
Software Engineering Agents on Real Repositories: SWE-Bench and the Debate Over Evaluation Scaffolding#
As RAG and agent discussions shift from “can it solve LeetCode?” to “can it fix production bugs?”, the evaluation target changes too: no longer single-function pass rates, but GitHub issue → patch → do project tests turn green? SWE-bench, from Princeton and Stanford first-author teams, crystallizes that chain into a reproducible benchmark; companion SWE-agent pushes the debate onto Agent-Computer Interface (ACI)—how much “intelligence” to leave to the LM versus symbolic scaffolding between model and codebase.
Below, mechanisms, evidence boundaries, and still-competing approaches are organized by engineering theme; podcast narration is not treated as the sole source of truth—what official docs and papers can verify is separated from “speaker opinion”.
Evaluation target: from synthetic problems to PR-driven resolved#
Why#
HumanEval-style benchmarks measure isolated functions with unit-test pass rates; real engineering adds cross-file localization, environment dependencies, and regression risk. If agent products optimize only on such metrics, they can still fail in production with “fix one issue, break ten tests.”
Mechanisms and constraints#
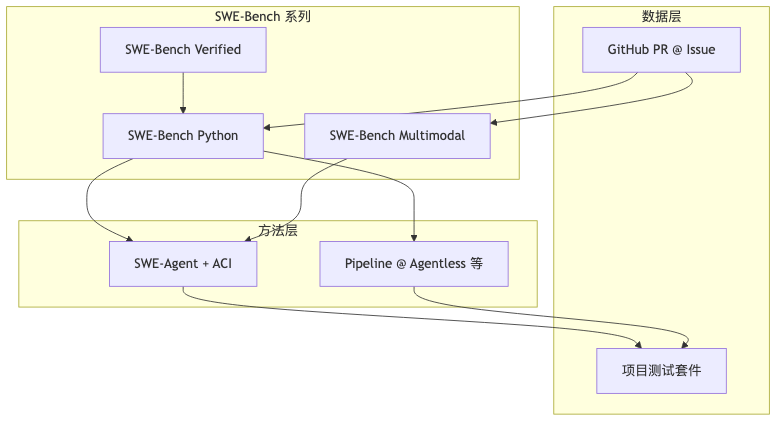
The SWE-bench paper abstract states: 2,294 real GitHub issues and pull requests from 12 popular Python repositories; the model task is editing the codebase to address the issue; acceptance relies on unit test verification, with post-merge PR behavior as reference. The official original page further describes the pipeline: crawl PRs/issues → build Docker images → run Fail-to-Pass and related tests on submitted patches → judge resolved.
The primary metric is resolution rate (share of submissions successfully resolved), not retrieval MRR; SWE-agent reports pass@1 = 12.5% on SWE-bench (verifiable on the abstract page). Different subsets (Full / Lite / Verified / Multimodal) differ in denominator and difficulty—do not compare percentages across splits without naming them.
How to do it (minimal example)#
# Conceptual flow: Docker required locally; exact CLI per swebench docs
# 1) Get instance: repo + base_commit + problem_statement
# 2) Model produces unified diff / patch
# 3) Harness applies patch in container → runs FAIL_TO_PASS tests
# 4) All green → resolved
The Hugging Face dataset card provides Oracle and BM25 retrieval settings, corresponding to SWE-bench_bm25_* derivatives—the original paper already included retrieval baselines, not only “end-to-end guess the file.”
Common pitfalls#
- Treating leaderboard pass@1-style resolved rates as “can replace mid-level engineers”—absolute scores remain low, and subset curation differs.
- Ignoring FAIL_TO_PASS / PASS_TO_PASS semantics: resolved means fix under test contract, not product acceptance or subjective UI correctness.
- Assuming the name SWE implies Java, mobile, or ops scripts; speaker opinion: current series covers only part of repositories and engineering activity—Multimodal systematically extends to JavaScript / visual UI (617 instances, 17 JS libraries per paper abstract).

