
Agents on Semi-Structured Retrieval: STaRK Benchmark and AvaTaR Optimization#
When a knowledge base holds both free text and explicit relations (product attributes, citation graphs, drug–protein–disease edges), “wire up a vector store + function calling” does not automatically mean good retrieval. Stanford PhD student Shirley Wu, on the STaRK and AvaTaR lines of work, splits the problem into measurable benchmarks and optimizable tool policies. What follows synthesizes her published papers and frontline engineering discussion without forcing a single conclusion—where interview claims and published tables tension, that is called out.
Problem space: why a dedicated benchmark for “retrieval agents”#
Why: Enterprise knowledge bases increasingly resemble semi-structured knowledge bases (SKBs)—nodes with multiple text spans and attributes, edges expressing brand, indication, co-authorship. Traditional practice evaluates textual retrieval (BM25 / dense VSS) and relational retrieval (text-to-SQL, graph traversal) separately, while real queries need both: “Nike + cute design” requires structural filtering and semantic matching (speaker opinion).
Mechanism / constraints: STaRK unifies retrieval tasks on three SKBs: STaRK-Amazon (products), STaRK-MAG (academic graph subgraph), STaRK-Prime (biomedical graph based on PrimeKG). Metrics follow retrieval literature: Hit@k (whether the correct answer appears in top-k), Recall@k (fraction of relevant items covered in top-k; synthetic sets often use k=20), MRR (mean reciprocal rank of the first relevant result)—see the STaRK paper experiments section.
How: Use the official snap-stanford/stark eval.py on the same query set to compare BM25, ada-002 single-vector VSS, graph-neural-network baselines, and agent pipelines—avoid per-domain one-off scripts.
Common pitfall: Treating STaRK as “another RAG QA set.” It is entity-level retrieval (return node / product / paper IDs). Whether SQL or vector search is called in the middle is up to the system; scoring is still Hit@1 / Recall@20.
flowchart LR
Q[Query] --> A{Agent policy}
A --> T[Textual tools<br/>VSS / BM25]
A --> R[Relational tools<br/>filter / traverse]
T --> SKB[(Semi-structured KB)]
R --> SKB
SKB --> M[Hit@k / Recall@k / MRR]
Operational definition of agents and retrieval roles#
Why: “Agent” is overloaded onto a single completion. If the optimization target is vague, prompt search and architecture search cannot be attributed.
Mechanism / constraints (speaker opinion): Agent ≈ LLM + multi-step tool use + verifiable changes to the environment; a retrieval agent specifically chooses sequences of textual tools (semantic search) and relational tools (attribute filter, neighborhood expansion) on an SKB. Contrast with hand-built workflows (fixed DAGs) and compound multi-agent setups (multiple roles, multiple intermediate artifacts); on STaRK-style end-to-end metrics, intermediate-step failures can be masked by the final answer (speaker opinion).
How: For each tool, specify input schema and failure semantics—interviews note zero-shot setups often confuse “vector similarity” with “metadata filter,” analogous to splitting nearText vs where on Weaviate (host practice, not a STaRK paper requirement).
Common pitfall: Judging agent capability by “whether an API was called.” What matters is whether the action sequence changes with query patterns, not call count.
Multi-vector retrieval: Recall rises, Top-1 may still fall short#
Why: A single text embedding dilutes signals at different granularities (title, brand, specs); embedding node fields separately and aggregating (multi-vector) is a natural baseline.
Mechanism / constraints: AvaTaR paper Table 2 compares ada-002 vs multi-ada-002 (separate embeddings per text span, then aggregate): on Amazon, Recall@20 rises from 53.29% to 55.12%, Hit@1 from 39.16% to 40.07%; on Prime, Recall@20 +2.05pp, Hit@1 +2.47pp. But on the MAG subset Hit@1 drops from 29.08% to 25.92%—so “multi-vector always improves” does not hold. Versus AvaTaR-optimized Amazon Hit@1 49.87%, multi-ada-002 at 40.07% is still ~10 points behind—aligned with “better recall, first hit still weak” (speaker opinion; numbers from the paper, not interview oral quotes).
