
REFRAG: Turning RAG Context from a Token String into a Compressible Representation#
The usual production RAG path is: retrieve several passages → stitch them into the prompt → let the decoder run full-length self-attention prefill. The bottleneck is often decoder compute and TTFT, not retrieval itself. Vector databases and rerankers optimize what to find; once top-(k) text enters the LLM, prefill still bills by token length.
REFRAG (Representation For RAG, Meta Superintelligence Labs, first author Xiaoqiang Lin) proposes compress → sense → expand: shorten the decoder sequence with chunk-level representations, then use RL to selectively expand high-information-entropy spans. The abstract reports 3.75× and 16× effective context extension versus prior work, and up to about 30.85× TTFT in specific settings—these figures depend strongly on the baseline model (e.g., CEPE), compression rate (k), whether pre-computed cache is used, and sequence length; do not generalize them outside the Figure 2 / Table 2 context.
The sections below follow mechanisms, training, and evaluation boundaries; product judgments from the interview and numbers not stated in the paper are labeled separately. If you already use compression-style long-context schemes such as CEPE, you can view REFRAG as baking compression and on-demand expansion into the training objective under a RAG block-sparse attention assumption, rather than inference pruning alone.
The problem: what RAG prefill is actually computing#
Why: After retrieving top-(k), passages often run to hundreds of tokens each; concatenating several segments makes prefill complexity roughly quadratic in sequence length (standard Transformer attention). Industry more often tracks TTFT (time to first token), not throughput alone.
Mechanism/constraints: On concatenated RAG context, the paper observes block-diagonal attention patterns—attention within a passage is stronger than across passages (appendix visualizes LLaMA-2-7B-Chat). From this they argue that much fine-grained cross-chunk attention can be omitted; this conflicts with the intuition that “RAG must attend over the full text mutually,” but no deployable quantitative threshold is given (speaker view: cross-chunk weights are “small”).
Common pitfall: Treating “compression” as vector-database ANN quantization. REFRAG’s compression rate (k) means every (k) tokens occupy one position in the decoder ((L=s/k)); it is unrelated to embedding bit-width (§2).
Multi-granularity representations: chunk embeddings into the decoder#
Why: If all raw tokens still feed the decoder, prefill length barely changes. REFRAG uses a separate encoder (\mathcal{M}_{\text{enc}}) to encode each chunk (C_i) as (\mathbf{c}_i), projects via (\phi) to (\mathbf{e}^{\text{cnk}}_i=\phi(\mathbf{c}i)), and feeds these with question token embeddings into (\mathcal{M}{\text{dec}}) (§2 Model Architecture).
Mechanism/constraints: The interview analogizes VLMs representing images with few embeddings (speaker view; the paper body does not discuss modality/vision). What can be verified: both pre-computed chunk embeddings and online parallel encoding work; even without full-corpus pre-computation (“REFRAG without cache”), a shorter decoder sequence still speeds things up (Figure 2 reports up to about 16.53× TTFT at (k=16), length 16384—check baseline and whether cache is included).
How to proceed (worked example): (k\in{16,32}) are the paper’s main settings. 16 384 tokens, (k=16) → 1024 chunk positions; (k=32) → 512. The interview’s “16k compressed to about 1k” matches (k=16) arithmetic (verified).
Common pitfall: Assuming “one embedding replaces the whole document.” The interview says early attempts to compress hundreds–thousands of tokens into a single embedding failed completely (interview only); the paper only has performance regression curves as (k) grows (Figure 10), not that exploration narrative.
At (k=32) the paper reports 32.99× TTFT versus LLaMA and 3.75× versus CEPE (§2), while CPT perplexity remains competitive—aligned with the interview direction that “(k=32) can match an uncompressed LM,” but the paper is more cautious: it does not claim lossless equivalence to LLaMA-Full Context on all tasks. Regression is clear for (k>32); in production treat (k) as a latency–quality knob, not “bigger is better.”
Attention roles and block-level prefill#
Why: In compressed mode the decoder sees only (L) chunk positions; token–token attention inside chunks disappears in the compressed segment; chunks chosen for expansion re-enter as (k) raw token embeddings (§9.1 mixed input).
Mechanism/constraints: The encoder encodes (C_i) in the usual way (paper uses RoBERTa; it does not spell out “full self-attention within the block” sentence by sentence, but that matches standard encoder behavior). The decoder does chunk-level mutual attention on compressed spans; expanded spans restore token-level attention. The host’s block-diagonal attention mention matches paper terminology consistently.
