
Semantic Query Engines: When LLM Operators Enter the Query Optimizer#
RAG and Agents have made “retrieve + generate” the default architecture, but production pipelines still rely heavily on batch analytics: filter, join, and map over millions of rows of text, images, and audio, mixed with relational operators. Traditional TPC-H / TPC-DS benchmarks barely include long text or multimodal fields; text-to-SQL suites such as Spider and BIRD also lack a search / semantic operator dimension. MIT PhD student Matthew Russo works on SemBench, Palimpzest, and Abacus, arguing that semantic filter / join / classify / map / rank on foundation models should be first-class query operators, scheduled uniformly by logical / physical planners and cost–quality optimizers—a different path from “hand-written Python + tuned models” at every RAG step.
The sections below follow the problem space, operator taxonomy, execution and optimization, benchmarks, and deployment boundaries. Expressive equivalence is not the same as optimizer rewritability; product comparisons, industrial bear cases, and specific dollar figures from the interview are labeled separately where they cannot be verified.
Problem space: from ML UDFs to semantic operators#
Why: Relational WHERE cannot express “image path points to a red car” or “contract clause contains a non-compete”; historically, routes such as BigQuery ML embed prediction functions in SQL, but generalization depends on feature engineering. Foundation models’ zero-shot ability lets predicates and transforms live directly in the query (speaker view).
Mechanism/constraints: Once a pipeline includes LLM or vision calls, latency and dollar cost often dominate traditional joins and index scans—vector retrieval on the order of milliseconds versus seconds per LLM call is a common rule of thumb (speaker view; exact ratios vary by model and batching). The optimization objective shifts from “minimize I/O” to a cost–quality–latency tradeoff, and quality is often estimable only by sampling.
How to proceed (conceptual): Compile user intent into a plan with semantic operators, not row-by-row apply() in the application layer:
# Conceptual sketch: declarative semantic filter (not a complete API for any one system)
plan = (
scan("papers")
.semantic_filter("abstract mentions retrieval-augmented generation")
.semantic_map("extract first author name")
)
# Optimizer may choose: filter before map, Flash vs GPT, RAG pre-screening, etc.
Common pitfall: Equating “semantic query engine” with a text-to-SQL agent. The Weaviate Query Agent focuses on natural-language Q&A and filter generation; the Transformation Agent uses append_property / update_property to materialize new columns back into a collection—closer to semantic map/classify, but intermediate results are persisted by default. Palimpzest-style engines emphasize on-the-fly computation without writing back to the database (architecture contrast is the speaker’s view). Another pitfall is treating a vector database as a full semantic query processor: ANN solves a similarity-retrieval subproblem; it does not automatically choose physical plans for cross-table semantic join, nor replace filter pushdown and model-level implementation rules.
Operator taxonomy: five classes and the map universality thesis#
Why: SemBench standardizes core operators as filter, join, classify, map, rank (paper wording: filters, joins, mappings, classification, ranking) so systems with different API surfaces—LOTUS, ThalamusDB, Palimpzest, BigQuery—can be compared horizontally (verified: arXiv:2511.01716 abstract and README headers).
Mechanism/constraints: There is a “semantic map universality” thesis: filter (binary predicate), classify, and rank can theoretically be written as map (rank over a full table is closer to aggregate). Russo’s position: expressive equivalence ≠ optimization equivalence—only filter naturally fits Oracle + proxy approximate query processing (AQP): proxy and Oracle can agree/disagree on the same row, and high/low confidence bands can skip expensive Oracle calls (speaker view; aligned with LOTUS cascade learn_filter_cascade_thresholds and gold algorithm terminology, partially verified). Semantic map (e.g., generating summaries) is hard to threshold the same way with binary agreement (speaker view).
How to proceed (rewrites vs optimization): If you only need expressiveness, map can simulate filter: map("does image show red car? yes/no") then relational filter; if you need cascade, keep a distinct semantic_filter operator type so the optimizer can learn proxy thresholds (LOTUS) or pick black-box implementations (Palimpzest). Semantic rank is a separate SemBench class; full-table ordering is closer to aggregate + order and should not be folded into map (taxonomy motivation; verified README lists Rank separately).
Common pitfall: Using open-ended summaries as ground truth in benchmark design—SemBench prefers rigid field extraction (e.g., paper author name); open-generation evaluation remains an open boundary (speaker view).
Execution models: eager DataFrames vs lazy SQL plans#
Why: Operator order determines call count (especially filter/map reorder) and whether pushdown is possible.
Mechanism/constraints:
| Path | Typical behavior | Optimization space (literature/code) |
|---|---|---|
LOTUS DataFrame sem_* | Materialize per operator (speaker view) | LazyFrame + optimize() supports cascade / predicate pushdown (partially verified) |
| Palimpzest / ThalamusDB / BigQuery | Whole query submitted → logical reorder + implementation rules | Abacus: transformation rules + implementation rules (e.g., PushDownFilter, EmbeddingJoinRule) |
How to proceed (plan sketch): Scan papers → semantic filter by topic → two semantic map steps: filter before map to avoid expensive map over the full corpus (Abacus paper case; verified filter pushdown rules exist).
