
Data Agents: When Code-Writing Models Meet the Real Data Stack#
In most enterprises, the hard data problem is no longer “can the model write SQL.” The same business fact may live in a Snowflake warehouse, a MySQL app database, Mongo documents, Salesforce (SOQL), and Slack threads; join keys may be a prefix game between bid_* and bref_*, not a clean id = id. On stacks like that, the “single big index” vision of Retrieval-Augmented Generation (RAG) and the Kaggle-style “thousands of tables, each on its own” sit on either side of a harder class of system to evaluate: the data agent—an autonomous (or semi-autonomous) executor that fetches across sources, cleans, reasons, and returns answers you can check.
Below, work from UC Berkeley–affiliated researcher Shreya Shankar on public benchmarks, declarative document systems, and “tribal knowledge” memory is set alongside Weaviate’s product mapping for query/transformation agents. There is no forced single conclusion. Verifiable claims align with papers and repositories; spoken numbers and mechanism paraphrases are marked where the boundary matters.
What “data agent” actually means#
Why arguing the definition matters#
If “data agent” in evals, roadmaps, and job posts is not aligned, teams get false confidence between high text-to-SQL leaderboard scores and “can’t answer across databases.” How you define it directly decides whether you optimize NL retrieval on one vector DB or build cross-DBMS tooling and a failure-mode library.
Mechanisms and constraints#
Three layers of tension are common (speaker opinion alongside product language):
| Perspective | Core claim | Verifiable boundary |
|---|---|---|
| Broad definition | Pull information across DBs, files, and collaboration tools, then compute and reason | Hard part is data thinking and tool fluency, not point NL→SQL (speaker opinion) |
| Product mapping | Read path (NL→retrieve/aggregate) + write path (classify, fill properties) = full agent | Weaviate Query Agent / Transformation Agent as read/write halves under speaker opinion |
| Eval definition | Multiple DBMSes, ill-formed joins, SQL+Python tool traces | Workload properties per Data Agent Benchmark (DAB) |
How to do it (minimal landing view)#
Decompose “one question” into observable sub-capabilities, then pick execution shape—don’t start with “whether we call it an agent”:
User question → schema/sample probing → cleaning and join plan → execute (SQL / Python / declarative operators) → automatically checkable answer
Common pitfalls#
- Treating pass@1 on single-DB text-to-SQL as data-agent capability.
- Assuming “add RAG” replaces cross-DB joins and cleaning; when structure is expressible in SQL, the guest leans SQL when you can (speaker opinion), embeddings for fuzzy semantics.
What public benchmarks say—and don’t#
Why a new DAB is needed#
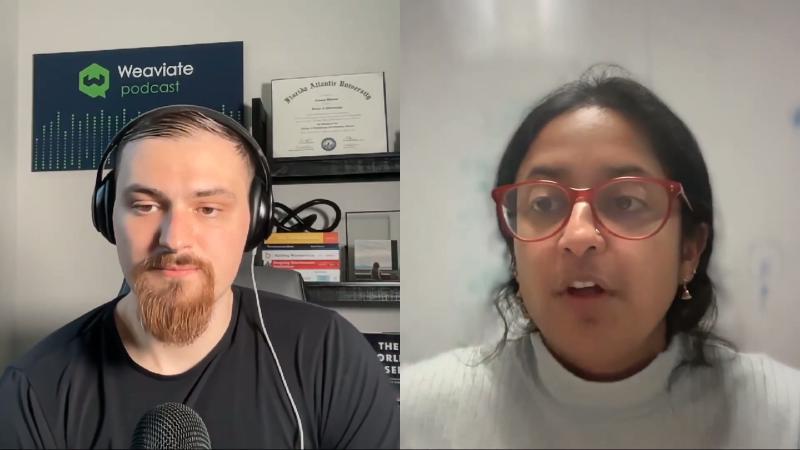
Can AI Agents Answer Your Data Questions? argues prior work mostly covers text-to-SQL slices, small in-context tables, or single-pipeline skills, and lacks systematic evaluation of full pipelines across multiple DBMSes. The guest cites at least 25 related benchmarks (speaker opinion; no verifiable list seen); “25+” should not be written as a paper theorem.
