
Enterprise AI on Exabyte-Scale Unstructured Content: Permissions, Layered Retrieval, and Agent Boundaries#
Once enterprises put documents, contracts, RFPs, and media into content clouds such as Box, the hard part is rarely “can we call GPT?” It is making three things hold at once: data keeps changing, who can see what keeps changing, and indexing and inference bills keep changing. In a technical podcast, Box CTO Ben Kus and Weaviate co-founder Bob van Luijt, with Connor Shorten, range from storage and multi-tenant permissions through RAG, embedding economics, and agents. What follows is reorganized by engineering theme, not chronological recap. Anything not verified in SEC 10-K filings, OpenAPI specs, or papers is labeled speaker opinion.
Problem space: why “large context + general models” still is not enough#
A common industry claim is that as context windows grow, RAG is “almost unnecessary.” Ben Kus’s counter (speaker opinion) targets enterprise private corpora, not public-web Q&A: content is uploaded and revised continuously; the visible set for the same question differs by user; stuffing “the whole library” into a prompt is unrealistic on cost and compliance grounds. Bob’s angle is more implementation-oriented: the token sequence inside a window still maps to vector representations on the model side; walking the token→embedding pipeline with stacks such as Hugging Face Transformers helps show that a larger window does not remove the need for retrieval up front—a reproducible learning path, not a Box product spec.
Meanwhile, the Box FY2026 10-K discloses more than 100,000 paying organizations as of January 31, 2026, with generative AI / Box AI and BYOM (bring your own model) as explicit directions. Ben’s remarks in this episode—exabyte-scale storage, hundreds of billions to trillions of objects, 120,000+ customers, tens of millions of users—do not appear as exabyte or trillion-object figures in the accessible 10-K; migration tool Box Shuttle describes only petabyte-scale migration capability. For writing and architecture choices, keep SEC figures separate from CTO oral scale claims.

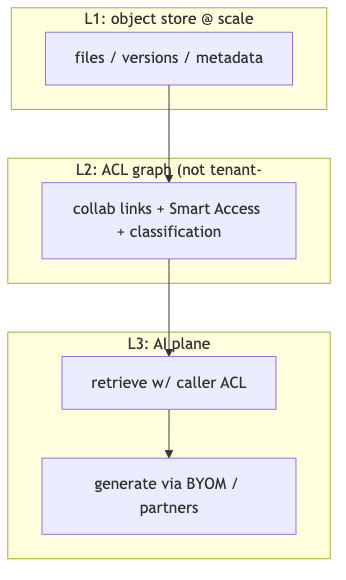
Three-layer infrastructure: storage, permission graph, AI invariants#
Why#
The first-order constraints of an unstructured-content platform are not embedding dimensionality but L1 throughput and reliability (millions of interactions per second at scale, object storage), L2 collaboration permissions (cross-company sharing), and L3 AI (multiple models, permission consistency, fast onboarding of new models without leakage). Weakness in any layer turns upper-layer RAG into “demo-ready, not production-ready.”
Mechanisms and constraints#
The crux of L2 is cross-tenant behavior: when user A@customer-one shares with user B@customer-two, you cannot solve visibility with naive “hard-isolate shards per enterprise” alone (speaker opinion). The 10-K describes internal/external collaboration, Smart Access, shared links, and classification policies; OpenAPI Hubs list resources by requesting user—aligned with a “global multi-tenant visibility graph” narrative, though that term does not appear in official docs.
L3 invariant: AI answers must not exceed authorization. Retrieval and generation may use only content the caller may access; the same must hold when integrating Azure OpenAI, Vertex AI, Claude, Bedrock, and others (speaker opinion; consistent with Box API’s “do not bypass content permissions” principle—see Box Developer Security). On security culture, Ben stresses that permissions and compliance cannot follow “move fast and break things”—tension with founders pushing an AI vision is an organizational tradeoff, not a single quotable technical spec.
How to implement (minimal example)#
At the application layer, treat “user identity + content ACL” as a hard filter before vector or keyword search:
# Pseudocode: bind caller-visible file_id set before retrieval
visible_ids = box.acl.resolve_visible_files(user_id, hub_id=None)
candidates = hybrid_search(query, filter={"file_id": {"$in": visible_ids}})
Common pitfalls#
- Treating “tenant ID = shard key” as the permission model while ignoring B2B external collaboration.
- Filtering only at the app layer on the vector store without syncing Box permission-change events, producing stale visibility.

