
Retrieval List Diversification: Geometric Post-Processing, Evaluation Gaps, and RAG Context Budgets#
Vector retrieval brings “relevant” hits into a candidate pool, but relevant does not mean the list is useful. E-commerce must avoid the same SKU flooding the page, academic search must span subfields, and RAG must allocate a limited context window across complementary passages—all pointing at the same class of problem: given existing relevance scores, how do you pick a Top-N subset with enough internal spread? Pyversity wraps greedy diversification algorithms such as MMR, MSD, DPP, Cover, and SSD as a NumPy post-processing layer that sits after any Python retrieval stack. This article organizes mechanisms and boundaries by engineering theme: links are given where literature and repo implementation can be checked; Springer Nature production paths, default-strategy shifts, YouTube+DPP, and similar oral claims are labeled speaker view, with unverified points stated explicitly.
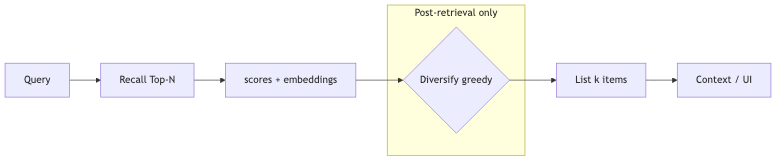
Problem space: where diversification sits in the retrieval pipeline#
Why: A typical RAG / search pipeline is query → dense or hybrid recall → (optional) cross-encoder rerank → list construction → LLM. Upstream stages optimize query–document relevance; diversification optimizes redundancy within the chosen list. Skip this step and Top-10 may be near-duplicate chunks on one theme; multi-hop agents keep reading semantically overlapping passages (speaker view: redundant context wastes tokens and hurts reasoning; distinct from “lost in the middle”–style position bias per Lost in the Middle—no controlled comparison in this episode).
Mechanisms/constraints: Diversification is O(k) greedy steps; each step compares candidates only to the selected subset and the full candidate set—no globally optimal permutation. Inputs are embeddings[N,d] and scores[N] (relevance from vector distance or a cross-encoder); output is a length-k index reordering. Unlike offline k-means clustering: clustering models full-set structure; at online thousand-QPS scale a second pass over the full set is often impractical (speaker view; k-means one pass is typically O(n·k·d), not necessarily O(n²), but the guest uses complexity contrast to stress lightweight post-retrieval processing).
How to proceed (minimal example):
import numpy as np
from pyversity import diversify, Strategy
embeddings = np.random.randn(500, 256).astype(np.float32)
scores = np.random.rand(500) # may differ in source from embeddings
idx = diversify(
embeddings, scores, k=10,
strategy=Strategy.DPP,
diversity=0.5, # [0,1]; higher favors diversity; internally λ = 1 - diversity
)
Common pitfalls: Treating diversification as “swap the embedding model.” The mainstream pattern is strongest relevance embeddings first, then cheap diversify (speaker view); whether training objectives can bake in “naturally spread neighbors” remains an open question (guest). Another pitfall is conflating diversification with query-time clustering / semantic group-by: both feel like “group similar documents,” but clustering usually discovers full-set structure while diversification reorders a list that already has scores; the guest draws the line on latency and incremental updates over the selected subset only, not denying conceptual overlap (speaker view).
MMR and MSD: marginal distance vs global spread#
Why: Maximal Marginal Relevance (Carbonell & Goldstein, SIGIR 1998) is the industrial baseline: each step picks the candidate maximizing “relevance − max similarity to already selected.” The original paper uses λ (relevance weight); the Pyversity API uses diversity ∈ [0,1] with λ = 1 − diversity internally—do not mix symbols when writing runbooks.
Mechanisms/constraints: MMR penalizes via max similarity, pushing away from the nearest selected item; Max-Sum Diversification (MSD) sums distance to all selected items, so lists tend to spread more evenly. README lists both as O(k·n·d); on synthetic benchmarks at 10k candidates and k=10, MMR/MSD/DPP are all ~15ms (benchmarks/README—hardware not fixed, not a production SLA).
How to proceed: strategy=Strategy.MMR or Strategy.MSD, sweep diversity from 0.3–0.5; Weaviate Query Agent Search mode has built-in MMR reranking via diversity_weight (0–1).
Common pitfalls: (1) Confusing MMR with MRR (Mean Reciprocal Rank). (2) At recording the guest said “package defaults to MMR, prescription tries DPP first”—current main default is already Strategy.DPP (checked 2026-05); production docs should follow the repo version. (3) Setting diversity=0 as “turn off diversification” while expecting order identical to pure score sort—implementation still runs the greedy framework; confirm with controlled experiments.