DAB scale (paper): 54 queries, 12 datasets, 9 domains, 4 DBMS types; workload shaped with Hasura PromptQL industry interviews (including ill-formatted key joins, multi-database integration).
Mechanisms and constraints#
Metrics (paper, verified May 2026):
- Best frontier model Gemini-3-Pro: pass@1 ≈ 38% (podcast ~37%, same order of magnitude).
- 50 independent trials per query; pass@50 up to ~69% under the same setup—large gap between “try many times” and “one paired run.”
- pass@k follows code-generation convention: success on a query if any of k independent runs is correct.
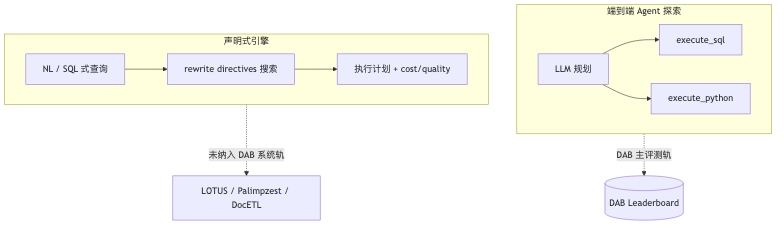
Deliberately not covered (by design, aligned with speaker opinion): semantic-operator systems (e.g. LOTUS, Palimpzest); realistic, auto-gradable writes; reliable multi-turn “simulated business user.” Each item still mostly has one gold answer, tension with real analysis’s many valid answers.
How to do it#
To reproduce or compare leaderboard rows, align model name, trials/query, hints. DataAgentBench repo and leaderboard row fields are all required.
Common pitfalls#
- Comparing third-party 5 trials/query, 60%+ directly to the paper’s 50 trials, 38%.
- Treating benchmark score as production-ready (write path, permissions, cost untested).
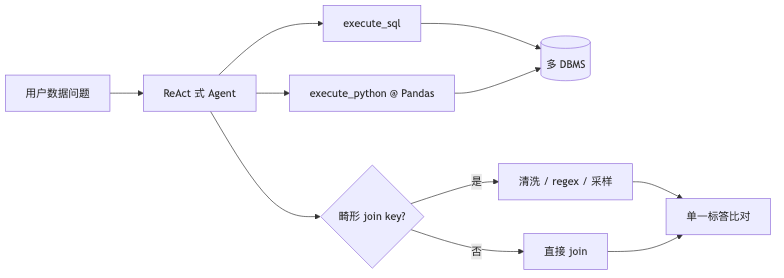
Multi-database integration: schema is not enough—you must “look at the data”#
Why#
DAB lists multi-database integration and ill-formatted key joins as core properties: e.g. PostgreSQL and SQLite together, id vs bid_* / bref_* prefix mismatch forces the agent to parse rather than assume equality joins. One company may run multiple SQL engines (warehouse + business MySQL); similar operators still don’t federate in one SQL (speaker opinion).
Mechanisms and constraints#
Metadata APIs list schema but often fail on ill-formed join keys (text, string arrays, etc.); trajectory failure types include Incorrect Regular Expression (FM4) (paper appendix). The guest stresses: look at the data before cleaning (e.g. union several regexes then join), not “assume in your head” (speaker opinion, aligned with paper direction).
How to do it#
-- Exploratory sampling (common in paper trajectories; not production best practice)
SELECT * FROM some_table LIMIT 5;
-- Then: design cleaning from samples, then join (logic sketch)
In production: controlled sampling APIs, column profiling, versioned transforms—not agent ad-hoc regex.
Common pitfalls#
- Assuming Spider 2.0 (enterprise text-to-SQL workflow) and DAB measure the same “cross-DB agent” skill—they overlap but benchmarks differ.
- Only adding schema text to the prompt without a repeatable sample-access policy.
Typical failure modes: can sample, but won’t “think like a DBA”#
Why#
When the tool surface allows “SQL to disk → Python,” agents take the path of least resistance. The paper provides execute_python (Pandas/Pyarrow), so SELECT * → flat file → Pandas is legal and an scalability trap.