How: Treat multi-vector as a recall layer; the upper layer still needs query decomposition (divide-and-conquer) and relational filtering. Do not prove product readiness from Recall@20 alone.
Common pitfall: More embedding fields = relational constraints solved. Structural conditions (brand, indication) often need anchor nodes first, then neighborhood expansion.
When a fully tooled agent loses to a dense retriever#
Why: If an agent underperforms single-vector retrieval, prompt optimization matters more than stacking tools—one motivation for AvaTaR.
Mechanism / constraints:
- Speaker opinion (first-hand): The team’s zero-shot tool agent on STaRK (with prompt engineering / ICL) was clearly worse than a simple dense retriever (~29:01 segment).
- Partial conflict with the paper: In the same Table 2, ReAct (Claude 3 Opus) Hit@1 on Amazon / MAG / Prime is not below ada-002 VSS (e.g. Amazon 42.14 vs 39.16). So “agents always lose to dense” cannot be inferred directly from published ReAct rows; it more likely points to an early in-house agent (tool descriptions, function boundaries, unoptimized policy) vs paper baseline configuration.
- Qualitative support: AvaTaR introduction and Figure 2 note hand-crafted mega-prompt ReAct on product queries tends toward trivial / misleading answers and struggles to escape LLM prior tool patterns (paper).
How: First lock a strong simple baseline (single-vector + necessary metadata filters), record Hit@1 / Recall@20, then add tool chains; during optimization use validation-set Recall@20 to split positive / negative query batches (paper default ℓ=h=0.5, batch b=20).
Common pitfall: Equating Table 2 ReAct with the interview’s “failed agent.” For writing and reproduction, document tool list, model version, whether AvaTaR optimization was applied.
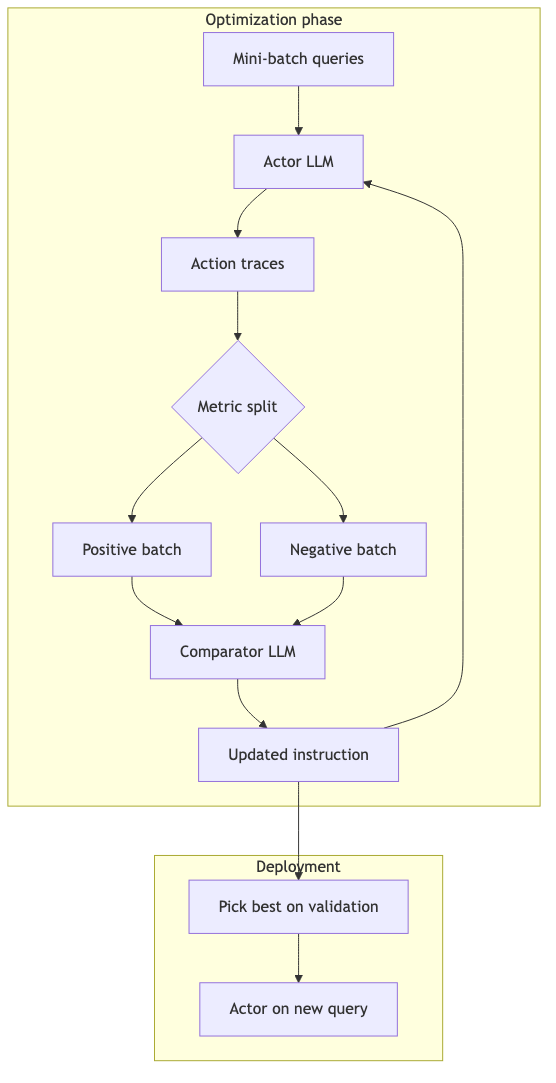
AvaTaR: Contrastive Prompt Optimization#
Why: With too few labeled trajectories, SFT / RL is impractical; you need to induce patterns from success and failure of the same action sequence across a batch of queries (e.g. decompose complex queries, when to use relational tools).
