
Enterprise RAG and Agents: When Vector Databases Meet Four Decades of Analytics Software#
Builders in regulated industries often face the same tensions: most data is unstructured, models move faster than compliance approvals, and POC density far exceeds operable production. In a technical conversation, SAS’s Saurabh Mishra and Weaviate co-founder Bob van Luijt unpack these tensions from the sides of enterprise analytics software and an open-source vector database. What follows is reorganized by engineering theme, not chronological recap. Verifiable claims are tied to primary sources such as the RAG paper, SAS Retrieval Agent Manager (RAM), and Weaviate documentation; everything else is labeled speaker opinion.
Problem space: three parallel curves#
Enterprise AI rarely stalls on “can we call an LLM?” It stalls on whether three curves align:
- Data curve: Documents, manuals, tickets, and scans keep changing. A SAS blog states that >80% of enterprise data is unstructured—that figure is a SAS secondary claim and is not backed by a reproducible survey link in the post; treat it as directional, not audit-grade.
- Model curve: BYO LLM, embedding models, quantization, and ONNX acceleration (mentioned on the RAM Features List) expand inference choices, but knowledge cutoffs and compliance boundaries do not auto-resolve with each API version.
- Organization curve: B2C products (e.g., ChatGPT) at weekly-active scale raise executive anxiety about “AI strategy / agent counts” (speaker opinion), while an engineering view that “enterprise RAG is still early” coexists—those narratives need not converge to one conclusion.
Capability evolution: retrieval, RAG, and agents#
Why#
On the same team, “RAG” may mean retrieval-augmented generation as a pattern, or the full data pipeline including chunking, embedding, and indexing (SAS emphasizes the latter more heavily, speaker opinion). Without aligning semantics first, scheduling and acceptance criteria drift apart.
Mechanisms and constraints#
Bob frames enterprise capability as three stages: retrieval → RAG → agents (speaker opinion). Academically, Lewis et al., 2020 combine parametric memory (pretrained seq2seq) with non-parametric memory (dense vector index)—the index can update without retraining all generation parameters; that is what “decoupling” means at the architecture layer. The paper still fine-tunes the joint components; that does not mean zero coordination in production forever.
Saurabh adds a time-scale note: industry “historical” narratives often look back only one year; serious RAG investment started roughly in the first half of 2024, and data preparation before the “R” has long been underestimated (speaker opinion).
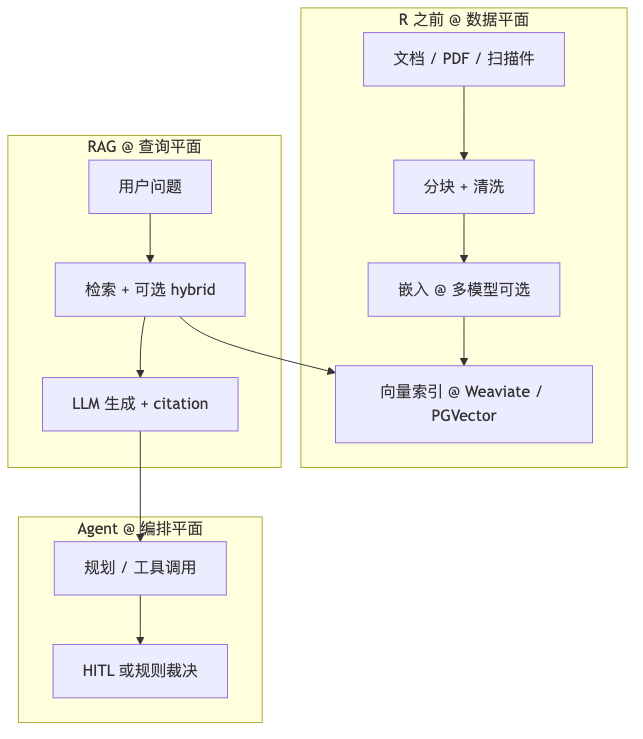
How to implement (minimal example)#
Conceptually, accept three SLAs separately: index freshness (hours/days), retrieval recall@K, generation groundedness—do not substitute a single “chat thumbs-up rate.”
ingest_job → chunk_store + vector_index
query → retrieve(k=8, filter=tenant_acl) → prompt → answer + citations
Common pitfalls#
- Equating “we deployed a vector database” with “we finished RAG.”
