
From RAG to Search Agents: Three Tensions in Retrieval, Synthetic Data, and Evaluation#
Once large-model products make “search the web” a default capability, engineering teams often hit the same set of tensions: do users want a short answer or a long report? Should training budget go to LLM tokens or search API calls? Should evaluation optimize for correctness or for trajectory efficiency? This article centers on the working definition of a search agent—using search / browse tools to answer multi-hop web questions on the open internet—alongside public benchmarks such as BrowseComp-Plus, synthetic-data routes like WebShaper, and the engineering judgments of guest Nandan Thakur (BEIR / MIRACL co-author) in interview. We do not force a single conclusion; any figure not appearing in a paper or on a leaderboard is labeled speaker view or unverified.
Problem space: three axes, not one “smarter RAG”#
Classic RAG is often “retrieve once → stuff into the prompt → generate.” Agentic search turns retrieval into a multi-turn, branchable process: the model decides when to search, what to search for, and whether to keep reading documents. In the public literature, BrowseComp-Plus operationalizes Deep-Research agents as LLM + search tools, measured on a fixed corpus by Accuracy and Search Calls.
At the same time, industry pushes a deep research product narrative—users often expect report-style output, arbitrary tool orchestration, and longer test-time compute. The guest’s split is: a search agent is anchored on “answer one question”; deep research is a wider umbrella (speaker view). Both product lines can share the same retrieval stack, but optimization targets and harnesses are not the same.

Search agent vs. deep research: naming sets product expectations#
Why#
The same “model that can search the web,” if marketed as deep research, primes users for long documents, many tools, downloadable reports; if marketed as a search agent, it sits closer to web QA / the BrowseComp family (speaker view).
Mechanisms and constraints#
BrowseComp-Plus evaluates on roughly 100K fixed documents for reproducible retrieval stacks (BM25, DiskANN dense indexes, etc.)—not directly comparable numerically to commercial agents on live, full-web APIs.
How to (mental model)#
Decompose the harness into plan → search → read → answer; first clarify whether the deliverable is a span-level short answer or a nugget-level long answer (the latter is closer to TREC RAG nugget / support evaluation).
Common pitfalls#
Judging BrowseComp-style short-answer tasks with report-product UX, or holding multi-turn agents to a single-shot RAG latency SLA.
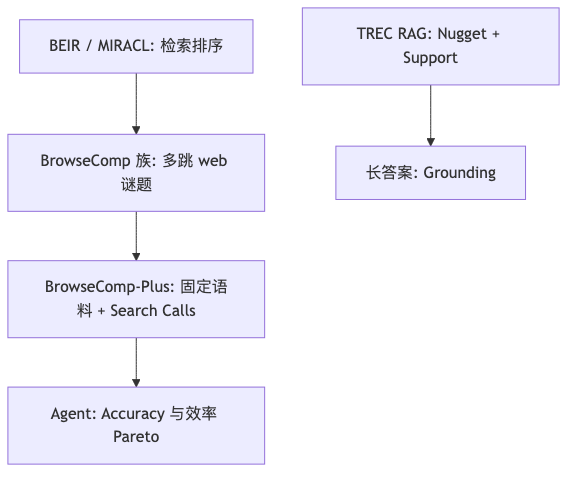
Evaluation lineage: from BEIR to BrowseComp+#
Why#
BEIR helped the community iterate retrievers across 18 zero-shot datasets; MIRACL brought heterogeneous languages under the same qrel mindset. Search agents need a similar “community orbits the benchmark” pull, but IR metrics and agent metrics are not the same random process (speaker view).
Mechanisms and constraints#
| Layer | Typical metrics | Stability (literature / common sense) |
|---|---|---|
| Retriever | NDCG@k, MRR | Fixed qrels, reruns have tiny variance |
| Agent end-to-end | Accuracy, Search Calls | Same model, multiple rollouts—high variance |
| Long-report RAG | Nugget recall, Support 0–2 | Different family from BrowseComp Accuracy |
The BrowseComp-Plus paper reports GPT-5 + BM25 at 55.9%, rising to about 70.1% with Qwen3-Embedding-8B; the project page footnote gives GPT-5 + Google Search API at about 59.9%. The guest’s oral claim that “top models are at 90–95%” does not match the August 2025 public table—possibly another benchmark, a private leaderboard, or an unverified BrowseComp (non-Plus) setup; the article must not substitute interview for leaderboard.
The guest describes BrowseComp+ sub-clauses with a filter / funnel mental model: many candidate constraints narrowed step by step (speaker view). The paper side has human-verified supporting docs + mined negatives and a GPT-4o sub-query decomposition pipeline—directionally aligned, but the 10³–10⁵ → single-digit magnitude does not appear verbatim in the paper.
How to#
Reproduce BrowseComp-Plus + Tevatron on fixed corpus before claiming “swap retriever → gain Accuracy”; commercial API trajectories need a separate private eval.
Common pitfalls#
Equating NDCG gains on BEIR with Accuracy gains on BrowseComp; Search-R1 + BM25 at only ~3.86% on BrowseComp-Plus shows “keyword-style queries are enough” has not held on that hard benchmark.

