
Scaling DataFrames: When Notebook Habits Meet Distributed Execution#
In RAG pipelines, evaluation scripts, and agent toolchains, pandas remains the default “load the table into memory and compute” interface: feature tables, retrieval logs, and labeled results often become a DataFrame first, then feed embedding, reranking, or metric computation. Bottlenecks usually are not “whether you can write SQL,” but single-process GIL, loading whole tables into memory, and parallel semantics of human-readable file formats (CSV). On the Snowflake side, pandas on Snowflake, the open-source Modin project, and Ponder (now part of the Snowflake ecosystem) represent two broad approaches: either compile pandas calls to the warehouse engine, or run a task-parallel DataFrame engine on Ray / Dask.
The sections below align technical claims from public conversations with Modin author Devin Petersohn (Snowflake; Ponder co-founder) against official documentation, papers, and verifiable source. They are not collapsed into a single verdict; spoken causality and performance judgments are labeled speaker view, with links or reproducible pointers where claims can be checked.
DataFrames and SQL: not “which is faster,” but different semantic contracts#
Why#
When data scientists iterate in notebooks, they default to repeatable row order (head() looks the same every time) and freely composable operations; warehouse SQL is often optimized for logical relations, with no promise of physical order. Comparing raw latency between the two hides the split between interactive exploration freedom and structured execution inside the engine.
Mechanisms and constraints#
| Dimension | Common practice | Guest stance (speaker view) |
|---|---|---|
| Mental model | SQL = warehouse batch; pandas = local EDA | DataFrame like a “food court” where operations mix freely; SQL like a “Michelin” menu—more constrained but consistent |
| Iteration style | Write and run SQL in chunks | DataFrames more incremental; SQL interaction not necessarily more “natural” (partly contrary to popular narrative) |
| Adoption drivers | Chasing lower latency | In genomics and similar domains with weekly/monthly experiment cadence, faster may not matter; productivity and keeping the existing workflow win |
Snowflake SELECT documentation states that without ORDER BY, the result is an unordered set and repeated runs may return different order each time. That tensions with pandas users’ stable expectation for head() (see next section).
How to proceed (minimal example)#
On the warehouse side, if you only care about set semantics, sort explicitly or use keys:
SELECT * FROM events ORDER BY ts, id LIMIT 10;
On the pandas side, do not assume read_sql without ORDER BY yields stable row order.
Common pitfalls#
- Using a single benchmark to prove “SQL is better than DataFrame for exploration.”
- Ignoring the product gap between logical order (DataFrame) and physical disorder (relational engine).
“pandas wrapper” or “compiler”: Modin’s intermediate representation#
Why#
Users often read Modin as “pandas that can run on Ray”; if you only change one import line and miss Query Planner → Dataframe Algebra → execution backend, you may pick the wrong ops model between Snowflake and Ray paths.
Mechanisms and constraints#
Modin architecture documentation describes: Query Planner translates the pandas API into a Dataframe Algebra DAG; Query Executor optimizes and compiles an execution sequence; the docs use the word compiler. The paper Towards scalable dataframe systems (Petersohn, Lee, Parameswaran, et al.) proposes a dataframe data model and algebra, discussing flexible schema, ordering, row/column equivalence, etc.—it does not use the guest’s spoken “marriage of relational algebra and linear algebra” wording; treat that metaphor as intuition (speaker view).
The guest emphasizes: relative to Dask DataFrame / Ray Datasets, Modin on Ray/Dask mainly uses task scheduling, with a custom dataframe engine and algebraic operators (partially verified: RayWrapper / DaskWrapper wrap arbitrary callables with @ray.remote and client.submit; public docs do not literally say “zero use of Ray Datasets”).

How to proceed#
import modin.pandas as pd # drop-in narrative per Modin README
df = pd.read_parquet("s3://bucket/large.parquet")
df = df[df["country"] == "US"] # planner may push down filter (backend-dependent)
print(df.head())
Common pitfalls#
- Equating “compiler” with a published formal IR specification (the podcast does not provide PDF-level spec).
- Expecting the same control plane on the Snowflake backend as on the Ray path (guest: SQL side more like a transpiler, optimizer a black box—speaker view).
Row order, materialized views, and the Snowflake semantic gap#
Why#
Interactive notebooks depend on a stable head; MPP warehouses do not guarantee order without ORDER BY. If the bridge layer adds no extra semantics, users assume “the database is broken.”
