
Enterprise RAG and Agents: From Frankenstein Pipelines to an Optimizable Whole System#
After ChatGPT, many teams pushed “retrieval + large models” into production and soon hit the same wall: prompts break when scenarios drift—fix A, break B; vector stores, rerankers, and generators are tuned in isolation, with no one accountable for whether end users are satisfied. Contextual AI co-founder and CTO Amanpreet Singh frames the problem along four axes—RAG 2.0, active retrieval, preference learning (KTO/APO), and LMUnit-style evaluation (unless noted below, unattributed claims are speaker opinion). That complements Weaviate vector infrastructure as an ecosystem, but this article focuses on transferable engineering judgment, not a play-by-play of the conversation.
Public materials and podcast wording do not always align: for example, the official evaluation product is LMUnit (subtitles often mishear it as “LLLLM Unit”); open-source checkpoints are 70B-class dedicated scoring models, which conflicts with casual “small model” talk; BIRD text-to-SQL is described on the official blog as having been overall #1 and currently top 5 (full dev recipe ~73% execution accuracy), so it should not be summarized loosely as “current SOTA.” Where sources conflict, evidence boundaries are noted below.
Problem space: why “demo-ready” ≠ “traffic-ready”#
Why: Enterprise knowledge often sits far beyond the context window (the guest cites on the order of 4 billion tokens and production around 10k queries/min—not verifiable from public docs, included only as scale intuition). At that scale, 5–10-shot agentic RAG demos can work, but once QPS and preference distributions widen, failure modes cannot all be written into the prompt.
Mechanism / constraints: Bottlenecks are often distribution shift (new documents, terminology, compliance rules) and sparse feedback (production thumbs are often heavily negative—the guest cites roughly 90% negative / 10% positive, also speaker experience, no public statistics). Pure test-time multi-round retrieval does not update weights; every request stays a cold start, and in-domain abbreviations (e.g. corporate SAT ≠ Scholastic Aptitude Test) rarely persist via in-context correction (speaker opinion).
What to do: Shift the optimization target from “does this one answer look like the training set?” to “trajectory + terminal feedback”—simple RAG can be viewed as a query → retrieval → generation → feedback quadruple; complex agents are the same closed loop over tool-call chains.
Common pitfalls: Treating “can call a retrieval tool” as production-ready; treating latency work as “just retrieve fewer rounds”—with multiple rounds, errors compound in long context (speaker opinion), a different lever from DeepSeek-R1’s emphasis on verifiable rewards + trajectory filtering.
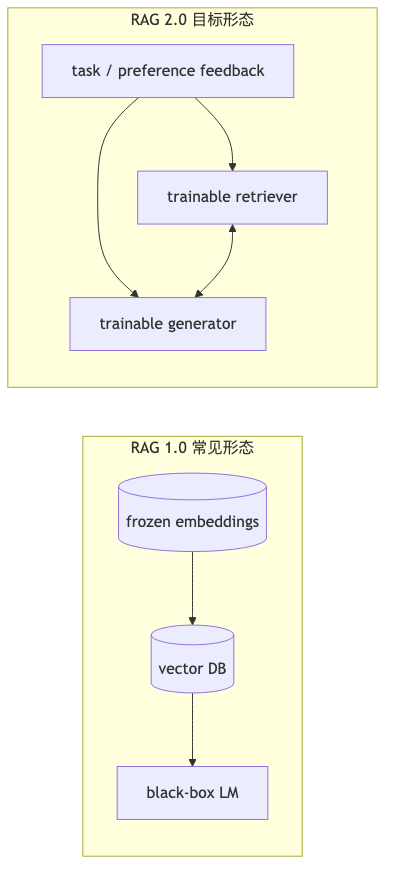
RAG 1.0 vs RAG 2.0: Frankenstein stitching or joint optimization#
Why: The original RAG paper (Lewis et al., 2020) already used differentiable access and a fine-tunable neural retriever for knowledge-intensive tasks; common industry practice is frozen embeddings + vector DB + black-box LM, so the retriever never sees gradients from generation errors—the guest calls this RAG 1.0’s “Frankenstein” stitching (aligned with Contextual AI’s RAG 2.0 definition: pretrain / fine-tune / align all components, with backprop through LM and retriever).
