
AI-Powered Search: When RAG, Agents, and Classic IR Get Rewired#
Anyone who has wired RAG into production eventually hits the same tensions: who owns failures—retrieval quality or the agent loop; what is cheaper—long context or searchable history; what counts as the “production answer”—MTEB leaderboard models or your domain corpus. In roughly 54 minutes of conversation, Doug Turnbull (Relevant Search co-author) and Trey Grainger (Searchkernel; co-teaching AI-Powered Search with Doug) unpack those tensions from different engineering vantage points—no single verdict, only deployable boundaries and hypotheses still worth testing.
The episode is mostly a three-way video call; no OCR-readable architecture slides appear on screen. Technical claims below are tied to public literature and product docs; guest quotations are labeled speaker views.
Problem space: search is still here—only the interface changed#
In e-commerce and forum-style products, users still expect “search box + fast click”—precision and low latency come first. Legal discovery, medical literature, and recruiting workflows demand high recall, auditable, multi-turn exhaustiveness (speaker view). One vector stack cannot optimize both objective functions at once; NDCG@k, Recall@k, MRR, and related metrics also do not collapse into one leaderboard score across task types on MTEB.
Agents turn “query the index” into tool calls and “assemble context” into prompt engineering—Trey places that alongside classic relevance engineering: content, domain, and user context buckets mirror agent-side prompt management (speaker view). The open question is whether decades of search-system index grounding and revealed preferences actually move into the agent loop.
Can agents replace a strong retriever?#
Common narrative#
Industry storytelling often implies agents can issue many queries, self-correct, and make a weak retriever “good enough”; coding-agent success with grep / keywords is then analogized to product search.
Guest divergence#
| Position | Key points |
|---|---|
| Iteration compensates for weak retrieval (host push) | Many queries, self-adjustment—do we still need to chase embedding benchmarks? |
| Strong retrieval and explainable matching still required (Doug) | On “good enough, stop training embeddings”: “you absolutely have to” keep improving (speaker view); grep/BM25 work partly because input→output is predictable, which helps agent reasoning. |
| BM25 + agent was viable (Doug, ~08:47) | Give the agent a simple BM25 tool; via query expansion, multi-strategy index queries, and aggregation, you might approximate semantic retrieval—no first-party benchmark here proves equivalence to dense retrieval (verification boundary). |
Mechanism / constraint: the agent loop solves policy search (which query next, when to stop); Okapi BM25 and a dense retriever solve the matching function for a single retrieval step. The two are orthogonal. Doug also stresses the harness: start/stop, reset context, avoid re-exploring already searched regions—sometimes dumber model + good harness is enough (speaker view), unlike the “million-token single window” route.
Minimal example (conceptual):
loop:
q = agent.expand(previous_hits, user_goal)
hits = bm25(index, q, k=50)
if agent.should_stop(hits): break
# Evaluate: Recall@100 on legal discovery, not one-shot MRR@10
Common pitfall: inferring from coding-agent lexical wins that product search can stop training embedders; in recall-first settings, weak retrieval + multi-turn agents can still miss critical documents (task-dependent evaluation).
Doug also notes: pure similarity ranking without filtering—vector neighbors find “mattresses like Purple” but cannot tell whether the user wants the Purple brand or the color purple; disambiguation needs index mining, facets, or classifiers (speaker view), not a single cosine sort.

Context: compress or make history searchable?#
Why it matters#
Long-running agents often compact context to save tokens—dropping early tool outputs and user clarifications, keeping only a summary.
Mechanism / constraint#
Trey and Doug (~11:46) argue: do not throw context away; log it to the side, scan when needed, and generate better context for the current prompt; today’s compaction wastes data and is fundamentally a search problem (speaker view). That aligns with RAG’s non-parametric memory idea: external retrievable store + pull on demand, not hard deletion inside the window.
