
Agent Oversight Stack: From Static Evaluation to Trajectory-Level Observability#
Multi-agent systems shift engineering focus from “single-generation quality” to “whether long trajectories are trustworthy.” Fixed benchmarks still help, but in open-ended tasks the action space explodes, and the cost of humans reading traces line by line does not scale with model capability. In public narratives around Percival, Patronus AI co-founder Anand Kannappan frames the problem as a progression: evaluation → observability → oversight. This article unpacks that chain mechanistically and marks the boundary between literature, official documentation, and speaker opinion—without pretending all parties have converged on a single conclusion.
Problem space: a four-stage stack and three tensions#
A common evolution path (speaker opinion) can be summarized as: isolated LLM → composite systems with RAG → single-agent tool loops → multi-agent mutual calls. After the third stage, three structural tensions recur in the interview; quantitative claims (e.g., “tens of millions of tokens of context”) lack reproducible benchmarks and should be treated as directional signals, not scale facts:
| Tension | Engineering consequence |
|---|---|
| Context explosion | Long trajectories exceed a single window; action order matters strongly |
| Domain adaptation | Generic rubrics struggle to cover vertical compliance |
| Multi-agent orchestration | Static test cases poorly enumerate joint failure modes |

Static evaluation is not obsolete, but its boundary is narrowing#
Why#
Flows with few steps and clear goals—booking tickets, writing a fixed blog post, schema validation—still suit fixed datasets and outcome checks (speaker opinion). Industry practice has long used benchmarks such as HaluBench for regression.
Mechanism and constraints#
Open marketing agents and autonomous systems with unpredictable paths see preset test-case coverage decay quickly; “process rewards” used for optimization often require runtime judgment of whether each step is compliant, not offline labels alone (speaker opinion). This is conceptually adjacent to per-instance natural language unit tests emphasized in LMUnit: criteria can be generated at runtime, but no public implementation comparison exists between Percival and LMUnit.
How to do it (minimal example)#
For a fixed RAG pipeline, keep a regression set of (context, question, answer) triples and use a dedicated judge for binary hallucination detection:
# Conceptual sketch: Lynx-style judge outputs grounded / not grounded
verdict = lynx_judge(context=ctx, answer=ans) # see HaluBench protocol
assert verdict.label in {"grounded", "hallucination"}
Common pitfalls#
- Abandoning all static sets because agents are trendy; highly deterministic subtasks should keep snapshot tests.
- Generalizing the interview claim that “static eval is impossible” to every system—that statement targets high-openness multi-agent setups and cannot be verified as a universal law.
Production traces first: Percival and a failure taxonomy#
Why#
Patronus debugging documentation positions Percival as analyzing agentic traces, detecting errors, and offering optimization guidance; the first-version narrative emphasizes interpreting traces that already ran (dev, test, or production), not replacing the entire static eval pipeline (speaker opinion). Customer anecdotes claim that manually understanding a handful of traces can take “hours,” and turning another trace into an eval case adds roughly “+1 hour/trace”—no sample size or statistical protocol; use only as an order-of-magnitude cost reference.
Mechanism and constraints#
The public Error Taxonomy documents 20+ failure modes across categories such as Reasoning, System Execution, and Planning and Coordination; Custom error taxonomies are supported for extension. The interview once cited 60 categories—inconsistent with the site’s 20+; that may include subtypes or internal enumerations; as of public documentation, no full list of 60 items exists.
A demo case (not representative of average product performance) scored a single run on multiple 1–5 dimensions: documentation explicitly lists security, reliability, and other dimensions; the UI also shows extensions such as Plan Optimality and Instruction Adherence.
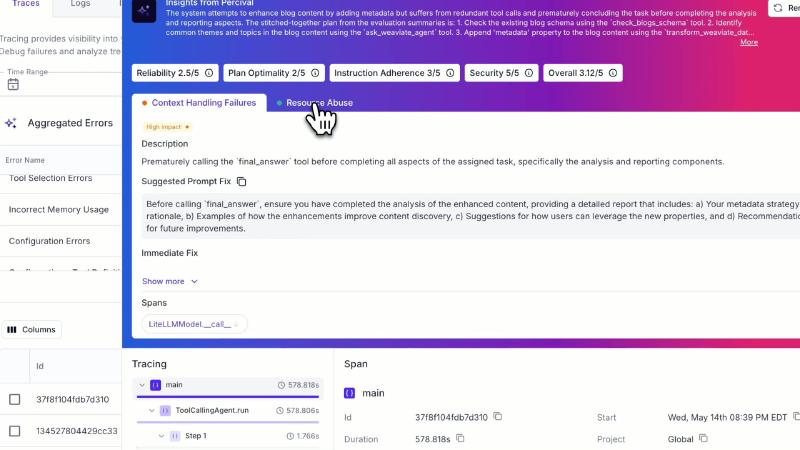
OCR and documentation align on fragments such as Context Handling Failures and Tool Selection Errors; Prematurely calling the ‘final_answer’ tool appears in the demo UI but was not found as a named entry in the public base taxonomy table. The trace tree shows ToolCallingAgent.run with a span of roughly 578.818s, indicating supervision targets long-running, multi-step tool-call chains—not a single completion.