Mechanisms and constraints#
Paper-verifiable patterns: stop after SELECT * LIMIT 5; catalog probing; heavy use of regex for text extraction; FM1–FM4 errors (shallow sampling, wrong plan, wrong column, wrong regex).
Speaker opinion (no fixed thresholds in paper): ~100k rows triggers “too many records”; DBA mental scale is often tens or hundreds of millions—scale mismatch leads to refusing full scans and over-relying on Pandas.
How to do it#
Add policy guardrails outside the agent (not replacing the model):
# Sketch: block ending after a blind LIMIT 5
if step == "sample" and rows < min_profile_rows:
require("distribution_stats or explicit justification")
For semantic-filter questions (e.g. longest sports article description), DAB items need semantic understanding; the evaluated object is still ReAct+SQL/Python, not LOTUS-style sem_filter (paper design choice).
Common pitfalls#
- Blaming regex failures only on “model not big enough” without changing tool feedback and intermediate checks.
- Banning Python—the paper shows Python is sometimes necessary; the issue is full export when one SQL would do.

Execution path split: SQL, Python, semantic operators, and declarative rewrite#
Why#
With multiple DBs, dialects, and non-SQL sources, there is no single silver-bullet engine. Guest vs host tension is essentially autonomous exploration vs declarative optimizer for data workloads.
Mechanisms and constraints#
| Path | Strengths | Limits (show + literature) |
|---|---|---|
| Multi-dialect SQL + skills | Clear semantics, auditable | No single-SQL federation; Mongo etc. agents often weak (speaker opinion) |
| Python/Pandas | What agents currently do best | High latency, poor scale; guest says overall still “pretty bad” (speaker opinion) |
| Semantic operators | NL map/filter/join; per-row LLM or synthesized regex | DAB did not test such systems; agents still prefer regex (paper takeaway supports tendency) |
| Declarative + rewrite search | DocETL rewrite directives + plan evaluation | Document/unstructured pipelines; tension with end-to-end Codex-style exploration |
DocETL (paper verified): user writes declarative pipeline; system uses agents to propose rewrite strategies (chunking, multi-level aggregation, gleaning, etc.), searching rewrite × prompt × model space; ~25%–80% over strong baselines on four tasks (task-dependent).
Palimpzest (podcast mishearing Palimpsest): declarative AI workload optimization, cost focus; guest’s Cascades-style analogy is directional, not formal paper terminology.
LOTUS: semantic operators + model cascade (small model + confidence threshold, then oracle) to cut cost.
How to do it#
CUAD example (510 contracts, 41 clause types; guest’s 512 is rounding): naive “41 attributes per document” → rewritable as 8×5 grouping etc.; DocETL agent searches chunking/grouping on samples (usage example, not CUAD paper mandate).
# Concept sketch: declarative operator chain (not real DocETL syntax)
pipeline:
- map: "extract clause types from chunk"
- reduce: "merge by contract_id"
Common pitfalls#
- Treating DSPy-optimized long BM25 strings as “maintainable skills” (guest criticism, no pinned journal version).
- Equating persistence differences with read/write semantics—guest clarifies DocETL and LOTUS/Palimpzest can persist; difference is optimization/rewrite philosophy (speaker opinion).
Agent-first databases: branching, speculation, and pass@k#
Why#
When LLM agents are the primary queriers, the classic “one submit, one result” transaction story is thin: agents need parallel trials, keep one success, discard failed exploration (speaker opinion, aligned with Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First—formal title is not literal overlords).
Mechanisms and constraints#
CIDR-direction paper proposes agentic speculation, branched updates: fork state on Neon–style copy-on-write branching, speculative writes, rollback failed branches. Verbatim pass@50–Neon binding not seen in fetched paper HTML; pass@k comes from DAB protocol, CIDR paper is a separate source. Guest self-describes as not deep on Neon implementation (speaker opinion).
How to do it#
Separate “50 trials in eval” from “branch strategy in production”: eval needs independent random seeds; production uses short-lived branches + merge policy so agents don’t dirty the main DB.
Common pitfalls#
- Treating branching as the only fix while ignoring permission model and cost (storage and compute per fork).
- Assuming all exploration auto-merges—business rules often need human confirmation.
