
The Multi-Vector Retrieval Index Paradox: How MUVERA Approximates Chamfer with Single-Vector ANN#
Models such as ColBERT and ColPali represent a document as a set of token-level vectors. At query time they use late interaction (for each query token, take the maximum similarity over document tokens, then aggregate—commonly called MaxSim in industry, often written as Chamfer in papers) to gain finer semantic alignment than a single-vector bi-encoder. The cost is direct: index entries grow from “one per document” to “hundreds per document,” and the query side must perform matrix-style interaction. Google Research’s MUVERA (Multi-vector Retrieval via Fixed Dimensional Encoding) proposes FDE (fixed dimensional encoding): a deterministic, non-learned spatial partition that compresses a multi-vector set into one high-dimensional single vector, runs one approximate nearest neighbor pass on HNSW / MIPS, then reranks the top-K with true Chamfer. Weaviate v1.31 has integrated this encoding path.
What follows is a standalone technical synthesis for experienced engineers: verifiable paper/documentation is kept separate from interview opinions. We do not mix BEIR nDCG with paper Recall@N, and we do not imply that “single-vector heuristics” and MUVERA have an absolute winner on every dataset.

Problem space: three retrieval paradigms and an overlooked similarity#
Why late interaction returns you to “index entry count”#
The retrieval layer in RAG and Agent systems usually trades off among three tiers (speaker opinion, consistent with ColBERT community narrative):
| Paradigm | Document representation | Query cost | Typical bottleneck |
|---|---|---|---|
| Cross-encoder | No query-independent doc vectors | All-pairs attention | Cannot scale ANN |
| Single-vector dual encoder | One embedding | One ANN | Loses token-level interaction |
| Multi-vector | Fixed doc token vector set | Late interaction at query time | Storage + multiple retrievals/reranks |
MUVERA paper §1.1 states the multi-vector similarity standard as
[ \textsc{Chamfer}(Q,P)=\sum_{q\in Q}\max_{p\in P}\langle q,p\rangle ]
and notes it is synonymous with MaxSim; distance variants are also called relaxed earth mover distance. Rajesh Jayaram (first author of MUVERA) analogizes multi-vector similarity to Earthmover / optimal transport in the interview, with the difference that one-to-one token matching constraints are removed (speaker opinion; no theorem number for formal isomorphism was given on the podcast).
Mechanism and constraints#
- ColBERTv2 experimental setting: d=128, |Q|=32 query tokens (MUVERA §3).
- Chamfer is insensitive to duplicate tokens on the document side (max over P treats duplicates identically) but sensitive to duplicates on the query side—formally true; Rajesh analogizes this to asymmetric set containment (speaker opinion).
- Retrieval with schema constraints (e.g., title must not match body) is not applicable to Chamfer as-is; the loss or masks must change (speaker opinion; ColBERT/MUVERA main text does not expand).
How to (minimal example)#
Conceptually: at index time store all token vectors in P; at query time compute Q, then Chamfer or the engine’s MaxSim operator (Weaviate tutorial).
Common pitfalls#
- Assuming “average then max” is equivalent to the paper’s sum—implementations may divide by |Q|; do not assume consistency with paper notation by default.
- Treating Chamfer as the default metric for arbitrary structured-field retrieval.

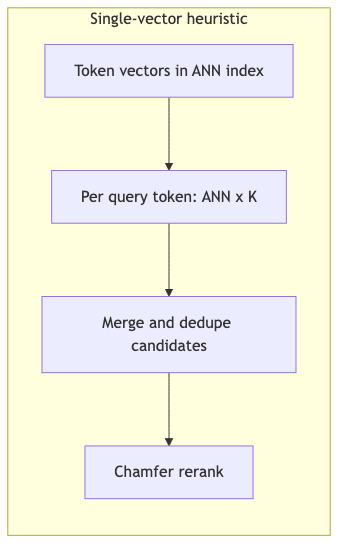
Single-vector heuristics: workable in practice, no theoretical guarantee#
Why ColBERTv2 / PLAID still flatten tokens into ANN#
Before MUVERA, the community’s mainstream approach was the single-vector heuristic (paper terminology): treat each query/document token embedding as an independent vector in a MIPS/ANN index; retrieve per query token, merge candidates, then rerank with Chamfer. PLAID adds centroid interaction, pruning, etc., and reports large latency reductions versus vanilla ColBERTv2 relative to the baseline (paper data, not podcast QPS tables).