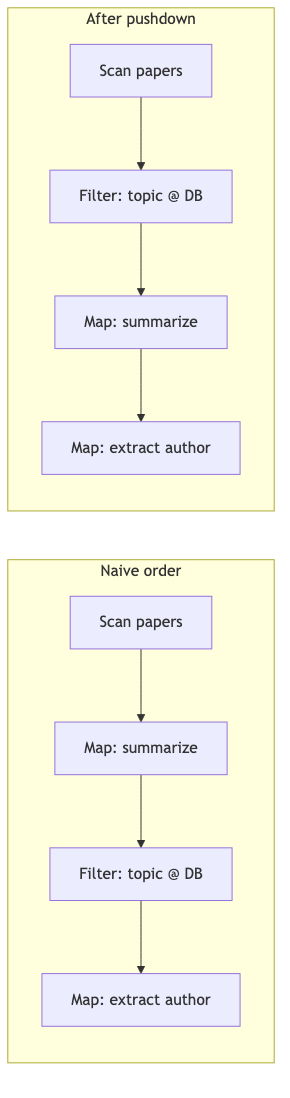
ThalamusDB note: ThalamusDB describes itself as an approximate query processing engine; whether its cascade is isomorphic to LOTUS’s proxy/oracle ternary structure was not verified in the README—the guest’s “probably similar” should remain interview opinion.
Common pitfall: Assuming a vector database automatically delivers query-level optimization. ANN solves retrieval; semantic join with nested-loop LLM on both sides can still reach N×M complexity (Palimpzest NestedLoopsJoin double-loops left/right candidates, verified). With LOTUS LazyFrame available, “DataFrames can never reorder” should be weakened to default eager API vs explicit optimize() (partially verified).

Semantic join: academic bull case vs industrial bear case#
Why: Join reorder and physical implementation choice were central in traditional analytic workloads; if semantic join similarly dominates the dollar bill, optimizers are worth the investment (speaker view).
Mechanism/constraints:
- Bull: In queries with multimodal joins, implementation choice can swing cost by orders of magnitude—the guest’s revised oral case: ~12,000 images, total cost ~$2–$27, embedding join much cheaper than per-image vision LLM (interview opinion; public Abacus paper/repo not verified for 12k and $2–$27; SemBench MMQA scale is 1,000 images).
- Bear: Real workloads are hard to cite with many mandatory multimodal joins; more common is semantic map to extract entities + relational join. In an animal scenario, mapping
elephantandNorth African elephantthen string-joining fails (speaker’s own attempt; no quantitative failure rate given). - Vector search vs semantic join: “Find similar profiles” in dating apps is closer to vector search than a declarative join operator (discussion view).
EmbeddingJoin uses sample LLM labels to set min_matching_sim / max_non_matching_sim; similarity in the middle band triggers LLM—same family as filter’s “two thresholds + middle band” (partially verified).
Common pitfall: Modeling every “cross-collection match” as semantic join. Many-to-many text alignment in industry is often map + equi-join, and map extraction quality is unstable.
Optimizer philosophy: fixed Oracle vs black-box implementation space#
Why: Users should not hand-tune model name, temperature, ensemble, and RAG (K) at every step.
Mechanism/constraints:
| School | Optimization variables | Representative mechanisms |
|---|---|---|
| LOTUS-style (guest summary) | Cut cost with proxy under fixed gold / Oracle | Cascade thresholds; paper emphasizes accuracy guarantees relative to gold (DOI 10.14778/3749646.3749685) |
| Abacus / Palimpzest-style | Implementations as black boxes, sample cost / quality / latency | Pareto-Cascades, OptimizationStrategyType.PARETO, sample budget (paper example: spend less than $1) |
Palimpzest implementation rules for map/filter include: model selection, MixtureOfAgents*, CritiqueAndRefine*, RAGRule (context reduction + retrieval), k_budgets = [1,3,5,10,15,20,25], etc. (partially verified in rules.py). Semantic filter can be a single LLM call, RAG → top-K → LLM, or an agent-generated Python / regex script run in batch (speaker view; Palimpzest design philosophy).
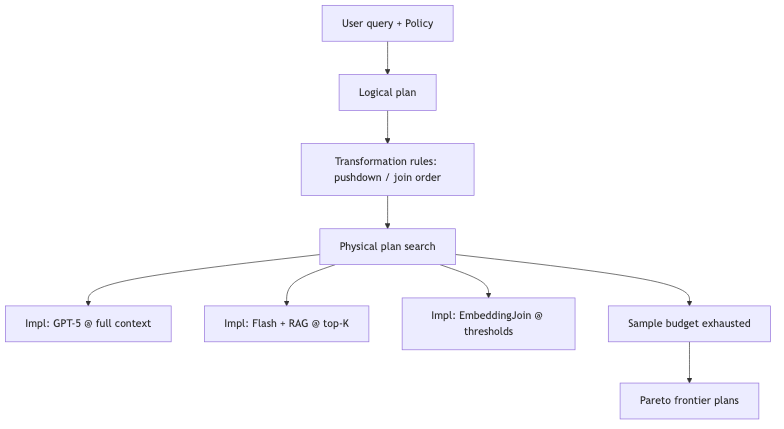
Common pitfall: Reading the paper’s $1 sample budget as “10¢ per row”—public Policy uses plan-level constraints such as MaxQualityAtFixedCost(cost_budget) (verified); per-row 10¢ does not appear in the docs reviewed.
