
When Format Constraints Hurt LLMs: A Split Between Agent Pipelines and Benchmark Evaluation#
Vector retrieval, tool calling, and multi-step agents embed LLMs in Compound AI pipelines: intermediate states must be parseable, routable, and retriable. In production, JSON is widely used to pass parameters between steps; public leaderboards and academic benchmarks still score natural-language (NL) final answers with exact match or accuracy. In Let Me Speak Freely?, Appier AI Research’s Zhi Rui Tam turns this split into reproducible experiments: the same “structured output” techniques often lower scores on reasoning tasks and raise them on discrete classification. Below we unpack the mechanisms—there is no single verdict; task symbol, API generation (JSON-mode vs JSON-schema), and schema depth can flip the sign.
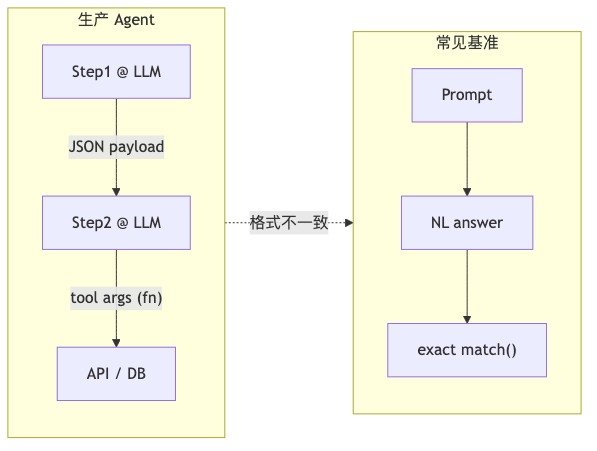
Why production and evaluation diverge#
Why: Orchestration frameworks (LangGraph, CrewAI, etc.) need parseable intermediate states; ops and eval harnesses still default to exact match / accuracy on NL final answers. If production runs JSON mode or Structured Outputs end-to-end while leaderboards report only NL scores, deployed performance and public rankings can systematically misalign (consistent with the paper’s Introduction and Compound AI Systems motivation).
Mechanism: Format restrictions change the token space available to decoding—not merely post-processing, but biasing or pruning the generation trajectory itself.
How to: On your own dev set, report three curves in parallel: NL, FRI, and JSON-mode; if you use OpenAI Structured Outputs, add a fourth—they can differ by nearly 5 pp from JSON-mode on GSM8K (Table 2: 91.71 vs 86.95). Agent benchmarks should explicitly include a “JSON between steps” condition (as the paper urges; PlanBench can supplement planning-style evals—not used in the main experiments). The same applies to RAG: retrieved chunks may be structured, but whether the answer reasoning chain should be JSON-constrained needs A/B testing with task symbol—not a default full-pipeline schema.
Pitfall: Treating “leaderboard SOTA” as “JSON pipeline SOTA” without format-aligned controls.
po Dilamllr My, y te,).
A spectrum of constrained generation: FRI, JSON mode, two-stage, function calling#
| Path | Where constraint applies | Typical guarantee |
|---|---|---|
| FRI (Format-Restricting Instructions) | Schema embedded in prompt | No hard decoding guarantee; format violations remain common |
| JSON-mode | Provider-constrained decoding | Valid JSON; paper ties OpenAI/Gemini behavior to function calling API implementation |
| NL-to-Format | Two calls | NL reasoning first, then convert to JSON/XML/YAML |
| JSON-schema / Structured Outputs | Schema + strict | Stronger than legacy JSON-mode; does not automatically fix reasoning semantic order |
Why: Engineers often lump these under “structured output,” but valid syntax ≠ correct reasoning ≠ correct field order.
Mechanism (paper): Stricter constraints correlate with larger performance degradation on reasoning sets (abstract); on classification sets JSON-mode often beats plain text by pruning the answer space (§5.2). From a decoding view, constraints shrink the logits support set each step: helpful for 49-way diagnostic labels; on GSM8K, which needs multi-step arithmetic symbol expansion, they may prune correct reasoning paths early. Figure 1 gives a canonical case: GPT-3.5-turbo correct in NL on GSM8K, fails after format restriction—damage occurs during generation, not only at parse time.
How to (minimal pipeline):
# Reasoning-oriented: keep NL intermediate state (illustrative, not paper hyperparameters)
reasoning = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": problem}]
)
structured = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Convert the following reasoning to JSON schema:\n{reasoning}"}],
response_format={"type": "json_schema", "json_schema": SCHEMA},
)
Pitfalls:
- Drawing conclusions from a single prompt “output JSON only”—the paper averages 9 prompt combinations (3 task descriptions × 3 format variants) and reports higher sensitivity after adding schema (Appendix G.2).
- Assuming XML/YAML occasionally beating JSON in Table 1 means a wholesale switch—the paper attributes variance to prompt variance, not format superiority.
if Ahh = 2 = = q 3 4).
po Nilamtl Mays, Cs ra,).