Agent loop vs pipeline: control and the generalization tax#
Why#
In engineering, “agent” often means the LM decides each step whether to call tools and whether to stop; another route hard-codes localization → search → edit, with AST, vector stores, or class/function inventories doing part of navigation for the model. Both compete for the same budget: dollars per instance, whether Docker is required, whether scaffolding must be rewritten when changing language.
Mechanisms and constraints#
| Dimension | Agent (e.g. SWE-agent) | Pipeline / compound-style (Agentless, AlphaCodium-class) |
|---|---|---|
| Control flow | Model-driven tool calls and stopping | Preset stages, more symbolic steps |
| Codebase representation | Simpler interface, LM self-navigates | Preprocessed NL summaries, vector indexes, symbol tables |
| Execution environment | Usually needs Docker, runnable tests | Many schemes weaken or omit online execution |
| Generalization | Speaker opinion: more general but costlier, heavier ops | Speaker opinion: often strong on Python SWE-bench, brittle on JS/React |
SWE-bench Multimodal abstract gives one comparison: SWE-agent ~12% resolved, next best ~6% (specific experimental setup). Speaker opinion (John Yang): under the same bash/CLI interaction, the agent is still relatively best on Multimodal, but absolute scores stay below Python SWE-bench—“interface is general” ≠ “task is solved.”
No single winner: an explicit trade-off between LM capability vs scaffold responsibility; Multimodal emphasizes parsers tuned for Python OOP may systematically fail on React hooks / functional code—the heavier symbolic scaffolding, the more likely a domain change forces a rewrite (speaker opinion, aligned with the paper’s “harder across languages” direction).
How to do it (minimal example)#
# Agent route (conceptual)
while not done:
obs = env.run(last_tool_output) # test logs, file snippets, search summaries
action = lm.choose_tool(obs) # edit | search | run_tests | finish
env.execute(action)
# Pipeline route (conceptual)
files = bm25_or_ast_localize(issue_text)
patch = lm.edit_only(files) # often no online test loop
Common pitfalls#
- Inferring “pipeline universally beats agent” from high Python subset scores—may overfit BM25 + fixed file set settings.
- Treating “no Docker” as a permanent advantage—official evaluation still centers on in-container tests; pipeline “no execution” is not the same as a reproducible leaderboard.
- Opposing compound AI systems (fixed graph: retrieve → rerank → edit) and ReAct-style agents as ideology; both are composable engineering choices.


Retrieval, long context, and “whole-repo input”#
Why#
Issue text often fails to point at the right file; either retrieve to shrink context, or use long context to swallow more files. When long windows became practical around 2023, there was no coding benchmark for “truly eating the whole repo”; the team tried giving the entire codebase to the LM to fix bugs (speaker opinion, Carlos E. Jimenez).
Mechanisms and constraints#
SWE-bench’s first version included a BM25 retrieval baseline in the paper and HF README—speaker opinion (John Yang): that was the “fastest path to a working run”; finer retrieval/symbolic structure was deferred to SWE-agent.
Parallel explorations still coexist on the leaderboard: file-by-file long context, vector-store schemas, agent-native grep/search (ACI-specific search commands). They trade off context budget, ambiguous empty results, false-positive files differently; unsettled, no public conclusion that one dominates “all splits, all models.”
How to do it (minimal example)#
# BM25 retrieval + edit (conceptual, aligned with HF derivatives)
candidates = bm25_index.query(issue.title + issue.body, top_k=20)
context = "\n".join(read_file(f) for f in candidates)
patch = llm.generate_patch(context, issue)
Common pitfalls#
- Assuming “128K context = no retrieval needed”—cost, attention dilution, and irrelevant file noise can still crush pass@1.
- Optimizing only the embedding model without validating patches on FAIL_TO_PASS—retrieval MRR decouples from resolved.
- Speaker opinion (host raised, guests did not refute but no controlled experiment): richer docstrings / repo metadata sometimes beat changing the agent—worth ablation, not proven fact.