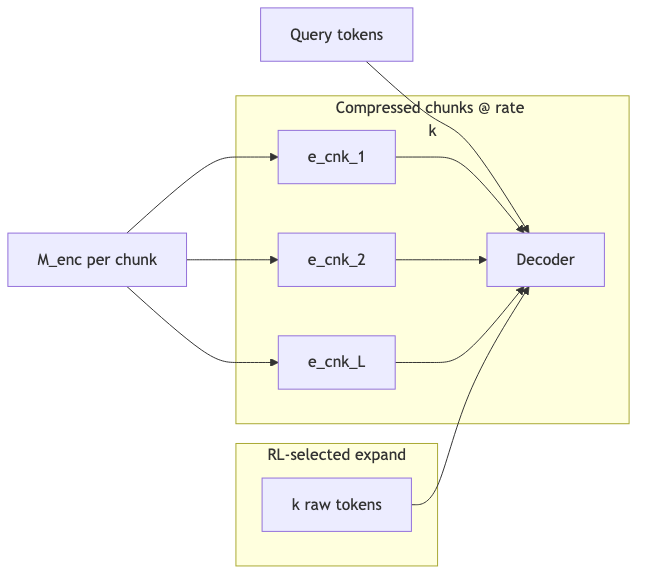
Common pitfall: Assuming that after dropping cross-chunk attention you never need raw tokens. High-entropy facts (numbers, fine-grained fields) often need selective expansion; reconstruction loss alone may barely move perplexity, yet “recite a long number inside the chunk” still fails (§3.1 + speaker view).
RL selective expansion: binary decisions and their limits#
Why: Uniform compression loses high-entropy information inside chunks; you must trade latency against fidelity.
Mechanism/constraints: The policy sequentially picks (T’=pL) indices to expand on chunk embeddings; Pointer Networks masking constrains the action space (paper footnote); optimization uses GRPO, not Vinyals’ original training objective. Reward ties to perplexity in the next segment (§9.1). The interview’s “one forward pass + mask, renormalize softmax, sample (m) without replacement” is spiritually aligned with sequential + no logit recomputation, but should not be read literally as identical (partially verified).
Relation to retrieval diversity: The host asks whether MMR/deduplication weakens “cross-chunk attention can be omitted”; the guest answers RL expansion is unrelated to diversity mechanisms—diversity affects attention between different chunks, because chunks come from different sentences/documents (speaker view; the paper mentions block-diagonal patterns after dedup, does not discuss MMR).
Common pitfall: Treating expansion as continuous granularity control. The current implementation is essentially binary: a chunk is either one (\mathbf{e}^{\text{cnk}}) or expanded to (k) tokens (speaker view); dynamic chunkers / dynamic tokenizers are listed as future work.
Policy network (g_\theta) stacks two Transformer layers on chunk embeddings (§9.1), reusing ({\mathbf{c}_i}) without recomputing logits after each pick—an engineering trade for training throughput. At inference latency, expansion ratio (p) (expanded chunks (T’=pL)) sets prefill length between “pure compression” and “near full tokens”; if TTFT is your SLA, profile (p) and (k) together, not only retrieval top-(k).
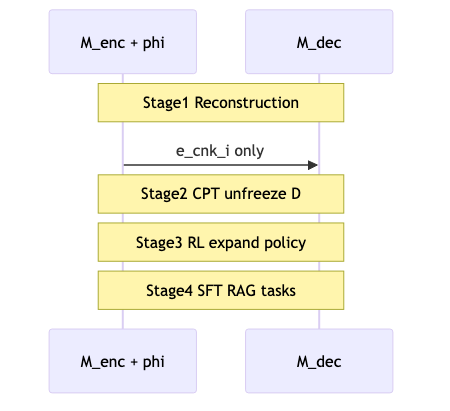
Training: four-stage pipeline and alignment pitfalls#
Why: RAG-style SFT alone may let the decoder ignore chunk embeddings and fall back to parametric memory (emphasized in the interview; the paper uses reconstruction + curriculum to avoid this, §3.1).
Mechanism/constraints (paper maps to four stages, no “four-stage” heading):
- Reconstruction: freeze decoder, train encoder + (\phi); start reconstructing (x_{1:k}) from a single chunk (\mathbf{c}_1).
- CPT (continual pre-training): next paragraph, unfreeze decoder.
- RL selective compression.
- SFT: RAG, multi-turn, etc.
Curriculum inside CPT/reconstruction has its own Stage 1–9 data mix (Table 8), ≠ the interview’s informal “four stages” label.
How to proceed (resources): Main experiments use LLaMA-2-7B decoder; paper default 8 nodes × 8 H100, FSDP, Bfloat16 (§10.2). Interview “single machine 8 GPUs 5–6 days / 8 machines×8 GPUs 1–2 days” (interview only; paper gives no wall-clock). Stack PyTorch + Hugging Face (interview only); facebookresearch/refrag was 404 as of 2026-05, reproduction not verified.
Common pitfall: Skipping reconstruction/curriculum. Appendix ablations show removing either item degrades sharply (verified).
CPT uses a Slimpajama subset of about 20B tokens (§10.2), far larger than RAG SFT’s 1.1M samples. That explains why the interview tells readers to prioritize pre-training and RL sections: Tables 1–2 perplexity reflects whether continual pre-training learned to read compressed context; RAG exact-match tables are application-layer demos on an aligned model. If you only have small domain QA data and cannot afford CPT, expect not to reproduce paper-level TTFT–quality tradeoffs—at best borrow architectural ideas for small experiments.

