
Judge-Time Compute: When LLM Evaluation Moves from a Single Score to a Composable Pipeline#
In production, RAG, agents, and guardrails all eventually answer the same class of question: Is the output trustworthy, auditable, and iterable? Common approaches run static benchmarks, attach an LLM-as-a-judge, or wire a DSPy metric into an optimization loop. Haize Labs co-founder Leonard Tang proposes another axis in public interviews and the open-source project Verdict: judge-time compute—stack structured, composable weak-model calls at judgment time, rather than defaulting to “the most expensive model scores once and that’s enough.”
This axis differs from treating eval as a pre-release checklist: it treats the judge itself as an engineerable subsystem—with schema, an execution tree, consistency metrics—and something that can plug into RL, red-team, or guardrail distillation pipelines. This article separates checkable documentation from speaker opinion or undisclosed detail; conclusions do not converge to a single recipe across benchmarks. Readers should condition on their own SLOs (latency, dollars per thousand judgments, explainability).


Problem space: what evaluation, preferences, and “eval companies” are competing over#
Why static leaderboards do not fill the enterprise gap#
The industry habitually equates “doing eval” with another SQuAD-style dataset or an LMSYS Chatbot Arena Elo board. Leonard Tang’s position (speaker opinion) is that most enterprises do not have SQuAD-like gold answers; the real need is to train a customer-owned judge on very sparse preference signals while asking humans as little as possible. That does not contradict a “for loop over scores → table” UX—he considers table-style views relatively mature; the gap is how domain experts annotate the current judge and how to densify annotations into automated reward.
From an engineering split, static sets suit regression (“did this model version regress?”); preference sets align “which reply sounds more like our brand/compliance”; fuzz simulates malicious or edge users when there are no production traces yet. Budgets differ: static sets are expensive to label once but cheap to run; preference labeling is cheap per item but hard to scale; fuzz is compute-heavy but can find systemic holes a pointwise judge misses. The interview does not claim to replace MLOps observability; it stresses that eval and red-team should share the same judge semantics, so online metrics and offline judges do not talk past each other.
| Paradigm | Common practice | Tension in the interview |
|---|---|---|
| Static eval | GT dataset + accuracy | Enterprise data often has inputs but no standard outputs |
| Preference eval | Pairwise / Arena Elo | Needs a custom judge + active sampling for labels |
| Adversarial testing | Red-team, jailbreak search | Haize stresses fuzzing user interactions, not only leaderboards |
Mechanisms and constraints#
Haize positions itself as custom reward models (judges) and user-interaction simulation (fuzz testing) (speaker opinion), with DNA from adversarial robustness rather than observability dashboards. On the public repo side, the get-haized README states it includes red-teaming, fuzzing, and optimization algorithms; VAE, reverse LM, and similar items mentioned in the interview do not appear in the README checked here (evidence boundary: interview list ⊃ public docs).
How to think about it (minimal mental model)#
Define three object types first, then pick tools—not the other way around:
- System under test (RAG / agent / generator)
- Judge pipeline (single pass vs multi-path + aggregation)
- Human signal entry (full scoring vs comparative A/B + qualitative rationale)
Common pitfalls#
- Assuming an “eval company” is by default a benchmark vendor—the interview explicitly distinguishes them (speaker opinion).
- Copying academic static sets when preference data is almost absent—may mismatch production data shape (speaker opinion).
- Buying an “eval platform” without a domain-expert workflow—pretty tables can still misalign the judge with business standards.
Evidence boundary: Customer names (OpenAI, Anthropic, AI21, etc.), funding, and pricing are interview claims; comparisons to industry products like Patronus Lynx/Glider are external reference, not proof of Haize capabilities.
Judge-time compute and test-time compute#
Why the naming matters#
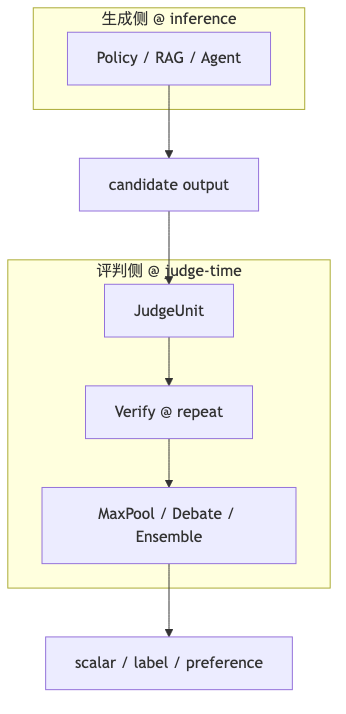
Test-time compute usually means generation-side extra inference—search, self-consistency, or verification at decode time (e.g., sample multiple completions and pick the best, or execution-based filtering on code). The host once misspoke “test time”; Leonard insists on judge-time compute: spend extra compute on the judgment path, where judgment itself can be parallel probes + serial verify + aggregate, not a single forward pass. The open Verdict paper title and README both use judge-time compute and attribute the inductive bias to scalable oversight (debate, ensembling, etc.)—verified.