DPP: volume maximization and the default-strategy debate#
Why: Determinantal Point Process in embedding space maximizes the “volume” of the selected set (kernel determinant / greedy residual variance), constrained by vector length and angles—more geometric than a single cosine-distance penalty. Chen et al. give fast greedy MAP; the abstract reports online A/B in recommendation—supporting “diversification validated by product experiments” as methodology, not proof that “YouTube homepage” uses DPP (guest oral Google YouTube case; no paper title this episode, unverified).
Mechanisms/constraints: Pyversity complexity O(k·n·d + n·k²); constant factor often beats MMR/MSD when n is large. Author README marks DPP as Recommended default; synthetic benchmarks usually show DPP ahead of MMR/MSD on ILAD/ILMD (definitions below).
How to proceed: With no prior, strategy=Strategy.DPP, tune from diversity=0.4; A/B against MMR on business CTR / satisfaction, not offline nDCG alone. Runtime is NumPy-only, embeddable in existing Python rerank services (verified in repo pyproject.toml).
Common pitfalls: Assuming DPP is “an order of magnitude slower than MMR”—same greedy order, difference mainly in the n·k² term; at n≈hundreds with cloud vector DB RTT dominant, guest and host lean toward +1ms diversification mattering less than network and first-stage recall (speaker view).
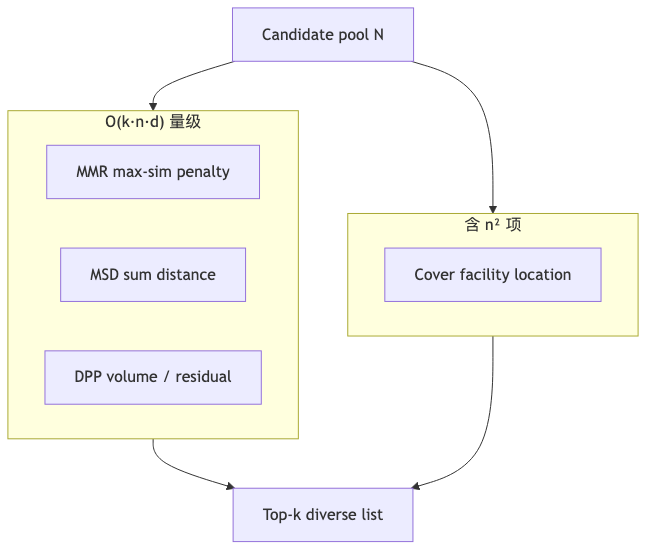
Cover and SSD: slow-path coverage and session sequences#
Why: Scientific literature search needs subfield coverage (CV / NLP / classical ML, etc.), not just deduplicating titles (speaker view). Coverage-based diversity (RecSys 2016) and Pyversity Cover (facility location) align with k-medoids intuition on “represent the full set,” but the implementation name is coverage greedy, not literal k-medoids.
Mechanisms/constraints: Cover precomputes pairwise similarity, complexity O(k·n²); README suggests GPU or another language rewrite around n≈10k+. Guest says optimizing Cover is worth it only at ~10k-result scale; everyday search fast path uses DPP/MMR/MSD (speaker view).
SSD: Sliding Spectrum Decomposition is sequence-aware greedy (sliding-window Gram–Schmidt), suited to feeds or session RAG with recent_embeddings; benchmarks list it as niche—mechanism not expanded orally this episode.
How to proceed: Literature exploration, catalog curation → strategy=Strategy.COVER on a shrunk pool; session scenarios → Strategy.SSD with recent-read vectors.
Common pitfalls: Running Cover on a million-document live recall full set—truncate to a rerank window (e.g. Top-200) first.
Evaluation: BEIR, ILAD, and FreshStack measure different things#
Why: If selection only sweeps MTEB / BEIR nDCG@k and Recall@k, you measure relevance ranking, not within-list spread. Running the same metrics on diversified lists in BEIR-style tasks often hardly moves the needle—because the objective shifted from “single-point relevance” to “list structure” (speaker view; Pyversity’s own CF benchmark can show DPP +nDCG under specific synthetic settings—not generalizable to all BEIR).
