
Enterprise RAG on Financial Research Corpora: Engineering Trade-offs in Vector Stores, Agents, and Eval#
When financial institutions turn semi-structured text—analyst notes, fund/equity research, editorials—into queryable GenAI capabilities, the bottleneck is rarely “can we plug in a large model.” It is usually ingestion throughput, retrieval granularity, entitlement boundaries, and the latency and testability that agents introduce. Public product specifications for Morningstar’s internal Morningstar Intelligence Engine (MIE) are almost impossible to find; what follows separates verifiable primary documentation from speaker opinions so you can use it as an architecture reference in similar scenarios—not as an official Morningstar white paper.
Problem space: an API platform, not just a chat window#
Why: Internal product teams and external customers need the same RAG / agent capabilities, but skill stacks differ widely. If every application builds its own pipeline, embedding, chunking, and eval are duplicated and incomparable.
Mechanism / constraints: The speaker describes MIE as an API-driven, low-/no-code platform: configurable RAG pipelines, GenAI agents, built-in tools, and a roadmap that extends to text-to-SQL (speaker opinion; the Morningstar Developer portal exists but does not list MIE capabilities). The first production corpus domain is research / editorials / analyst notes (speaker opinion). The typical chain aligns with RAG narratives in Weaviate documentation: embed → semantic retrieval in a vector store → context to the LLM.
How to do it (minimal sketch):
document event → queue worker → chunk + embed → Weaviate upsert
user question → filter(entitlement) → hybrid/semantic search → rerank → LLM
Common pitfalls: Treating “platform” as a single Chat UI; ignoring unified APIs after Deploy and multi-tenant eval needs (tool marketplace, eval UI are speaker opinions with no public documentation).
Vector store selection: FAISS for validation, Weaviate for replication and ops boundaries#
Why: FAISS suits POC-scale dense retrieval (“efficient similarity search … of dense vectors”), but if you self-build HA, replication, and cross-AZ scaling, team time drifts from content quality to infrastructure (speaker opinion).
Mechanism / constraints: Weaviate Replication documentation states replication can “improve availability” and supports replicationFactor; that aligns with “trade engineering focus for a managed/mature vector store.” Speaker opinion: After GPT arrived they used FAISS first, then trialed open-source Weaviate in containers for several days before a partnership—timeline not verifiable from public case studies.
How to do it: Use local/file indexes for POC; before production, nail RPO/RTO, read scaling on read replicas, upgrade strategy, then decide between a self-managed FAISS cluster and a vector database.
Common pitfalls: Assuming “FAISS cannot go to production”—the FAISS README does not rule out production; what’s missing is replication and multi-replica semantics. Selection is a cost curve, not a moral judgment.
Ingestion: SNS/SQS/Celery for peak shaving, not a Kafka narrative#
Why: Analyst content floods in from CMS and other sources; embedding calls (at recording time, text-embedding-ada-002 on Azure—1536 dimensions, 8192 token limit) become the bottleneck at peaks.
Mechanism / constraints: Amazon SNS for topic fan-out, SQS for buffering, Celery workers elastically scaled on K8s—speaker opinion explicitly did not adopt Kafka (opposite of the default “large-scale ingestion must use Kafka” playbook). Component capabilities have primary documentation; whether MIE uses only this stack cannot be verified.
How to do it (sketch):
# Pseudocode: event-driven ingestion—directional example aligned with interview stack
sns.publish(TopicArn=DOC_TOPIC, Message=json.dumps({"doc_id": id}))
# SQS → Celery task: fetch → chunk → embed → weaviate batch import
Common pitfalls: Forcing Kafka to “look more big data” without cross-team stream-processing ops; under a Python stack, queue + worker is often enough (speaker opinion).
Chunking, synthetic questions, and “embed small, retrieve big”#
Why: Page-boundary / fixed-length first-pass chunks often cut semantics; users ask questions while chunks are statements, so vector-space misalignment hurts recall.
Mechanism / constraints:
- Speaker opinion: Overlap between chunks, multiple full re-ingests, rerank after retrieval; CMS pub/sub handles PDF/text/JSON, some needing external mapping.
- Synthetic-question embeddings: Use an LLM to generate hypothetical questions per chunk, then embed—because question–question similarity beats question–document (speaker opinion, no Morningstar paper).