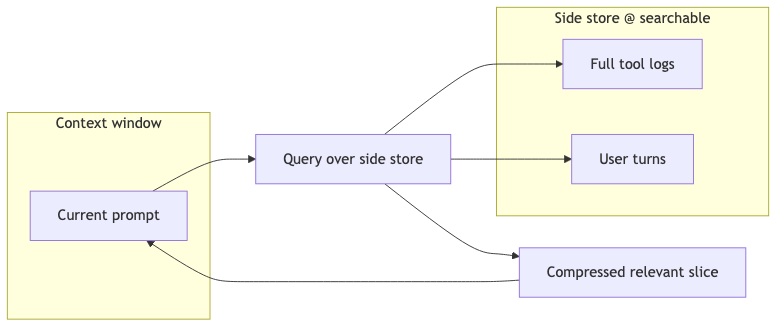
How to implement: maintain full-text-searchable side storage for the session (inverted index or vector index both work); each step fills the window via retrieve + summarize, not one-way discard.
Common pitfall: treating compaction as “efficient memory”; lost tool traces are often free supervision (speaker view), blocking later LTR or failure analysis.
Multi-stage RAG: understand the query before generation#
Why#
Single-stage “embed query → top‑k → LLM” on entity-sparse, heavily structured catalogs often mixes misunderstanding and retrieval failure in one hop, which is hard to debug.
Mechanism / constraint#
Trey (~17:35) describes multi-stage RAG: stage one is query interpretation—match query spans, entities, and terms in the index; stage two passes grounded hits to downstream RAG (speaker view). That differs from Lewis et al.’s two formulations inside the paper (“whole-passage conditioning” vs. “per-token passages”)—those are ablations in the paper; this is an index-mining engineering pattern (verified: RAG definition is literature-backed; stage split is interview).
How to implement#
stage1: spans, facets = interpret(query, index_stats)
stage2: hits = hybrid(spans, filters=facets)
stage3: answer = llm.generate(hits, query)
Common pitfall#
Treating Weaviate Query Agent filtering as “query understanding solved”—capabilities exist, but domain taxonomy and eval sets are still yours to build; the interview’s filter inspector naming does not align with public docs.
Query understanding: LLM classification vs. index grounding#
Common approach#
Use an LLM for domain classification (NAICS industry codes, product taxonomy), then write filters or generate answers.
Guest positions#
Doug: LLMs can classify quickly using public taxonomies in training data but hallucinate wrong codes (speaker view). Trey: Index-as-LM—extract spans from the query → verify against index fields, terms, aggregations → then facet and build the retrieval query; “almost like RAG for the LLM” for understanding, not only for final answer passages (speaker view).
Mechanism / constraint: code tables like NAICS have official hierarchies; LLM outputs must be checkable against corpus statistics (does a facet exist, does co-occurrence support it). Weaviate Query Agent docs describe semantic search with optional filters and aggregations; the interview’s filter inspector node name does not appear in public documentation (partially verified).
Minimal example:
spans = llm.extract_entities(query)
for s in spans:
assert index.term_stats(s) # Grounding: term must appear in index or aggregatable field
facets = index.top_facets(matched_field)
query = build_lexical_or_hybrid(spans, facets)
Common pitfall: skipping index statistics and letting the LLM emit filter JSON—errors on long-tail entities and brand/color ambiguity (e.g. “Purple mattress”) (speaker example).
Hybrid fusion vs. wormhole: two orthogonal paths#
Hybrid (classic industrial path)#
[Trey ~31:42]: run BM25 and dense in parallel, then merge/boost—Weaviate hybrid search docs verified: “runs both search types in parallel and combines their scores”, with relativeScoreFusion / rankedFusion and alpha weighting.
Why: lexical excels at exact identifiers (SKU, product ID); dense excels at semantic neighbors; parallel fusion mitigates single-path blind spots.
Common pitfall: treating fusion as a “stronger merge” version of wormhole—the goals differ (below).
