
When Scalar Reward Isn’t Enough: Reflective Text Evolution in GEPA and Compound AI#
Compound AI systems chain retrieval, tool use, multi-step reasoning, and verifiers into a language program (DSPy terminology), yet in production they repeatedly hit the same wall: what you really want to tune are prompts / instructions / editable text components, while mainstream RL pipelines still compress the learning signal into a single scalar at the end of a trajectory. The paper GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning (arXiv:2507.19457; full name Genetic-Pareto) proposes another path—drive reflective mutation and per-instance Pareto retention with natural-language feedback—reporting on LangProBe six tasks an average of roughly +6% vs GRPO and up to about +20%, with at most 35× fewer rollouts (per paper abstract). Implementation: gepa-ai/gepa, integrated into DSPy as dspy.GEPA.
What follows is a technical synthesis for experienced engineers: common practice, paper/code-verifiable mechanisms, and speaker views from Lakshya A. Agrawal in the podcast are kept separate. This episode is entirely remote conversation—no on-screen architecture slides (images provide context only, not substitutes for Fig. 3).

Problem space: what compound AI optimization is optimizing#
Why: RAG, agents, PoT, ReAct, and related forms are unified in LangProBe as “LLM programs with control flow.” Architecture choices and the optimizer (Bootstrap, OPRO, MIPRO, GRPO, GEPA) jointly define the cost–performance frontier; swapping in a larger model is often less cost-effective than changing instructions or evolvable text.
Mechanisms/constraints: The paper denotes evolvable objects as program parameters (\Pi_\Phi), with weights (\Theta_\Phi) frozen. Optimization budget is usually metric / rollout call count (max_metric_calls), not GPU training steps. A prerequisite: you can supply per-instance automated (\mu) (scalar) and ideally (\mu_f) (text feedback)—compiler errors, rubric sub-scores, profiler output, LLM-as-judge comments, etc.
How to proceed (minimal interface): On the DSPy side, a metric can return Prediction(score=..., feedback=...); GEPA’s EvaluationResult likewise carries score and feedback.
# Conceptual sketch: feedback need not collapse to a single float
def metric(example, pred, trace=None):
ok = pred.answer == example.answer
feedback = "" if ok else f"expected {example.answer}, got {pred.answer}"
return dspy.Prediction(score=float(ok), feedback=feedback)
Common pitfall: Treating GEPA as a “annotation-free universal RL replacement.” The paper compares prompt evolution on the same language program; open-domain tasks without reliable verifiers, and judge-only optimization outside PUPA, remain systematically unverified boundaries (speaker view).
Scalar trajectories vs text feedback: learning-signal density#
Why: Group Relative Policy Optimization (GRPO) and similar methods aggregate reward at the end of long trajectories; with slow rollouts (compile + on-board execution), many comparative trajectories are extremely expensive. Guest motivation (aligned with paper abstract): rubric sub-items, suggested symbol names, length constraints, and other trace information are denser than a single scalar.
Mechanisms/constraints: The paper introduces feedback function (\mu_f), used alongside scalar (\mu). One of six tasks—PUPA—is implemented in the artifact as PAPILLON (data: Columbia-NLP/PUPA), with an LLM judge producing quality scores and natural-language feedback.
How to proceed: First define “what counts as failure and what the model should see when it fails”—then let the reflective-mutation LLM read traces and revise instructions.
Common pitfall: Assuming “with feedback you don’t need a score.” Code paths still require a comparable scalar for Pareto scoring and accept/reject; text is proposal direction, not the sole metric.
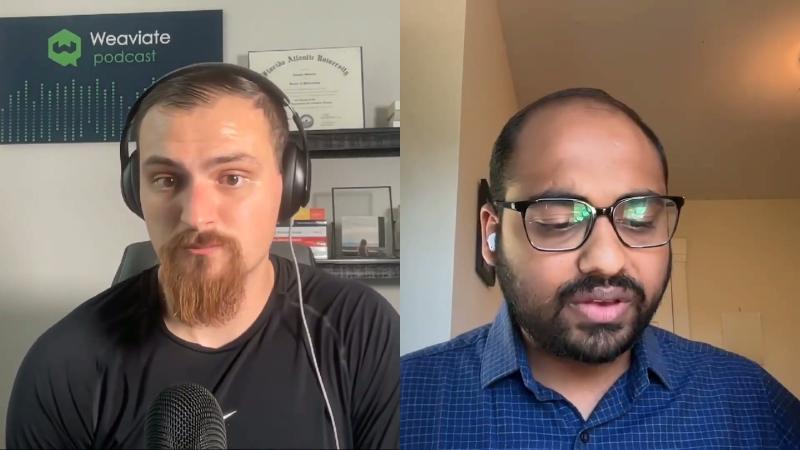
GEPA main loop: candidate pool, minibatch probe, full scoring#
Why: Globally greedily mutating only the “current highest aggregate score” prompt tends toward local optima; you need diverse candidates and per-instance tracking of who is best on the validation set.
Mechanisms/constraints (paper Fig. 3–4, engine.py):
- Maintain a candidate pool and Scores Matrix (each candidate × each validation instance).
- Each round: Pareto sampling → reflective mutation or merge proposes a new candidate.
- Evaluate on a minibatch first; if improved, full eval and add to pool.