Synthetic data: Orbit, WebShaper, and “chained” multi-hop#
Why#
Search-R1 and similar work train on NQ, HotpotQA, etc., where task difficulty misaligns with the BrowseComp family; many dataset papers do not release training data (speaker view). Synthetic pipelines try to build hard cases with an intersection pattern: seed → retrieve → extract facts → hide → retrieve again.
Mechanisms and constraints#
- WebShaper (verifiable): formalization-driven, Knowledge Projections + agentic Expander; dataset WebShaperQA.
- Orbit (unverified): guest describes ~20k BrowseComp-style four- to five-layer riddles, DeepSeek generation + self-verification + external search-agent verification, months of continuous runs on a consumer laptop (speaker view). Public search found no paper/repo under the name Orbit; treat as project oral history until published.
- Difficulty contrast (speaker view): BrowseComp+ leans filter (many sub-clause candidates, funnel step by step); Orbit is closer to A→B→C→D chaining, self-assessed as not yet reaching Plus-level filter strength.
How to (minimal pipeline)#
seed_entity → web_search → extract_facts → mask_entity → repeat → QA_pair
Quality gate: validate solvability at each hop with independent retrieval results, not LLM self-consistency alone.
Common pitfalls#
Synthetic items that let the model guess from one clue (guest cites Emoji Movie–style shortcuts, speaker view); the ideal agent should todo-list–style verify constraints one by one.
Training economics: GRPO, rollouts, and “search costs more than the LLM”#
Why#
Search-R1 uses outcome-based reward and retrieved-token masking, reporting roughly +41% / +20% over naive RAG on seven QA sets for Qwen2.5-7B/3B (paper tables). The next competitive axis is often stated as: same Accuracy with fewer tokens and search calls (speaker view).
Mechanisms and constraints#
- GRPO (DeepSeekMath): sample G outputs per problem, group-normalized reward for advantage; G is a hyperparameter—the paper does not fix it at 8. Training where “one of several trajectories succeeds still yields positive advantage” is mechanistically compatible with the guest’s “signal if 1 of 8 is right,” but do not conflate training group size G with inference pass@k under one symbol.
- API billing (speaker view): if
6 turns × 8 rollouts × 1 search/turn, back-of-envelope ~48 searches / training sample; BrowseComp-Plus reports strong models averaging >20 searches per question. When search is billed per call and the LLM per token, search bill can exceed LLM in agent training—opposite the intuition that “tokens only get cheaper.” - Sequential long horizon vs. parallel: pass@K works at inference; cross-rollout credit in RL for training is too expensive—common path is strong teacher rollouts → SFT distillation (speaker view).
- Context rot: Chroma’s research report shows performance falls as input grows under controlled difficulty—tension with “eval keeps full trajectories” vs. “engineering compresses context.”
How to#
Start with Search-R1’s codebase PPO/GRPO/reinforce switches on small corpus, then scale G and turns; log search_calls and tokens as separate cost columns.
Common pitfalls#
Writing GRPO’s G as pass@8; counting repeated identical queries in BrowseComp+ trajectories as useful exploration (guest criticizes as waste, speaker view).


