
Stateful Agents and Context Compilation: The Engineering Divide from MemGPT to Letta#
When teams push LLM applications beyond “single completion + external vector store” toward cross-session memory, tool loops, and replayable debugging, the debate is often not “whether to use agents” but three tensions: who compiles context, who writes memory, who stores state. Letta (formerly MemGPT) represents one explicit path: treat the finite context window as a compiled runtime view, with the framework performing Memory.compile() / recompile, and the model deciding via tools when to retrieve and when to rewrite in-context blocks.
That coexists with workflow engines (LangGraph, Temporal, etc.) that stress recoverable, deterministic steps; the Letta side stresses that the same tool-call primitives can power open-loop agents and explicit workflows built with tool_rules (speaker opinion; the show did not provide reliability benchmarks against Temporal). This article separates verifiable docs/source from guest architecture views—it does not offer a single “correct answer.”
Problem space: RAG, stateful services, and “black-box context”#
Why talk about an “agent framework” beyond RAG#
Typical production RAG automatically stitches retrieval into the prompt (Simple RAG: the application decides when and what to query). The stateful agent path defers “whether to retrieve and what to write to memory” to explicit model tool calls (Agentic RAG: All the RAG logic is handled by the agent). They are not mutually exclusive: batch indexing may still be application-owned; the divide is read/write timing on the conversation loop.
Another axis is state persistence. Stateless APIs carry full history every call; Letta docs describe agents as stateful agents—memory blocks, messages, and tool definitions live in a database, with each step approximating read state → compile context → infer → write back (guest summary as “agents as REST API”; in practice a REST/SDK platform—separate slogan from mechanism).
Mechanism: two layers of “database”#
| Role | Typical contents | Who triggers read/write |
|---|---|---|
| Business store (vector DB, OLTP, etc.) | Documents, transactions, user data | Agent via custom tools |
| Letta-managed store | Conversation, blocks, tool definitions | Framework + built-in memory tools |
Context hierarchy layers Memory Blocks (in-context), Archival (out-of-context, on-demand tool), Files, and External RAG—orthogonal to naive “everything is vector top-k” pipelines.
What to do (minimal closed loop)#
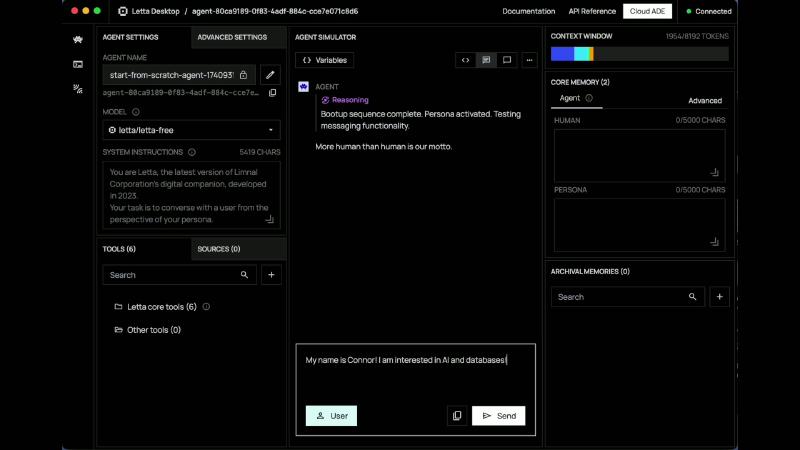
Start local service with Docker (official guide): docker run -p 8283:8283 letta/letta:latest. When creating an agent, attach human / persona blocks (Memory blocks), drive one inference step via agents.messages.create, and inspect compiled token usage in ADE—not only the final reply.
Common pitfalls#
- Treating Letta as “another vector-store wrapper”—archival must be pulled via tools; blocks are the always-visible in-context surface (comparison tables in docs state this).
- Assuming a model swap drops persona—Models docs say Agents keep their memory and tools when changing
model(you still must regression-test tool compatibility).