- Using agent orchestration to mask poor chunking (garbage in, agent out).

Before the “R”: the embedding pipeline is the hidden main battlefield#
Why#
The SAS RAM product page targets unstructured enterprise data (including PDFs and scans). If ingest quality is poor, stronger generation models only amplify noise.
Mechanisms and constraints#
Saurabh says SAS validated document→embedding flows on an existing complex AI pipeline engine, connectable to SAS-trained or external models (speaker opinion; engine SKU not named on the public RAM page—await an architecture white paper). The interview claims a no-code UI can complete document→embedding in minutes (speaker opinion, no public benchmark).
Manufacturing narrative (case study / speaker opinion): telemetry ML alerts → documentation/RAG generates actionable repair plans. A SAS predictive maintenance blog argues for RAG orchestration atop ML detection and doesn’t replace your existing ML systems—consistent with a “prediction + retrieval + generation” stack, but without named customers or quantitative metrics.
How to implement (minimal example)#
Retain doc_id, chunk_id, and embedding_model_id per document version for traceability and re-embedding:
{
"doc_id": "manual-v3",
"chunk_id": "manual-v3#p12",
"embedding_model": "text-embedding-3-large",
"vector_ref": "weaviate://Class/uuid"
}
Common pitfalls#
- Tuning prompts only, without versioning chunks and embedding models.
- Ignoring systematic OCR errors on scans in vector space.

Fine-tuning and RAG: stack them, don’t pick one#
Why#
“We already fine-tuned, so we skip the knowledge base” often fails when data keeps changing.
Mechanisms and constraints#
Saurabh: a fine-tuned model is still a point-in-time snapshot; unless update cadence tracks business data, it goes stale; RAG injects fresh facts (speaker opinion). That aligns with the RAG paper using explicit non-parametric memory to ease updating world knowledge, while enterprises may also add domain fine-tuning—modular composition, not mutual exclusion.
How to implement#
domain_finetuned_llm + fresh_index(query) → grounded_answer
Before launch, compare three arms on a fixed eval set: fine-tune only, RAG only, fine-tune + RAG.
Common pitfalls#
- Treating fine-tuning as “train once, correct forever.”
- Using fine-tuning instead of an auditable citation chain in regulated settings.
Framework POCs vs. enterprise software: two speed curves#
Why#
Enterprise builders often prototype quickly with LangChain; the interview claims framework version drift makes POC→production hard (speaker opinion). Bob adds that enterprises always have people who “stop you from doing things” and people who “build new things”—below focuses on builders, not that governance is redundant (speaker opinion).
Mechanisms and constraints#
Saurabh summarizes: frameworks are “good at tinkering, not necessarily production-level software” (speaker opinion). Verifiable fact: the LangChain repo exists and is active; claims about POC→production difficulty lack third-party benchmarks.
RAM contrast: built-in automated / user-driven evaluations, plugin-style integrations (Features List)—product promises, not an objective LangChain ranking.
How to implement#
During POC, record: dependency version locks, retrieval metrics, compliance checklists. For production migration, prioritize operable boundaries (index service, eval pipeline, permission middleware) over line-by-line notebook porting.
Common pitfalls#
- Treating demo latency as production SLA.
- Ignoring the gap between “success stories you can count on one hand” and conference density (speaker opinion).

Permissions, compliance, and agents: RBAC did not change paradigms#
Why#
AI does not make “data is hard” easier: governance and privacy rigor are not relaxed (speaker opinion). Regulated industries still question sending data to OpenAI/Anthropic prompts (speaker opinion).
Mechanisms and constraints#
Bob discusses Weaviate Query Agent: for agents, traditional RBAC “basically hasn’t changed” (speaker opinion). Verifiable: Weaviate RBAC defines roles → permissions → resources (collections, tenants, etc.); Query Agent is a Cloud natural-language query service. Docs do not state “agents don’t change the security paradigm”—keep that as interview judgment, compatible with RBAC mechanics but not official wording.