Tribal knowledge: not a “data wiki,” but correction memory#
Why#
After cross-DB failures, teams want a “knowledge base” so the agent remembers Nike spelling, column aliases; offline washing in model-agnostic truth can mismatch executor behavior (regex vs LIKE vs column brand).
Mechanisms and constraints#
Arming Data Agents with Tribal Knowledge (Tk-Boost; guest cites colleague work, no Shankar authorship) defines tribal knowledge as reusable NL statements that correct agent misconceptions, not restate table facts. Stored in a TK Store, each entry has applicability conditions (SQL structure: columns used, clauses, etc.); flow is first-attempt SQL → retrieve by applicability → subquery-level fix. On BIRD and Spider 2.0, roughly +13.7% / +16.9% vs baselines (relative gains, not absolute accuracy).
Guest’s spoken “columns by SQL keyword + table/column” differs from paper schema; writing should follow the paper. Spirit aligns: memory often binds failure modes of a specific model (speaker paraphrase); offline generalization may be premature optimization.
How to do it#
1. Record "misunderstandings" in failed trajectories, not only facts
2. Write applicability per item (which query shapes trigger it)
3. Fix agent version in eval, then test memory transfer
Common pitfalls#
- Treating tribal knowledge as full RAG document dump.
- Not separating database facts vs correction statements (paper is explicit).
Retrieval and RAG: one index vs a thousand tables#
Why#
The host poses extremes: internet-scale single index vs dataset-search-style table sprawl; the guest prefers retrieval over RAG (skeptical of the generation part, speaker opinion). For data agents, agentic grep and tool chains are hard to embed in classic IR/DB frames—hybrid retrieval strategies are needed.
Mechanisms and constraints#
When structure is expressible, SQL first (speaker opinion); embeddings for fuzzy match. Weaviate product hybrid search and agent orchestration are a separate engineering path, not automatically equivalent to DAB scores.
How to do it#
Default retriever per source type: tables/columns → SQL + stats; text → vector + keyword; logs → time range + regex (with audit).
Common pitfalls#
- One vector collection pretending to cover normalized warehouse tables.
- Ignoring whether retrieval is executable (can it become runnable SQL/Python?).
Programs, data, and blurring “skill” boundaries#
In Claude Code skills, program description, personal habit, and context memory resist the classic CS compute/data split (speaker opinion, not formally verified). Spawn sub-agents resemble dynamic compute creation; resource boundaries blur—conflict with traditional DB predictable resource models, and partly explain why the guest bets on both declarative query optimization and public benchmarks.
If you are shipping this#
- Use DAB or a homemade multi-DB mini set for regression; report pass@1, pass@k, trials, hints—don’t convince yourself with single-DB Spider-style scores alone.
- Make “sample → clean → join” observable, cap blind
LIMIT 5stops and mindless regex; set rubrics for semantic-filter items or add LOTUS–style declarative operators as a contrast (not official DAB track). - Tool policy: allow Python, guard
SELECT *full exports by cost/row count; SQL-first for structured questions by default. - Memory: store misconception + applicability per Tk-Boost, fix eval model version; avoid one-shot “wash the knowledge base.”
- Infrastructure: if agents trial often, assess Neon branching or similar COW branches and agent-first architecture against your write semantics and compliance.
References and further reading#
- Can AI Agents Answer Your Data Questions? (DAB paper)
- DataAgentBench code and leaderboard
- Retrieval-Augmented Generation (Lewis et al., 2020)
- Spider 2.0: enterprise text-to-SQL workflow
- CUAD contract understanding dataset (510 contracts / 41 clause types)
- Atticus Project CUAD official page
- DocETL: declarative document processing and agentic rewrite
- DocETL project site and docs
- LOTUS: semantic operators and model cascade
- Palimpzest: declarative AI workload optimization
- SemBench: cross-engine eval for semantic systems (incl. LOTUS, Palimpzest)
- Supporting Our AI Overlords (agent-first data systems)
- Arming Data Agents with Tribal Knowledge (Tk-Boost)
- Weaviate Query Agent docs
- Weaviate Transformation Agent docs
- Neon database branching docs