If your system already uses o1-style long reasoning on the generation side, stacking comparable reasoning on the judge side roughly multiplies cost. Judge-time compute economics come from many small models + structured output reducing variance, not simply swapping the judge for a reasoning model. Whether to adopt it depends on whether judge errors are random-noise or systematic blind-spot—the former suits ensembling; the latter may need rubric changes or domain tools (retrieval, calculators, rule engines).
Mechanism: correspondence with scalable oversight#
Weak-to-strong generalization and weak LLMs judging strong LLMs ask whether weak supervisors can constrain stronger models. Verdict implements debate, ensemble, verify, and similar patterns as composable primitives (DebateUnit, ModelEnsembleJudge, MaxPoolUnit, etc.—see the repo)—verified class names and paper citations; interview “wargaming” has no built-in primitive named Wargame (interview terminology).
What to do#
Separate two budget lines: generation tokens and judgment tokens. If SLO allows, prioritize repeat, pairwise, and pool on the judge side before using an o1-class reasoning model for a single judgment—section P05 below explains that is not always worth it.
Common pitfalls#
- Equating DSPy MIPRO-style “compound system + meta-optimization” with judge-time compute—Verdict can be a DSPy
metric, but the inductive bias differs (interview opinion + cookbook integration verified). - Assuming verification is always cheaper than generation—in RAG, if the judge must also judge whether retrieval was correct, difficulty can approach a full agent task (speaker opinion).
Verdict: a declarative judge pipeline#
Why a library instead of hand-written debate each time#
Repeatedly building judge → verify → vote pipelines for customers was folded into the open library Verdict (speaker opinion, aligned with README motivation). The core is Unit / Layer / Block / Pipeline composition plus judge primitives such as CategoricalJudgeUnit, PairwiseJudgeUnit, and BestOfKJudgeUnit—verified in README Quickstart. Layer’s repeat duplicates an entire subgraph (e.g., judge+verify each), not only sampling the last layer three times; related to “call the API three times on the same prompt” but at a higher abstraction, easier to align latency and success rate in a visual execution tree.
The interview lists many debate variants: parallel debaters + meta judge, round-robin, shuffled order, pros/cons dual judges, etc. Public code offers DebateUnit, ConversationalUnit, and similar blocks, but no one-click “automatically pick optimal debate topology”—topology still depends on task and manual experiment (speaker opinion + source verified primitives, not verified automatic search).
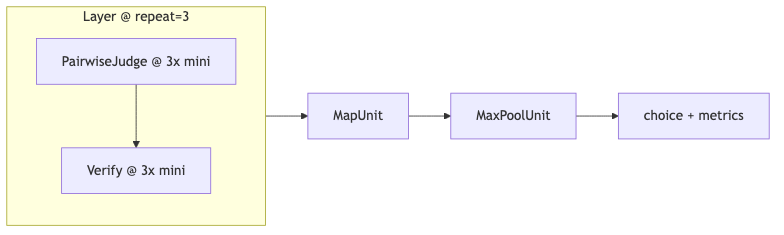
Mechanism: Judge → Verify → MaxPool#
Demo frames match README (OCR shows gpt-40, CategoricaljJudgeUnit as recognition errors):
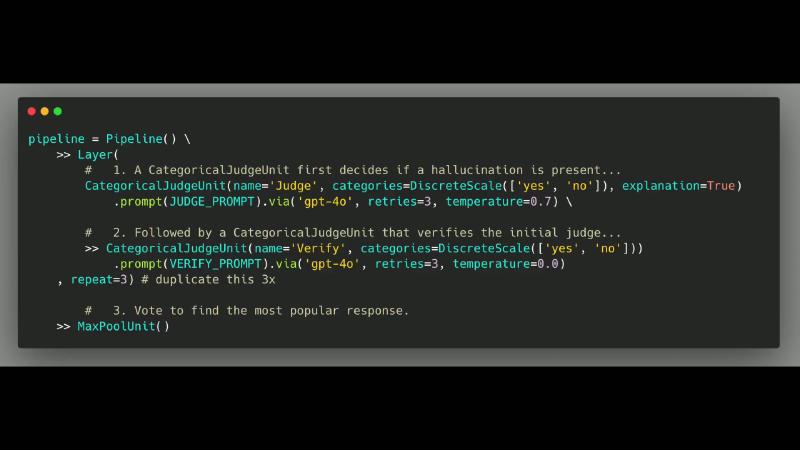
CategoricalJudgeUnit(name='Judge'...) → CategoricalJudgeUnit(name='Verify'...) → repeat=3 → MaxPoolUnit(); via gpt-4o, temperature 0.7 / 0.0.
