
Architectural Tension in the Voice-Agent Era: SSMs, Low-Latency TTS, and Whether End-to-End Eats the Orchestration Stack#
When RAG, long-context windows, and reasoning models enter the production stack at the same time, voice scenarios expose a harder set of constraints: whether multimodal signals survive intact at ingestion, whether tail latency (P99) stays below users’ psychological anchors, and whether architectural innovation must yield to the data flywheel. The path Cartesia co-founder Karan Goel (State Space Models / Mamba research background) outlines in public discussion does not align with the industry narrative that “million-token context is already commoditized.”
What follows is layered into facts checkable against literature, vendor documentation, and speaker opinions. This episode does not supply MOS, WER, or market-share figures—none are invented here. The target reader has already deployed a vector database or a voice stack and needs to map options against their own SLOs, not a show recap.
Problem space: Compound AI and the hard metrics of voice stacks#
The common production shape is still ASR → LLM → TTS cascade (compound orchestration), paired with vector retrieval or long-context caching. Voice agents add a phone / real-time session dimension: users tolerate not only average latency but P99 and time-to-first-audio (speaker opinion; vendor docs include a WebSocket low-latency example).
Meanwhile, “agent” in voice products often means a callable voice entity with a configurable persona, not the same thing as an autonomous agent with a tool loop (speaker opinion). A bifurcation where highly sensitive calls stay human and the rest are handled by AI is the guest’s read on customer-service verticals—no industry statistics cited.
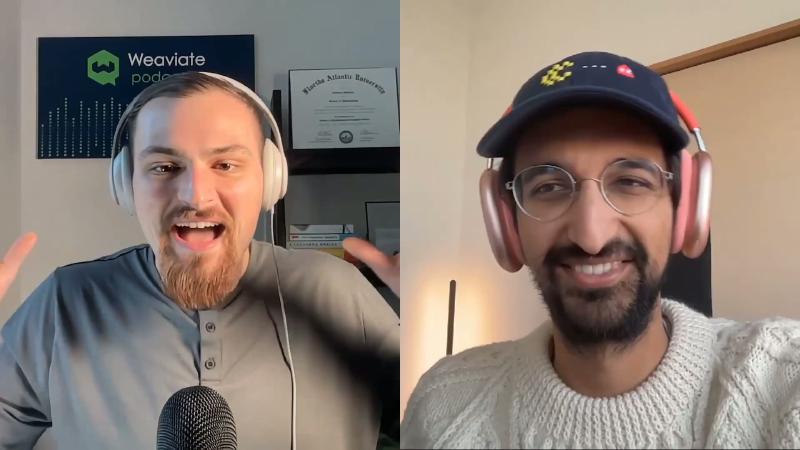

“Stack the window” vs “compress state” with SSMs: two paths that have not converged#
Why quadratic complexity is still discussed#
Standard Transformer self-attention has per-layer complexity O(n²·d) for sequence length (Vaswani et al., 2017); the FlashAttention abstract describes time and memory as quadratic in sequence length—a verifiable claim. The industry side points to Gemini million-token context, Command R+ 128k, and similar as proof that engineering larger windows + exact-attention optimizations is already productized—tension with the stance that only an architectural breakthrough enables “machine memory.”
Mechanisms and constraints#
| Path | Core mechanism | Constraints |
|---|---|---|
| Engineered exact attention | IO-aware implementations such as FlashAttention 1–3; context caching reuses prefix tokens | Complexity remains quadratic; even huge windows have limits (speaker opinion) |
| SSM / Mamba state compression | Selective state spaces; Mamba-2 SSD claims linear scaling | Long-horizon reasoning and online adaptation still need “multiple breakthroughs” (speaker opinion; roadmap not verifiable) |
The guest likens context caching to a KV cache for prompts (mechanism checkable via Hugging Face KV cache docs); the Mamba abstract reports throughput multiples vs. Transformers, but task- and hardware-dependent—not a law for the whole industry. The guest says SSMs can run efficiently on NVIDIA GPUs (Mamba README requires Linux + NVIDIA GPU); claims about native Mamba on AWS Trainium/Inferentia have no primary documentation page found—treat as market judgment pending evidence. The company still trains Transformer baselines to answer “which architecture is right” (speaker opinion).
How to do it (verify complexity, not pick sides)#
# Check Self-Attention complexity table from arXiv source (P01)
curl -sL "https://arxiv.org/src/1706.03762v7" -o /tmp/attn.tar.gz
tar -xzf /tmp/attn.tar.gz -C /tmp/attn && grep 'O(n^2' /tmp/attn/why_self_attention.tex
Common pitfalls#
- Treating a bigger window as a paradigm shift—FlashAttention improves wall-clock for exact attention, not asymptotic order (literature + speaker opinion).