Evaluation: which tables to read and how to read the numbers#
Why: RAG downstream tasks (QA, summarization) mix in SFT and retriever differences; the interview argues strict conclusions live in CPT perplexity and RL (speaker view); paper §5 still spends space on RAG applications—do not dismiss that side alone.
| Dimension | Verifiable in paper | Interview / unverified |
|---|---|---|
| CPT main metric | Perplexity (Table 1–2) | — |
| RAG | Exact match, 16-task average % gain; implementation stricter (footnote) | Interview “2M” SFT → paper 1.1M |
| Equal latency | REFRAG 8 passages vs LLaMA 1 passage: strong retriever +1.22%, weak +1.93% (§5.1) | “~+2%” is close but retriever must be labeled |
| TTFT | Abstract 30.85×; §2 has 16.53× ((k=16), 16384, cache), etc. | Must state baseline and cache |
| Data ablation | No needle-in-haystack-style ablation | Guest: architecture and long-context data both matter; this work did no data ablation |
Common pitfall: Calling RAG table exact-match average gains pass@k or MRR; treating equal latency as “same token count.”

Vector databases and agents: product tension (mostly inference)#
Vector databases: Common practice heavily quantizes retrieval embeddings and discards them at inference, keeping only raw text. If REFRAG were productized, the interview argues you need full-precision chunk vectors into the decoder, shifting the database center from “store passage text” to “store decodable representations” (speaker view; paper does not argue ANN quantization comparison). Quantized chunk vectors are mentioned only as “optional elsewhere” in engineering around pre-computed on-disk paths.
Agents: The paper mentions multi-turn / agentic settings; the interview groups search agents (many results stuffed into the prompt) with GUI, multimodal, and long tool history as the same class of context management (speaker view). The host speculates “APIs return REFRAG vectors, agents pass vectors to each other”—no experimental support.
TTFT and serving: Quantization, linear attention, and specialized chips (Cerebras/Groq, etc.) may be orthogonal to REFRAG (guest judgment); the paper did not combine them experimentally.
Long-context data vs architecture: The host cites lost in the middle / context rot—can architecture alone fix it, or do you need needle-in-haystack-style long-context training? Guest: both, but REFRAG did no data ablation (speaker view; paper likewise). If your base model never ran long-context CPT, whether block-diagonal assumptions hold on out-of-domain data needs your own validation—do not extrapolate from the paper’s LLaMA-2-7B setup.
Structured extraction: The host asks whether expanding chunks that contain date published by field would replace traditional LLM structured extraction. Guest says it might affect database/RAG service shapes but is not a database expert (speaker view). This is not automatically equivalent to schema-first stores like Weaviate; the safer path treats REFRAG expansion as inference-time attention budget allocation, not a replacement for ETL/extraction pipelines.
If you are shipping this#
- Align evaluation definitions first: separate CPT perplexity (Table 1–2) from RAG exact match (§5.1); when reproducing equal-latency, fix passage count, retriever strength, and cache use.
- Start a latency–quality curve at (k=16) or (32): do not assume arbitrary (k) or “one embedding replaces a span”; the paper shows (k=32) still competitive, larger (k) regresses.
- Budget reconstruction + curriculum on the training side: do not expect pure RAG SFT to make the decoder trust chunk representations.
- Design storage and serving separately: retrieval ANN quantization ≠ REFRAG’s (k); on a pre-compute path, evaluate storage and load cost of full-precision (\mathbf{e}^{\text{cnk}}).
- Treat the paper as source of truth before open source: while the code repo is unavailable, implement against HTML §2–§3 and appendix §9.1; interview numbers (2M data, training days, VLM analogy) are clues only.
References and further reading#
- REFRAG abstract (arXiv:2509.01092)
- REFRAG HTML full text — architecture §2
- REFRAG — training recipe §3.1
- REFRAG — RAG experiments §5.1
- REFRAG — RL selective expansion §9.1
- REFRAG — compute and hyperparameters §10.2
- REFRAG PDF print version
- Retrieval-Augmented Generation (Lewis et al., 2020)
- Pointer Networks (Vinyals et al., 2015)
- Lost in the Middle (Liu et al., 2023) — long-context position bias, relevant to block-diagonal discussion
- Needle In A Haystack — long-context evaluation paradigm — contrast reading when the paper lacks similar data ablations
- CEPE — compression-style long-context baseline (paper bib)
- GRPO — REFRAG RL optimization citation (Shao et al., 2024) — see paper reference list
- Hugging Face Transformers — interview cites as implementation base; not stated in paper body
- facebookresearch/refrag — paper-declared repo — 404 on verification date; recheck before shipping
- Weaviate vector database docs — contrast for “store passage vs store chunk representation” product discussion (not REFRAG official spec)


