
Compound AI: When a Single LLM Call Is Not Enough#
Production AI applications rarely stop at a single-round chat.completions call. Berkeley BAIR’s definition of Compound AI Systems centers on multiple interacting components—repeated model calls, retrievers, external tools, and business logic—working together on one task; enterprise surveys cited there put roughly 60% of LLM apps on RAG and about 30% on multi-step chains. At the same time, “Agent” product shapes, DSPy-style workflows, and stepwise sampling driven by o1 are all competing for the same engineering budget.
Baseten developer relations lead Philip Kiely, in an interview of about an hour, moves from structured output and the inference stack to multi-model orchestration and deployment granularity, repeatedly describing compound AI as a way to build systems, not a SKU. Below, mechanisms and boundaries are organized by engineering theme for practical use; figures not checked against official docs or papers are labeled by source.
Problem space: from RAG to Agent, competing for the same pipeline#
Common practice: RAG with a vector store plus a generative model, or Agents via ReAct loops with function schemas; evaluation targets retrieval quality (MRR, nDCG) or open tasks (e.g. WebArena).
Another view (speaker opinion): compound AI is a graph of nodes and edges—models, API wrappers, human-in-the-loop (HITL), and ordinary code are all nodes; an “Agent” is one product shape built from such a graph, alongside fixed-step workflows, and does not automatically reduce underlying deployment units.
Evidence and boundaries: the BAIR post supports a “multi-component system” framing but does not terminologically separate Agent vs Workflow. Alto (streaming and parallel orchestration for compound queries) and Agent Workflow Memory (in-context learning from workflow trajectories), mentioned by the host, align in public abstracts with “scale by components,” but the interview did not go into implementation detail, so specific metrics from those papers are not cited here.

Structured output: constrained decoding vs post-hoc cleanup#
Why#
In multi-model pipelines, schema mismatch between stages becomes integration debt: ASR text format, tool JSON, vector-store write-back fields—any illegal structure triggers retries, degradation, or silent data loss.
Mechanisms and constraints#
Outlines models generation as transitions on a finite state machine; arXiv:2307.09702 uses vocabulary index and allowed_tokens to mask illegal tokens each step, with structural guarantees during generation and little overhead in the paper. outlines-core Index::new corresponds to “compile once from schema/regex, reuse many times.”
Speaker opinion: Baseten integrates Outlines at the model server layer, claiming steady-state near-100% schema validity with tokens/s close to unconstrained generation; the first compile of a state machine for a complex schema may take 10–20+ seconds (longer for harder schemas), suited to batch workloads with fixed schema (e.g. vector-store generative feedback loops), not per-request dynamic schema changes.
Partially verifiable: the paper supports FSM and low-overhead directions; it does not imply equal throughput or 10–20s cold start—those are not in the public README; measure before production.
How to do it (minimal example)#
# Conceptual sketch: compile Index for fixed schema, mask tokens at inference
from outlines import models, generate
model = models.transformers("meta-llama/Llama-3.2-3B-Instruct")
generator = generate.json(model, YourPydanticModel) # compile once
out = generator("Extract entities from: ...") # reuse many times
Alternatives: natural-language generation → second LLM cleanup; or OPRO-style prompt search. The host argued constrained generation is “winning”; speaker opinion warns it may affect reasoning and similar capabilities—A/B test.
Common pitfalls#
- Treating “parse failed, prompt again” as a free retry—latency and cost stack linearly.
- Forcing compile-cache when every request has a different schema—cold start dominates P99.
- Ignoring the split between runtime constraints like DSPy Assertions (docs note Assert is deprecated; prefer
Refine/Suggest) and decoding constraints: the former targets program semantics, the latter token-level guarantees.
Speech and multimodal: specialist chains vs one “do-everything” model#
Why#
Built-in multimodal APIs like GPT-4o fold ASR, reasoning, and TTS into one interface with a simple deployment story; in real-time voice and region-latency-sensitive settings, specialist pipelines remain common.
Mechanisms and constraints#
Whisper transcribe() uses a sliding 30-second window (documented, verified). Long audio must be chunked, transcribed in parallel, then stitched—model/product boundary, not an optional optimization.
The README model table lists turbo at roughly ~8× the speed of large, with a footnote that English transcription was measured on an A100 and real-world speed may vary. Speaker opinion frames this as real-time factor and mentions T4/A10/L4—GPU list and RTF numbers are not in the README; write “README relative speed vs large,” not direct RTF equivalence.
