about 32k” matches the paper.
- Source stratification (1.0 §4.4): each minibatch contains only one data source; Table 5 at batch 16,384 shows stratify Yes → 46.96 vs No → 43.74 nDCG@10 (MTEB-R subset). 2.0 also treats different language subsets as sources. The paper cites prior work with single-source minibatches—call it an Arctic systematic ablation, not a global first.
- Negatives: Pre-training relies mainly on large-batch random in-batch negatives (speaker opinion); curated hard negatives matter most in fine-tuning.
How to (conceptual): When reproducing, fix stratify switch and batch scale before swapping backbone; clustering-style pre-training appears in preprint 2407.18887, but the main report finds smaller gain than stratification.
Common pitfall: Taking interview “4k→8k→16k keeps improving” as the 2.0 paper curve—1.0 Table 5 has 4,096 vs 16,384 only; a full three-point curve was not found in published text and may come from internal runs or retelling of E5/BGE. Modal full pre-training ~$2,000 is an interview estimate, not reproducible here.
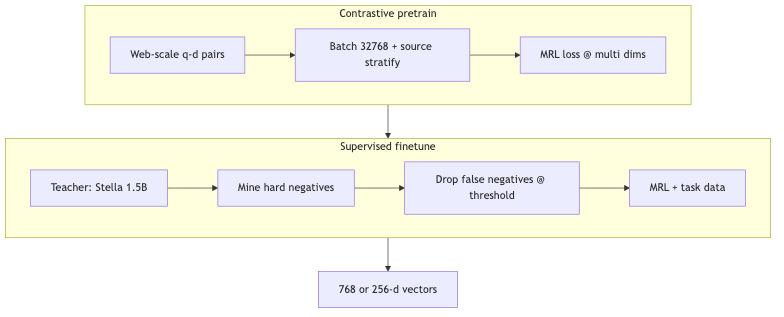
Fine-tuning 2.0: teacher, false negatives, and curriculum’s negative result#
Why: Pre-training gives a general geometry; domain retrieval often needs fine-tuning to pull query–positive pairs closer and push hard negatives away.
Mechanism / constraints (2412.04506 §2.4, verified):
- Teacher models: English uses
stella-en-1.5B-v5(HF:dunzhang/stella_en_1.5B_v5), stronger thangte-large-en-v1.5; multilingual side usesmultilingual-e5-large, etc. - False-negative filtering: Follows NV-Retriever (do not confuse with NV-Embed)—drop candidate negatives if score exceeds a percentile threshold of the known positive (Figure 2 scans 95%–99%) so truly relevant docs are not trained as negatives.
- Curriculum learning: The paper states random data ordering produced comparable or better results—contrasting with 1.0/1.5-era “curriculum hard negatives ~+0.5 MTEB-R.”
Speaker opinion: upgrading to a stronger single teacher can yield gains on the order of fine-tuning’s “10× scaling law”; versus NV-Embed-style multi-teacher ensembles, the team chose a simpler single teacher (ensemble gains in that paper are also limited—comparative statement, not reproduced here).
How to: In a custom fine-tune pipeline, at minimum implement (1) teacher scoring to mine negatives, (2) false-negative filtering by fraction of known-positive score, (3) fixed random order as ablation baseline before curriculum.
Common pitfall: Stacking curriculum on 2.0 without upgrading teacher and thresholds—may be wasted effort. When citing hard-negative pipelines, link NV-Retriever (2407.15831).
MRL and production: dimension, memory, and metric definitions#
Why: Matryoshka Representation Learning (MRL) trains so prefix subvectors remain useful at each truncated dimension, enabling 256 dimensions on the index for ~4× storage and HNSW memory while preserving ranking quality where possible.
Mechanism / constraints:
- 2.0: MRL through both contrastive pretraining and finetuning beats MRL only in fine-tune, which beats “truncate without MRL” (§2.5). Large model 768→256 retains ~98% MTEB-R nDCG@10; vs Google text-embedding-004 truncation ~94% (2.0 cites third party; not a direct full replication of Gecko).
- Weaviate Resource Planning: HNSW indexes must reside in memory;
vectorCacheMaxObjectscaps cached vectors. At billion scale, 7B-class embeddings for 2× quality that consume the memory budget often lose to MRL dimension reduction + optional PQ rescore (speaker opinion: full-precision vectors may still be kept because query prefix dimension is unknown). - Speaker opinion (no public table): After MRL truncation, recall@k drops slowly, nDCG@10 drops more—“low dim still finds hits, ranking is noisier.” The paper does not report recall@k comparisons; keep metrics separate in writing.
How to: Index dimension d_index=256, same truncation for query and document; if using quantized index, rescore candidates on disk then refine with full vectors (product stacks vary).
Common pitfall: Reading “98% retention” as unchanged recall@10. Also: MRL fine-tune after only ~30% of planned pre-training hurts—Puxuan’s development experience (interview); literature direction agrees but there is no public “30%” table.
Multilingual: transfer, over-training, and the “omnilingual” illusion#
Why: Enterprise corpora mix English, Chinese, Japanese, Spanish, etc.; one multilingual model avoids ops split “English stack vs multilingual stack.” Industry default assumes multilingual sacrifices English MTEB; Arctic Embed 2.0 reports English MTEB-R close to strong English-only baselines (Table 1: 2.0-M 0.554 vs 1.0-M 0.549), but the team admits they do not fully understand why a single model does not hurt English (interview opinion).