The oral workflow from the interview (compatible with the paper; K varies by implementation): roughly 32 ANN calls → up to 32×K candidates → deduplication → MaxSim rerank. Roberto Esposito (Weaviate Applied Research) stresses candidate set size and rerank cost.
Mechanism and failure modes#
MUVERA states explicitly: this heuristic may fail to find true Chamfer nearest neighbors, and must query a larger index for each query embedding (introduction).
Speaker opinion counterexample: a document with extremely high similarity on one query token but poor alignment elsewhere may still be recalled; a document with ~80% global alignment can lose to a “single perfect token match”—at odds with intuition about “overall query semantics.” The paper theoretically emphasizes the SV proxy has no ε-approximation guarantee, but does not number podcast-style counterexamples.
How to#
If you already run PLAID/ColBERTv2, you need not tear it down short term; in evaluation, log recall@K (Chamfer ground truth) and latency, not end-to-end nDCG alone.
Common pitfalls#
- Equating PLAID’s centroid pruning with “bare flattening: 32 ANN calls”—implementation details per PLAID paper.
- Believing “reranking always fixes recall errors”—reranking only reorders documents already in the candidate set.
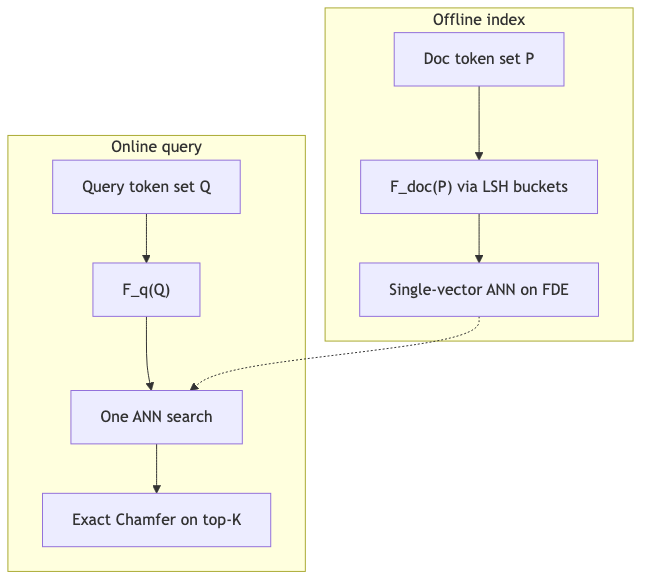
MUVERA / FDE: one ANN + a provable proxy#
Why “back to single vector” is not training another bi-encoder#
MUVERA’s core is asymmetric deterministic encodings (\mathbf{F}{\text{q}}(Q)), (\mathbf{F}{\text{doc}}(P)) such that the inner product ε-approximates Chamfer (Theorem 2.1 / 2.2, §2). This differs from “train a separate single-vector model + ColBERT rerank”: the latter has no guarantee linking single-vector scores to multi-vector scores (interview opinion, aligned with the paper’s “first provable single-vector Chamfer proxy” claim).
Offline: compute FDE for documents (and queries) → one MIPS/ANN (existing solvers; product side often HNSW) → true Chamfer rerank on top candidates. Roberto describes shrinking candidates from “32×K scale” to “K scale” (directionally consistent; strict K still depends on over-retrieve settings).
Paper-level summary vs PLAID (BEIR subset experiments, not universal over all corpora): ~10% higher average recall, ~90% lower latency; at matched recall, FDE may need ~2–5× fewer candidates than the SV heuristic (abstract).
Mechanism: cannot concatenate tokens before the query arrives#
MaxSim matching is query-dependent: before the query arrives, which query token a document token should align with is unknown (speaker opinion + algorithmic necessity). Simply concatenating token vectors does not yield FDE; enumerating permutations is infeasible at |Q|=32.