Mechanisms and constraints#
- Verified: Snowflake
SELECTwithoutORDER BY→ unordered (documentation above). - Speaker view: Modin simulates order for Snowflake and similar backends; open-source path has cached materialized views; Snowflake path emphasizes guaranteed order. Not verified: Modin main-repo public docs/source for Snowflake materialized-view implementation details.
How to proceed#
When you need a stable preview, add key order in SQL, or accept materialization/caching cost from the bridge (product behavior per Snowflake pandas documentation).
Common pitfalls#
- Assuming
SELECT * LIMIT 10on any warehouse equals pandashead()semantics. - Treating the guest’s materialized-view narrative as default Modin open-source behavior (boundary unconfirmed).
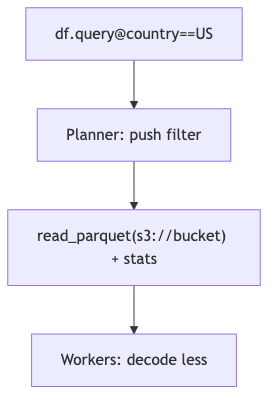
Query optimization: filter first, then talk about the “smartest” optimizer#
Why#
A distributed agent that read_parquets the whole table then filters amplifies network and decode cost; the classic database lesson filter-first applies equally to DataFrame compilation stacks.
Mechanisms and constraints#
- Apache Parquet supports predicate pushdown via row-group statistics, Page Index, etc.; Modin’s Parquet read path with
engine="pyarrow"usespyarrow.datasetandfilters_to_expression(source parsers.py). - Speaker view: owning the full task graph enables finer bypass ideas, some not shipped in open source; guest self-describes Modin as not having the most sophisticated optimizer—a different dimension from paper speedups “vs. pandas/Dask DataFrame”; do not frame as contradiction.
How to proceed#
# PyArrow-style reads often support filters (confirm for your Modin/pandas version)
df = pd.read_parquet("data.parquet", filters=[("year", ">", 2020)])
Common pitfalls#
- Expecting storage-layer pushdown on giant CSV comparable to Parquet (CSV has no columnar statistics).
- Denying planner + executor optimization because the guest downplays the optimizer (docs already describe both layers).
Parallel CSV reads: commas inside quotes are not delimiters#
Why#
RAG cleaning, eval exports, and crawler dumps still use CSV heavily; naive splits by row count or byte ranges break inside quoted fields, causing silent row corruption—an order of magnitude harder than “each worker reads different lines.”
Mechanisms and constraints#
- Verified: Modin
TextFileDispatcher.offset()usesquotecharparity to decide whether a split point is outside quotes; otherwise read to line terminator (text_file_dispatcher.py). - Speaker view: bottleneck often parse not raw read; Amazon reviews–style data has commas and newlines inside quotes. Compare Python csv
quotecharbehavior.
How to proceed#
# Concept: driver assigns byte offsets, workers start at quote-safe boundaries
# Modin partition sketch — do not naively bytes // n_workers on giant CSV
df = pd.read_csv("huge.csv") # Modin on Ray: parallel quote-aware splits
Common pitfalls#
- Sharding by fixed row count without RFC-style quoting.
- Assuming “more workers” scales linearly while parse CPU dominates (podcast gives no benchmark numbers).
Data movement: Arrow, Ray object store, and “pass handles only”#
Why#
In multi-step agent chains and feature pipelines, shuffle and cross-node copies often cost more than a single groupby.
Mechanisms and constraints#
| Claim | Verification |
|---|---|
| Guest: worker serialization generally Apache Arrow | Partially verified: dependency includes pyarrow; Ray partition put comments point to Plasma store; Ray Serialization main narrative is pickle/cloudpickle + object store |
| Guest: large files prefer shared storage (NFS/S3/GCS), pass handles not file chunks | Partially verified: experimental CSVGlobDispatcher uses fsspec URLs; no Modin official “forbid over-the-wire sharding” verbatim |
| Ray: runtime pickles functions, not 600 separate pandas API task types | Verified: RayWrapper._deploy_ray_func wraps arbitrary callables (engine_wrapper.py) |
Apache Arrow columnar memory is tightly tied to Parquet/Feather I/O; do not write “official rule: workers only Arrow IPC.”
How to proceed#
Deploy so every worker can read the same s3:// prefix directly; reduce driver aggregation of intermediate results.
import ray
@ray.remote
def process_shard(path: str, offset: int, limit: int):
# worker opens path locally — sketch
...