How to do it#
- Import existing OpenTelemetry / framework traces into Patronus or a comparable platform.
- Derive rubrics from high-frequency failure modes, then decide whether to add them to a custom taxonomy.
- Treat Suggested Prompt Fix (documentation:
Suggests concrete prompt improvements) as input for human review; avoid unverified one-click automatic prompt changes (product strategy, speaker opinion).
Common pitfalls#
- Treating a single demo Overall 3.12/5 as an SLA.
- Assuming the taxonomy already covers “premature final_answer”—custom taxonomy or product updates may be required.
- Blurring advisory fixes and automatic patches, triggering incorrect auto-repair loops (speaker opinion).
LLM-as-a-judge: two tracks for dev-time evaluation and real-time guardrails#
Why#
The same “model judges model” paradigm serves different goals under different latency budgets: offline comparison of prompts/weights vs. online interception of high-risk output.
Mechanism and constraints#
Lynx (PatronusAI/Llama-3-Lynx-70B-Instruct) targets reference-free hallucination detection for RAG; on HaluBench (~15k samples, including finance, medicine, etc.) it reports Accuracy, with the paper claiming superiority over GPT-4o, Claude-3-Sonnet, and peers under the same setup. Training uses CoT reasoning traces generated by GPT-4o for instruction tuning—literature supports that approach; the interview’s “first evaluation model trained with CoT” is overclaimed and should not be written as a global first.
Glider (GLIDER 3.8B, based on Phi-3.5-mini-instruct) supports 0–1 / 1–3 / 1–5 Likert scales, rubrics, and multi-metric scoring; the paper uses Pearson correlation against human ratings on settings such as FLASK, and reports F1 on some LiveBench subtasks (e.g., GLIDER 0.654 vs GPT-4o-mini 0.481). The interview’s “first SLM to match GPT-4o-mini” should be scoped to specific benchmarks, not all-task SOTA.
| Product | Typical scenario | Primary metric (paper) |
|---|---|---|
| Lynx | RAG groundedness, offline regression | HaluBench Accuracy |
| Glider | Guardrails, low-latency multi-metric | Pearson / F1 (task-dependent) |
Debate-style judges (multiple models arguing) were judged in the interview as almost absent from production; foundation models from the same pretraining distribution debating each other share directional bias; dedicated judges with non-overlapping distributions are needed (speaker opinion, no census data).
How to do it#
# Glider: multi-metric output per rubric (0–1 or Likert)
scores = glider.score(
interaction=log,
rubric={"helpfulness": "...", "safety": "..."},
)
if scores["safety"] < threshold:
block_or_escalate()
Common pitfalls#
- Analogizing Lynx Accuracy to NDCG in search—the host made that interview analogy; it is not a paper metric.
- Stacking high-latency debate judges on the default production path by default.
- Ignoring that Glider and Lynx use different benchmarks (FLASK vs HaluBench) and directly comparing “which is stronger.”

Dynamic evaluation and scalable oversight#
Why#
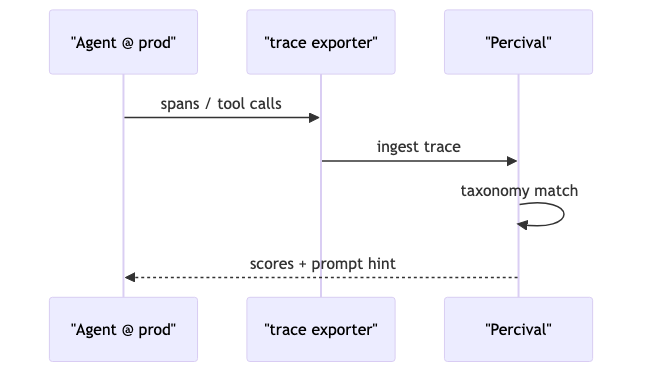
When humans cannot review AI output at scale, systems of comparable capability must judge the agent under test at runtime (speaker opinion). This is conceptually adjacent to scalable oversight in Bowman et al., 2022—that paper does not prove Percival works; do not graft its conclusions onto the product as empirical validation.
Mechanism and constraints#
Dynamic evaluation ≠ abandoning benchmarks; it supplements unpredictable trajectories with process-level adjudication. Percival is positioned as one productized path for agentic supervision; industry “supervision” terminology (e.g., OpenTelemetry) was not precisely mapped in the interview—use terms domain-by-domain in writing.
A counterintuitive point (speaker opinion, no quantitative survey): users care more whether the workflow completes than sub-second response; extra inference latency for supervision may be acceptable in some scenarios. That does not fully align with “more test surface inevitably ruins UX”—pressure often lands on compute and human trace interpretation, not latency alone.
How to do it#
Common pitfalls#
- Reading “AI oversee AI” as replacing human-in-the-loop; the interview stresses collaborative interfaces (chat, inbox-style questioning), not fully automated release.
- Treating scalable-oversight paper results as Percival A/B test conclusions.
Memory layer: episodic vs semantic roles#
Why#
Long-trajectory supervision needs accumulation across runs: “how we fixed a similar failure last time” vs. “domain baseline facts” are different information types.