Wormhole vectors (course / interview concept)#
Trey (~26:17–35:58): treat the query as a semantic representation of a document set and jump among sparse/lexical, dense, and behavioral spaces (e.g. matrix-factorization recommenders latent factors), not only fuse ranked lists side by side (speaker view).
Interview mechanism example: lexical hit set → aggregate (e.g. average) document vectors → find neighbors in dense space; reverse path dense top‑k → generate lexical/SKG queries. Community implementation wormhole-vectors README describes significant_terms aggregation, not “vector average”—inconsistent with subtitle “average” (verification boundary: average-vector operator labeled interview view).
Vector arithmetic intuition comes from Word2Vec analogies; Trey’s Darth Vader + puppy → cosplay puppy is informal and highly model- and domain-dependent (speaker view). Inverted indexes can be taught as very high-dimensional sparse term vectors (IR textbook level, not strict one-hot).
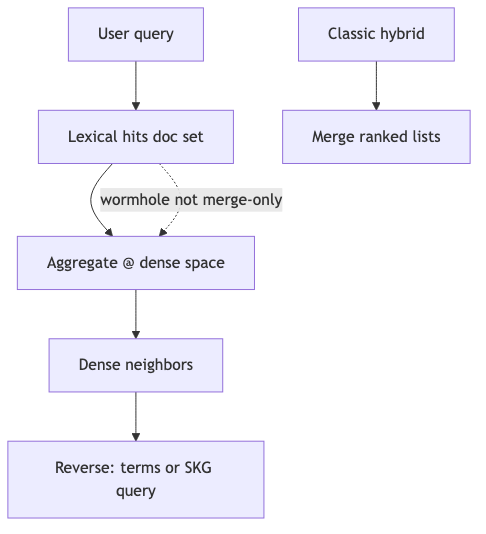
How to implement (pseudocode, interview version):
docs = bm25.search(q, k=100)
centroid = mean(embed(d) for d in docs)
neighbors = dense.knn(centroid, k=20)
Common pitfall: claiming three-space wormhole without behavioral/CF space; swapping in MTEB-top embedders for in-domain fine-tuning without A/B.
Leaderboard embeddings, domain factors, and behavioral signals#
Common approach#
Pick a MTEB top text embedder, plug into Weaviate or Elasticsearch, ship.
Guest positions#
Trey (~39:06): leaderboard models are a starting point; the “secret unlock” is wiring the query to your corpus, your domain, your users (speaker view)—aligned with MTEB’s “no particular text embedding method dominates across all tasks” (literature support). Doug (~41:51): decades of beating BM25 relied on domain ranking factors, not hybrid alone; embedding quality is necessary but not sufficient (speaker view).
Behavior > complex reranking (Trey, ~44:17): on head queries, pop-boosting items users already clicked/bought often beats obsessing over BM25 rank positions—consistent in direction with industrial Learning to Rank from clicks; “often beats” has no quantitative A/B in this episode (interview view).
Split training objectives (Doug, ~25:15): optimizing for ranking/embedding vs. clicks/purchases and other revealed preferences is a gray zone of different objectives—continuous with pre-LLM search/recommendation (speaker view).
Common pitfall: using Claude or similar to generate ranking functions without isolating an eval set—Doug warns of memorizing the training set (speaker view, consistent with general ML leakage).
Delivery shape: workflows before tool piles#
Common approach#
Give the agent many tools and hope the model composes a product.
Guest positions#
Trey (~53:46): use agents to design workflows and tools, then wire repeatable, shippable workflows; atomic agents on very narrow scopes can be small-model deterministic (speaker view). That contrasts with an open-ended tool loop—production search leans toward orchestration + primitive quality.
Doug adds: the search box still exists in high-recall flows, alongside mass impulse-click behavior (speaker view). The episode teases ColBERT late interaction as a next course topic—verified paper, complementary to this episode’s wormhole/hybrid discussion.