Common pitfalls#
- Distributed read for small files, paying scheduling overhead.
- Equating historical Plasma components with the only serialization path in all current Ray versions.
GPU DataFrames: cuDF as one backend, not a universal replacement#
Why#
Vector retrieval and embedding batch jobs push GPU operators; “wacky” DataFrame operations often lack GPU implementations or fall back slowly.
Mechanisms and constraints#
- Partially verified: Modin repo has experimental
cudf_on_raypath (cudf_on_ray); RAPIDS cuDF offers pandas-like API. - Speaker view: distributed GPU DataFrame POC with Georgia Tech is feasible; cuDF harder on wacky ops; no performance numbers in the podcast.
How to proceed#
For regular numeric columns and GPU-friendly ops, evaluate cudf.pandas or Modin+cuDF; for string/object-heavy workloads, profile before committing.
Common pitfalls#
- Assuming the entire pipeline GPU-accelerates without measuring PCIe transfer and fallback.
- Treating POC narrative as production default.
LLMs, Copilot, and API design: unverified adoption accelerators#
Why#
Engineers building RAG/agents care whether tool schemas match training corpus distribution. If an agent emits import pandas as pd but runtime is an approximate API, repair cost grows.
Mechanisms and constraints#
- Speaker view: mirroring the pandas API makes Copilot suggestions more usable—an after-the-fact surprise in Modin adoption; “close to pandas” may lose to “is pandas” under LLM suggestions; customers increasingly want “match API”—cannot verify causality or magnitude (no A/B, no Copilot official study).
- Checkable: Modin README drop-in and API coverage tables (e.g.
DataFramecoverage fraction)—keep separate from LLM narrative: latency measurable, Copilot not tested. - Host extension: few Snowflake SQL extensions → low training DSL cost; or LLM treats Ponder as a tool (product direction; this conversation does not expand schema/eval).
- Weakly related AI thread: Lux (rule/recommendation visualization, not LLM drawing); Weaviate × Arrow × GPU vector index is host speculation, guest gives no implementation-level response.
How to proceed#
Agent tool definitions should bind APIs that are well documented and high-frequency in training data; with Modin, prompt explicitly import modin.pandas as pd and pin versions.
Common pitfalls#
- Treating Copilot anecdotes as proved cause of download growth.
- Evaluating agents with SQL pass@k only, ignoring DataFrame tool traces and multi-library cleaning (cf. different workloads in Data Agent Benchmark).
Tension summary: no need to force unification#
| Topic | Docs/paper | Speaker view | Suggested wording |
|---|---|---|---|
| Compiler strength | Dataframe Algebra + compiler copy | Near query compiler | Aligned, but no public IR spec |
| Arrow serialization | pyarrow dep, Plasma comments | generally Arrow | Downgrade to “columnar I/O + object store,” not sole IPC |
| Snowflake order | SELECT disorder verified | materialized views preserve order | Product behavior: check Snowflake pandas docs |
| LLM adoption | README performance story | Copilot boost | Separate tracks: causality unverified |
If you are shipping this#
- Fix semantics first: need stable
head()or accept unordered sets in the warehouse? Then choose pandas on Snowflake, Modin+Ray, or local pandas. - Prefer Parquet formats: predicate pushdown has format-spec support; for huge CSV confirm quote-aware parallel read—do not naively split by bytes.
- Reduce data movement: shared object storage + worker-local reads; avoid driver collecting full table then broadcasting (aligned with Ray object store design).
- Optimizer expectations: default filter-first and Parquet statistics; do not assume open-source Modin equals warehouse-grade CBO (guest humility—speaker view).
- Agent/RAG on separate tracks: aligning tool API with training distribution deserves its own experiments; do not mix Copilot anecdotes and latency benchmarks into one KPI.
References and further reading#
- Modin documentation home
- Modin system architecture — Dataframe Algebra
- Modin README — engines and API coverage
- Towards scalable dataframe systems (VLDB 2020)
- Flexible rule-based decomposition in Modin (VLDB)
- pandas enhancing performance guide
- Ray Core concepts
- Ray Tasks and remote functions
- Ray object serialization
- Apache Parquet file format and metadata
- Apache Arrow columnar memory specification
- Snowflake SELECT semantics
- Snowflake storage/compute separation
- pandas on Snowflake developer guide
- RAPIDS cuDF documentation