Mechanism / constraints: End-to-end does not mean backprop everywhere: domain proxy tasks or environment rewards can approximate the terminal objective (speaker opinion). Compared with only changing the generator system prompt, joint optimization lets the retriever learn which passages to pull from “wrong answers”—but it needs scalable data and compute, and discrete hyperparameters (chunk size, top-k) explode combinatorially; the guest says internal R&D addresses this, methods not disclosed this episode.
What to do (conceptual):
# Feedback loop (illustrative, not Contextual-specific API)
for (query, user_label) in production_logs:
trace = rag_pipeline.run(query) # retrieval + generation (+ tools)
loss = alignment_objective(trace, desirable=(user_label == "up"))
update(retriever, generator, optional_reranker_head)
Common pitfalls: Slapping “RAG 2.0” on the 2020 paper alone; conflating “user thumbs” with official RAG 2.0 narrative—docs stress benchmark-level joint training; production thumbs loops lean more on platform capabilities like KTO (see below).
Retrieval paradigms: retrieve-then-read, multi-hop, and active retrieval#
Why: Static “retrieve once, read once” fails on fiscal-year/calendar ambiguity, post-tool query revision, etc.—the guest uses financial documents as an example: you must see the corpus before deciding the next query (speaker opinion).
Mechanism / constraints (literature-checkable):
| Paradigm | Representative work | Behavior summary |
|---|---|---|
| retrieve-then-read | RETRO, Fusion-in-Decoder (FiD) | Retrieve chunks / multiple passages then one conditional generation; FiD gains from more passages but is not agentic multi-round tool calling |
| condensed multi-hop | Baleen | Latent hop ordering + condensed retrieval—still not “revise query after seeing documents” |
| active / orchestrated | Platform GA copy | Agent orchestrates retrieval and generation from dialogue context—product wording, no unified paper definition |
What to do: Trigger a second retrieval/SQL pass on low confidence or conflict detection; write tool outputs into the trace for later optimization. On structured data, Contextual claims text-to-SQL is best fully-local on BIRD, full dev recipe ~73% EX (execution accuracy, see BIRD paper)—vs the guest’s spoken “sort of state-of-the-art,” writing should add timestamp and local vs API distinction.
Common pitfalls: Assuming parallel multi-hop query splitting is enough; ignoring non-parametric tool ceilings (e.g. Notion API searching titles only)—the system can only learn “less wrong usage” within tool limits, not magically exceed the API (speaker opinion).
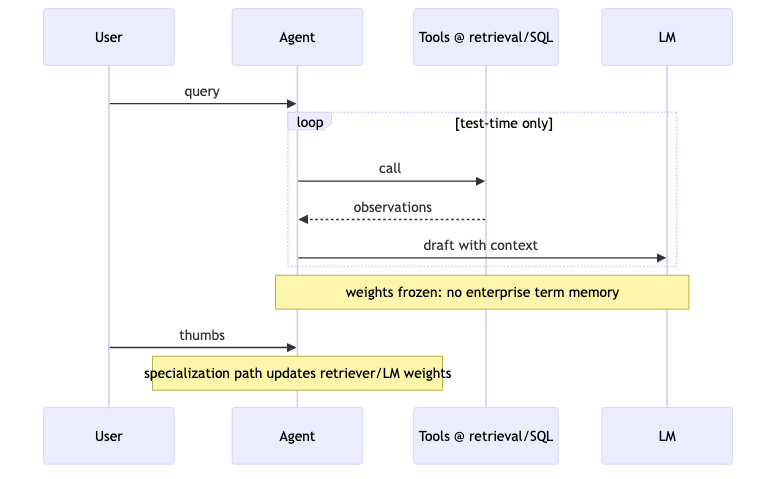
Agentic RAG, test-time compute, and weight specialization#
Why: Agentic selling points (multi-round retrieval + reasoning) dazzle in demos with few-shot; production faces heterogeneous user preferences—you cannot stuff every failure into the prompt (speaker opinion).
