
Multi-Vector Search: Choosing Among Single-Vector, Late Interaction, and Cascaded Reranking#
In RAG and agent stacks, retrieval remains the cost–quality watershed: single-vector bi-encoders are fast but over-compress; cross-encoders are accurate but cannot scan the full corpus; multi-vector late interaction (exemplified by ColBERT) tries to occupy an indexable gap between the two. Evaluation is splitting too—dense SOTA on MTEB can fall sharply on BRIGHT, while agents stretch the “query” from keywords into tool traces and reasoning chains.
LightOn’s Amélie Chatelain and Antoine Chaffin cover training dynamics, code semantics vs. grep, reasoning-heavy benchmarks, and PLAID, Muvera, and ColBERT-Zero. The guests are not hung up on naming (multi-vector / late interaction / ColBERT family), but they disagree on whether approximate indexes are worth it and whether RAG has been replaced by grep. In practice it looks more like picking layers by scale and budget than betting on a single silver bullet. Below we unpack the mechanisms, mark what the literature supports, and label speaker opinion where it applies.
Where the problem comes from: compression, interaction, and agent query shapes#
Why: Production RAG must satisfy latency, recall, and explainability together. Single-vector methods compress an entire passage into one point; lexical variants and fine-grained alignment are lost in compression. Cross-encoders do full query–document interaction but only suit short-list reranking. Agents further pull queries away from keywords toward long reasoning traces and tool-call context, misaligning with the classic “short query + long document” assumption.
Mechanism / constraints: Information retrieval has long used retrieve-then-rerank; multi-vector schemes defer “interaction” until after retrieval, using MaxSim (for each query token, take the max similarity to document tokens, then aggregate) for soft matching between independently encoded query/document token embeddings. In the official ColBERT implementation, late interaction means query and document are encoded separately, then scored with fine-grained token-level max-then-sum (score() path).
How to (conceptually):
# MaxSim core (aligned with ColBERT score, illustrative)
# Q: [q_len, dim], D: [doc_len, dim]
scores = (Q @ D.T).max(dim=1).values.sum()
Common pitfall: Equating “multi-vector” with “mixing multiple embedding fields in one search”; or assuming MaxSim compute equals “full-corpus cross-encoder”—the bottleneck is often storing a vector per token (speaker opinion: compute is roughly query length × dimension matrix multiply, acceptable; index size is the pain point). At video-scale token counts, storage and IO with full-precision on disk can beat compute as the bottleneck (speaker opinion).

Late interaction vs. dense: structure for training, not just a bigger model#
Why: Amélie describes dense as lossy compression of semantics; late interaction keeps token granularity but soft-matches in learned space. Antoine’s PhD motivation was bi-encoder speed plus cross-encoder expressiveness—ColBERT is one path, not the endpoint.
Mechanism / constraints: ColBERT-Zero compares dense vs. multi-vector on the same backbone from public Nomic Embed mixtures: BEIR average nDCG@10 = 55.43 (<150M tier, verifiable on the model card). Speaker opinion: early late-interaction models trained on ~2M samples vs. “fully pretrained” dense is unfair; on comparable data, text-side late interaction is often still stronger. Another speaker opinion: with enough dimensions dense could theoretically approximate a cross-encoder, but bi-encoder training is noisy; MaxSim’s max only reinforces the best token alignment, yielding “cleaner” dynamics—Antoine cited a specific paper without giving the title in conversation; cannot be independently verified.
How to: Cascade rather than single-hop—speaker opinion favors dense → late interaction → cross-encoder, narrowing candidates stage by stage; ColBERT used only as reranker wastes capability if upstream recall is weak (consistent with two-stage IR common sense).
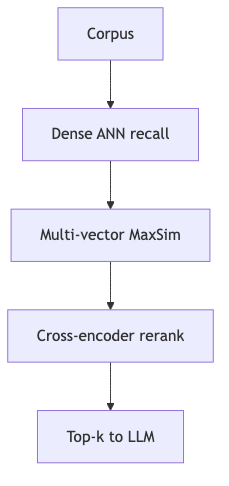

Common pitfall: Feeding ColBERT rerank from a tiny dense candidate pool expecting recall “rescue”; or ignoring PLAID centroid pruning—when candidates come from cluster centers, the center pool itself must preserve recall first (speaker opinion).