- Literature side: Anthropic Contextual Retrieval attaches context to chunks before embedding, claiming fewer failed retrievals combined with rerank (their internal eval, ≠ MIE numbers); LlamaIndex Auto Merging Retriever embodies retrieve small chunks, merge parent chunks—“small index, large context”—isomorphic to the guest’s remarks, but the literal slogan “embed small, retrieve big” does not appear in official LlamaIndex docs.
How to do it:
chunk → LLM(synthetic_questions[]) → embed each → store metadata: parent_doc_id, offsets
query → retrieve top-k synthetic hits → expand to parent span → rerank → prompt
Common pitfalls: Using ingestion-time synthetic questions directly as golden eval or fine-tuning data—speaker opinion says synthetic questions mainly serve retrieval and do not by default enter eval; if you later run synthetic eval, change models / add noise to avoid same-source bias.

Production RAG keeps ReAct: trading latency for answer quality#
Why: Single-round retrieve-augment-generate often misses tool steps or picks the wrong corpus on complex financial questions.
Mechanism / constraints: ReAct (Yao et al., 2022) requires “reasoning traces and task-specific actions in an interleaved manner”; each round adds an LLM call → latency rises predictably. Speaker opinion: MIE started without agents; for quality they keep ReAct in production; in-platform RAG pipelines are themselves ReAct, while function calling / programmatic action calling mainly serves downstream consumers of the MIE API—one downstream function can call the platform’s ReAct again, forming nesting.
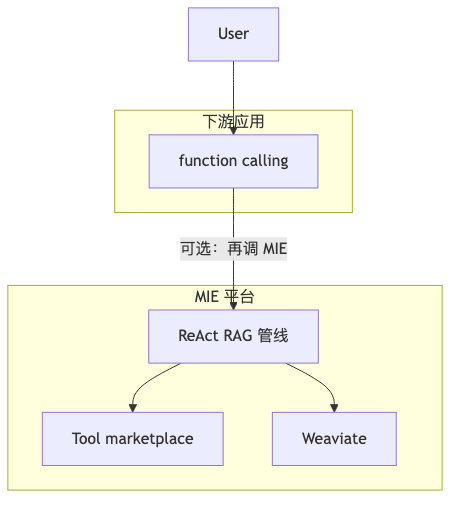
How to do it: Set max_steps, timeouts, tool allowlists for ReAct; keep a vanilla RAG downgrade switch on latency-sensitive paths (not claimed implemented in the interview—engineering recommendation).
Common pitfalls: Agentifying everything because benchmarks look flashier; ignoring stepwise eval cost exploding with step count (guest contrasts LangGraph StateGraph observability; they lean toward tool descriptions + ReAct selection, speaker opinion).
Extensions (not production boundaries): Microsoft AutoGen POC only—suited to background multi-turn + cached insights; Reflexion reports pass@1 gains on HumanEval—different task and metric from the guest’s spoken SQL “~80–83%”; do not conflate.
Tool marketplace and “multi-agent”: routing beats org metaphors#
Why: Financial scenarios have many tools (RAG, SQL, custom APIs); you need discoverability and isolation, not LLM role-play as “CEO / marketing.”
Mechanism / constraints: Speaker opinion—Tool marketplace publishes custom APIs running in containers; ReAct reads tool descriptions + prompt to choose tools; after Deploy, a unified API exposes capabilities. Shipped shape is closer to shared Morningstar RAG tool + per-agent SQL and other tools routed by need, not multi-agent org metaphors (speaker opinion).
Common pitfalls: Using AutoGen multi-role agents for end-user requests—guest says latency and eval difficulty make it better for batch processing (speaker opinion).
Eval: golden Q&A and meta-evaluation, not ingestion synthetic questions#
Why: When you change models, temperature, or ingest large new document batches, you need repeatable comparisons—or you cannot show the business “it got better.”
Mechanism / constraints: Speaker opinion—built-in golden Q&A; metrics include accuracy, conciseness, groundedness, plus meta-evaluation; non-engineers can upload eval via UI. Cannot verify MIE metric formulas or pass@k implementation. Public RAG eval often uses LLM-as-judge, but that is not the same measurement family as Spider/BIRD SQL leaderboards.
How to do it: Fix three dimensions—question-set version + retrieval snapshot + model version; when changing embedding models per Azure docs, plan full re-embed for ada-002 → text-embedding-3-*.