Reflective mutation (ReflectiveMutationProposer): run traced execution on the selected parent, pass input/output and user-defined metric text to a reflection LLM, which produces a new instruction; system-aware merge combines textual insights across lineages in the evolution tree, then fully evaluates whether to add to the pool.
How to proceed: gepa.optimize() defaults to reflection_minibatch_size=3, meaning one traced execution on each of 3 different instances, not 3–4 repeated samples on the same instance (podcast “3–4 rollouts” is weakly consistent with the default—label as speaker view). With use_merge=True, merge proposals are enabled; after long runs, lineage is preserved via structures such as DspyGEPAResult.parents.
Common pitfall: Treating the “candidate pool” as k-best single-scalar ranking; the core is per-instance sub-scores (prog_candidate_val_subscores). Another pitfall: ignoring minibatch screening—proposals that don’t improve on the subset never enter full scoring; this is the key valve for max_metric_calls.

Genetic-Pareto: per-instance retention, not only chasing the aggregate champion#
Why: There may be instruction fragments that are “excellent only on Task 1”; if each round mutates only the aggregate top scorer, these non-champion insights are lost.
Mechanisms/constraints: Paper §3.1 Pareto-based candidate sampling; code defaults to frontier_type="instance" (ParetoCandidateSelector). Randomly pick a parent from the set of candidates that are best on each instance for mutation; after long runs, system-aware merge (MergeProposer) tries to merge textual insights across lineages.
The guest analogizes this to MAP-Elites quality-diversity thinking—the GEPA paper does not cite MAP-Elites; mechanistically it is closer to “per-instance elite sets,” not “implements MAP-Elites.”
Common pitfall: Tension between test-time “store best prompt per instance” and deployment “single universal prompt”—paper §5.1 inference-time usage allows overfitting a batch of hard tasks and sharing insights; whether to ship a single prompt is a product decision, not a required algorithm output.

Relative to MIPROv2 and GRPO: position in the DSPy lineage#
Why: The team’s DSPy trajectory ran Bootstrap FewShot → OPRO (prompt + score) → MIPROv2 (instruction + examples, Optuna search) → GEPA. The GEPA paper reports average 10%+ vs MIPROv2 (abstract), +12% on AIME-2025 as an example; vs GRPO (experimental config in gepa-artifact): six-task average +6%, up to about +20%, at most 35× fewer rollouts.
Mechanisms/constraints: GEPA replaces MIPRO’s Bayesian/Optuna program search with genetic-style proposal + Pareto sampling, and emphasizes iterative reflection on a single trajectory (reflective mutation). When comparing to GRPO, the artifact often uses settings like num_rollouts_per_grpo_step=12—the comparison is teleprompter-level prompt optimization, not pretraining RL.
Oral conflict (must be labeled): The guest once said up to about +25% vs GRPO; the abstract says up to 20%, with task-level 19% etc. in the body. 35× matches the abstract; 25% has no abstract support.
Common pitfall: Reading the title “Outperform Reinforcement Learning” as “eliminates all RL.” Paper scope is compound LLM systems with rich (\mu_f); the guest also believes future RL will absorb natural-language reflection (speaker view, not an established MMGRPO conclusion).


LangProBe experiments and §5.1 kernel / inference-time search#
Why: Need to compare architecture (CoT, RAG, ReAct, …) and optimizer Pareto jointly; the guest says better architecture often both raises performance and lowers cost, with the optimizer pushing the frontier further (speaker view + LangProBe design goal).
Mechanisms/constraints (verified): GEPA main table six tasks: HotpotQA, AIME, LiveBench-Math, IFBench, PUPA, HoVer (consistent with artifact get_benchmarks()). AppWorld is in LangProBe’s agent benchmark set but not in the GEPA paper’s six-task main table. Podcast mention of Baleen was not found in LangProBe directories or the GEPA PDF—likely oral confusion; the body does not rely on that name.
§5.1 (preliminary experiments—do not mix with main table):
- AMD XDNA2 / NPUEval and KernelBench + NVIDIA V100 CUDA;
- Paper wording: CUDA kernels >20% faster than PyTorch-eager on 35 representative tasks (not the guest’s loose “beats hand-written PyTorch baseline”; check tables).
Inference-time: Use the task set to solve as both (D_{\text{train}}) and (D_{\text{pareto}}), allowing “overfitting” to that batch and transferring insight across similar subtasks (paper §5.1; consistent with guest test-time narrative). Guest example: a batch of PyTorch→CUDA operators can share lessons from the same evolving prompt; you can also optimize for a single instance then discard updates—a different product mode than “train one universal prompt from scratch” (speaker view).
Counterintuitive but paper-supported: Optimization changes (\Pi_\Phi) (instruction and other text), but at test time what actually changes each round is code/output generated under that prompt; compiler/runtime errors written back into the prompt resemble bootstrapped data more than one gradient step (§5.1 and guest “change prompt = change solution” framing).
Sample-efficiency claim boundaries: Abstract says “even just a few rollouts” can yield large gains; guest says as few as one failed rollout + feedback is enough—the latter should be labeled speaker view. README gives expensive-scenario 100–500 metric calls vs GRPO 5,000–25,000+—same direction as 35×, but a marketing range; in production, use your own counter.
Common pitfall: Using old CITATION.cff text “four tasks / +10%”—conflicts with v2 abstract six tasks / +6%; trust arXiv abstract and PDF. Do not fold KernelBench paragraph numbers into the six-task main table as “comprehensive SOTA.”