Scale tiers: exact MaxSim, PLAID, Muvera#
Why: Million-scale corpora cannot afford full-precision token–token scoring on every document; thousand-scale codebases or support KBs may brute-force entirely in memory.
Mechanism / constraints (literature side):
| Component | Verifiable points | Interview addendum |
|---|---|---|
| ColBERTv2 | Residual compression; index ~6–10× smaller than vanilla | — |
| PLAID | Centroid interaction / pruning; up to 7× (GPU) / 45× (CPU) vs. ColBERTv2; experiments to 140M passages | Guest spoken “IVF-PQ”: PLAID abstract does not mention IVF-PQ; PQ/residual closer to ColBERTv2; write as centroid + compression combo |
| Muvera | FDE compresses multi-vectors to fixed-dim single vectors; inner product approximates multi-vector similarity; abstract claims ε-approximation | Antoine: has not personally verified proofs; effectiveness varies by model |
| MS MARCO | BEIR lists 8.84M passages | Spoken “8.8 million” is approximate |
Speaker opinion (Antoine): For very small corpora (thousands of documents), exact MaxSim often beats Plaid approximation; on small models Plaid can even lose to brute force—“Occam’s razor, don’t optimize what you don’t need to.” Connor paraphrases Weaviate product direction: Muvera single-vector recall + full-precision MaxSim rerank; Muvera integration details could not be verified from fetchable Weaviate developer docs in this pass—treat official releases as source of truth.
How to (selection):
- < ~10⁴ documents: Prefer exact MaxSim or full token storage; skip approximate indexes.
- 10⁶+ documents: PLAID-style centroid candidates + full-precision MaxSim rerank; LightOn provides Fast Plaid (Rust) and
indexes.PLAIDin PyLate. - Candidate generation: Muvera FDE can replace Plaid centroids (paper reports ~10% recall gain, 90% lower latency on BEIR on average); silver bullet or not—speaker opinion: “when it works, it works very well,” inconsistent across models.
Common pitfall: Using Plaid at million scale when unnecessary; or feeding the LLM after Muvera approximation without full-precision MaxSim rerank.
Vector DB integration boundary: Connor mentioned Weaviate exploring Muvera and IVF-PQ-class capabilities—product facts should follow the current Weaviate vector index documentation; this episode is spoken at recording time, and Muvera paragraphs could not be verified from fetchable pages here. If you self-host, the logic remains: approximate recall for breadth, MaxSim for late-interaction precision.
Code retrieval: grep, semantic extension, and “RAG is dead”#
Why: Coding agents default to grep; multi-round keyword probing is low-latency but can miss semantically related implementations. LightOn’s product line is ColGrep + LateOn-Code (spoken “CodeGrep” in the interview), offering grep-like API semantic search.
Mechanism / constraints (product docs verifiable): LateOn-Code-edge (17M), LateOn-Code (~130–149M); pretraining pipeline CoRNStack 2412.01007, fine-tuned for MTEB Code v1. README compares 17M multi-vector vs. larger dense (e.g. GTE-ModernBERT) on Code v1 subtasks—not all Gemini API claims. Speaker opinion: Thousand-file repos can run exact MaxSim on GPU in memory; “RAG is dead” means agents with grep + large context suffice, but semantic grep can one-shot code that needs many grep rounds; human-perceived latency grep ≈ ColGrep.
Common pitfall: Treating spoken “70M” as the official SKU (should be 17M edge); substituting general MTEB leaderboard for MTEB Code v1 subtask metrics.
Reasoning-intensive retrieval: BRIGHT, ReasonIR, and very long queries#
Why: BRIGHT tests reasoning-intensive similarity (e.g. same theorem, different problem statements); top MTEB-class dense models can drop from 59.0 nDCG@10 (MTEB) to 18.3 nDCG@10 on BRIGHT. Agents further lengthen query-side tokens with chain-of-thought and tool traces.
Mechanism / constraints: ReasonIR (Meta ReasonIR-8B) reaches 29.9 nDCG@10 on BRIGHT (no reranker), 36.9 nDCG@10 (with reranker). Speaker opinion: Antoine fine-tuned 130M ModernBERT-ColBERT with PyLate on ReasonIR public data, claiming better than up to 7B and near 8B on the same data while same-backbone dense is clearly worse—130M figure not found in ReasonIR official repo; needs independent reproduction; BrowseComp+, API embedding comparisons are also speaker opinion.