Mechanism and constraints#
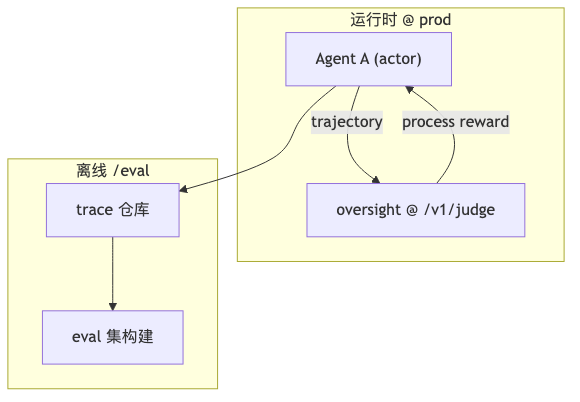
Debugging documentation distinguishes episodic (tool calls and similar history in past traces) from semantic (human feedback–style semantic memory) for continuous improvement analysis. Interview opinion states Percival’s core relies on Weaviate, collections, text2vec vectorization, and per-run nearest-neighbor retrieval; Weaviate is not mentioned in Patronus public Percival docs chapters checked (as of 2026-05). Weaviate multi-tenancy and hybrid search only describe vector-database capabilities; they cannot be reverse-inferred as Percival’s schema.
How to do it (conceptual)#
- Episodic: store span summaries keyed by
trace_id/run_id; retrieve “similar failure repair history.” - Semantic: store stable domain constraints (compliance clauses, API contracts) in a separate collection from episodic data to avoid polluting the baseline with noise.
Common pitfalls#
- Equating podcast partnership with a publicly documented Percival storage implementation.
- Mixing all memory types in one vector store, conflating tool errors with domain facts in retrieval.

Process rewards, outcome rewards, and prompt / weight editing#
Why#
Compound AI systems are often split into multi-step inference, each step eligible for static eval; open autonomous agents lean more on outcome plus environment feedback (host and guest consensus, details vary by system).
Mechanism and constraints#
- Process rewards: stepwise checks inside the trajectory (tool choice, premature
final_answer, etc.). - Outcome rewards: whether the business goal was met (e.g., ticket booked).
Prompts remain the main battlefield where most customers see “change one place, global jitter” (speaker opinion). Model editing sits near sparse autoencoders and mechanistic interpretability; the guest said SAE work on guardrail / eval models (e.g., Lynx) is nearly blank—unverified that “no one in industry has done it.”
Next-generation eval data will increasingly be pulled by agents from tools/RAG/internal docs into domain samples, plus adversarial dataset generation for stress testing (speaker opinion); no public Patronus reproduction pipeline.
Common pitfalls#
- Optimizing outcome only while ignoring in-process logical errors such as “ending too early” (see Percival demo).
- Expecting Percival to replace entire prompt sections automatically; v1 deliberately offers suggestions only (speaker opinion).
Unresolved disagreements (deliberately juxtaposed)#
| Topic | Common practice | Guest / product narrative | Evidence limit |
|---|---|---|---|
| Static eval | Regression sets + CI | High-openness agents need dynamic judging | Holds per scenario; “impossible” is interview qualitative only |
| Failure scale | Docs: 20+ | Interview: 60 | Per taxonomy docs; 60 marked speaker opinion |
| Judge “firsts” | Multiple SLM judges | Lynx/Glider first claims | Papers claim specific benchmarks only |
| Weaviate integration | Generic vector DB | Percival memory backend | Memory types in docs; Weaviate implementation is interview opinion |
| Latency vs oversight | Lower is better | Completion rate first | Speaker opinion, no survey cited |
If you are shipping this#
- Layered evaluation: keep static sets + outcomes on deterministic subchains; on open agents, apply process-level taxonomy to production traces plus sampled human review.
- Traces first, then expand benchmarks: use Percival Debugging–class tooling to compress “hours reading traces” into “see failure mode + suggested prompt,” then feed eval cases.
- Judge selection: Lynx/HaluBench protocol for RAG offline regression; Glider-class SLM + explicit rubric for online guardrails; log Accuracy vs Pearson/F1 separately—avoid mixed leaderboards.
- Split memory stores: episodic (trajectory summaries) vs semantic (stable constraints) in separate collections; mark Weaviate configuration pending verification until Patronus publishes schema.
- Human gate: route Suggested Prompt Fix through PR review; do not auto-write unverified suggestions into production prompts.
References and further reading#
- Patronus AI
- Percival — Agentic Supervision product page
- Percival Debugging Overview (official docs)
- Percival Error Taxonomy (official docs)
- Lynx paper (arXiv:2407.08488)
- Lynx open-source repo
- HaluBench dataset
- Glider paper (arXiv:2412.14140)
- Glider model (Hugging Face)
- LMUnit paper (arXiv:2412.13091)
- LMUnit introduction (Contextual AI)
- Scalable Oversight (Bowman et al., 2022)
- Weaviate developer documentation
- Weaviate multi-tenancy
- Weaviate hybrid search
- OpenAI Models documentation (context and GPT-4o mini)