MaxPoolUnit majority-votes categorical fields; Layer(..., repeat=3) copies the whole sub-layer—verified.
What to do (minimal example)#
pipeline = Pipeline() \
>> Layer(
CategoricalJudgeUnit(name='Judge', categories=DiscreteScale(['yes', 'no']), explanation=True)
.prompt(JUDGE_PROMPT).via('gpt-4o', retries=3, temperature=0.7) \
>> CategoricalJudgeUnit(name='Verify', categories=DiscreteScale(['yes', 'no']))
.prompt(VERIFY_PROMPT).via('gpt-4o', retries=3, temperature=0.0)
, repeat=3) \
>> MaxPoolUnit()
“Declarative” on the open-source side mainly means schema validation and pipeline composition (speaker opinion: commercial prompt/pipeline optimizers are not fully open).
Common pitfalls#
- Assuming the open package includes DSPy MIPRO-level automatic prompt search—the interview calls optimizers commercial “core alpha” (speaker opinion).
- Ignoring that
VerifyandJudgecan use different temperatures—the demo deliberately uses 0.7 for explanations and 0.0 for verification (verified in README).
Pairwise, consistency, and the execution tree#
Why a single categorical judge is not enough#
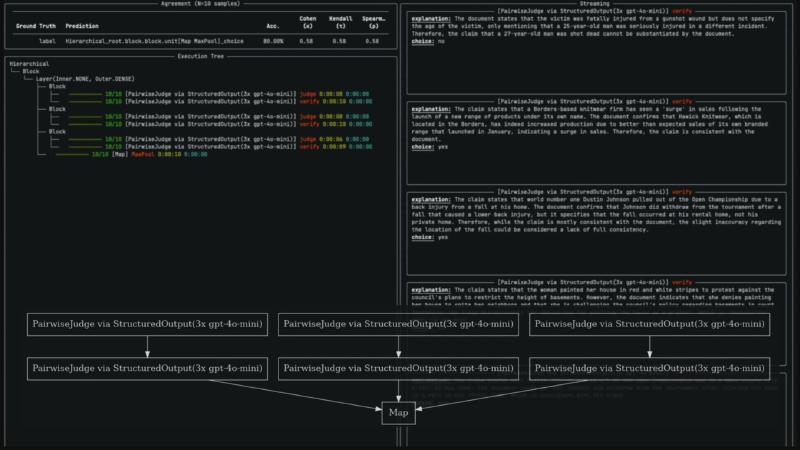
Factuality, groundedness, content moderation, and similar tasks often need pairwise comparison and structured output: the model outputs not only yes/no but an auditable explanation, so humans can fix the judge’s reasoning chain instead of rewriting the rubric from scratch (speaker opinion). Verdict provides PairwiseJudgeUnit + StructuredOutputExtractor; experiment panels show Agreement (N=10 samples) with Cohen κ, Kendall τ, Spearman ρ—verified in experiment.py and the hierarchical notebook.
Demo samples involve news-like claims (e.g., athlete withdrawal, corporate sales figures) against documents: the streaming panel shows how the judge trades off “mostly aligned” vs “detail mismatch.” That UI’s value is locating failure samples to execution-tree nodes (e.g., a verify step at 0/10), not only a single aggregate score—more direct for engineering iteration than a leaderboard rank.