How to (parameter mental model)#
Weaviate documentation gives the encoding dimension formula (verified):
[ \text{dimension} = \texttt{repetitions} \times 2^{\texttt{ksim}} \times \texttt{dprojections} ]
Example ksim: 4, dprojections: 16, repetitions: 20 → 5120 dimensions. Paper experiments use d_FDE ∈ {2460, 5120, 10240}; spoken “5k–10k” should be read as a range, not a single point. Configuration: Multi-vector encodings.
Common pitfalls#
- Treating FDE inner-product score as the final ranking score—production should still Chamfer-rerank top-K.
- Assuming the paper claims K=1 suffices in production—that is an interview inference from the FDE ideal limit; the paper discusses recall–latency Pareto.

FDE construction: bucketing, asymmetric aggregation, and empty buckets#
Why LSH instead of “32 k-means centroids”#
Spatial partition (\bm{\varphi}) defaults to SimHash (LSH); k-means is also possible (§2). For each bucket (k):
- query side: sum token vectors in the bucket;
- document side: average token vectors in the bucket (avoids doc duplicate tokens inflating scores; Rajesh notes proofs hold for average or any single point in the bucket).
fill_empty_clusters: document FDE only; query side never for queries (paper wording). Filling empty buckets on the query side artificially inflates scores for buckets with no corresponding query token (interview explanation consistent with the algorithm).
Multiple independent SimHash repetitions can be concatenated to reduce variance. Paper comparison: replacing SimHash with k-means on the Pareto front usually no gain and often worse, and loses data-oblivious properties.
Rajesh’s speaker opinion: partition count should be on the order of query token count (~32–64); at tens of millions to billions of tokens, k-means with very few centers underfits; LSH’s “guarantees for all points” at the encoding stage beats underfit clustering. This does not contradict “LSH underperforms HNSW on general ANN benchmarks”—LSH is for bucket partitioning, HNSW for FDE ANN (interview + paper division of labor).
How to#
When tuning, sweep ksim (bucket count (2^{ksim})), repetitions, dprojections first; Weaviate default example ksim: 4 → 16 buckets, not a paper-mandated 32–64.
Common pitfalls#
- Applying subspace PQ in ways that break within-bucket semantics—Roberto warns PQ-style splits on the spatial partition may break guarantees (engineering warning, not theoremized line-by-line in the paper).
- Equating document-side averaging with rerank-stage ball carving—the latter is token merging at another stage (see below).
Dimension, PQ, and reranking: staying memory-efficient after inflation#
Why exploding FDE dimension can still save memory#
Index entry count drops from “hundreds of token vectors per doc” to one FDE. On ColBERTv2, average ~10,087 floats per doc (≈ tokens×128, §3). FDE can reach 10240 dimensions, then ~32× product quantization (example: 10240 dims → 1280 bytes, abstract). The interview calls PQ a key piece of paper and product paths; Weaviate v1.31 can stack MUVERA with PQ/BQ/RQ/SQ (compression docs).
Larger FDE → higher Recall@N → smaller retrieval K; smaller FDE needs larger K and heavier reranking (paper Pareto + interview trade-off).
Rerank acceleration: paper ball carving vs podcast numbers#
Appendix ball carving (§C.3): cluster query tokens before reranking; on MS MARCO, query embedding count reduced ~5.4× (τ=0.7, etc.). Podcast oral “4× pruning, 16× matmul” — not found verbatim in MUVERA; label as interview opinion or cite ball carving paper data when writing.
Weaviate v1.31 experiments: PQ and scalar quantization both materially improve QPS (product experiments / interview); no official absolute QPS table matching the podcast.
Common pitfalls#
- Treating Recall@N (FDE retrieval) and nDCG@10 (BEIR end-to-end) as the same metric.
- Assuming float32→1-bit scalar quantization’s theoretical ~32× ceiling always beats PQ—depends on implementation and recall loss; measure yourself.