Trey also mentions Google’s “Generative UIs” direction: LLMs output HTML/JS/CSS for interactive surfaces (speaker view). This environment did not lock a first-party paper or blog URL matching the subtitle exactly (unverified); do not hard-depend on it for architecture—treat as a boundary note on “generative UI + search.”
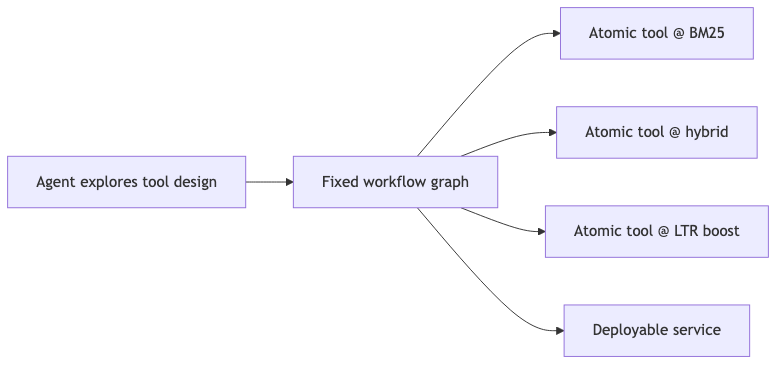
If you are shipping this#
- Fix the objective first: precision@10 merchandising search vs. recall@1000 compliance/legal discovery—then decide on an agent outer loop and whether to score MRR or Recall.
- Default to hybrid, then evaluate wormhole: baseline with official hybrid API for parallel BM25+dense; if jumping across spaces, compare wormhole-vectors significant_terms implementation to the interview’s vector average—do not conflate them.
- Ground query understanding in the index: after LLM entity extraction, filter hallucinations with facet/term stats; align taxonomies (NAICS) to official code tables.
- Use retrievable side storage for session memory, avoid irreversible compaction; treat historical tool output as searchable corpora.
- Wire behavioral signals into LTR or shallow boost, separate objectives from embedding training; any LLM-generated ranker features need hold-out leakage checks.
References and further reading#
- Retrieval-Augmented Generation (Lewis et al., 2020) — RAG parametric / non-parametric memory
- Massive Text Embedding Benchmark (Muennighoff et al., 2022) — no single embedding dominates all tasks
- MTEB Leaderboard — public leaderboard and task breakdown
- ColBERT: Efficient and Effective Retrieval via Late Interaction (Khattab & Zaharia, 2020) — teased at episode end
- Efficient Estimation of Word Representations (Mikolov et al., 2013) — vector analogy and compositionality
- Introduction to Information Retrieval (Manning, Raghavan & Schütze) — inverted indexes, BM25, evaluation basics
- Okapi BM25 (Wikipedia + Robertson survey chain) — lexical baseline
- From RankNet to LambdaMART (Microsoft Research) — LTR and click supervision
- Matrix Factorization Techniques for Recommender Systems (Koren et al. PDF) — behavioral latent factors
- Weaviate Hybrid Search concepts — parallel BM25+vector and fusion
- Weaviate Query Agent introduction — semantic search + optional filters/aggregations
- wormhole-vectors (community OpenSearch concept implementation) — dense↔sparse bridge (compare mechanisms to interview)
- AI-Powered Search (Grainger & Turnbull, Manning) — course textbook
- Relevant Search (Turnbull et al., Manning) — relevance engineering background
- U.S. Census Bureau — NAICS — official industry classification (fetch failed in this environment; link remains standard)
Evidence note: Weaviate hybrid, ColBERT, RAG, MTEB, BM25/LTR/Word2Vec per links above; wormhole vector averaging, BM25+agent≈semantic, pop-boost beating reranking, workflow-first, compaction-as-search labeled speaker view or partially verified; Google “Generative UIs” paper title not locked to a first-party source in this episode (unverified).