Common pitfall: Inferring BRIGHT from MTEB scores; using agent traces as queries without shifting training distribution (ReasonIR route: synthetic reasoning data + dedicated fine-tuning).
Long documents and long queries: ColBERT emphasizes documents can be encoded offline and queries interact online—suited to long-document retrieval. Speaker opinion: ColBERT generalizing to long documents better than dense is “known,” but Antoine remains partly skeptical on very long queries (human question vs. concatenated LLM reasoning trace); in his experiments, reasoning-tuned models plus trace helped—experimental judgment, not a BRIGHT paper theorem.
Training and tooling: ColBERT-Zero, PyLate, prompts#
Why: Multi-vector pretraining is expensive; productization needs Sentence-Transformers-style APIs and large-batch contrastive learning.
Mechanism / constraints (verifiable): ColBERT-Zero three stages (unsupervised contrastive → supervised hard negatives → KD); skipping the costliest unsupervised stage: ~40 vs ~408 GH200-hours (~10×), retaining 99.4% performance (55.12 vs 55.43 nDCG@10). HF offers ColBERT-Zero-noprompts variants; speaker opinion: simple query/document prompts (not LLM instructions) help, mechanism unclear (guess similar to query expansion).
PyLate: CachedContrastiveLoss from GradCache 2101.06983, gather_across_devices=True, lowering GPU memory barriers for multi-vector contrastive training.
Common pitfall: Assuming “dense + KD” is enough (ColBERT-Zero paper argues clear under-training); treating prompts like ChatGPT system prompts.
Fine-tuning productization (speaker opinion): ColBERT-class models “don’t collapse easily,” suitable for embedding fine-tuning product lines—consistent with P01 MaxSim mechanism narrative, but “gradients only update matched tokens” is training intuition; check PyLate loss implementation, not a ColBERT paper theorem.
Multimodal and hybrid signals#
Why: Image/video token density far exceeds text paragraphs; single-vector compression loses more (speaker opinion, information-theoretic argument, no quantitative theorem).
Mechanism / constraints: Text-side ColBERT-Zero already aligns dense vs. multi-vector under comparable training; fair multimodal comparison still skewed by pretraining scale imbalance (speaker opinion).
Hybrid retrieval: Both agree to keep BM25 with complementary failure modes vs. dense and ColBERT; tuning focus is candidate M per stage and rerank depth (speaker opinion).

Rerank controversy (not fully verified): Connor cited Databricks “Drowning in Documents” where increasing candidate M yields phantom hits—that URL returned 404 on 2026-05-17 fetch; body could not be verified. Antoine offered another narrative: rerankers are weak on the distribution tail because training uses only hard negatives; fix requires tail samples—whether same study, not verified.
Common pitfall: Dropping BM25 for the strongest semantic model only; or crushing dense candidate M for latency then blaming ColBERT rerank for ineffectiveness.
If you are shipping this#
- Dimension first, then index: document count, average tokens, QPS, whether full in-memory MaxSim fits—small corpora: exact compute; large corpora: PLAID / Muvera + full-precision rerank.
- Fix metric definitions: retrieval reports nDCG@10 / MRR@10; code uses MTEB Code v1; reasoning-intensive uses BRIGHT—do not mix with general MTEB leaderboard.
- Bake cascade into SLA: dense recall → multi-vector MaxSim → (optional) cross-encoder; log recall@M each stage; avoid blindly increasing M on phantom hits or tail collapse.
- Agent code path: keep grep; try semantic layer ColGrep / LateOn-Code, A/B on your repo (speaker opinion: latency near grep).
- Tight training budget: follow ColBERT-Zero skipping the costliest unsupervised stage; reproduce with PyLate + GradCache, start public data from Nomic Embed mixtures.
References and further reading#
- ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
- ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
- PLAID: An Efficient Engine for Late Interaction Retrieval
- Muvera: Fixed Dimensional Encoding for Multi-Vector Retrieval
- BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval
- ReasonIR: Training Retrieval Models to Reason
- ColBERT-Zero: Multi-vector pretraining recipe and BEIR results
- ColBERT-Zero model card and training cost notes
- Nomic Embed: Public training data mixture
- GradCache: Large-batch contrastive learning
- PyLate: ColBERT training and retrieval library
- Fast Plaid: Rust multi-vector index engine
- ColGrep and LateOn-Code release notes
- MTEB Leaderboard
- Weaviate vector index concepts