Mechanism: Map + MaxPool hierarchy#
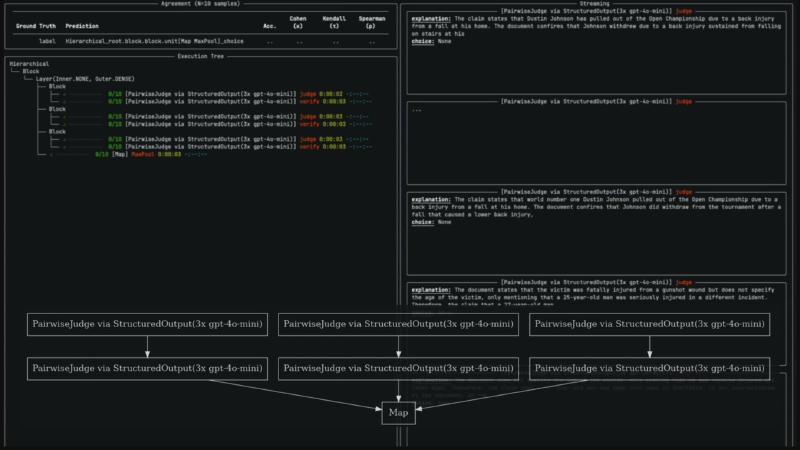
Execution-tree labels like Hierarchical_root.block...unit[Map MaxPool]_choice come from runtime visualization (not a standalone DSL keyword Hierarchical_root). MapUnit runs parallel judge/verify paths, then MaxPool aggregates—consistent with OCR and source (partially verified: OCR 3x gpt-4o-mini may differ from notebook default gpt-4o).
Metric meaning: Acc. is (ground_truth == prediction).mean(); κ/τ/ρ measure rater agreement, not pass@k or MRR (verified).
What to do#
Before launch, run a small Agreement panel on the judge pipeline: if κ stays low, fix prompt/schema before upgrading model tier; do not extrapolate a one-off 80% Acc. demo to full production. Also log per-node latency (execution-tree timings like 0:00:08) and verify pass rate, not only Acc.—or verify becomes cosmetic.
For pairwise tasks, specify whether you compare two replies, reply vs document, or reply vs retrieved chunk—rubrics are not interchangeable. StructuredOutputExtractor splits explanation and choice into parseable fields for downstream rules (e.g., choice=yes but explanation contains negation → human review).
Common pitfalls#
- Reading Cohen κ=0.58 as “58% business accuracy”—different quantities.
- Assuming debate / round-robin / shuffled-order variants are all “one-click” in Verdict—mostly composable primitives; you build the pipeline (speaker opinion + source verified
DebateUnit).
Weak-model stacking vs one strong pass: numeric boundaries#
Why “eval must use the most expensive model” deserves skepticism#
The interview claims multi-path LLM judges vs a single judge and frontier reasoning models can yield roughly 10–20 percentage points absolute improvement (speaker opinion). Paper arXiv:2502.18018 reports per-task numbers, e.g. hallucination detection Verdict(GPT-4o) +14.5 pp vs prior SOTA, and with GPT-4o-mini still +3.05 pp; ExpertQA Verdict(4o) 79.17% vs o1 69.91% (+9.28 pp); XSTest Verdict 96.44% vs o1 96.00% (~+0.44 pp)—verified, and cannot be merged into one 10–20% constant.
When reading tables, fix three questions: (1) percentage points or relative gain? (2) Is the baseline judge fair (same prompt budget, same temperature)? (3) Same domain as production—when content moderation is near saturation, 0.44 pp and 14.5 pp mean very different things. The paper background cites generative verifier / Best-of-N literature with “16–40% improvement” in another problem setting—do not paste that onto Verdict pipelines (evidence boundary).
| Benchmark | Verdict (4o-mini) | o1 | Reading |
|---|---|---|---|
| ExpertQA | 67.72% | 69.91% | mini stack does not beat o1 (verified) |
| ExpertQA | 79.17% (4o) | 69.91% | Verdict with 4o backbone above o1 |
| JudgeBench | mini 50.00% | 75.43% | even Verdict(4o) 63.55% below o1 |
Cost: README/paper qualitatively say “fraction of cost and latency”; the interview mentions prefix / KV cache reuse across stages (speaker opinion; skunkworks not in public tables with a unified cost multiplier).
Mechanism#
The logic: structured redundancy + aggregation trades many weak calls for one strong reasoning pass; whether it pays depends on task difficulty and judge variance. Paper Figure 3 Pareto narrative supports “better and cheaper on some tasks,” not dominating o1/o3-mini on every benchmark.