a / 3 =x / } Weaviate (no architecture slide—interview footage only).
RAG vs large context: when each opposing claim holds#
Why#
Enterprise RAG value, in this framing (speaker opinion), is fresh data + permission-filtered context + generation—not merely enlarging the token window. That is compatible with the usual RAG definition (retrieval-augmented generation), but Ben’s argument centers on ACL + dynamic corpora as a scenario judgment.
Mechanisms and constraints#
Bob summarizes stack evolution as: vector database → RAG (embeddings for candidates) → Agent (generated results can be written back) (speaker/product opinion). Ben recalls the ChatGPT / GPT-3.5 API “production-ready” inflection (roughly late 2022–early 2023—cross-check against public API timelines) as when enterprises seriously invested in content platforms; he also subjectively argues early GPT-3.5 Turbo feels far behind GPT-4.1, Gemini 2.5, Claude 3.7, and others for enterprise use cases—model iteration itself is platform risk, not a one-time vendor pick.
How to implement#
Minimal closed loop for permission-aware RAG:
query → (metadata/keyword/coarse vector) recall@K
→ ACL filter
→ rerank / optional "deep" read
→ LLM w/ citations
Common pitfalls#
- Treating a “128k/1M window” as a substitute for incremental indexing, ignoring daily document updates and revoked access.
- Skipping citation granularity (file vs paragraph), so answers cannot be audited to a specific chunk.

tabs tH Wilts; no readable slide title.

“Find the file” vs “find the answer”: dual-granularity embeddings#
Why#
Enterprise search has long conflated two tasks: locating which artifact vs locating which passage inside it. The AI era requires splitting them; otherwise recall is insufficient or embedding counts explode (speaker opinion).
Mechanisms and constraints#
- File-level: which deck, which proposal—suited to navigational queries.
- Paragraph/page-level: revenue or risk sections in a filing—suited to Q&A-style queries.
Connor (Weaviate) cites ColBERT (Khattab & Zaharia, SIGIR 2020) as a reference path for long PDFs: multi-vector + late interaction, finer than fixed 500-token coarse chunking—paper mechanism verified; Ben does not claim Box has shipped ColBERT. On “five paragraphs per page → five vectors?”, Ben’s answer is it depends on query type, not a fixed five (speaker opinion).
ColBERT core (document side): query and document are encoded independently; late interaction yields fine-grained similarity; document representations can be precomputed—good for long documents, but storage is often many vectors per document, tying directly to the cost section below.
How to implement#
Maintain two index levels for the same file_id (conceptual sketch):
{
"file_id": "f_123",
"file_vector": "[...]",
"chunks": [{"page": 3, "span": "...", "vector": "[...]"}]
}
Query path: narrow candidates with file_vector or metadata first, then paragraph-level vectors or ColBERT-style reranking on the subset.
Common pitfalls#
- Precomputing paragraph-level embeddings for the entire corpus—Ben says at Box scale the cost can reach “years of total customer payments” order of magnitude (speaker opinion; no public bill).
- Ignoring that for short spans + high-dimensional float32, vector storage can exceed source text size (next section).