Beyond prompt strings: optimize_anything and multi-objective Pareto#
Why: HNSW loops, CUDA snippets, any textualizable system component may iterate faster than weight fine-tuning (README / optimize_anything docs). Guest calls GEPA a text evolution engine (speaker view); HNSW-specific experiments were not found in the GEPA paper PDF.
Mechanisms/constraints: With objective_scores + frontier_type set to "objective" / "hybrid" / "cartesian", multi-objective Pareto tracking applies; reflection can see recall↑ and runtime↑ side by side, not only an aggregate scalar.
Common pitfall: Assuming you must split a separate repo “GEPA-as-a-text-evolution-engine”—capability is already in the gepa main repo and PyPI gepa.

Open disagreements (do not force a single conclusion)#
| Topic | Common practice | Guest argument | Evidence boundary |
|---|---|---|---|
| Agent vs fixed workflow | Product-level either/or | For system builders, both are LLM + control flow; difference is who writes the control flow | Speaker view; LangProBe includes both AppWorld and fixed pipelines |
| Domain knowledge in prompt vs weights | Fine-tuning camp vs prompt camp | Extract into prompt first, then encode into weights is more efficient | MMGRPO not in GEPA paper; mmgrpo_runs has no public README |
| Train-then-generalize vs test-time | Single deployed prompt | Former: feedback should transfer; latter: can be hyper-specific (e.g. concrete compiler error) | §5.1 + speaker view |
| One failed rollout enough? | RL needs many comparative trajectories | “As few as one” | Paper says “few rollouts”; “one is enough” is speaker view |
| GEPA vs JEPA naming | External GEPA | Team internally once called it JEPA | Speaker view (Yann LeCun JEPA naming conflict background) |
| Small model + search vs huge model | Stack parameters | 350M with search beats 500B (host paraphrase) | No experiment name this episode; cannot verify |
| Source of diversity | High-temperature best-of-N | Pareto + reflective mutation alone explores solution space | Paper emphasizes diversity; strict equivalence to best-of-N unproven |
DSPy integration status (as of 2026-05 lookup): dspy.GEPA exists on DSPy main; PyPI package gepa installs standalone; podcast “merging within days” exact date cannot be inferred, but engineering-wise you can follow the official tutorial now. Guest roadmap MMGRPO (prompt first, then RL for weights) and GEPA-like reflection for weight updates have no corresponding entries in paper or arXiv search—do not conflate with README’s BetterTogether.
If you are shipping this#
- Clarify (\mu) and (\mu_f) first: What text should the model see on failure (compiler error, judge rubric, leakage explanation), then choose
dspy.GEPAorgepa.optimize(); with open-domain score only and no verifier, keep expectations conservative. - Separate validation roles: (D_{\text{pareto}}) is for per-instance scoring and Pareto sampling; don’t treat “train leakage into selection” as a bug—inference-time mode intentionally sets train=pareto (§5.1).
- Budget around
max_metric_calls: vs thousands of GRPO artifact rollouts, GEPA marketing/README often cites 100–500 calls—same direction as paper 35×, but calibrate to your metric cost. - Don’t mutate only the aggregate champion: Confirm
frontier_type="instance"(default) fits multi-task / multi-skill instruction needs; useobjective_scoresfor multi-objective cases. - Cite numbers from the paper: Main table +6% / +20% / 35×; kernel and NPU as §5.1 preliminary; guest 25% only as an oral-discrepancy footnote, not an SLA.
References and further reading#
- GEPA paper (arXiv:2507.19457) — Genetic-Pareto, six tasks, metrics vs GRPO/MIPROv2
- GEPA paper PDF — Fig. 3–4 algorithm and §5.1 inference-time
- gepa-ai/gepa —
GEPAEngine,gepa.optimize()API - gepa-ai/gepa-artifact — reproduction and GRPO/MIPROv2 configs
- DSPy repository — language programs and teleprompter ecosystem
- DSPy GEPA tutorial — integration usage
- DSPy GEPA source —
GEPAFeedbackMetric,@experimental - LangProBe paper (arXiv:2502.20315) — compound AI benchmark definition
- LangProBe repository — AppWorld, HoVer, and other programs
- PUPA dataset — privacy rewriting + judge feedback
- optimize_anything introduction — textual parameter evolution
- PyPI: gepa — install and versions
- MAP-Elites (QD analogy background) — not a GEPA citation; for understanding Pareto-per-instance
- BetterTogether (arXiv:2407.10930) — “GEPA + RL” complementary direction in GEPA README, ≠ MMGRPO
- MIPROv2 implementation (Optuna) — Bayesian search side for comparison with GEPA


