
When Queries Become Whole Blocks of Code: The Split Between RAG Evaluation and Search-Style Benchmarks#
Production RAG pipelines are no longer “the user types five words and the system returns ten blue links.” Developers feed retrievers stack traces, LangChain config snippets, and multi-repo context; Agents query the index repeatedly during generation. Meanwhile, teams still pick models from nDCG@10 on BEIR or MTEB rankings—leaderboards that mostly assume short queries, second-scale latency, and ranked-list quality. BEIR co-author Nandan Thakur argues in public discussion that search-style IR evaluation and RAG evaluation focused on long context and fact-level coverage are splitting; the two should not be collapsed into a single number. (Sections marked Speaker view reflect his interview remarks; points cross-checked against papers are labeled separately.)

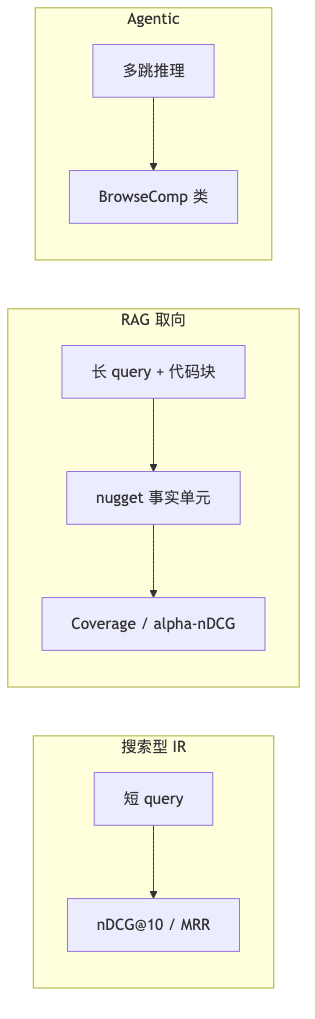
Problem space: three evaluation axes that do not substitute for one another#
| Axis | Typical representatives | What it measures | Easy misread |
|---|---|---|---|
| Heterogeneous zero-shot retrieval | BEIR, MIRACL | Short query → document ranking | High score ≠ usable for long code Q&A |
| Developer-domain RAG retrieval | FreshStack | Nugget coverage on SO long questions + GitHub corpus | A retrieval test collection, not an end-to-end generation leaderboard |
| Agentic / multi-hop | BrowseComp, BRIGHT | Reasoning chains + repeated retrieval | Latency budget not comparable to BEIR |
Speaker view: RAG benchmarks in the Wikipedia / HotpotQA mold—“short question + world knowledge the model may already know”—let models answer without retrieval; evaluation should instead stress niche domains, fresh documents, and tasks that need long summaries (he cites multi-factor relationship questions from TREC RAG as an example). That is an evaluation philosophy, not a BEIR paper conclusion.
If you run a vector store or RAG gateway, a common failure mode is: online query distribution has shifted to “paste half a page of logs,” while offline regression still runs MS MARCO–style short queries—extrapolation error often shows up as recall looks fine but nugget coverage is insufficient, not as nDCG jitter in the fourth decimal place.
BEIR: why IR and NLP need one zero-shot leaderboard#
Why#
The BEIR paper argues that neural IR was compared too often under homogeneous, narrow settings (e.g., train on MS MARCO and evaluate on the same distribution), making it hard to tell whether models transfer to out-of-distribution tasks such as law, biomedicine, or controversy detection. BEIR aggregates 18 public collections across 9 retrieval task types and reports zero-shot nDCG@10 uniformly (ndcg_cut_10 in pytrec_eval).
Mechanisms and constraints#
- DPR is described in the paper as one of few dense baselines not trained on MS MARCO; its zero-shot generalization across 18 sets is generally weaker than models trained on MS MARCO—showing that “high score on train/test from the same source” can diverge from “cross-domain leaderboard” performance (literature).
- Main tables center on nDCG@10; the beir framework also supports MRR and Recall@k, but the paper’s primary results are not unified around MRR.
- Speaker view: @10 was chosen to mimic the top of a search results page; the paper only says users want relevant results near the top—no explicit Google/SERP wording. Treat that as an engineering analogy, not BEIR’s own wording.
How to (minimal example)#
# Concept: evaluate a retriever’s nDCG@10 on multiple BEIR datasets
from beir import util
from beir.datasets.data_loader import GenericDataLoader
from beir.retrieval.evaluation import EvaluateRetrieval
dataset = "nfcorpus"
url = f"https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/{dataset}.zip"
data_path = util.download_and_unzip(url, "datasets")
corpus, queries, qrels = GenericDataLoader(data_path).load(split="test")
# After retriever.search(...):
# ndcg, _map, recall, precision = EvaluateRetrieval.evaluate(qrels, results, [10])
Common pitfalls#
- Picking a long-query RAG product from the BEIR leaderboard alone—query length, label granularity, and latency assumptions all differ.
- Mixing MRR with the paper’s main nDCG@10 as one “BEIR score.”