Weaviate bug; OCR lacks full ColBERT wording—do not invent slide terminology.
Embedding economics and layered retrieval#
Why#
Ben’s early billing experience (speaker opinion): storing and fast-retrieving embeddings can cost more than compute; hanging exabyte-scale vectors beside exabyte-scale content is not realistic. Bob gives a reproducible estimate: 1500 dimensions × float32 ≈ 6000 bytes (~5.86 KiB):
dims = 1500
bytes = 1500 × 4 # float32
# → 6000 bytes
For short-text chunks indexed paragraph by paragraph, 10×–100× source size on storage is not unusual (speaker opinion; exact multiplier depends on chunk size, quantization, and multi-vector schemes).
On the Weaviate side, Bob describes moving from “all in memory” toward disk-backed flat index, vector cache, and dynamic index that promotes beyond a threshold to HNSW (see Weaviate Vector Indexing). Spoken “warm storage” has no same-name product in official docs; prefer flat index / disk-backed in prose—do not present it as a verified product name.
Mechanisms and constraints#
Ben’s high-level retrieval pipeline (speaker opinion; “Deep Search” does not appear in Box OpenAPI v2025.0—must not be written as a published API):
- Narrow recall: metadata, keywords, precomputed embeddings (including file-level), etc.
- More expensive analysis on a small subset: AI rerank/deep read called Deep Search (name not verified).
- When needed, paragraph-level embeddings; in some cases compute at query time beats full precomputation.
Industry two-stage retrieval (cheap recall → expensive rerank) is weakly related to the narrative above but cannot be equated with Box’s implementation.
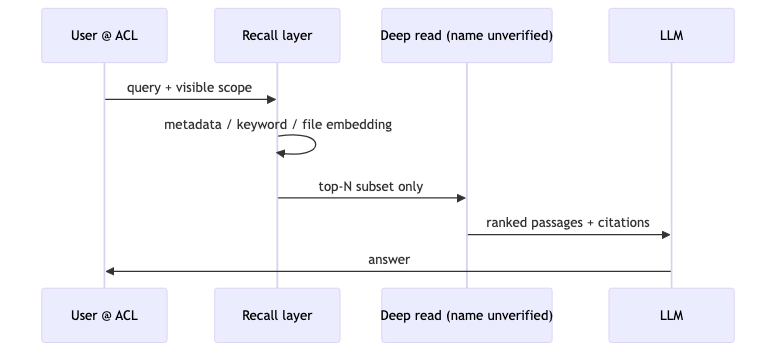
How to implement#
Layered retrieval pseudocode:
candidates = cheap_recall(query, top_k=500) # file-level + BM25
scored = deep_rerank(query, candidates[:50]) # speaker's "Deep Search"; implementations vary
context = embed_on_demand(scored[:10]) # on-demand paragraph vectors
Common pitfalls#
- Large customers demanding “index all 30PB first”—both sides should push back; opposite of “recall first, deep compute second” (speaker opinion).
- Optimizing embedding compute GPUs while ignoring vector storage and indexing bills.

We hs Oy Tas and Weaviate bug.

Weaviate : == fC = A (no billing or dimension slide).
Agents, workflows, and the “copy-paste tax”#
Why#
Workflow / RPA fits fixed-step processes with weak per-step intelligence (speaker opinion). Agent, in Ben’s working definition (deliberately non-dogmatic): goal-driven, with some autonomy, able to execute multiple steps on the user’s behalf—complexity tiers include query, transformation, heavier transformational work, etc. Weaviate’s product-side query / transformation / personalization agent taxonomy is a separate product classification—analogy only, not equivalence.
Enterprise value case: RFP. RAG compresses “10 people × hours” to about one hour, but manual copy-paste between Hub and questionnaires remains heavy; a full agent chain (retrieve → transform → Box Doc Gen GA noted February 2025) approaches “the team works for me” (speaker opinion; RFP metrics and endpoints not verified in OpenAPI).
Hubs: OpenAPI exposes GET /hubs, listing Hubs for the requesting user—a technical anchor for cross-file RAG containers. Box × Weaviate agents integration was described as shipped by Bob (interview claim); confirm via Weaviate Agents documentation and both parties’ press releases.
Mechanisms and constraints#
Box platform narrative: understand content (AI) + generate content (doc gen); agents chain retrieval, transformation, and document write-back. Versus a pure chatbot, the difference is side effects: writing files, filling forms, orchestrating across Hubs—failure modes expand from “wrong answer” to “wrong write, leakage, unauthorized write.”
How to implement#
RFP-style workflow (conceptual):
Hub(historical bids) → retrieve Q&A pairs → draft answers
→ human review gate → doc_gen(new document)
Common pitfalls#
- Treating a one-shot RAG Q&A as an agent while ignoring state, tool calls, and write-back.
- Shipping agents without human approval gates—unacceptable in regulated industries.