Common pitfalls: Using ingestion synthetic questions as eval—easy to overfit the retriever and diverge from real user question distributions (speaker opinion).
text-to-SQL: schema engineering and the ceiling on spoken accuracy#
Why: Structured holdings, ratings, and metric queries via vector retrieval alone are costly and hard to aggregate correctly.
Mechanism / constraints: Speaker opinion—text-to-SQL POC existed early; on few tables (<10) with self-explanatory column names, spoken ~80–83% (no benchmark name, no pass@1 / execution-accuracy definition; cannot verify). Engineering: integer rating_id on columns to avoid AVG on text ratings; database views to reduce joins; read-only SQL role, LIMIT, push aggregates into SQL; SQL agent retry on errors. Public comparison can only cite community suites like Spider 2.0 to show industry baselines exist—cannot confirm or refute 80–83%.
How to do it:
-- Read-only role + row cap (illustrative)
SET ROLE mie_readonly;
SELECT rating_id, AVG(metric) FROM v_fund_ratings GROUP BY 1 LIMIT 100;
Common pitfalls: Expecting a general model to be “near usable” once tables multiply or column names abbreviate; or misreading Reflexion’s 91% pass@1 HumanEval as a SQL score.
Permissions and compliance: do not ingest at source; filter before retrieval#
Why: Post-generation redaction of a single sentence cannot undo a leaked vector; financial data also has domicile and entitlement dimensions.
Mechanism / constraints: Speaker opinion—non-public sensitive content should not enter the vector store; ingested objects carry metadata; narrow or deny by entitlement before the request reaches Weaviate/LLM. Store-side: Weaviate Filters support property filtering; Weaviate v1.28.0 introduced RBAC Preview (“roles and permissions … Isolation is at the collection level”, preview API may change)—mentioned by the host; overlap strength with business entitlements unknown.

Common pitfalls: Relying on post-RAG redact only; ignoring Python tools must be sandboxed, otherwise fall back to a limited function set (speaker opinion: SQL defaults to read-only role; Python risk is higher).
Guardrails and model stack: buy vs build, fine-tune vs prompt#
Why: Templated compliance (disclaimers, banned investment-advice phrasing) and input/output checks—outsourced services often fall short in financial settings.
Mechanism / constraints: Speaker opinion—after trying several guardrails-as-a-service vendors, they lean in-house; the platform will support customers bringing their own guardrails (rules / small models / LLM prompts). On tone, small-scale Llama fine-tuning—“response was okay”; short articles GPT-4o + prompt already suffice (gpt-4o in Azure model table); large research reports still rely on analysts (speaker opinion).
Common pitfalls: Assuming financial tone requires fine-tuning; or overnight auto-generated research with no human review—guest says output remains research product needing human review; multimodal charts carry higher risk (speaker opinion).
If you are shipping this#
- Map permissions and data classification first: Default sensitive unpublished material out of the vector store; filter before embed query on the retrieval path; threat-model against vector-store replication/RBAC capabilities.
- Decouple ingestion from eval: Synthetic questions serve recall; maintain golden Q&A separately; when changing embedding models, plan full re-embed + eval re-run.
- Layer agents: Cap ReAct steps on the user-facing path; batch / insight cache can consider AutoGen-class frameworks, but do not share the same eval matrix with the front door.
- Shrink schema before text-to-SQL: views + read-only role + LIMIT; spoken accuracy bands need a home-grown benchmark—do not cite unrelated paper metrics.
- Models at recording time are aging: Before 2025+ deployments, check Azure/OpenAI deprecations for ada-002 and GPT-4 family to avoid silent retrieval regression from dimension changes.
References and further reading#
- ReAct: Synergizing Reasoning and Acting in Language Models (arXiv:2210.03629)
- Reflexion: Language Agents with Verbal Reinforcement Learning (arXiv:2303.11366)
- FAISS — Facebook AI Similarity Search
- Weaviate database and RAG workflow introduction
- Weaviate — Replication configuration
- Weaviate — Filters (property filtering)
- Weaviate v1.28.0 Release — RBAC Preview
- Anthropic — Introducing Contextual Retrieval
- LlamaIndex — Auto Merging Retriever
- LangGraph overview — state graphs and workflows
- Microsoft AutoGen — agentic AI framework
- Azure OpenAI — models and embeddings (text-embedding-ada-002, gpt-4o)
- Amazon SNS and SQS — AWS async messaging components
- Celery — distributed task queue introduction
- Spider 2.0 — text-to-SQL community benchmark (for comparison)