Retrieval interface: snippets, full text, and self-hosted stacks#
Why#
Commercial search APIs often return snippet + offset, like classic reader spans; self-hosted BM25 / ANN can start at billion-scale corpora, but agents sometimes need snippet-level reproducibility or a full-text tool (speaker view).
Mechanisms and constraints#
The guest favors a two-stage pattern: search → pick doc → document tool pulls full text; end-to-end full-text RL was not done much in training because APIs are slow/expensive (speaker view). Academic alternatives include FineWeb / ClueWeb indexes + internal search API; BrowseComp-Plus with Tevatron gives reproducible BM25/dense retrieval. The proper name “Deep Research Gym” had no independent project page in public URL checks (verified 2026-05); in writing, point to the Tevatron/BrowseComp-Plus ecosystem or mark unverified.
Guest hypothesis (no experimental numbers): after SFT/RL, the agent might only need to emit BM25 keywords for a lexical retriever—not yet supported by public results on BrowseComp-Plus; keep as a research hypothesis.
How to#
# Concept harness (not production code)
for turn in range(max_turns):
q = llm.plan_query(state)
hits = retriever.search(q, top_k=10) # snippet + doc_id
if need_full_text(hits):
doc = corpus.fetch_full(hits[0].doc_id)
state = llm.update(state, hits, doc)
answer = llm.finalize(state)
Common pitfalls#
Replacing multi-turn search with one vector top-k; ignoring that REPLUG-era “retrieval vs. LM division of labor” reappears in agents as summarization / external-folder memory (e.g., Claude Code–style), not only Databricks-style “compress and retrieve trained end-to-end together” (host paraphrase; official benchmark page not verified 2026-05).


Harness: memory, compression, and the eval loop#
Why#
Multi-turn search makes context length a second bottleneck; themes from RAG a few years ago—prepend retrieved docs (REPLUG), chunk trimming, nugget report evaluation—show up again in agent harnesses (speaker view).
Mechanisms and constraints#
- Modular: search first, full-document tool on demand; coexists with “retrieval agent + compressor trained end-to-end”; guest personally leans modular (speaker view).
- TREC RAG (verifiable): 2024 guide includes Nugget, Support, Fluency, Retrieval; Support 0–2 scores grounding. Guest judgment that “fluency weight should drop, grounding matters more” is a participant view.
- Tool-use bar: ~six months ago SFT+RL was still needed for stable tool use; now mid/post-training has distilled it into large models—the race shifts to efficiency and Pareto (speaker view, time anchor is oral around recording).
Common pitfalls#
Dropping audit-friendly citation trajectories to save length; applying IR’s “single deterministic ranking” mindset to stochastic rollouts.

Unresolved conclusions (deliberately side by side)#
- Task definition: BrowseComp-Plus’s operational Deep-Research agent definition can coexist with the guest’s “search agent ⊂ deep research umbrella”; product naming still shapes user expectations (speaker view).
- Data: WebShaper is published; Orbit scale and pipeline await public verification.
- SOTA: public BrowseComp-Plus ≤70.1% (fixed-corpus setting) conflicts with guest 90–95% oral claim—the article can only list both, not merge them.
- Training: GRPO’s within-group relative reward supports “sparse success”; 48 API calls/sample is lab back-of-envelope, not a theorem.
- Next benchmarks (speaker view): multilingual/multimodal riddles, FreshStack / CRAG family plus agentic search, harder filters—aligned with Omar Khattab–style “we need harder benchmarks,” specific metrics not developed in the podcast.
If you are shipping something#
- Pin deliverable and eval family first: short answers → BrowseComp-Plus-style Accuracy + Search Calls; long reports → TREC nugget/support—do not mix tables.
- Split the cost ledger: log
search_callsandllm_tokensseparately; simulate budget with small G and few turns before training (GRPO’s G per DeepSeekMath). - Harden synthetic data gates: external retrieval check per hop + anti-shortcut rules (no single-clue guessing); see WebShaper’s agentic Expander pattern.
- Prefer reproducible retrieval: reproduce on BrowseComp-Plus fixed corpus before swapping commercial APIs; when you need full text, add an explicit
fetch_full(doc_id)tool—do not assume snippets suffice for training. - Align context strategy with eval: if eval needs full trajectories, training can compress/distill separately; see context rot on length–accuracy tradeoffs.
References and further reading#
- BEIR: A heterogeneous benchmark for zero-shot information retrieval evaluation
- MIRACL: A multilingual retrieval benchmark
- Search-R1: Reinforcement learning with multi-turn search
- Search-R1 official implementation and experiment logs
- DeepSeekMath: GRPO algorithm definition
- BrowseComp-Plus paper
- BrowseComp-Plus project page and results table
- BrowseComp-Plus code and Tevatron retrieval stack
- OpenAI BrowseComp dataset (Hugging Face)
- WebShaper: Formalization-driven web agent data synthesis
- REPLUG: Tunable retrieval + frozen LM
- TREC RAG Track home
- TREC 2024 RAG evaluation guide (nugget / support / fluency)
- Chroma: Context Rot research report
- Meta CRAG comprehensive RAG benchmark repository