Mechanism / constraints: More test-time compute (more retrieval/reflection) does not change weights; enterprise terminology that never lands in parameters means every request is still generic priors + ephemeral context. The guest argues a safer path is to distill corpus knowledge into weights first, then serve (speaker opinion), contrasting DeepSeek-R1-Zero’s “skip SFT, use RL to incentivize reasoning” narrative—R1 stresses verifiable tasks and a strong base; the guest’s ~50k vocab action space and rejection sampling for long text are not line-by-line R1 conclusions.
What to do: Log full trajectories (tool calls, retrieved spans, intermediate drafts), filter with verification signals (LMUnit below), then update; the direction of 16 human preferences → unroll many trajectories parallels OpenAI-style RL fine-tuning APIs (speaker judgment on future sample efficiency).
Common pitfalls: Cutting retrieval rounds blindly for latency, or adding rounds without trajectory-level eval; stripping parametric knowledge until the model is only a “snippet repeater”—you still need in-house groundedness / conflict-resolution fine-tuning (speaker opinion).
Evaluation: from string equality and LLM judges to LMUnit#
Why: At thousand-scale QPM, judging every answer with a GPT-4-class judge can cost as much as generation (speaker opinion). Non-ML customers need “global unit tests”: style, off-topic, guardrails, groundedness, attribution—not only BLEU-style string match.
Mechanism / constraints: The LMUnit paper proposes natural language unit tests: input prompt + response + unit_test(natural-language criterion), LMUnit scoring model outputs a 1–5 continuous score (official wording), thresholdable to pass/fail, but primary interface is not binary. Research pages claim ~9% higher than GPT-4o / Claude 3.5 Sonnet on unit-test scoring, RewardBench 93.5%; open ContextualAI/LMUnit offers Llama 3.1-70B checkpoints—conflicts with “small model, low latency” talk; prefer “dedicated evaluation model” in writing.
What to do:
# Conceptual example: LMUnit pattern (see official pip install lmunit)
score = lmunit.evaluate(
prompt=user_query,
response=answer,
unit_test="Answer must cite document IDs; do not invent policy clauses not retrieved.",
)
pass_ = score >= threshold # threshold calibrated per business
Multi-axis “credit report”: groundedness, attribution, style, each with its own rubric. The host cites Who Validates the Validators? (Shreya Shankar et al.)—the guest’s stance is fix broken metrics, not stack judges infinitely (dialogue citation, not verified this episode).
Common pitfalls: Treating LMUnit scores as a universal “human preference” proxy; ignoring 70B evaluator deployment cost; synthetic QA failing to write plausible questions in skewed domains (guest’s SAT terminology example, speaker opinion)—yet shipping on real user query distributions can still proxy the query side.

Preference learning: KTO, APO, and the ceiling of “just change the prompt”#
Why: RLHF compresses sentence-level preferences into scalar rewards—large information loss, yet “weirdly works” (speaker opinion). Production often has only thumbs, heavily imbalanced; KTO (Ethayarajh et al.) explicitly learns from desirable / undesirable binary signals without pairwise “A better than B.”
Mechanism / constraints: APO paper (Anchored Preference Optimization and Contrastive Revisions, authors include Amanpreet Singh) proposes a more controllable alignment objective; anchoring ties to KL / reference model—guest spoken “anchor gap normalized spacing” is not standard paper terminology, and CLAIR experiments still use preference pairs. vs DSPy/MIPRO-style “use an LLM to rewrite prompts,” the guest argues multi-user distributions are hard to summarize in natural language, weights must move eventually, and fine-tuning one module alone is insufficient—you need “whole-system knobs” (speaker opinion).
What to do: Feed LMUnit binary/threshold signals or user thumbs into KTO/APO objectives; for non-parametric tools (Python sandbox, read-only APIs), learn “fewer mistakes within constraints,” not fantasy backprop into Postgres.
Common pitfalls: Balanced sampling under 90/10 negatives; treating APO as purely unpaired thumbs—paper experiments and CLAIR_and_APO code are still pair-heavy; optimizing only the generator while the retriever stays frozen forever.