Mechanism / constraints (AvaTaR paper §4, verified):
- Actor LLM runs a tool action sequence per query;
- Split mini-batch into positive / negative by Recall@20 (retrieval) or Accuracy (some QA);
- Comparator LLM does contrastive reasoning on the two batches, produces holistic instruction, updates actor policy and tool descriptions;
- After several optimization epochs, deploy the best action sequence / instruction on the validation set.
Relation to OPRO (speaker opinion; AvaTaR body does not name OPRO): both can maintain multiple candidates and pick on validation; OPRO writes historical solutions and scores into a meta-prompt for the LLM to generate new prompt text, while AvaTaR’s evolution axis is contrastive batches across query patterns, optimizing reusable actions / instructions, not a pure natural-language prompt population. Note: briefing docs once mis-cited OPRO as arXiv:2306.03427; the correct id is 2309.03409.
How (minimal conceptual loop):
# Pseudocode: single optimization step
batch = sample_queries(train, b=20)
for q in batch:
trace[q] = actor.run(q, instruction=current_instr)
pos = [q for q in batch if metric(trace[q]) >= threshold_high]
neg = [q for q in batch if metric(trace[q]) < threshold_low]
current_instr = comparator.contrast(pos, neg, traces={**pos, **neg})
best_instr = select_best_on_validation(candidates)
Ablation AVATAR-C (no comparator) shows clear Hit@1 drops on STaRK (paper Takeaway 2)—the comparator is not decorative.
Graph traversal, GraphRAG, and one-hop message passing#
Why: For a “Nike shoes” query, query–node cosine similarity alone may hit irrelevant Nike entries; anchor the brand node then take neighbors along edges—usually more precise (speaker opinion). This is isomorphic to GraphRAG “vector seed → expand subgraph as context,” chain-of-thought on a graph (speaker opinion).
Mechanism / constraints: One layer of message passing aggregates direct neighbors only; k layers ≈ k-hop. The speaker’s “shoe node—price neighbor—image node” example: at hop=1, price attributes can update the shoe representation but do not propagate to an image node without a direct edge—teaching analogy only, not in STaRK / AvaTaR text; the mechanism itself matches PyG docs.
How: Implement relational tools as constrained traversal (edge type, depth, node-type filters), not free-form Cypher from the LLM; the agent chooses “filter then expand” vs “semantic then filter.”
Common pitfall: Using the LLM as an embedding model; on queries that need decomposition, spend reasoning tokens on query splitting, not longer single vectors.
Multi-agent, workflow, and compound systems: optimization boundaries#
Why: One task admits many agent decompositions (researcher → writer, etc.); structural effects tangle with randomness (speaker opinion). Compound AI has many intermediate artifacts; end-to-end metrics poorly attribute failure to a single agent.
Mechanism / constraints (speaker opinion):
- Push back on role-play chat; prefer task-specialized agents (different prompts / tool sets) collaborating.
- Host path: hand workflow + DSPy / MIPRO stepwise optimization + AvaTaR to refine tool descriptions—coexists with “single agent self-edits prompt”; no unified optimum (interview discussion).
- Evaluation: input–output only misses intermediate errors; add metrics or LLM-as-judge on key intermediate states (AvaTaR uses a judge on some QA subtasks, paper §4).
How: In compound systems, selectively optimize bottleneck agents (usually retrieval / planning), keep the rest fixed; avoid searching architecture and prompt simultaneously.
Common pitfall: Agent count ∝ performance. The interview stresses compatibility: some agent combinations are mutually exclusive; the search space needs constraints.
Memory banks, kNN trajectories, and contrastive batches#
Why: Whether longer context obsoletes memory banks is unsettled; the speaker still keeps a “store successful trajectories” database-style memory route because stuffing everything into context is costly (speaker opinion).