"POUR eR noise and Weaviate bug.

weirs “iy ire and Weaviate.

Cloud and models: what documents verify vs what was said orally#
| Topic | Verifiable (examples) | Interview framing (not fully verified) |
|---|---|---|
| Hosting | 10-K: substantial majority outsourced to GCP, with alternative providers as backup | “100% hyperscaler multi-cloud” |
| AI partnerships | Azure OpenAI, Vertex AI, Claude, Amazon Titan (Bedrock), etc. | Bound to permission invariants (inference) |
| Customer scale | >100,000 paying organizations (FY2025/2026) | 120,000+, tens of millions of users |
| Storage scale | Shuttle petabyte-scale migration | exabyte platform total storage |
If architecture decisions depend on hosting topology or exact scale, trust the 10-K; the podcast supplies engineering tradeoff samples on a very large content platform.

<> Awe and Weaviate; three-panel interview, not a timeline slide.
If you are shipping this#
- Build ACL-aware recall before paragraph embeddings: file-level + metadata + keywords to narrow candidates; paragraph vectors or ColBERT-style multi-vectors in stage two, with
dims × sizeof(float)and index cost worked out. - Reframe “RAG is dead” as a scenario claim: under dynamic corpora + permission boundaries, retrieval stays mandatory; large windows compress multi-passage evidence, they do not replace visibility solving.
- Permissions and audit as first-class: retrieval filters, generation citations, and write-back under the same
user_id; reconcile ACL changes regularly. - Align product names with official APIs: do not put interview terms Deep Search or warm storage straight into external design docs; on Weaviate use flat index / vector cache and other documented terms.
- Enter agents via scenarios that eliminate the copy-paste tax: Hub + retrieval + human gate + doc gen beats “fully autonomous bidding” for deliverability.
References and further reading#
- Box FY2026 Form 10-K (through 2026-01-31) — paying organizations, GCP hosting, Box AI / Doc Gen, model partnerships
- Box FY2025 Form 10-K — year-over-year comparison
- Box OpenAPI v2025.0 — Hubs and other REST surfaces
- Box Developer documentation — security and integration guides
- Box Developer — Security principles — APIs do not bypass content permissions
- ColBERT paper (arXiv 2004.12832) — multi-vector + late interaction
- Retrieval-Augmented Generation (Lewis et al., 2020) — RAG baseline concepts
- Weaviate — Vector Indexing concepts — flat / HNSW / dynamic index
- Weaviate — vector-index configuration reference —
vectorCacheMaxObjects, etc. - Weaviate Agents introduction — agent product boundaries
- Hugging Face Transformers documentation — token and representation learning path
- Google Cloud — Vertex AI documentation — one partnership direction cited in the 10-K
- Azure OpenAI Service documentation — enterprise model hosting options
- Anthropic Claude documentation — third-party model integration reference
- Amazon Bedrock User Guide — Titan and other model access
This article reorganizes engineering views from the Box × Weaviate technical conversation, cross-checked against SEC 10-K, OpenAPI, the ColBERT paper, and Weaviate official documentation; where they conflict, documents prevail. Podcast footage is three-panel interview; illustrations contain no quotable architecture slide text.