Task-type fork: reasoning ↓, classification ↑#
Why: Reasoning needs long chains of intermediate symbols (arithmetic, letter concatenation); classification answers often sit on a discrete support already in the pretraining distribution.
Mechanism (verified, paper HTML v3):
- Reasoning: GSM8K, Last Letter, Shuffled Objects; metric exact match. On gpt-4o-mini GSM8K: NL 94.57 → FRI 87.17 → JSON-Mode 86.95 (Table 2).
- Classification: DDXPlus (49 disease diagnoses), Sports Understanding, NI Task 280, MultiFin; metric accuracy. Gemini-1.5-Flash / DDXPlus: Text 41.6 vs JSON 60.3 (Table 10).
How to: Before launch, route by task symbol—use JSON-mode sparingly for math / multi-hop agents; for medical/finance-style finite label sets, try constrained decoding (same family as Outlines).
Pitfalls:
- Generalizing podcast phrasing “output 1–49” to any 49-class problem—the paper’s object is DDXPlus’s 49 diseases.
- Assuming JSON-schema necessarily recovers reasoning scores—same table GSM8K JSON-Schema 91.71 still below NL 94.57.
- The host once assumed JSON strongly shifts classification distributions; paper and discussion both admit classification-side mechanisms remain incomplete (speaker view @ classification intuition segment).
goo Milaatte May, ta,).
Lily Hiro / fal al ii Ahh 3).
Valid JSON decoupled from task success#
Why: Engineering KPIs often watch parse success first.
Mechanism: JSON-mode guarantees valid JSON (product narrative); the paper also uses Perfect Text Parser, etc., separating format errors from final metrics.
Evidence boundary: The guest said in roughly 99% of cases 5–10 samples yield valid JSON, but final result is another matter—speaker experience; the paper gives no 99% statistic (P06: quantitative claim not verifiable).
How to: Monitor parse_ok and task_correct as separate SLOs; for resampling, prefer a stronger model first, then 3–10 identical prompts (guest priority; not verified whether same-temperature 10× beats 9 prompt variants).
Pitfall: Declaring Agent success when json.loads succeeds.
= any Milani 7, 1 ? ~ a).
Two-stage and “speak freely first, format second”#
Why: Strict JSON binds schema during generation and may compress the intermediate token distribution reasoning needs (guest hypothesis: switching decoding domains among JSON / NL / LaTeX-style outputs causes confusion—speaker hypothesis, not a theorem).
Mechanism (partially verified): Paper NL-to-Format is nearly identical to NL on most models; vs JSON-mode / FRI it is clearly better on reasoning sets. Podcast “much better” compares to strict JSON, not a huge gain over pure NL—do not over-read.
How to: For complex agents, keep planning / CoT in NL, one terminal format_to_json(); split nested schemas by layer (next section).
Pitfall: Stuffing every step into one giant JSON—the guest said ~10 levels of nesting visibly degrades single-step quality (interview view; paper has no 10-layer controlled experiment).
) — ———_ xxii ¥ 2 —_—).
Nilunt go Muni Nar, a ,).
Function calling, field order, and RFC semantics#
Why: Tool calls are marketed as the modern structured output, but JSON objects are unordered (RFC 8259); in OpenAPI, function.arguments is a string and properties carry no order semantics.
Mechanism (partially verified): Paper §5.4 links OpenAI JSON-mode to the function calling API and records violations where reasoning should precede answer on reasoning tasks; conclusions stress key order and reasoning–format decoupling. Guest advice: function calling suffices when you only need enum-level tool names; for order-sensitive cases use controllable JSON-mode / schema—conditional advice; podcast did not cross-vendor API test.
How to: If business logic depends on reasoning → answer presentation order, use arrays or two field-specific calls at the protocol layer—do not assume object key order.
Pitfall: Conflating function calling with JSON-schema—the latter strengthens validity, does not automatically guarantee semantic order (GSM8K JSON-Schema 91.71 still below NL).
iti JHE erry rai <).
HHEIIT Hy RAEN TIER TD).
RAG, workflow step order, and test-time compute#
Why: Retrieval-augmented and multi-step workflows often pass structured payloads between steps—tension with “let me speak freely”: do intermediate steps need strict JSON?
Mechanism: The paper does not evaluate RAG specifically; discussion extends to step order (retrieve-then-generate vs reversed) and test-time compute (o1-class models with more internal reasoning). The guest finds public benchmarks “a bit limited” for datasets that both need structured output and gain from structure (speaker view).
How to: In RAG pipelines, A/B structured retrieval with NL reasoning chains; track planning tasks via PlanBench.
Pitfall: Because o1’s internal chain is invisible, concluding external JSON constraints “do not matter”—external format still affects parsing and tool wiring on observable steps.
