
Sufficient Context: RAG Should Measure Whether There’s Enough to Answer, Not Just Whether Chunks Look Relevant#
In a RAG pipeline, the retriever stitches chunks into the prompt and the generator answers. Engineers often blame failures on “nothing was retrieved” or “the model hallucinated”; evaluation leans heavily on RAGAS relevance and faithfulness metrics. Collaborators from UC San Diego, Google, and others propose in Sufficient Context: A New Lens on Retrieval Augmented Generation Systems (Published as a conference paper at ICLR 2025): given the current context, should the model be able to answer this question—a different dimension from “how relevant is each chunk to the query.” Below, paper-verifiable claims are separated from engineering inferences drawn in the interview; numbers are aligned with Table 1 / Figure 2 / Figure 4 / Figure 6 where possible.

Problem space: retrieval quality, context sufficiency, and abstention#
| Concern | Common practice | Gap emphasized here |
|---|---|---|
| Retrieval ranking | nDCG@k, vector similarity | High relevance ≠ enough information to answer |
| Generation faithfulness | RAGAS faithfulness | Answers faithful to a wrong premise in context can still be wrong |
| Abstention / selective generation | Fixed thresholds, model self-assessment only | Gating on “insufficient” alone drops many “insufficient yet correct” cases |
In production logs, three failure modes often stack: under-retrieval, context sufficient but the model does not use it (Table 4a: Gemma is judged to hallucinate on roughly 25.4% of human-labeled sufficient cases), and context insufficient yet answered correctly via parametric knowledge (abstract: SOTA models still answer correctly 35–62% of the time under insufficient context). Optimizing only similarity—or only training “say I don’t know when unsure”—can overfit the wrong subset.

Sufficient context vs. relevance: concepts and measurable boundaries#
Why#
RAGAS offers context_precision, context_recall, faithfulness, answer_relevancy, and more, but no binary label named sufficient context as in the paper. Paper §3.1 defines: instance ((Q,C)) is sufficient iff there exists a plausible answer (A’) such that (A’) reasonably answers (Q) from the information in (C); multi-hop reasoning is allowed, and a ground-truth answer need not be given upfront. This differs from TRUE-NLI-style entailment (judge given answer (A) first).
Mechanisms and constraints#
- Conceptual distinction (interview framing, not a formal theorem): “relevant but insufficient” can exist; guests argue sufficient information should be relevant, but the paper does not prove a partial order “sufficient ⇒ relevant.” Speaker view.
- In Table 1, TRUE-NLI (T5 11B) shows high precision, low recall, consistent with “entailment ⇒ sufficient, converse does not hold” (literature).
How to (minimal example)#
Use an LLM as a binary autorater (paper Table 1: Gemini 1.5 Pro 0/1-shot; large-scale labeling: FLAMe-RM-24B):
Given question Q and retrieved context C only:
Does there exist an answer A' that Q can be reasonably answered from C alone?
Reply: sufficient | insufficient
Do not treat “does C contain the GT string” as the only rule: paper Contains GT accuracy is 0.809, still below Gemini 1-shot 0.930 (Table 1).
Common pitfalls#
- Replacing sufficiency labels with embedding similarity thresholds.
- Using RAGAS
context_precisionas a proxy for “enough to answer.”
Gold-label autorater and main experimental datasets#
Why#
To evaluate whether an autorater is reliable, you need a small human gold set, then analyze model behavior on large-scale retrieved contexts.
Mechanisms and constraints#
- Gold set (§3.2): 115 ((query, context)) pairs, expert-labeled sufficient / insufficient; drawn from PopQA, FreshQA, Natural Questions, EntityQuestions—not HotpotQA / MuSiQue (those appear in §4 main experiments). If the interview mixes dataset names, trust the paper.
- Main evaluation (§4.1): FreshQA (True Premise, 452), Musique-Ans (dev 500), HotpotQA (dev 500); retrieval pipeline FlashRAG + REPLUG +
intfloat/e5-base-v2. - Table 1 (115 gold pairs): Gemini 1.5 Pro 1-shot F1 0.935 / Acc 0.930; 0-shot 0.878 / 0.870; FLAMe-24B 0.892 / 0.878. Podcast “80–90%” sits in range but is conservative; prefer 87–93%.