Typical chain: Whisper → streaming LLM → TTS (Piper, Coqui, Rime, etc.). Speaker opinion: same-region deployment, avoiding public-network hairpins and DNS/cluster-internal routing can keep end-to-end under sub-second; poor orchestration easily reaches 3–4 seconds.
How to do it#
Audio stream → chunk@30s → Whisper Turbo (parallel) → stitch text → LLM (stream) → TTS → audio stream
↑ same VPC / same AZ, avoid cross-region hairpins
Common pitfalls#
- Assuming one Realtime API is always more expensive or slower than a three-model chain—depends on traffic shape, region, and willingness to invest in orchestration.
- Ignoring the fork between ColPali-style “retrieve PDF images directly in the vector DB” vs “image→text then RAG”; the interview gave no quantitative comparison—an engineering choice.

Inference stack: prefill/decode, MoE, TensorRT-LLM, and Truss#
Why#
Compound systems often bottleneck on GPU utilization at the slowest node, not API-layer QPS.
Mechanisms and constraints#
Prefill vs decode (partially verified): NVIDIA’s inference optimization article describes prefill as a parallel phase that can saturate GPU compute, and decode as memory-bound, dominated by HBM bandwidth. Speaker opinion further casts prefill as compute (FLOPs) dominated—finer than the official wording; with long context, both can be tight.
MoE (partially verified): Switch Transformers stresses sparsely-activated experts per sample. Speaker opinion: in batch inference, different requests may activate different expert subsets; batches often tend toward activating all experts, shrinking MoE’s bandwidth advantage vs dense—engineering intuition, no verbatim theorem in the paper.
TensorRT-LLM (partially verified): Core Concepts explains compilation via build_engine, with TensorRT choosing kernels for the available GPU; in-flight batching is continuous / iteration-level batching. Speaker opinion: Baseten internal tests beat vLLM in some scenarios—no public tables; not a universal conclusion. Changing GPU usually warrants rebuilding the engine (strong inference; docs do not state “must rebuild” in one sentence).
Truss (speaker opinion): Truss packages model services with Python + YAML, compared to Ray Serve and BentoML; Philip said he is not a Docker expert and Truss lowered the serving bar. Quick prototypes can still use vLLM for OpenAI-compatible endpoints.
How to do it#
# Minimal Truss sketch (structure varies by version)
model_name: my-llama
python_version: py311
resources:
accelerator: A10G
Common pitfalls#
- Costing MoE from “sparse per single request” under batch traffic.
- No CI/CD plan for GPU model lock-in on TensorRT engines.
- Equating one Agent “entry point” with one autoscaler—see next section.
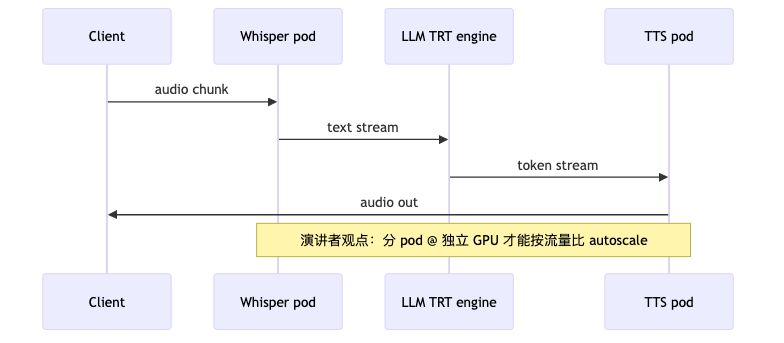


Agents, tool calling, and evaluation: same graph, different products#
Why#
Benchmarks like WebArena reward open loops (“is the task done?”); a fixed five-step blog-writing pipeline is closer to a workflow, with explicit parallelism like a forward pass (host’s summary).
Mechanisms and constraints#
Function calling moving down-stack: Llama 3.2 MODEL_CARD reports BFCL V2 Tool Use: 1B acc 25.7, 3B acc 67.0 (bf16 row), with 3B near Llama 3.1 8B at 67.1. The table header is Tool Use, not the exact phrase “function calling”; prefer BFCL tool-use capability in prose.
Separating tool selection from execution (speaker opinion): favor function selection—the LLM only picks tools and fills parameters; execution lives outside the compound graph. The host added that parameter formatting remains hard in Gorilla and GraphQL/text-to-SQL settings.