1 { Hl alt \. an —— ad).
rip il if Hi hth).
waite Ei? "7 ‘gn).
Open-source constrained decoding: Outlines, TGI, Llama 3 8B#
Why: When data cannot leave the perimeter you need mask-logits decoding, not only a black-box API flag.
Mechanism: Paper cites Willard & Louf (2023) and Text Generation Inference Guidance; Outlines offers guaranteed valid structure. TGI docs describe grammar mapping on /chat/completions and tools.
Evidence boundary: Guest said Llama 3 8B + TGI JSON mode is already “pretty good”—subjective interview; 100% SQL syntax at AI Engineer Summit is venue hearsay; not reproduced on the podcast; guest is cautious on Python/C++.
How to: For privacy-sensitive deployments, evaluate Outlines / TGI Guidance first; cross-check against API JSON-mode.
Pitfall: After fine-tuning on one DSL (e.g. GraphQL) the model only speaks that DSL—incompatible with multi-tool Agent interfaces (host experience; guest did not systematically refute).
Nilenth ae * Hayy, We te,).
Prompt optimization, fine-tuning, and eval extrapolation#
Short term: DSPy, OPRO, TextGrad, etc. can ease prompt sensitivity (guest named them; not compared to this paper’s experiments). Before committing to fine-tuning, estimate variance with nine prompt variants (paper Appendix G.2 methodology) to avoid being misled by one-shot FRI.
Scale: At millions of users, fine-tuning may still be needed to compress the long tail (guest)—orthogonal to format constraints. The host noted GraphQL fine-tuning narrows the generation surface, tension with open multi-tool Agent APIs—if you fine-tune, separately verify format compliance and tool generalization.
Format diversity: On some model × dataset × prompt cells, XML/YAML beat JSON/NL—attributed to prompt sensitivity, not inherent format superiority (Table 1/9). Models include gemini-1.5-flash, claude-3-haiku, gpt-3.5-turbo, LLaMA-3-8B-Instruct (§3.3), not identical to the podcast’s spoken “latest frontier” list—re-run before extrapolating.
XML/YAML conditional conclusion verified; do not write “always switch to XML.”
a dat th H BS ' i ok).
Evidence boundaries (skim before reading the full piece)#
| Claim | Status |
|---|---|
| Strict format lowers reasoning / JSON raises classification | Verified in paper Tables 2, 10 |
| NL-to-Format better than strict JSON | Partially verified; vs pure NL “nearly identical” |
| 99% valid JSON in five samples | Interview view; paper has no such statistic |
| ~10-level nesting degrades single-step quality | Interview view; paper has no controlled experiment |
| Function calling key order | RFC unordered verified; reasoning order in paper JSON-mode section |
If you are shipping this#
- Choose format by task symbol: reasoning/math/multi-hop agent → NL or NL-to-Format; discrete classification (DDXPlus-style label sets) → JSON-mode / enum constraints. Replicate Table 2 direction on your data; do not copy point scores blindly.
- Report eval under format conditions: If production uses JSON between steps, benchmarks should include the same condition—otherwise misaligned with Compound AI deployment reality.
- Split KPIs: Alert on
valid_json_rateandtask_accuracyseparately; resampling for syntax does not replace model upgrades. - Order-sensitive schemas: Do not rely on object key order; consider staged calls or array fields (RFC 8259 + paper reasoning-order observations).
- Deep nested schemas in stages: One API call emitting “ten layers” splits success rate from apparent capability (interview ~10 layers is order-of-magnitude); NL plan first, then fill tables layer by layer.
References and further reading#
- Let Me Speak Freely? — arXiv:2408.02442 — Systematic study of format restrictions on LLMs (Tam et al., 2024)
- Paper HTML v3 (includes Table 2 / DDXPlus)
- OpenAI Structured outputs guide — JSON-schema and strict mode product semantics
- OpenAI OpenAPI spec repository —
json_schema,ChatCompletionMessageToolCallfield definitions - RFC 8259 — The JSON Data Interchange Format — Normative definition of objects as unordered collections
- GSM8K — grade-school-math — Reasoning exact-match benchmark
- Compound AI Systems — Berkeley BAIR — Multi-component AI system architecture context
- PlanBench — gpt-plan-benchmark — Planning and agentic eval extensions
- Hugging Face TGI — Guidance concept — Grammar / JSON constrained decoding
- Text Generation Inference GitHub — Self-hosted inference and guided generation
- Outlines (dottxt-ai/outlines) — Constrained decoding and guaranteed structure
- Willard & Louf — Efficient Guided Generation (Outlines paper line) — Theoretical basis for constrained decoding (paper citation chain)
- DSPy — stanfordnlp/dspy — Declarative prompt / weight optimization framework
- Weaviate Podcast #108 video search — Official YouTube discovery entry (confirm watch URL on the channel)
- DDXPlus dataset background (paper cites StreamBench subset) — 49-class medical diagnosis experimental setup