Evaluation and product boundaries: BEIR, CRISP, and incomparable SOTA#
Why multi-vector should not “leaderboard chase” single-vector SOTA directly#
MUVERA experiments use BEIR 6 subsets (including MS MARCO, HotpotQA, NQ, Quora, SciDocs, ArguAna). Rajesh’s methodology opinion: compare on the same IR data, but scores only against other multi-vector models; do not claim victory over years of hill-climbed single-vector SOTA. Long queries and complex documents need new benchmarks (interview; MTEB main leaderboard is mostly single-vector tasks—no official equivalent multi-vector leaderboard found).
CRISP (Clustering Multi-Vector Representations for Denoising and Pruning, co-authors include Rajesh Jayaram) reports vector reduction vs. quality trade-offs on BEIR; abstract examples include ArguAna C4×8 +5.5% vs. unpruned, etc. “Podcast drove CRISP release” — cannot verify (paper submission date 2025-05-16).
Engineering integration (verified)#
| Capability | Version |
|---|---|
| Multi-vector + late interaction | v1.29+ |
| Multi-vector GA | v1.30 (blog) |
| MUVERA encoding | v1.31 |
Tutorial model examples: ColBERT, ColPali, ColQwen; configure Encoding.muvera(...) per official docs.
Common pitfalls#
- On sensitive subsets like ArguAna, concluding “multi-vector doesn’t work” without tuning pruning/clustering (CRISP direction).
- Mixing v1.29 multi-vector requirements with v1.31 MUVERA requirements.

Disciplinary culture: why NN theory and vector databases talked past each other#
Rajesh argues that nearest-neighbor search theory (sketching, LSH, ε-approximation) and vector database practice (HNSW, IVF, DiskANN, product quantization) have had limited cross-talk for two decades (speaker opinion). MUVERA can be read as embedding a provable proxy into the MIPS index pipeline; whether it becomes mainstream depends on multi-vector model share in RAG/Agent stacks and whether FDE+PQ Pareto beats your PLAID engineering stack on your data.
No unified conclusion: PLAID remains a strong baseline; MUVERA reports higher recall and lower latency on paper subsets, but coverage of your corpus, schema constraints, and SLOs requires self-testing. Whether high-dimensional FDE can be replaced outright by a learned compressed representation is an open question per Rajesh (interview).
If you are shipping this#
- Fix the metric first: confirm the product truly needs Chamfer/MaxSim; with field-level matching constraints, change loss or masks before picking index structure.
- Track two metrics: Recall@N (vs. Chamfer ground-truth neighbors) at the FDE stage separately from end-to-end nDCG/MRR; do not compare directly to single-vector MTEB leaderboards.
- Compare two recall chains: on the same ColBERTv2 index, run SV heuristic/PLAID vs. MUVERA FDE (Weaviate ≥1.31 or paper reference implementation); sweep
d_FDEand retrieval K on the Pareto curve. - Encoding parameters: start near paper 5120/10240 and the Weaviate formula; sweep
ksim,repetitions; when enabling PQ, measure recall loss separately; empty-bucket fill on doc side only. - Rerank budget: on top-K Chamfer, add ball carving (paper ~5.4× query token reduction) rather than blindly trusting podcast 4×/16×; for ArguAna-like tasks, evaluate whether CRISP-style pruning is necessary.
References and further reading#
- MUVERA paper (arXiv:2405.19504)
- MUVERA HTML full text (§1 Chamfer / §2 FDE)
- ColBERT (SIGIR'20)
- ColBERT official README (MaxSim diagram)
- ColBERTv2
- PLAID: Performance-optimized Late Interaction Driver
- BEIR benchmark paper
- BEIR GitHub suite
- CRISP: clustering multi-vector representations for denoising and pruning
- Weaviate tutorial: Multi-vector embeddings
- Weaviate: Multi-vector encodings / MUVERA configuration
- Weaviate 1.31 release notes (MUVERA)
- Weaviate GitHub Release v1.31.0
- ColPali: visual document late interaction
- Original RAG paper (retrieval-augmented generation framework)