How to (minimal example)#
Before stratified stats, fix the autorater (paper main analysis: Gemini 1-shot), then slice by sufficient / insufficient into Correct / Abstain / Hallucinate (LLMEval semantic correctness, not pure string match; see Appendix B.3).
Common pitfalls#
- Assuming the gold set matches HotpotQA distribution—the 115 pairs and 500-pair dev analyses are separate constructions.
- Using prompts that include ground-truth answer as production default (Table 1 shows gains but still below answer-free Gemini 1-shot).
Correct despite insufficiency: parametric knowledge and RAG coupling#
Why#
If “insufficient ⇒ should abstain or re-retrieve,” you assume the model will not fill gaps from pretraining—the paper shows that assumption fails.
Mechanisms and constraints#
- 35–62% (abstract): SOTA LLMs still output correct answers under insufficient context (literature, §4.3).
- Table 2 qualitatively: much of this comes from questions the model could already answer closed-book—retrieved chunks are not enough alone, but parametric knowledge carries the answer.
- Counterintuitive (literature): when the model cannot answer without context, injecting still-insufficient context sometimes “unlocks” the correct answer (emphasized in interview; mechanism open).
How to (minimal example)#
Per query, log the quadruple: (sufficient_label, rag_context, model_answer, llm_eval_correct), and report insufficient ∧ correct separately—do not mix with overall accuracy.
Common pitfalls#
- Forcing second retrieval when insufficient share is high—you may remove samples already answered via parametric knowledge.
- Equating “correct” with “faithfully used context.”

RAG hurts abstention: more retrieval, less willingness to say “I don’t know”#
Why#
Engineering intuition says RAG reduces hallucination; paper §4.2 is titled Models Abstain Less with RAG: adding context makes models less willing to abstain; hallucinations rise relatively on the insufficient subset.
Mechanisms and constraints#
- Gemma 2 27B (
gemma-2-27b-it) on HotpotQA (Figure 6, stacked bars): Without RAG — Correct 65.2% / Abstain 24.8% / Hallucinate 10.0%; With RAG, insufficient — 37.9% / 11.9% / Hallucinate 50.2% (literature). - Podcast “~66% hallucination after adding retrieval” does not align precisely with paper figures; closest misread is hearing 64.1% correct (sufficient + RAG) as hallucination rate. Unverified boundary: without slides, use Figure 6 numbers.
- Claude et al.: abstain 84.1% without RAG → 52% with RAG (§4.2, literature).
How to (minimal example)#
Compare three curves per model: no_rag, rag_sufficient, rag_insufficient; report abstain rate and hallucinate rate separately (paper uses LLMEval pipeline).
Common pitfalls#
- Assuming risk drops when retrieval hits GT chunks—abstain can rise on sufficient subsets; insufficient subsets may still hallucinate heavily.
- Training only “answer when you see context,” not “say you don’t know when context is inadequate.”