Search-style ensembles: the host asked whether o1-style “sample N times per step then ensemble” becomes mainstream; speaker opinion sees more multi-model multimodal stitching in the wild than large-scale repeat-inference ensembles.
Meta Agent Search: Automated Design of Agentic Systems searches for agent designs; speaker opinion on customer work is capability-driven (longer audio, more modalities)—architecture is often reverse-engineered from model limits, with validation steps added for weak points, rather than searching topology first.
How to do it#
For fixed flows: explicit DAG plus parallel steps without dependencies; for dependencies or very long steps, use queues plus async/webhook (Baseten async inference). Weaviate generative feedback loops (batch LLM over a collection writing properties back) fit fixed schema + batch; aligned with Philip’s “do not serialize independent subtasks through a queue.”
Common pitfalls#
- Using WebArena scores to drive deterministic pipeline product decisions.
- Assuming one Agent service reduces Whisper / LLM / TTS endpoint count (speaker opinion: still deploy and scale each, e.g. 2× Whisper + 3× Llama + 1× TTS).
- Pushing every model weakness (spelling, counting, math) into fine-tuning; BAIR stresses system design often iterates faster than scale alone; speaker opinion outer regex/retrieval/arithmetic code is often cheaper.

Reliability: validation, queues, and human in the loop#
Why#
Compound failures are often cascading: missed retrieval, malformed JSON, tool timeouts—all surface as “the model hallucinated.”
Mechanisms and constraints#
Outer validation (partially verified): BAIR lists filtering outputs, verifying facts, and similar controls. DSPy Assert/Suggest can backtrack on failure (Assert deprecated).
Speaker opinion: for 100% format compliance, regex wrapping can beat more RL; “verifying is easier” in the interview is oral summary, not tied to a single paper title.
Queue vs parallel: dependencies → task queue + webhook; no dependencies → parallel. HITL can hook Slack + HumanLayer and similar (host example).
Common pitfalls#
- Putting every step in a FIFO queue “for stability,” slowing parallelizable segments.
- Only constraining generation, not business-fact checks (RAG still needs citation / second-pass retrieval verification).
Unresolved tensions (left deliberately open)#
| Topic | Common practice | Another emphasis in the interview | How to choose |
|---|---|---|---|
| System vs product | Buy an Agent platform | Compound is how you compose; Agent is one artifact | Draw data flow and SLA first, then labels |
| Multimodal | Single frontier multimodal API | Same-region specialist chain | Measure latency variance and $/minute |
| Output constraints | Instructor / second LLM | Outlines-style decoding constraints | Is schema fixed? Can you amortize compile? |
| Deployment | One K8s Deployment | Per-model GPU and autoscaler | Do traffic ratios drift over time? |
| Weak spots | More SFT / RLHF | Outer code and regex | Can failures be formalized? |
If you are shipping this#
- Draw the compound graph first: per-node input/output schema, timeouts, retry policy; then decide Agent vs workflow naming.
- Fixed-schema batch write-back (vector generative, ETL): evaluate Outlines or similar constrained generation; budget cold start for schema compile (measure P99 yourself; do not assume 10–20s).
- Voice / multimodal: chunk per Whisper’s 30s window; treat README turbo ~8× only as relative to large on A100—re-test on your GPU and languages before launch.
- Inference: prototype on vLLM; for peak throughput, evaluate TensorRT-LLM engine + in-flight batching and lock GPU model into the build pipeline.
- Scaling: independent replicas per node traffic ratio (Whisper vs LLM vs TTS), avoid monolith autoscaler; parallelize steps without dependencies by default; queues only for stateful or order-sensitive edges.
References and further reading#
- BAIR — Compound AI Systems (definition and RAG / multi-step chain stats)
- arXiv:2307.09702 — Efficient Guided Generation for LLMs (Outlines paper)
- Outlines — structural guarantees during generation
- outlines-core — Index and FSA API
- OpenAI Whisper — 30-second sliding window and turbo speed table
- NVIDIA — LLM Inference Optimization (prefill/decode)
- TensorRT-LLM — Core Concepts
- TensorRT-LLM — In-flight Batching
- vLLM project
- Baseten Truss — model packaging and deployment
- Llama 3.2 MODEL_CARD — BFCL V2 Tool Use
- arXiv:2307.13854 — WebArena
- arXiv:2305.15334 — Gorilla
- arXiv:2403.04311 — Alto
- arXiv:2408.08435 — Automated Design of Agentic Systems