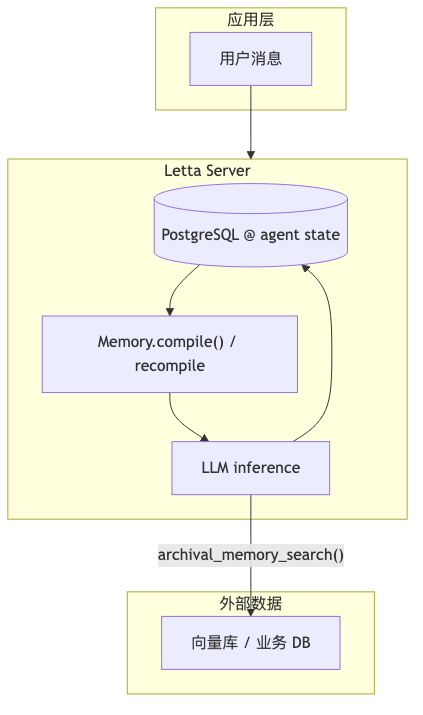
Virtual context and core memory: paper lineage vs product terms#
Why MemGPT still matters#
The MemGPT paper (arXiv 2310.08560) proposes virtual context management: simulate a larger context inside a finite window and intelligently manages different memory tiers (OS-style tiering analogy). Letta describes itself as Born from MemGPT (memgpt.ai / GitHub README).
Boundary: the paper abstract does not contain the guest’s exact phrase “self-managed / self-editing memory”; Memory blocks docs use self-editing for block behavior—call that product/doc terminology, not a paper theorem. The claim of the “first” self-managed memory agent paper (speaker opinion) was not checked with systematic prior-work search.
Mechanism: human / persona and tools that write blocks#
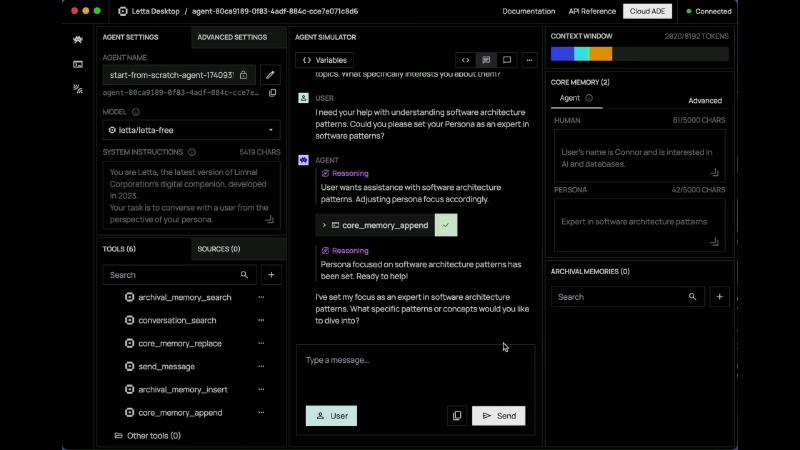
Typical chat uses human and persona labels (Memory blocks). The model rewrites via core_memory_append / core_memory_replace (base.py). Blocks have limit (doc example chars_limit=5000; source default CORE_MEMORY_BLOCK_CHAR_LIMIT is larger—use config at creation time).
Guest view: persona is not only personality; user feedback can be written there so later turns carry readable “online learning,” easier to audit than fine-tuning. The counterpoint from production RAG circles (e.g. preference-in-weights routes in Contextual AI on the Weaviate podcast)—fine-tuning needs datasets, eval loops, and conflict explanation (mechanistic interpretability was named but not expanded).
| Path | Advantages (summary) | Cost / risk |
|---|---|---|
| In-context blocks | Human-readable, hand-editable, visible in ADE | Consumes tokens; model may write wrong content |
| Fine-tuned weights | Zero extra tokens at inference | Data and eval investment; hard to debug vs explicit memory |
This article does not pick a product winner; if compliance needs auditable memory, doc-supported self-editing blocks align better with an evidence trail.