Engineering skunkworks in the interview: reuse prefix / KV cache across Verdict stages; add nonce to prefix when diversity is needed (speaker opinion). Under API billing, that can materially change “many mini calls” total cost, but savings are not in the public paper as a unified dollar figure (evidence boundary). Self-hosted deployments controlling weights and cache may have different economics than pure API users.
What to do (rough cost mental model)#
Let (C) = one strong judge cost, (c) = one mini call, (k) = repeat count, (r) = verify on/off (2× chain length). Rough Verdict single-layer cost (\approx k \cdot r \cdot c) (plus negligible pool). Increasing (k) helps monotonically only when error is mostly randomness, not rubric error—otherwise fix prompt / schema / tools first.
Common pitfalls#
- Generalizing “gpt-4o-mini stack beats o1”—false on ExpertQA / JudgeBench (verified).
- Replacing table numbers with marketing beat reasoning models like o1—state backbone and dataset.
Aligning a customer judge: labeling UX, RL, and meta judge#
Why “we have labels so SFT” may be wrong for judges#
Leonard argues essentially no SFT on judges (overfitting, hurts implicit reasoning—speaker opinion), favoring RL + judge-time scaling; reward from a meta judge (stack Verdict-like judges to judge the judge, “directionally correct” on a little customer data with reward aggregation canceling error—speaker opinion). Public docs cannot verify a three-layer framework (implementation / query / UI) or active-labeling algorithm detail.
The three layers in the interview: (1) judge implementation and learning algorithms; (2) which samples to query for human labels; (3) how the UI presents them—showing only samples that materially affect the judge currently being trained (speaker opinion). Spirit is similar to active learning’s uncertainty sampling, but the objective is “improve the judge, not the generator.” With only dozens of labels, spend budget on borderline pairs (A/B where the model is most uncertain) rather than uniform points to move κ.
On parameter updates, the interview mentions aggressive parameter-saving beyond LoRA with undisclosed detail—do not assume plug-and-play weights; a realistic start is Verdict as an offline gold-standard generator, then distill to a small online model.
Mechanism: comparative signal and three-layer design#
The interview stresses comparative answers (two replies A/B on the same input) collecting “why A beats B” qualitative gradients, better than unstable human 1–10 scores (speaker opinion). Spirit is close to RLHF/DPO pairwise paradigms, but cannot reverse-prove Haize product implementation (evidence boundary).
Meta judge aligns conceptually with DeepSeek inference-time scaling for generalist reward modeling: paper uses SPCT, adaptive principles + critiques at inference, Voting@k / MetaRM@k—verified title and methods; interview “instance-specific rubric” is conceptual analogy—the paper uses principles / critiques (not verbatim).
LMUnit (Contextual AI, not a Stanford-led project) uses natural-language unit tests + a scoring model for fine-grained eval—close to in-context LLM scoring; interview “Stanford LM-Unit” is misleading (verified institutional attribution).
What to do#
If building your own alignment loop: design pairwise + rationale labeling UI first, then choose RL or DPO; before SFT on a judge, use a Verdict pipeline to see whether Agreement and task Acc. diverge.
Common pitfalls#
- Treating meta judge as a noise-free oracle—the interview explicitly needs stacking and aggregation (speaker opinion).
- Ignoring that humans iterate judge reasoning, not rewriting rubrics from scratch—a workflow claim, no public benchmark.
RAG, fuzz, and production guardrails#
Why RAG breaks “verification is easier than generation”#
If the judge only checks whether the answer is grounded in given context, verification is often lighter than generation; if it must also judge whether retrieved context is correct, that is equivalent to redoing retrieval (speaker opinion). Parametric knowledge conflict (context vs parametric memory) can be localized with counterfactual diffs with/without context, but no general solution (speaker opinion). Engineering: split the judge into two levels—level one only whether cites support the sentence; level two on sample or high-risk requests runs retrieval audit (extra index queries, version, source allowlist), avoiding agent-level cost on every user message.
Production cases appear qualitatively: lightweight judges inside agent reasoning loops, Constitutional Classifiers, hallucination distillation, etc. (speaker opinion, no public reproduction package). Unlike “eval only offline,” guardrails are an online subset of judge-time compute with tighter latency budgets—usually must distill.
Fuzz and agentic eval#
Public side: BEAST-implementation for beam-search adversarial attacks (arXiv:2402.15570), dspy-redteam multi-layer attack/refine. Agents for evals are described as a looser form of judge-time compute: more tokens, more steps; some tasks need judge capability matching production agents (speaker opinion).