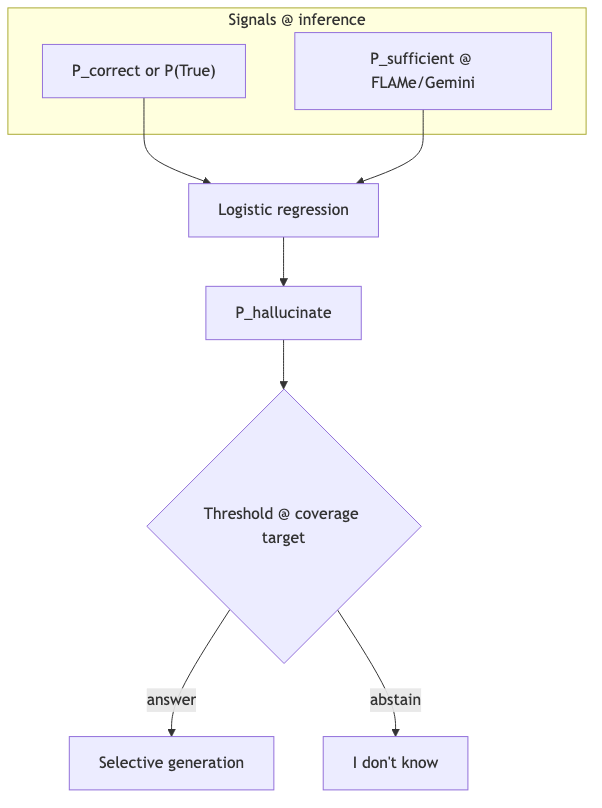
Selective generation: do not gate on P(sufficient) alone#
Why#
The team once considered using a sufficient-context rater to decide abstention; §5.1 states this heavy-handed approach lowers overall performance because it cuts “insufficient but correct” samples.
Mechanisms and constraints#
- P(True): Kadavath et al. — multiple samples then self-evaluate (costly for open models).
- P(Correct): ask directly for “most likely answer + probability” (proprietary models, literature §5.1).
- Sufficient signal: binary autorater (experiments use FLAMe, 1600-token chunks; any chunk sufficient ⇒ overall sufficient).
- Combination: logistic regression with self-eval probabilities to predict hallucination, then threshold—not standalone P(sufficient) gating.
- Gain (vs. confidence only): HotpotQA Gemma 27B >10% in the highest-accuracy region; Gemini 1.5 Pro >5% around 70% coverage (literature Figure 4). Abstract also reports 2–10% correct share improvement on the actually-answered subset.
- Coverage = share of queries not abstained; Selective accuracy = correctness on the answered subset—do not conflate with recall@k or pass@k.
How to (minimal example)#
# Concept: fit offline, apply same threshold online to control coverage
# features: [logit_p_correct, logit_p_sufficient, optional_bias]
# label: hallucinate per LLMEval on (Q, C, model_answer)
On Musique, Gemma’s sufficient coefficient can be 0 (gain vanishes)—combined signals are dataset-dependent (literature).
Common pitfalls#
- Abstaining or re-retrieving when
P(sufficient) < τ. - Reporting only full accuracy, not coverage–selective accuracy curves.
Context length, concatenation, and “engineering-layer” context#
Why#
As long-context windows spread, a common claim is “skip RAG, stuff the whole corpus once.” Paper Figure 2 and the interview offer partial counterevidence and extensions.
Mechanisms and constraints#
- Paper experiments (Figure 2): retrieved context capped at 2000 / 6000 / 10000 tokens; 2000→6000 yields modest sufficient-share shifts (e.g., Musique 33.4% → 44.6%), 6000→10000 nearly flat; later work fixes 6000 tokens (literature).
- Lost in the middle: Liu et al., TACL 2024 cited; this paper does not report “gold answer in middle vs. ends of context” ablations—podcast points on chunk concatenation, metadata volume, harder human sufficiency labeling are speaker view / experiential extension.
- Contradictory evidence: guests tend to label insufficient when retrieved chunks contradict each other; conflict with model parametric knowledge is another layer (pretrain/finetune). Speaker view.
- Context engineering: after relevance, assembling fragments into a usable whole (disambiguation, consistency)—alongside Graph RAG and reranking, not replacing recall (speaker view).
How to (minimal example)#
Under a 6k token budget, run truncation experiments: compare sufficient share and downstream selective accuracy, rather than blindly maxing the window.
Common pitfalls#
- “Bigger window is always better,” ignoring irrelevant context increasing hallucination (Related Work cites noise literature; main experiments here stratify by sufficient/insufficient, not a dedicated “irrelevant chunk” control).
- Attributing interview position-effect experiments to Joren et al. 2025 main text.

Teaching models to refuse: SFT/LoRA vs. product reranking focus#
Why#
If selective generation is still insufficient, the natural question is whether SFT can produce reliable “I don’t know.” Paper Table 3 and Vertex product docs give partial answers and boundaries.