What to do#
# Conceptual sketch: create agent with dual blocks (field names per SDK)
memory_blocks=[
{"label": "human", "value": "...", "limit": 5000},
{"label": "persona", "value": "...", "limit": 5000},
]
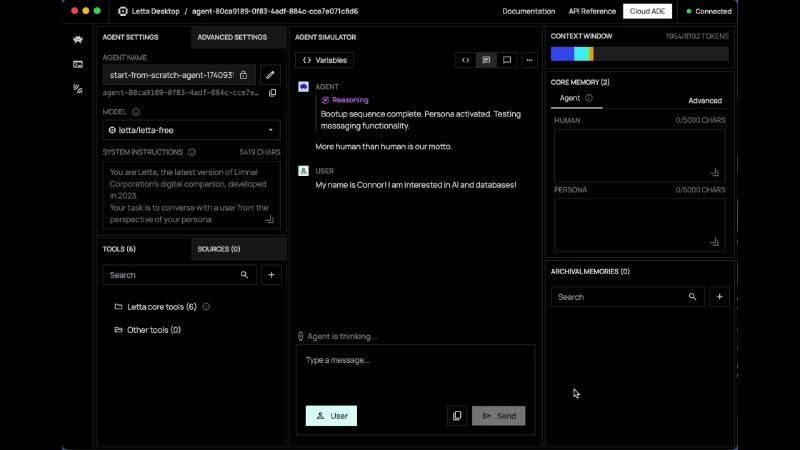
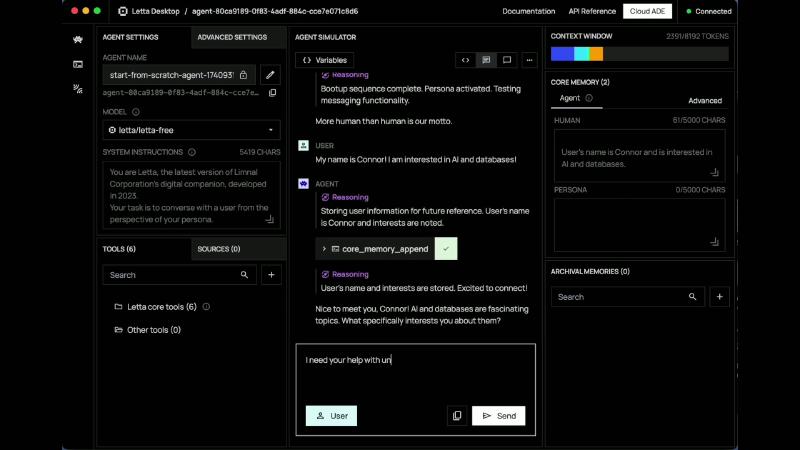
After bootup, Simulator token count rises from ~1954 to ~2391 (show OCR: ocr_pick_002 AGENT SIMULATOR CONTEXT WINDOW 2391/8192 TOKENS)—system instructions + blocks + messages share the budget; debug compiled output, not a single user message.
Common pitfalls#
- Assuming core blocks “auto-sync global facts”—block content is what the LLM chooses to write; errors can fossilize (fix via archival, or manual block edits).
- Treating 5000 characters as the universal cap—OCR matches doc examples, not the only source-of-truth for source defaults.
Context compilation vs long windows: budget engineering, not “bigger window wins”#
Why a 200k model might still use only ~30k#
Industry pattern: as context grows, stuff history, retrieval, and system into one window. Guest view (no reproducible paper cited): pain shifts from “won’t fit” to “fits but hard to debug, higher latency/cost, long-window reasoning may not beat a controlled short window.” Code-side LLM_MAX_CONTEXT_WINDOW["DEFAULT"] = 30000 (letta/constants.py) is a fallback default—do not equate it with “the only official 30k recommendation”; ADE docs give artificially limiting a 200k-capable model to 16k as an example.