SemBench: shared tasks matter more than leaderboard rank#
Why: Without shared workloads, “semantic query engine” cannot accumulate reproducible engineering knowledge the way the TPC era did.
Mechanism/constraints (from SemBench README, verified):
| Scenario (official name) | Queries | Modalities |
|---|---|---|
| Movie | 10 | table + text |
| Animals (colloquial wildlife) | 10 | table + image + audio |
| E-Commerce | 14 | table + text + image |
| MMQA | 11 | table + text + image |
| Cars (guest said “medical”) | 10 | table + text + image + audio |
| Total | 55 | all four modalities represented |
Operator columns are Filter / Join / Map / Rank / Classify only—no semantic group-by / aggregate workload yet (verified no GroupBy column). Systems evaluated: LOTUS, Palimpzest, ThalamusDB, BigQuery; README links an online leaderboard (TLS failed in this environment, leaderboard content not independently checked).
Evaluation philosophy (speaker view): Early on, relative rank matters less than establishing common tasks; prompt sensitivity drives high variance. Ground truth often comes from Kaggle labels plus synthetic columns (e.g., animal location); synthetic filters may correlate with embeddings (host analogized Weaviate mod 10 synthetic filters)—benchmark construction remains open. Abacus reports on CUAD legal contracts: +6.7%–39.4% quality vs suboptimal systems, 10.8× cheaper, 3.4× faster (verified at abstract level; see paper tables for curves). SemBench README emphasizes F1 / precision / recall / relative error, not pass@k for generation—align evaluators when comparing across papers.
Semantic GROUP BY: embed → cluster → summarize clusters; the guest would classify this as semantic GROUP BY (aggregation itself is semantic), not join—contrasts with Transformation Agent materialized properties (speaker view).
Hybrid queries and deep research: open boundaries#
Why: Real systems often chain ClickHouse-style relational filters with semantic operators in one pipeline.
Mechanism/constraints: For most workloads today, optimizing only the semantic segment captures most gains because semantic operators are orders of magnitude slower (speaker view). Counterexample: after relational filters shrink to a handful of rows, relational engine optimization matters, and Palimpzest does not specialize on the relational segment (guest’s own statement)—Palimpzest relational boundaries not verified.
Deep research (high-level intent → system self-plans) vs declarative semantic QP: overlap TBD (speaker view). If thousands of filters become parallelizable and API rate limits ease, bottlenecks may shift between relational and semantic operators (guest speculation, not verified). Self-hosted vLLM weights: LOTUS can reach vLLM endpoints via LiteLLM, but whether optimizers exploit self-hosted weights for cost—the guest said Palimpzest is very basic there, still API-first (interview opinion).
How to proceed (hybrid pipeline): Run highly selective WHERE / partition prune in the relational engine first, then pass hundreds of rows to semantic operators; when Palimpzest does not optimize the relational leg, this often must happen externally rather than expecting one framework to push down automatically (speaker view + Palimpzest boundary not verified).
If you are shipping this#
- Fix operator semantics and eval fields first: open summaries are hard to score; prefer rigid extraction + reproducible F1 / relative error (SemBench README direction) before complex map.
- Model filter and map separately: if you need cascade / AQP, binary filter predicates and map follow different optimization paths; do not merge operator types because “map can express it.”
- Measure plan-level dollars on SemBench or your workload: compare sembench.org and Palimpzest
Policy; on joins, explicitly compareNestedLoopsJoinvsEmbeddingJoin—do not assume the vector DB optimized join. - Agent materialization vs in-query compute: enrich columns reused many times suit the Transformation Agent; one-off analytics pipelines can use Palimpzest / LOTUS LazyFrame to avoid blowing up stored intermediates.
- Audit interview numbers: 12k images, $2–$27, leaderboard conclusions—recheck paper revisions and reproduction before writing or procurement decisions.
References and further reading#
- SemBench paper (arXiv:2511.01716)
- SemBench GitHub and workload table
- SemBench online leaderboard (README link)
- Abacus paper (arXiv:2505.14661)
- Abacus PVLDB entry
- Palimpzest GitHub
- Palimpzest documentation site
- LOTUS GitHub
- LOTUS semantic operator optimization (arXiv:2407.11418)
- LOTUS cascade optimization (VLDB 2025)
- ThalamusDB project site
- Weaviate Query Agent usage
- Weaviate Transformation Agent usage
- RAG survey (Lewis et al., 2020)
- TPC-H specification entry