Mechanism / constraints:
- Speaker opinion: The team used an experience library—at test time retrieve the most similar trajectory for few-shot—with poor results, tending to learn instance rules like
if Nike in query(overfit-style hard coding). - Paper contrast: AvaTaR has no “experience library” by that name; optimization uses a memory bank for historical best instructions/actions (prevent actor repeating mistakes), not test-time kNN trajectory retrieval. Baseline ExpeL is closer to “retrieve success/failure trajectories into context at inference”; on STaRK-MAG it is near ReAct and far below AvaTaR (paper Takeaway 1 vicinity)—supports “retrieving similar trajectories is weaker than contrastive batch optimization,” but does not verbatim restate the Nike case.
How: Prefer the comparator inducing patterns from cross-query positive/negative batches; if using few-shot, retrieving workflow templates is usually stabler than full trajectories (speaker opinion), but still validate out-of-domain.
Common pitfall: Equating optimization-phase memory bank with test-time RAG-style trajectory stores.
Open questions (tension preserved on purpose)#
| Topic | More aligned | Disagreement or unverified boundary |
|---|---|---|
| STaRK three-domain unified eval | Paper + code | Multimodal extension stated as direction only |
| Multi-vector | Amazon/Prime Recall↑ | MAG Hit@1 counterexample |
| Zero-shot agent vs dense | Intro / interview qualitative | Table 2 ReAct ≥ ada-002 |
| AvaTaR mechanism | Paper Figure 1 / Table 2 | Per-domain gains need appendix |
| OPRO comparison | Interview | AvaTaR body does not name OPRO |
| GNN shoe/graph example | Mechanism vs PyG | Interview analogy only |
| Experience library | Interview negative ablation | Paper: ExpeL + memory bank indirect |
If you are shipping this#
- Pin the baseline first: On the same SKB, run
ada-002VSS + necessary attribute filters, record Hit@1 / Recall@20, then layer a tool agent—avoid prompt tuning without a floor. - Split textual / relational tool contracts: Vector search vs metadata filter inputs, outputs, and error codes in the tool schema to reduce zero-shot mixing (engineering can follow hybrid query docs from your vector store).
- Optimize policy with contrastive batches, not stacked few-shot trajectories: Under small labels, use validation Recall@20 to split positive/negative batches and iterate instructions; be wary of test-time kNN trajectory stores that overfit.
- In compound systems, optimize retrieval/planning bottlenecks only: Add observable metrics on intermediate steps so end-to-end “looks fine” does not hide retrieval failure.
- Public reproduction: Clone snap-stanford/stark and AvaTaR appendix configs; reproduce one Table 2 row on STaRK-Amazon before extending to your own SKB.
References and further reading#
- STaRK paper (arXiv:2404.13207) — semi-structured retrieval benchmark and three-domain tasks
- STaRK project site — datasets and leaderboard entry
- STaRK GitHub (snap-stanford/stark) — eval scripts and data keys
amazon/mag/prime - STaRK Hugging Face dataset — direct load for experiments
- AvaTaR paper (arXiv:2406.11200) — contrastive prompt optimization and Table 2 baselines
- OPRO paper (arXiv:2309.03409) — evolutionary prompt optimization comparison
- OPRO code (google-deepmind/opro) — official implementation reference
- PrimeKG repository — biomedical graph source for STaRK-Prime
- PrimeKG project page (Harvard Zitnik Lab) — integrated data sources
- PyTorch Geometric — Message Passing tutorial — k-hop and layer constraints
- Weaviate developer docs — vector + filter hybrid retrieval (podcast ecosystem context)
- DSPy project — declarative prompt / program optimization (host practice path)
- Gorilla (Berkeley tool-calling LLM) — early tool-learning benchmark reference
- Dense Passage Retrieval (DPR, arXiv:2004.04906) — dense retriever methodology background
- ReAct paper (arXiv:2210.03629) — agent baseline source in AvaTaR Table 2