Trust, conflict, and discrete pipeline hyperparameters#
Why: Enterprise needs audit trail / citations (guest analogizes Perplexity-style enterprise demand, speaker opinion), uncertainty triggering human escalation, and conflicts across documents (recency, intranet vs external search, analyst preference rules).
Mechanism / constraints: Reranker described as a constraint that lowers generator difficulty—isomorphic to “add structure first, relax later” in deep learning history (speaker opinion). Vector stores can add recency expressions alongside end-to-end learning, but component APIs cap behavior. Chunk size, top-k, extraction strategy can A/B test, but combinatorial explosion needs distribution matching + narrowed action space (speaker opinion).
What to do: Declare conflict-resolution policy (explicit rules + optional learning); keep moderate parametric reasoning so the model is not only snippet concatenation; for bases like Llama 3.1, use prompt + fine-tune + whole-system optimization mix (speaker opinion; platform benchmarks use it as baseline—see 2025 benchmarks blog).
Common pitfalls: Assuming one GPT-4 judge completes governance; expecting full-document recall on Notion APIs that only search titles; fully bypassing black-box DB optimization—convenient but caps capability.

Two engineering credos (no need to force unity)#
| Credo | Common practice | Guest / official emphasis | Evidence strength |
|---|---|---|---|
| System over models | One foundation model does everything | Split retrieval, generation, verification, conflict resolution | Speaker opinion + product narrative |
| Enterprise specialization | General model + RAG | Trajectory + preferences + verifiable signals update weights | KTO/APO/RAG2 partially paper-backed; scale numbers not verifiable |
| Constraints before end-to-end | End-to-end black box | Reranker, specialized modules lower optimization difficulty | Speaker opinion |
| Evaluation-driven training | Offline benchmarks first | LMUnit signals as reward | LMUnit docs partially support |
Mainstream test-time compute today does not change weights; if inference-time parameter updates arrive, the problem returns to the training stack (speaker opinion). Division of labor with vector databases (e.g. Weaviate): storage/retrieval infrastructure vs end-to-end RAG/agent optimization layer—complementary, not substitutive.
If you are shipping this#
- Map trajectories before picking optimization levers: Log
query → retrieval/tool → generation → feedback; separate “multi-round test-time” from “distill failures into weights”—don’t optimize only by cutting rounds for latency. - Productize evaluation before stacking judges: Use LMUnit-style natural-language rubrics + threshold calibration; accept 1–5 scores + dedicated 70B evaluator cost model—don’t assume “small model is free.”
- Design preference signals for production distribution: Prefer KTO-style unpaired thumbs; if using APO, read paper paired / KL anchor setup—don’t copy spoken “anchor gap” verbatim.
- Align retrieval paradigm with tool APIs: Verify retrieve-then-read vs active orchestration; for fiscal-year/terminology issues, reserve query-after-corpus-feedback; for BIRD-style SQL targets, state local vs API, EX vs pass@k, dev leaderboard date.
- Keep parametric reasoning + explicit conflict rules: Reranker/recency/human escalation are constraints, not legacy mistakes; learn “better usage” end-to-end within tool ceilings.
References and further reading#
- Contextual AI
- Introducing RAG 2.0 — end-to-end joint optimization
- Retrieval-Augmented Generation for Knowledge-Intensive NLP (Lewis et al., 2020)
- RETRO: Improving language models by retrieving trillions of tokens
- Fusion-in-Decoder (Izacard & Grave, 2020)
- Baleen: Robust Multi-Hop Reasoning at Scale
- LMUnit research page and paper arXiv:2412.13091
- LMUnit open-source repository on GitHub
- KTO: Model Alignment as Prospect Theoretic Optimization
- APO: Anchored Preference Optimization arXiv:2408.06266
- BIRD Text-to-SQL Benchmark
- Contextual-SQL and BIRD results (2025 blog)
- Platform GA press release (2025-01-15)
- DeepSeek-R1 technical report
- Weaviate developer documentation