Mechanisms/constraints:
| Metric | Source | Meaning | Boundary |
|---|---|---|---|
| ILAD | Pyversity metrics.py | List pairwise mean (1 − cos sim) | Standard name in benchmark suite; not verified against every broader IR paper |
| ILMD | Same | List minimum (1 − cos sim) | Same |
| coverage / α-nDCG | FreshStack | Nugget coverage, weighted nDCG | Needs topic/nugget labels; not ILAD |
| nDCG@k | BEIR/MTEB | Relevance | Does not score diversity |
FreshStack targets technical-doc RAG: community Q&A → nugget extraction → score whether retrieval covers answer blocks; not the same framework as MTEB’s FreshStackRetrieval code-retrieval task (verification report noted).
How to proceed: Offline ILAD/ILMD for algorithm comparison and diversity sweeps; add FreshStack coverage when nugget labels exist; production validation via A/B (with/without diversify) on CTR or satisfaction (speaker view; Chen et al. 2017 abstract supports A/B methodology; Springer pipeline has not A/B-tested diversification; unified benchmark suite not published).
Common pitfalls: Proving diversification useless because BEIR scores do not rise; or writing FreshStack coverage as ILAD. Guest: “pretty recall / nDCG / ILAD curves” remain proxies—reliable validation is online A/B (speaker view)—consistent with diversification literature in recommender systems, but offline metrics still screen algorithm families and hyperparameters; online validates business hypotheses. Also: BEIR qrels can include multiple relevant docs per query—more accurate framing is “main leaderboards do not measure within-list spread,” not “one relevant doc per query only.”
RAG, agents, and “geometry vs LLM” diversification#
Why: RAG and multi-hop agents have finite context; Pyversity README states the motivation as Avoid feeding the model near-duplicate passages. First-hop retrieval with broad coverage and low duplication leaves room for information gain on later hops (host scenario + guest agrees on use-case direction).
Mechanisms/constraints: Diversification remains post-processing on retrieval lists, not the agent workflow itself. Weaviate Query Agent offers Ask and Search; podcast think mode did not appear in public docs checked 2026-05 (oral or legacy name). Search diversity_weight is built-in MMR.
Using an LLM to pick a “diverse document set” lacks geometric guarantees and costs latency (speaker view), analogous to “LLM rerank works, but a dedicated cross-encoder is often enough.” Embeddings and scores may come from different models—scores must reflect query–doc relevance accurately (speaker view); multi-vector (ColBERT / MaxSim) can be projected to single-vector then fed to algorithms; guest found no literature on diversification specialized for multi-vector (boundary unverified).
How to proceed: Recall Top-50 → cross-encoder scores → Pyversity DPP Top-10 → prompt; or Query Agent built-in MMR—avoid double diversify.
Common pitfalls: Stacking similar chunks every agent hop “for recall”; or treating Voyage-3-large (relevance-leaning) vs Arctic 2.0 (diversity-leaning) as a stable rule—guest saw no stable pattern (speaker view). Without diversification, random perturbation sometimes satisfies exploration but is high-variance and non-reproducible; diversification is a more controlled substitute (speaker view). In e-commerce, “diverse” often means dedupe same SKU while colors may coexist; scientific search leans toward serendipitous discovery (host citing Pierce)—one parameter set rarely optimizes both; pick strategy family by product semantics.
If you are shipping this#
- Default path: First-stage recall with strongest relevance embeddings + reranker; run DPP on Top-200 (
diversitygrid 0.35–0.55)—do not skip tuning and default to MMR habit. - Parameters and symbols: Use Pyversity
diversityconsistently (higher = more diverse); do not invert direction vs original MMR λ. - Evaluation layers: Offline ILAD/ILMD to screen algorithms; add FreshStack coverage when nuggets exist; go live with A/B on business metrics; BEIR nDCG only as relevance sanity check.
- Scenario routing: Product dedupe → MMR/MSD often enough; literature / exploratory search → shrink pool then Cover; session feeds → evaluate SSD.
- Performance budget: At n≤1e4, d≤768, pure NumPy Pyversity is usually not the bottleneck; optimize network and first-stage retrieval before Rust/GPU (speaker view).
References and further reading#
- MMR original paper — SIGIR 1998
- Max-Sum Diversification — arXiv:1203.6397
- DPP machine learning tutorial — arXiv:1207.6083
- Fast greedy DPP MAP and online experiments — arXiv:1709.05135
- Coverage-based recommender diversification — RecSys 2016
- SSD sliding spectrum decomposition — arXiv:2107.05204
- Pyversity repository and API
- Pyversity PyPI package
- Pyversity synthetic latency notes
- FreshStack paper — arXiv:2504.13128
- FreshStack code and evaluation
- BEIR benchmark and metrics
- MTEB leaderboard
- Weaviate Query Agent documentation
- Query Agent Search and diversity_weight
- Lost in the Middle — long-context position bias