Fuzz complements static sets: fuzz finds tail of the input distribution (jailbreaks, leak induction, malformed JSON); static sets monitor known business Q&A regression. Fuzz alone without a calibrated gold judge can look like “attack success down but UX worse”—still need humans or a high-fidelity Verdict pipeline to define “bad.”
A generic judge + one prompt covering every vertical is “unreasonable and impossible” (speaker opinion). Default path: domain rubric / unit test (LMUnit-style) + sparse preference + judge-time compute denoising, not waiting for one 70B universal hallucination detector.
Guardrails: safety vs compliance#
Cloud safety filters (Azure, Bedrock, etc.) are “enough” for many customers (speaker opinion); enterprises more often lack industry / brand guardrails. Claimed path: high-fidelity judge (Verdict + training) → distill to small model, cut latency (speaker opinion). Patronus Lynx/Glider are industry comparison only, not Haize product claims.
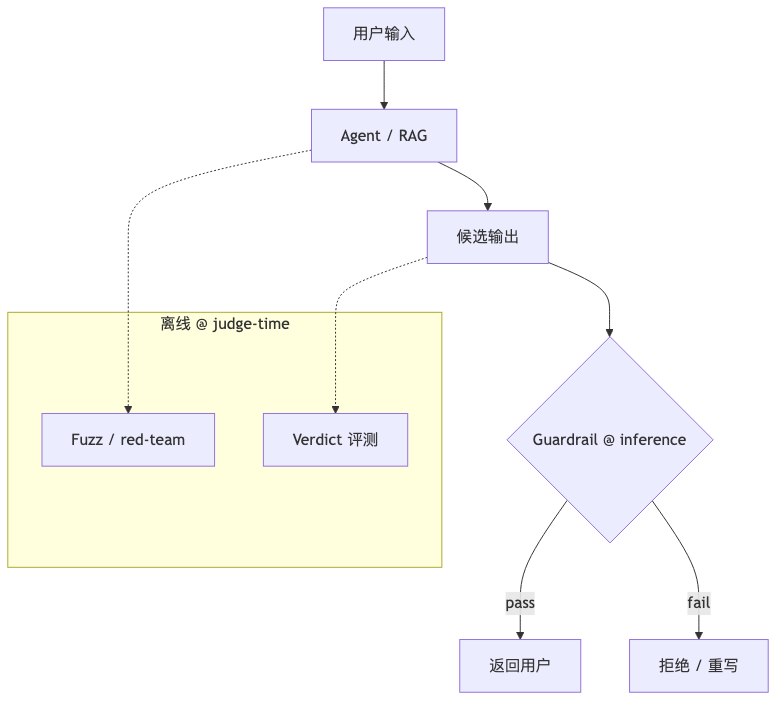
Common pitfalls#
- Another generic safety API equals business compliance—interview says need is often custom (speaker opinion).
- Mechanistic interpretability (SAEs, etc.) as near-term auditable tooling—guest sees it as still fragile, limited actionability (speaker opinion).
Verdict × DSPy: metric hook, not a replacement framework#
Why the two frameworks get bundled#
DSPy is analogized to “PyTorch for LLMs”: program + teleprompter optimizes prompts and module graphs. Verdict offers declarative judge-side primitives and scalable-oversight bias. Intersection is the evaluation function: DSPy metric takes example, pred, optional trace, returns scalar or boolean signal, driving Evaluate and optimizers like MIPRO.
Verdict can be the program’s metric (verified: dspy.md cookbook, dspy-redteam metric(..., use_verdict=True) → verdict_judge() → ModelEnsembleJudge). You can use a Verdict judge stack as a “more expensive metric” on the same DSPy program without baking debate into every signature.
Mechanism and boundaries#
- Verified:
dspy-redteamwires an ensemble Verdict pipeline todspy.evaluate.Evaluate. - Speaker opinion: Verdict also as guardrail / RL reward; DSPy is one integration example.
- Verified: set
litellm.cache = Nonebefore integration to avoid LiteLLM + Instructor issues.
Omar Khattab (okhat) appears in contributors (verified account link; interview “lots of feedback” cannot be fully proven by commit count).
What to do#
If you use simple answer_exact_match or single LLM scoring in DSPy, replace the metric implementation with a Verdict pipeline incrementally: keep the optimization target, compare pass rate and optimizer iterations; then decide whether to budget judge-time compute inside the teleprompter.