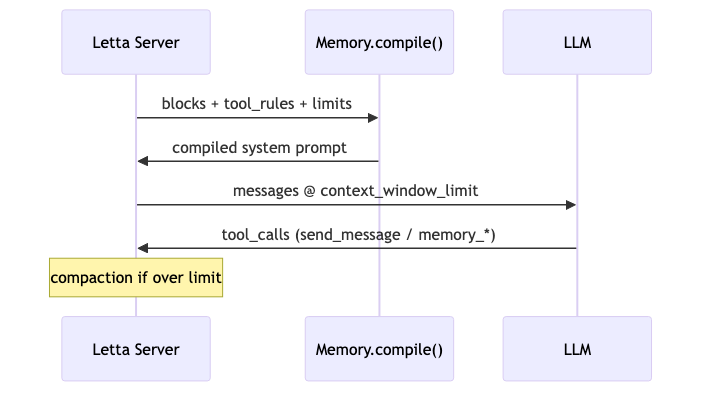
Mechanism: what the compile pipeline includes#
ContextWindowOverview (source schema) tracks core_memory, summary_memory, external_memory_summary (archival + recall metadata), system_prompt, functions_definitions, num_messages. Compaction summarizes older messages when too long (default sliding_window, etc.). The guest’s “context compilation” maps in docs mainly to recompile, compiled system prompt, Memory.compile()—engineering slang overlaps official terms partly (verification: partially verified).
What to do#
# Doc direction: artificially cap usable window (fields per current SDK)
client.agents.update(agent_id, context_window_limit=30000)
Use Context window viewer for Core memory blocks / message history / token usage breakdown, then tune context_window_limit—before jumping to a larger model.
Common pitfalls#
- Treating “unused 200k” as waste—controlled budget is a trade among observability + cost + quality (guest view + partial code defaults).
- Ignoring fixed overhead from
SYSTEMINSTRUCTIONS @ 5419 CHARSand six Lettacore tool definitions (show OCR).
Agentic RAG and archival: when content enters context#
Why not default top-k into the prompt#
Archival memory: must be queried on-demand via tools, unlike memory blocks pinned in-window. The RAG comparison table states Simple RAG retrieval is application-controlled; Agentic RAG is agent-controlled—aligned with Weaviate’s Agentic RAG narrative, while Letta implements retrieval as first-class tools like archival_memory_search.
Verified boundary: the platform does not auto top-k on every user message by default; developers can still pre-fetch in the app and write blocks—that is an integration choice.
Mechanism: pagination + updating core—“Map-Reduce” narrative#
Guest view: for very large datasets, tools can page through an external store and write distilled results into core memory instead of one-shot RAG top-k; host analogy to LangChain Refine—no benchmark (analogy only).
Compared with MCP (host experience): Claude Desktop + Weaviate via MCP writes external memory; Letta has the LLM decide writes to core / archival with framework persistence—not official Letta MCP integration docs, architecture contrast only.
What to do#
Only when the model calls:
archival_memory_search(query="...", top_k=5)
do snippets enter later-turn context; until then, vector-store content is invisible to the LLM.
Common pitfalls#
- Building archival but omitting search tools—memory becomes a black hole.
- Mixing in-context blocks with archival semantics—blocks always cost tokens; archival charges per retrieval.
Unified primitives: everything is a tool call (including talking to the user)#
Why send_message is also a tool#
Guest view: if chat uses chat completion and tools use function calling as separate APIs, workflow / multi-agent splits; Letta lists send_message in BASE_TOOLS (constants.py); user-visible replies go out via assistant_message (base.py).
Message types add reasoning_message / hidden_reasoning_message; MemGPT v2 system prompt asks for inner monologue … before taking any action—partially verified “reason first, act second”; not all API paths hard-enforce order.
Mechanism: tool rules and workflows#
tool_rules (tool_rule.py) can constrain sub-tool sets—configurable in ADE (UI details not fully verified). Same primitives can encode “must call tool X before Y” workflow agents (speaker view: no separate workflow runtime required).
Common pitfalls#
- Equating “tool steps” with “user-visible replies”—
send_messagemay follow many internal tools before one output. - Copying whether reasoning tokens enter later context from OpenAI docs—guest notes vary by version; Letta uses separate message types (readers should verify current OpenAI reasoning docs).
Multi-agent: shared blocks and message tools#
Why not a “multi-agent-only runtime”#
Guest view: multi-agent = shared memory blocks (update once, visible everywhere) + inter-agent messaging tools. Source includes send_message_to_agent_and_wait_for_reply, send_message_to_agent_async, send_message_to_agents_matching_tags (multi_agent.py)—no tool literally named broadcast (“broadcast” ≈ tag-matched send, partially verified).