FreshStack: long queries, nuggets, and “deliberate cheating” in test collections#
Why#
FreshStack targets developer RAG: queries from Stack Overflow (October 2024 dump, keeping accepted answers), filtered to niche tech topics from 2023 onward to reduce LLM training contamination; corpus is chunked public GitHub repos under matching tags (literature / HF dataset card). Speaker view: insist on real community questions; criticize some RAG benchmarks for over-relying on synthetic queries.
Mechanisms and constraints#
- Chunking: the paper sets corpus maximum 2048 tokens (literature). The interview cites embedding context limits at the time as the reason for the tradeoff—the paper does not state that causality; do not treat it as the official explanation. Larger chunks concentrate facts in one document, but cross-file dependencies (e.g., monorepo multi-package references) depend more on multiple retrieval hits than one large hit.
- Retrieval metrics: beyond ranking quality, Coverage@20 directly asks whether the top 20 documents can support all nuggets—closer to “enough context before generation” than “is there a relevant doc at rank 11” (literature definition; still not the same as downstream hallucination rate).
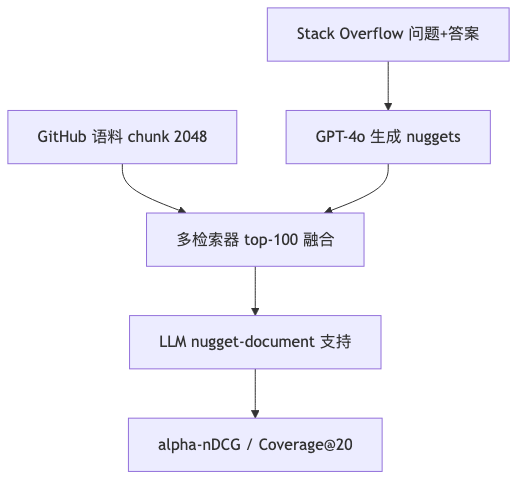
- Nugget: core concept or atomic fact essential in a response; lineage traces to TREC QA information nuggets (paper cites Voorhees 2003, Lin 2005/2006, etc.). FreshStack generates nuggets from Q&A with GPT-4o, with researcher validation of precision/coverage on a subset (literature).
- Labeling: unit is nugget–document support (binary), not “partial relevance” between a long query and a whole document. Pooling uses multiple inference paths (sub-question decomposition, HyDE-style closed-book answers, etc.) and oracle paths (full answer text, nugget concatenation); each model top 100, scores normalized and summed, then top 20 on the fused list for LLM support judgments (literature; differs from interview’s top-50 figure—paper wins).
- Speaker view: mixing BM25, dense vectors, and ColBERT-style retrievers when building a test collection is a kind of “cheating” in that context—aimed at reducing holes (documents that should be labeled but never enter the pool). Literature check: FreshStack pooling uses BM25, BGE, E5 Mistral 7B, Voyage-large-2 with score fusion; ColBERT is not used. MIRACL annotation uses BM25 + mDPR + mColBERT (top-10 judgment), with fusion as normalized average, not RRF either.
Retrieval-side metrics include α-nDCG@10, Recall@50, Coverage@20 (share of nuggets covered by top 20 documents), etc. (literature)—not directly comparable to BEIR’s main leaderboard.
How to (minimal example)#
Load queries and nugget labels from Hugging Face (accept FreshStack license terms):
from datasets import load_dataset
queries = load_dataset("freshstack/queries-oct-2024", split="train")
# Fields include nuggets, nugget-level relevant_corpus_ids, etc.; see dataset card
For a private corpus, reuse the pattern: decompose / multi-path queries → fuse to expand pool → nugget-level support judgment—but whether production should use the same multi-path fusion needs separate latency and cost analysis (speaker view).
Common pitfalls#
- Treating FreshStack scores as end-to-end RAG answer quality—it mainly evaluates a retrieval test collection.
- Assuming interview RRF is FreshStack’s default—paper uses normalized score sum; RRF is SIGIR 2009 and differs from MIRACL/FreshStack pool construction.
- “More recall is always better”—speaker view proposes a minimal spanning subset: if a few documents already cover all nuggets and citations, that beats stuffing 20 docs into context; not a standardized competition metric.