Saurabh agrees: data and security overlays remain old problems; AI is a new entry point.
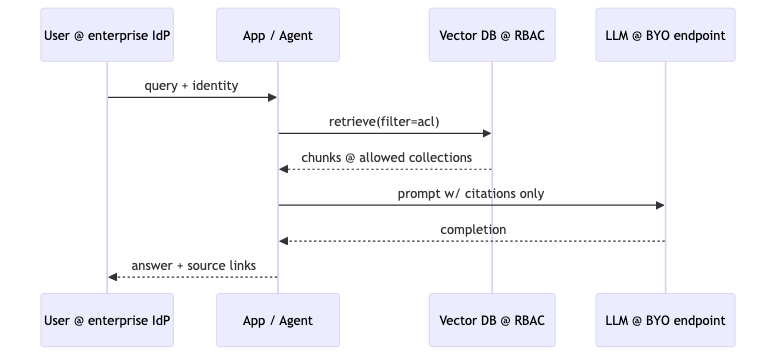
How to implement#
Hard-filter collection / tenant before retrieval; route LLM calls through enterprise-approved endpoints; separate prompt content from audit metadata retention in logs.
Common pitfalls#
- Assuming “autonomous agent” bypasses content ACL.
- Application-layer filters only on multi-tenant vector stores without syncing permission-revocation events.


Accuracy contracts: chat, eval, and citation#
Why#
In RAG settings, you trade accuracy for business value—you cannot demand 100% accuracy (Bob, speaker opinion). LLMs introduce non-determinism that cannot be fully eliminated inside workflows (Saurabh, speaker opinion).
Mechanisms and constraints#
Mitigation paths (product layer, partly verifiable):
| Approach | Documentation support | Interview supplement |
|---|---|---|
| Automated / user-driven eval | Features List: optimal configuration | Champion–challenger multi-path embedding pipelines (term not on official site) |
| Citation | Auto-generates citations linking answers to source documents | Click citation to scroll to PDF paragraph (UI detail not verified in docs) |
| HITL | human-in-the-loop oversight | Mission-critical branching (speaker opinion) |
Marketing copy Improve content accuracy by up to 40% gives no baseline, dataset, or metric—cannot align with academic MRR, pass@k, etc.
How to implement#
offline: golden_qa → score(retrieval, answer, citation_match)
online: thumbs + sample human audit → champion config promotion
Common pitfalls#
- Replacing “feels right in chat” with whether citations cover key sentences.
- Treating the 40% uplift as a reproducible experimental result.
Agent boundaries: autonomy, human-in-the-loop, and deterministic hybrids#
Why#
Autonomy is seen as a defining agent trait; in mission-critical settings, full autonomy conflicts with acceptable enterprise risk (speaker opinion). Barriers to autonomous agents exceed chat RAG: the former requires the system to decide for people; the latter lets people read before acting (speaker opinion).
Mechanisms and constraints#
Coexisting modes (Saurabh, speaker opinion):
- Human-in-the-loop agent: pause at critical steps for approval.
- Hybrid workflow: rules / traditional ML at decision points; RAG/LLM for paperwork, summaries, and other non-adjudication steps (mortgage-style example).
Bob’s Query Agent represents “natural language → autonomous retrieval”; if you add autonomous orchestration, policy still needs tool allowlists and side-effect ceilings.
How to implement#
Label each agent capability with autonomy_level (read-only / draft / execute-with-approval) and enforce it in the orchestrator.
Common pitfalls#
- Linear assumption: “we have RAG, so we can ship autonomous agents.”
- Single chat UI for high-consequence actions without an approval chain.
RAM and vector stores: first-class integration in an open stack#
Why#
Enterprises need BYO LLM / BYO vector database; if everything is optional, decision cost explodes (speaker opinion). A reasonable pattern is open architecture + first-class integration.
Mechanisms and constraints#
Verifiable (RAM Features List):
- Vector stores: PGVector and Weaviate listed together; plugin-based integrations, no vendor lock-in.
- LLMs: OpenAI, Azure OpenAI, Amazon Bedrock, Ollama, and others.