Mechanism / constraints (partly verifiable):
- Figure 3 / §4.1: As contrastive pre-training steps increase, languages absent from pre-training (e.g. zh, ja) on MIRACL can show negative cross-lingual transfer (e.g. zh after finetune nDCG@10 change -13.3% per figure captions). Conclusion: prolonged contrastive pretraining does not always enhance cross-lingual transfer.
- Figure 4: Adding Chinese to pre-training can raise English MTEB-R—addressing “over-training on non-target languages,” not “Chinese necessarily hurts English.”
- MIRACL vs proprietary sets: Puxuan cites unpublished out-of-training evaluation where many open multilingual models are strong on MIRACL, clearly worse on proprietary sets (not verifiable). Luke moderates: do not directly accuse overfitting, but vs Wikipedia distribution and commercial models like Gecko, ~100M open checkpoints can score much higher on MIRACL averages while trailing English MTEB-R by 2–5 points (interview + third-party tables; Gecko full table not recomputed here).
How to: For Chinese–English customers only, evaluate on customer-domain hold-out, not MIRACL alone; if Japanese was not in pre-training, monitor whether over-long pretraining degrades Japanese queries. Speaker estimate “halving pre-training still pretty decent”—no published ratio.
Common pitfall: Treating multilingual as omnilingual; MIRACL 18-language average does not represent tickets, regulation, or code comments.
Architecture fork: single-vector HNSW vs ColBERT / SPLADE / reranking#
Why: Multi-vector (ColBERT), sparse (SPLADE), and cross-encoder reranking can raise ceilings in theory but add storage, latency, and engineering complexity.
Mechanism / constraints (mostly interview opinion; no Arctic public ablation table):
- Snowflake Cortex Search targets large-scale single-vector + HNSW; Luke says ColBERT is stronger but implementation and storage cost are high.
- After strong dense neural retrieval, stacking SPLADE often shows marginal gain (internal pre-project experiments, unpublished).
- Weaviate’s path: modular vector database + optional hosted embeddings, avoiding a single black-box search stack.
How to: Default to single-vector + optional cross-encoder rerank; adopt ColBERT-class schemes only when recall is the bottleneck and the team can bear index complexity.
Common pitfall: Shipping leaderboard 7B embeddings to production—eval leakage, inference cost, and HNSW memory may not pay off. Speaker “hot take”: if pre-training alone reaches fine-tune-level hard-negative quality, 7B training jobs may look wasteful—strongly subjective, not consensus.
Trust boundary: “understand the model” vs “understand the provider”#
Why: Whether open weights match hosted APIs affects RAG supply-chain audit.
Mechanism / constraints: Snowflake claims Cortex Search shares the same model family as open Arctic Embed; Weaviate Cloud Embeddings lists Arctic SKUs. Charles’s argument: a provider using the same embedding in production retrieval builds more trust than leaderboard score alone—product ethics and organizational behavior, not a reproducible theorem.
Common pitfall: Choosing models by leaderboard only, ignoring training/eval overlap (2.0’s MIRACL self-description is one example).
If you are shipping this#
- Evaluate for your workload: Primary metrics MTEB-R / in-domain nDCG@10; for multilingual, add out-of-domain sets (news, tickets), not MIRACL Wikipedia alone.
- Design dimension and index together: If using Arctic 2.0 Large 256-d MRL prefix, fix
dbefore Weaviate (or other HNSW) ingest and check HNSW memory planning; rewrite colloquial “recall retention” as MTEB-R nDCG@10 retention. - Fine-tune playbook order: teacher mining → NV-Retriever-style false-negative filter → random-order baseline; under 2.0 settings do not prioritize curriculum first.
- Monitor multilingual pre-training: Plot learning curves for languages not in pre-training to avoid “more training is always better”; shorten contrastive pretrain if needed (interview suggestion) and validate on customer domain.
- Hosted vs self-hosted: Lock version and dimension via Weaviate Embeddings models or Snowflake-Labs/arctic-embed; on model change re-embed fully—do not assume old vectors are compatible.
References and further reading#
- Arctic-Embed (arXiv:2405.05374) — 1.0 report: contrastive pre-training, source stratification, batch ablation
- Arctic-Embed 2.0 (arXiv:2412.04506) — MRL, multilingual transfer, teacher and false negatives, curriculum negative result
- Snowflake-Labs/arctic-embed (GitHub) — weights, inference examples, README training scale
- MTEB: Massive Text Embedding Benchmark (arXiv:2210.07316) — task families and leaderboard definition
- BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation (GitHub) — zero-shot IR benchmark bundle
- MIRACL multilingual retrieval project — 18-language Wikipedia retrieval
- Text Embeddings by Weakly-Supervised Contrastive Pre-training (E5, arXiv:2212.03533) — Arctic pre-training paradigm source
- Matryoshka Representation Learning (arXiv:2205.13147) — original MRL method
- NV-Retriever: Improving Text Embedding Models with Effective Hard-Negative Mining (arXiv:2407.15831) — false-negative threshold strategy
- NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models (arXiv:2405.17428) — read separately from Retriever paper
- Gecko: Versatile Text Embeddings Distilled from Large Language Models (arXiv:2403.20327) — commercial embedding and truncation comparison context
- Embedding And Clustering Your Data (arXiv:2407.18887) — clustering-style pre-training exploration (not main path)
- Weaviate vector index concepts — HNSW and index types
- Weaviate resources and HNSW memory — “indexes must reside in memory”
- Weaviate Cloud Embeddings model list — includes Snowflake Arctic SKUs