- Over-simplifying the guest’s “approximate attention is usually worse than exact”—the paper criticizes some approximations on wall-clock, not that approximation is worse on every task (verification boundary).
From SSM research company to TTS first: Sonic and production constraints#
Why audio became the “simplest” testbed#
Cartesia traces to the Stanford Chris Ré group lineage; the company blog Announcing Sonic (datePublished 2024-05-31) states Sonic is built on state space models (SSM) with a proprietary state space model inference stack. The guest’s oral timeline puts first release around June–July 2024, ~one month off the blog (possible API public beta or recall bias, not verified).
The counter-intuitive part: a company founded on SSMs and “near-infinite context” commercialized TTS first—the guest frames it as an audio testbed for multimodal long memory, and TTS as the “simplest” slice of audio (speaker opinion).
Mechanism: four goals in tension#
Documentation and the blog support multiple objectives (not an independent benchmark):
- Expressiveness (naturalness, emotion, etc.; see Sonic 3.5 docs)
- Very low latency (blog claims model latency 135ms—vendor statement)
- Controllability (volume / speed / emotion; precise natural-language audio description still immature, speaker opinion)
- Pronunciation reliability (addresses, phone numbers, etc.; docs include spelling / read-out guidance; not verified that every entity type the guest listed is covered)
This episode gives no MOS, WER, or RTF percentiles; NISQA scores in the blog ≠ standard MOS.
How to do it (minimal integration)#
# Pseudocode: streaming TTS—track first packet and percentiles, not mean only
# Measure TTFA / P99 on your own network (metric definitions in vendor examples)
import cartesia # per current SDK at docs.cartesia.ai
client = cartesia.Client(api_key="...")
for chunk in client.tts.bytes(model_id="sonic-3", transcript="...", stream=True):
play(chunk) # record time_to_first_audio, p99_turn_latency
Common pitfalls#
- Treating 135ms model latency as voice-agent P99 (guest stresses P99 but gives no milliseconds; definitions may differ).
- Assuming TTS is “just reading aloud”—production complaints often cluster on rare words, numbers, proper nouns (speaker opinion).
Cascaded stack vs. end-to-end multimodal: where signals break#
Why cascades still dominate#
Cascades work and can be quite impressive (direction of speaker’s wording)—Cartesia offers both STT and TTS, showing a componentized stack. The host is familiar with LangChain, DSPy, STORM, and other decomposed reasoning chains; the guest does not reject search & planning (“ML is only learning + search”) but argues tone, emotion, and prosody are irreversibly lost after ASR textification, limiting empathetic response (speaker opinion; no ablation in this episode).
Mechanism comparison#
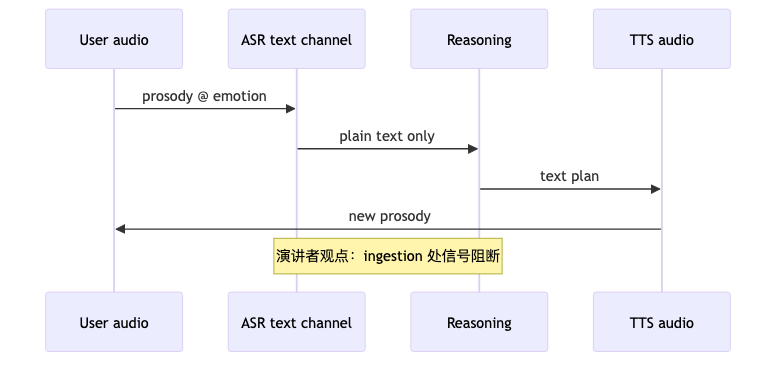
The end-to-end vision is one API behind ingest + respond (multimodal), with voice interaction that “feels human” (speaker opinion). Open question: whether end-to-end replaces orchestration or absorbs explicit tool calls / DB search—the guest gives no product roadmap detail.
How to do it#
- If you keep the cascade: pass confidence, speaker, prosody features, and other metadata from ASR into the LLM (engineering compensation—not equivalent to raw waveform).
- If you evaluate end-to-end: use the same script and test whether emotion instructions are followed; do not rely on text BLEU/WER alone.
Common pitfalls#
- Because cascades “work well,” assuming they will never be replaced—the guest’s bet is modality loss + latency anchor (subjective 4–5× gap after using a very fast system, speaker opinion, no quantitative study cited).