Mechanisms and constraints#
- Mistral-7B-Instruct-v0.3 + LoRA (rank 4, alpha 8): mix “I don’t know” with normal answers—%Correct can rise, %Abstain stays very low (literature). Interview says Mixtral; use paper model names.
- Interview: 100% “I don’t know” samples can work, but mixed ratios vs. abstention are nonlinear (speaker view); DPO/GRPO room for uncertainty calibration—not in this paper’s experiments.
- Vertex AI RAG Engine reranking: semantic reranker and LLM reranker (Gemini scores chunk–query relevance). Docs do not mention sufficient context as a ranking objective.
- Paper §6 Future Work: fine-grained sufficient autorater for ranking after retrieval—research direction, not verified product behavior. Guests describe Google collaboration wiring sufficiency into re-rankers (speaker view; not verifiable in public docs).
How to (minimal example)#
Product side: LLM reranker after multi-path recall to compress top-k; evaluation side: Table 1–grade autorater offline labels insufficient share to drive recourse (web search, human, stronger model), not a single abstain gate.
Common pitfalls#
- Assuming Vertex sorts by sufficiency by default.
- Using one LoRA run to dismiss all retrieval-aware fine-tuning (paper does not test RAFT etc.; host’s Frankenstein RAG vs. joint training is interview contrast, not a paper conclusion).
Evaluation ecosystem: alongside RAGAS, ARES, and active retrieval#
| Method | Relation to sufficiency |
|---|---|
| RAGAS | Multi-dimensional LLM-judge; no same-named sufficient label |
| ARES | Compiled judges: context relevance, faithfulness, answer relevance |
| FLARE | Low-confidence tokens trigger forward-looking re-retrieval |
| FLAMe | 24B-class autorater; cost between Gemini and human labeling |
Speaker view: next step could be a large sufficiency dataset and fine-tuned judge à la RAGAS; production logs labeled insufficient can trigger recourse—corpus edits, human adjudication, expensive retrieval—alongside “change the model only.”
If you want to ship this#
- Offline: run Gemini 1-shot or FLAMe sufficiency labels on ((Q,C)) from your logs; report insufficient ∧ correct separately before choosing recourse—avoid a single global abstain threshold.
- Online selective generation: collect P(Correct) (or P(True) for open models) and P(sufficient); fit hallucination with logistic regression; tune thresholds to target coverage and plot selective accuracy curves.
- Retrieval budget: prioritize truncation and reranking experiments around ~6k tokens (align Figure 2) before jumping to 10k+.
- Refusal training: if SFT on “I don’t know,” expect Table 3—accuracy may rise while abstain does not recover; design preference learning or retrieval-aware training separately and measure abstain on its own.
- Product reranking: Vertex-style LLM reranker docs describe relevance; treating sufficiency in ranking as paper Future Work + custom pipeline—validate on a gold subset before launch.
References and further reading#
- Sufficient Context (arXiv:2411.06037) — definitions, Tables 1–4, Figures 2/4/6
- arXiv PDF (2411.06037) — verifiable copy of tables and figures
- RAG original framework (Lewis et al., 2020)
- RAGAS available metrics documentation
- ARES: Automated Evaluation Framework
- P(True) / language model self-evaluation calibration
- FLAMe: Foundational Autoraters
- FLARE: Active Retrieval Augmented Generation
- Lost in the Middle (Liu et al., 2024)
- HotpotQA · MuSiQue
- Vertex AI RAG: Retrieval and ranking
- RAFT: Retrieval-Augmented Fine-Tuning — retrieval-aware fine-tuning direction cited in interview
- Weaviate docs: RAG and vector search — vector-store engineering background (not tied to the paper)
- DBLP: Joren et al., ICLR 2025 — bibliographic record
Editorial note: the paper states publication at ICLR 2025; if arXiv v2 and OpenReview camera-ready differ, prefer the published PDF. Where podcast numbers disagree with figures, the body labels literature / speaker view / unverified.