Query rewriting: SPLADE, decomposition, and tension with the “ideal embedding”#
Why#
Classic IR query expansion often helps BM25, ColBERT, and SPLADE. Speaker view: ideally, end-to-end embeddings should need no explicit rewriting; in practice, as user queries grow longer and more complex, query decomposition (FreshStack sub-questions, BRIGHT code/math) is still necessary for now—coexists with the “ideal,” not a forced either/or.
Mechanisms and constraints#
- SPLADE (SParse Lexical And Expansion): learns sparse activations over the vocabulary for implicit expansion, easing vocabulary mismatch (literature); can partly replace hand-added terms but does not remove every LLM rewrite step.
- FLARE (arXiv:2305.06983): on low-confidence tokens during generation, triggers forward-looking re-retrieval—an active RAG family (literature; speaker view links it to multi-hop evaluation motivation).
How to#
For short web queries: A/B no rewrite vs SPLADE/dense hybrid; for long developer questions: try nugget-level sub-queries on labels or eval sets, then compare to HyDE-style oracle paths per FreshStack’s inference/oracle split.
Common pitfalls#
- Equating a single-vector MTEB/BEIR #1 with “long queries need no decomposition.”
- Copying test-collection four-model fusion into production—speaker view admits offline pooling is strong while online multi-hybrid efficiency is poor.
Agentic retrieval and renegotiating the latency budget#
Why#
BRIGHT stresses longer, reasoning-heavy queries; BrowseComp–style tasks need agentic browsing and multi-hop retrieval. Speaker view: such tasks require agentic retrieval; one-shot search is not enough—contrasts with BEIR short web queries where “decomposition helps but is not mandatory.”
Mechanisms and constraints#
- Latency: PhD-era emphasis on retrieval latency; now ChatGPT/reasoning-model users will wait minutes for answer quality (speaker view, behavioral assumption, no unified experiment ID).
- Patent search, etc.: 30 minutes–1 hour offline with multi-stage rerankers (monoT5/duoT5 and other Waterloo-line work) is acceptable—same family as BrowseComp “agent browses 20 minutes”: correctness first, latency-insensitive (speaker view).
- FLARE and Search-R1 fold when and what to retrieve into training or loops—different axis from static top-k retrieval eval (Search-R1 details not independently verified in this article).
How to#
For agent products, build multi-hop success / tool-call trace evals separately and report beside nDCG@10; when citing TREC RAG Track nugget-level A_strict and similar metrics, align to that year’s task definition, not prior years’ wording.
Common pitfalls#
- One “retrieval accuracy” number for both BrowseComp and BEIR.
- Ignoring streaming-shifted “acceptable wait” and still designing multi-hop agents to a 200 ms SLA (speaker view).

Domain-specific embeddings vs general models: no standard answer yet#
Speaker view: admits “we don’t know the standard answer”; small models struggle to compress multi-domain knowledge, but as decoder/LLM backbones grow, general cross-domain training may get easier; knowledge cutoff can still be patched with RAG on new documents—you must measure on your domain, not copy leaderboard #1.
Synthetic/simulated-domain benchmarks like AIR-Bench help when human labels are scarce (speaker view); FreshStack’s “real SO” route is a different tradeoff, not a single winner-takes-all verdict.
Not developed in this episode’s subtitles: the host asked about FreshStack hard negative labeling; the guest pivoted to mixture of retrievers—do not treat this episode as a hard-negative training guide.
Structured retrieval and pagination: an evaluation gap#
Real-estate-app needs like “city + 500 listings + paginated aggregation” involve text-to-SQL, filters, and MapReduce-style parallel reasoning—not classic BEIR text relevance. Speaker view: personal research focus is plain-text retrieval and embeddings; pagination matters but no alternative to nDCG@10 for paginated eval was offered—engineering teams should define faceted retrieval + aggregation correctness metrics; do not expect BEIR extensions to cover this.


If you are shipping this#
- Build separate leaderboards per axis: keep BEIR/MTEB-style retrieval for short queries; if the product is long-context + code blocks, add FreshStack-like or custom nugget eval—do not select on one nDCG@10 alone.
- When reproducing FreshStack labels: follow paper top-100 fusion, top-20 support judgment; document whether fusion is score sum or RRF—do not conflate them.
- Report agents vs search separately: BrowseComp/BRIGHT beside BEIR; state latency SLA on its own.
- Thick pool offline, thin path online: multi-retriever fusion to expand pools works in offline labeling (speaker view + literature); production needs its own QPS/cost math.
- A/B controversial domains first: domain-specific embeddings (e.g., Voyage domain models) vs large general embeddings on your query distribution, not public leaderboard rank alone.
References and further reading#
- BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models
- BEIR evaluation code repository beir-cellar/beir
- FreshStack: Building Realistic Benchmarks for RAG on Developer Documentation
- FreshStack queries (Hugging Face)
- FreshStack corpus (Hugging Face)
- MIRACL: A Multilingual Retrieval Dataset
- MIRACL project homepage
- SPLADE v2: Sparse Lexical and Expansion Model
- Reciprocal Rank Fusion (SIGIR 2009)
- FLARE: Active Retrieval Augmented Generation
- BRIGHT: A Realistic Benchmark for Retrieval-Augmented Generation
- TREC RAG Track website
- MTEB Leaderboard
- Sentence-Transformers training and evaluation overview
- Original RAG paper (Lewis et al.)
- AIR-Bench: AI Retrieval Benchmark