Common pitfalls#
- Verdict plugged in means “DSPy will search debate topology”—open Verdict does not include MIPRO-level pipeline search (speaker opinion: commercial optimizer not fully open).
- Too much
repeatinsidemetricmakes each MIPRO step explode—subsample dev set or tier evaluation.
Theoretical gaps and future work (no unified answer)#
Closing notes: why DPO / PPO / GRPO / KTO can fit reward from pairwise preference is still theoretically incomplete (speaker opinion). Teams already train on preferences, but reward model design (judge-time compute, meta judge, generative RM) still relies heavily on experience and ablation.
Another thread: drift in “superintelligence” definitions—Turing test, sales role-play, chess vs everyday tasks like appropriate Slack replies use different bars (speaker opinion). Practical takeaway: regardless of macro narrative, verification, steering, evals remain investable engineering axes—if you clarify what you judge and how much judge compute you spend.
Haize 2024 commercialization and pre-release testing for model vendors are interview claims, not independently verified; procurement should demand reproducible benchmarks and contractual data handling, not brand narrative alone.
Evidence grading recap: verified claims can cite arXiv table numbers or GitHub lines in PR review; speaker opinion belongs on an “ablation TODO” list, not external SLAs. Unmarked text is engineering common sense, not Haize official commitment. Architects can read this as three stacked maps: (1) data shape (static / preference / adversarial) sets collection cost; (2) compute shape (test-time vs judge-time) decides which side absorbs error; (3) deployment shape (offline eval vs online guardrail) decides distillation and caching. Mis-pick one layer and debt shows elsewhere—static Acc. only while production sees OOD jailbreaks, or online blocks so strict usability collapses. No single diagram answers “which vendor to buy.”
If you are shipping this#
- Draw judgment boundaries first: groundedness only, or also retrieval correctness—the latter budgets like an agent subtask, not one LLM score. Put judge output schema (label + explanation + cite spans) in API contracts for product audit logs.
- Build Judge→Verify→Pool with Verdict or equivalent primitives; run Agreement (κ/τ/ρ) and Acc. on 10–50 gold labels before scaling benchmarks; when citing paper tables, state backbone (4o vs 4o-mini) and dataset. Low κ → fix annotation guide ambiguity before bigger models.
- When preference data is scarce, prioritize comparative A/B + rationale labeling UX, then RL/DPO; do not default to judge SFT (interview pushback needs your own ablation). When meta judge is only a directional signal, keep human spot-check channels.
- Production guardrails: offline fuzz with get-haized / dspy-redteam + Verdict; online distill a small judge; separate cloud safety filters from brand compliance. Log which node triggered reject/rewrite—avoid black-box blocks.
- With DSPy, treat Verdict as
metric, not the whole optimization stack—separate budgets and observability for generation optimization vs judge-time scaling; pin judge version during optimizer iterations or the teleprompter chases a moving target. - External communication: do not summarize multiple benchmarks with one percentage; internally use the execution tree to locate failure layer (judge vs verify vs pool); externally speak in per-domain SLA terms.
References and further reading#
- Verdict paper (arXiv:2502.18018) — judge-time compute and benchmark tables
- Verdict GitHub repository — API, Quickstart, Debate/Ensemble primitives
- Verdict documentation site — guides and results entry points
- Haize Labs GitHub organization — related tooling index
- Awesome LLM Judges list — papers and implementations
- DSPy official docs: Metrics —
metriccontract and evaluation loop - Verdict × DSPy Cookbook — integration example and cache notes
- dspy-redteam example — Verdict as red-team metric
- Weak-to-strong generalization (OpenAI PDF) — scalable oversight background
- Weak LLMs judging strong LLMs (arXiv:2407.04622) — weak supervisors on strong models
- Generative Verifiers (arXiv:2408.15240) — generative verification and test-time narrative
- DeepSeek: Inference-Time Scaling for Generalist Reward Modeling (arXiv:2504.02495) — inference-time scaling for generalist RM
- LMUnit (arXiv:2412.13091) — natural-language unit-test-style fine-grained eval
- LMSYS Chatbot Arena technical report (arXiv:2403.04132) — preference / Elo paradigm
- Get Haized / fuzzing suite README — automated red-team and fuzz entry points
- BEAST adversarial attack paper (arXiv:2402.15570) — discrete-search jailbreaks (partial overlap with interview stack)