- Treating Vapi + Cartesia integration (Vapi docs verifiable) as proof end-to-end is mature—it is an orchestrator integrating TTS.
RAG, pull/push, and the contradiction in “memory maximalism”#
Why long context has not killed RAG#
The guest calls himself a memory maximalist: the ideal is one warmup that fills context, no RAG; he also admits just-in-time information is still necessary (speaker opinion)—opposite the popular “RAG is dead because of long context” narrative.
The host cites RETRO (retrieval + generation, ~1/25 the parameters of GPT-3 with comparable performance) and Fusion-in-Decoder (retrieved passages injected into the decoder). Note: the host’s oral “8B ≈ 175B” does not appear in the FiD abstract; RETRO’s abstract says comparable to GPT-3 / Jurassic-1 with 25× fewer parameters—do not write a literal 8B/175B headline (verification boundary).
Pull vs. push#
| Mode | Behavior | Guest lean |
|---|---|---|
| Push | System pre-fills context / retrieval results | Mainstream RAG today |
| Pull | Model requests information on demand | More ideal interaction (speaker opinion) |
The host wants MCTS-style reasoning to call the whole database; the guest has no clear view on injecting embeddings into intermediate layers (self-described non-expert on RAG). That complements rather than replaces vector retrieval infrastructure like Weaviate—both narratives can coexist.
How to do it#
- Long documents: combine Gemini context caching (or vLLM prefix caching) with incremental retrieval; do not assume “window is big enough, no index needed.”
- Evaluation: beyond needle-in-a-haystack, add time-sensitive facts and permission boundary cases (not discussed in this episode).
Common pitfalls#
- Treating the guest’s maximalism as a product promise—he immediately admits it is unrealistic.
- Ignoring that pull still needs retrieval APIs and permission models; only the caller shifts from orchestrator to model policy.
Inference clock, test-time compute, and “complaints beat benchmarks”#
Mechanism#
A faster inference clock → more reasoning reps / search steps in the same wall-clock (speaker opinion). Let’s Verify Step by Step supports process supervision on intermediate reasoning steps, aligned with stepwise reasoning direction—not the same as OpenAI o1 product mechanics (o1 primary page not captured here; label as interview inference).
o1-class discussion often contrasts explicit generated tokens fed back vs. implicit latent search—the guest is unclear on the latter (speaker opinion).
Data flywheel and many-shot#
The guest stresses production complaints over abstract evals (speaker opinion). Architecture-innovation companies still invest in data; SSMs even drive what data to collect (speaker opinion).
Many-Shot In-Context Learning shows hundreds of examples can keep improving; the guest did not know the many-shot term beforehand but agrees it relates to long sequences and in-loop improvement—weakly related to his in-loop meta-learning (weight updates); do not conflate.
Common pitfalls#
- Replacing serious user complaints with public leaderboards—fine for early signal, not for compliance or bias audit.
- Treating many-shot as online learning shipped—the paper is in-context, not persistent weight updates.

If you are shipping this#
- Define latency metrics first: in the same region/network, measure TTFA and P99 turn latency; separate vendor model latency from agent end-to-end; do not cite 135ms as your SLO verbatim.
- Enrich the cascade with metadata: attach confidence / speaker / prosody summary to ASR output—mitigates but does not replace end-to-end multimodal experiments (build your own emotional script set).
- Long context + RAG in parallel: static knowledge via prefix cache; dynamic facts via retrieval; reserve tool schemas for pull even if models do not call them yet.
- Layer evaluations: TTS with rare-entity pronunciation tables + complaint clustering; reasoning with step-wise checks; do not mix MOS and NISQA.
- Keep an assumption list for architecture narratives: SSM production path (Cartesia blog) and FlashAttention long windows can coexist—choose stack by business metrics, not paper religion.
References and further reading#
- Attention Is All You Need — Vaswani et al.
- FlashAttention — Dao et al.
- FlashAttention GitHub
- Mamba: Linear-Time Sequence Modeling — Gu & Dao
- Mamba-2 / State Space Duality — Dao & Gu
- Announcing Sonic — Cartesia blog
- Cartesia documentation overview
- Sonic 3.5 model documentation
- Gemini long context
- Gemini context caching
- RETRO — Borgeaud et al.
- STORM — multi-perspective writing agent
- Many-Shot In-Context Learning
- Let’s Verify Step by Step — process supervision
- vLLM automatic prefix caching design