- Citation, evaluation, ONNX / quantization, and diverse hardware.
Interview-only / pending official confirmation: multiple embedding models, BYO embedding support coming, explicit champion–challenger flows; “RAM is GA”—the product page has Get started today; scraped text does not show GA wording; write “publicly available / purchasable” instead.
Bob: the Weaviate Python client (docs, PyPI weaviate-client, v4 defaults to gRPC) feels more like a library than a classic DB driver (speaker opinion)—a mental-model difference, not an API spec term. SAS stack is Python backend, React frontend, Go inside the company (speaker opinion; RAM implementation languages not confirmed on the official site).
The interview claims RAM can accelerate via architecture choices on no-GPU infrastructure (speaker opinion); the site only mentions hardware diversity and ONNX, not “GPU-free.”
How to implement#
# Concept: RAM orchestration layer + Weaviate as vector backend (pseudocode)
import weaviate
client = weaviate.connect_to_local() # or Cloud; see official quickstart
# ingest / hybrid_search / tenant config per RBAC and schema docs
For selection, run parallel PoCs on the same corpus: compare Weaviate vs. PGVector on hybrid search, multi-tenancy, and ops cost—do not decide on partnership narrative alone (SAS×Weaviate motivation is from the interview; not documented on the official site).
Common pitfalls#
- Reading “first-class” as “exclusive binding”—docs list PGVector alongside Weaviate.
- Ignoring gRPC 50051 and similar network policies (see Python client docs).


Maturity, TCO, and procurement conversations#
Why#
Builders focus on embedding models and frameworks; customer demos lead with deployment cost and TCO (speaker opinion)—misaligned priorities kill POC funding.
Mechanisms and constraints#
Bob analogizes enterprise AI adoption as possibly even earlier than practitioners think—like the internet before Google/Amazon IPOs (speaker opinion, not mapped to penetration data). Saurabh analogizes retail before online displacement: unpredictable disruption, and B2C adoption speed makes organizations unable to absorb “it’s still early” (speaker opinion).
RAM redirects to the product page; FAQ industries include banking, insurance, manufacturing, health care, public sector—consistent with the interview. GA timing and roadmap details follow SAS release notes.
How to implement#
Prepare commercial materials alongside technical ones: index scale → storage and re-embedding cost, query QPS → vector DB nodes, compliance → data residency and LLM routing.
Common pitfalls#
- Demoing “smarter answers” only, not $/1M tokens and re-index cadence.
- Deriving enterprise SLA from consumer ChatGPT experience.


If you are shipping this#
- Pin down what “RAG” means: accept ingest (chunking, embedding version, ACL) and query (recall, citation) separately before setting agent autonomy levels.
- PoC vector stores on the same corpus: compare Weaviate vs. PGVector on hybrid search, tenancy, and ops; treat RAM as a reference integration list, not your SLA substitute.
- Put RBAC before retrieval: align with Weaviate RBAC or equivalent; in regulated settings, review LLM egress data flows separately.
- Build trust with eval + citation: offline golden sets drive config promotion; online citations should reach at least document level—paragraph-level scroll needs product verification.
- Default to HITL or rule adjudication for high-consequence flows: LLMs handle paperwork and summaries; do not hand credit, safety, or similar decision points to end-to-end autonomy (speaker opinion, consistent with RAM HITL marketing direction).
References and further reading#
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (arXiv:2005.11401)
- RAG paper PDF
- SAS Retrieval Agent Manager product page
- RAM Features List (Weaviate / PGVector, eval, citation, LLM integrations)
- Why predictive maintenance needs more than retrieval (manufacturing + RAG narrative)
- Weaviate developer documentation
- Weaviate llms.txt (Query Agent, hybrid search, and other indexes)
- Weaviate concepts: data structure, vectors, and embeddings
- Weaviate Python client (weaviate-client, gRPC)
- Weaviate RBAC overview
- Weaviate Query Agent overview
- LangChain GitHub repository
- SAS Viya platform page (model governance and deployment ecosystem—not a RAM architecture white paper)
- SAS product documentation portal
- ONNX project home (RAM acceleration background)