Common pitfalls#
- Shared blocks without write permissions—concurrent persona updates can overwrite each other.
- Expecting ADE built-in Chatbot Arena-style pairwise model comparison—guest confirmed none (speaker opinion).
Tool execution, sandboxes, and “an agent is just an application”#
Server-side vs client tools#
Client tools: Server tools run in Letta server sandbox; Client tools run on the client with approval callbacks—contrast to OpenAI Assistants “return tool call, client executes” is interview opinion (Assistants current docs not captured this session).
Sandbox choice (source): with e2b_api_key, E2B AsyncSandbox; else local dir sandbox—not fully aligned with “Cloud defaults to E2B, local defaults to no sandbox” (partially verified): local is not “no isolation,” but LOCAL path.
State storage: row records vs one JSON blob#
Guest view: puzzled by “whole app state in one JSON blob” popularity in agents; Letta persists conversation / blocks relationally (Docker compose includes letta_db pgvector). Whether competitors use JSON was not verified.
Common pitfalls#
- Running untrusted Python tools on Cloud without E2B—may fall through to LOCAL; read deployment config for isolation level.
- Treating
letta/letta-freeas proprietary weights—guest said no own model yet, endpoint is a model router (interview opinion; product name not fully verified in OpenAPI).
Observability, evaluation, and “taste”#
Dev-time transparency vs Langfuse-class platforms#
Industry pattern: black-box context → rely on Langfuse etc. to reconstruct prompts. Guest view: if the framework (like ADE) shows the compiled context window, absolute reliance on dedicated observability in design drops; in production you still want trace/metrics (speaker opinion, no A/B data).
Numeric eval vs vibe eval#
Guest view: companion-style, highly personalized agents resist 200k-question benchmarks; “not eval, taste”; best eval is often using the agent directly; large numeric evals can detach from real behavior. Letta opportunity: full state in DB enables replay of “context at the time” (evals planned, no scale commitment).
Unverified: host mentioned a Berkeley paper on “structuring context window + reasoning”—no arXiv entry checked.
For teams needing regression tests, still maintain a small golden dialogue set (host cited ~50–100): even if you agree with vibe eval, fix assertions like “given agent state + user input → did it call tool X / does block contain keyword Y”; Letta full-state storage makes replay more direct than trace-only platforms (eval productization planned, not a shipped promise).
Working with vector stores: where Weaviate appears on screen#
ADE lists weaviate-query-agent (OCR: agent-5b01e7ea-06ee-42b3-9da0-e26f7cc0ad4e)—typical integration: Weaviate holds embeddings and objects, Letta agent queries via custom tools or archival backend; Letta does not replace the vector DB. The host also contrasted MCP writing memory into Weaviate—the difference is who initiates writes (MCP session vs Letta memory tools), not whether to use vector search.
If you are shipping this#
- Draw a context budget table first: system + blocks + tool definitions + messages/compaction token shares; use
context_window_limitto cap the window, then pick a model—not the reverse. - Turn RAG into explicit tool contracts: document archival/search vs blocks; integration tests for “must not cite store facts without search.”
- Deploy stateful like a service: PostgreSQL persistence + Docker or Cloud; on failure, replay messages + compile snapshot from DB.
- Multi-agent: shared blocks before message storms: agree
persona/humanwrite permissions; limit tag broadcast scope. - Put sandbox and tool paths in the runbook: verify
e2b_api_key, distinguish client vs server tools; do not assume “local = no isolation” for untrusted code.
References and further reading#
- MemGPT paper (arXiv 2310.08560)
- Letta documentation home
- Context hierarchy (blocks / archival / files)
- Memory blocks and self-editing
- Archival memory and on-demand tools
- Compaction (summarize older messages)
- Message types (tool_call / reasoning)
- RAG patterns: Simple vs Agentic
- Agentic RAG tutorial
- Stateful agents and DB persistence
- ADE Context window viewer
- Models and context_window_limit
- Docker deploy Letta Server
- Client tools vs server sandbox
- Letta GitHub (letta-ai/letta)
- E2B sandbox product page
- Weaviate: What is Agentic RAG