ACI: tool output shape caps the agent ceiling#
Why#
The same LM can change resolved rates sharply when the interaction surface changes. SWE-agent’s core claim is a tailored Agent-Computer Interface: let the model smoothly read files, search code, and run tests—not dump raw shell output into context without bound.
Mechanisms and constraints#
SWE-agent ACI docs (verifiable) highlights include:
- Dedicated search command: list only file paths with matches, avoiding spam.
- File viewer: ~100 lines per turn; docs state showing more match context confuses the model.
- Compared to bare
grep/bash, emphasize summarized search results.
Speaker opinion (John Yang): tried paginated grep hits; by page 37 context was full without added signal—paged browsing worse than one-shot summary (design narrative; no quantitative A/B from the podcast; mechanism per ACI docs and paper).
How to do it (minimal example)#
# Anti-pattern: dump 500 lines of grep raw into prompt
# Better: tool returns "path + line summary + optional local snippet"
search("TypeError.*NoneType") →
src/foo.py:42-48 (snippet)
tests/test_foo.py:10 (snippet)
Common pitfalls#
- Stacking more tools (GDB, browser, K8s) without observation compression—CTF agents and SWE-agent’s initial tool sets differ; speaker opinion from John’s InterCode / CTF experience.
- Assuming “language agnostic” means “zero inductive bias”—bash interfaces can still hurt on Windows/C# repos.

Evaluation infrastructure: Docker, Verified, and trust in numbers#
Why#
Leaderboard resolved rates implicitly mean “patch ran tests in what environment?” Environment drift, missing deps, and flaky tests mix model ability with harness defects.
Mechanisms and constraints#
SWE-bench GitHub README timeline (verifiable):
- 2024-06-27: with OpenAI Preparedness, migrate to fully containerized evaluation harness using Docker.
- 2024-08-13: release SWE-bench Verified—500 tasks, engineer-reviewed descriptions, tests, and solvability (verified page).
Evaluation guide treats Docker as a requirement for current evaluation.
Speaker opinion (John Yang): claims realizing only in January 2025 that early “existing CI is enough to reproduce” was wrong, and containerization had to be strengthened with OpenAI for Verified—this conflicts in time with official mid-2024 containerization announcement; safer wording: reflection on early non-container practice, or reinforcement for Multimodal/JS environments—not “Docker evaluation introduced only January 2025.”
Speaker opinion: Verified’s Docker sandbox engineering matters as much as 500 human-curated examples, but the former spreads less on Twitter. Sandbox limits: browser rendering, headless Chrome, some capabilities unavailable in sandbox—leaderboard numbers depend on underlying setup (aligned with Multimodal paper adding Node.js, Chrome, Xvfb).
Unverifiable: John’s oral “single-instance Docker image max ~10 GB”—Multimodal paper/HF/official site lack per-image size tables; official guidance suggests evaluation machines with ~120 GB disk (full image corpus scale); do not treat narration as a hard upper bound.
How to do it (minimal example)#
# Pre-submit self-check (conceptual)
docker info
# Build/pull repo@commit images per SWE-bench docs
# When using sb-cli / Modal cloud eval, verify split name and harness version
Common pitfalls#
- Reporting Verified 500 scores while training retrieval indexes on Full—data leakage risk depends on project policy; podcast did not expand.
- “Patch looks reasonable” locally without sandbox tests—does not match resolved definition.
- Ignoring PyPI-oriented collection (collect README) vs Node/frontend ecosystems—Multimodal fills that gap.


Multimodal and “seeing the UI”: Xvfb, Computer Use, and domain transfer#
Why#
Many frontend bugs accept pixels/layout/interaction; issue text has no screenshot. Multimodal brings visual, user-facing JavaScript under the same resolved contract.
Mechanisms and constraints#
Multimodal paper describes: add Node.js, Chrome on SWE-bench Docker; Xvfb for display, xwd screenshots; SWE-agent M adds browser/image tools.
Speaker opinion (Carlos E. Jimenez): “same class” as Anthropic Computer Use—no SWE-bench official doc establishes product-level equivalence; Xvfb + browser infra has paper support; the analogy itself is unproven.
Speaker opinion: containerization + agents not resident on the host machine will become normal—security and reproducibility over “fully local automation”; official push for Docker/cloud eval (Modal, sb-cli), not literal “ban local development.”
How to do it (minimal example)#
# Conceptual loop: headless display in container → screenshot → model → patch → visual/unit tests
Xvfb :99 → open PR repro steps → screenshot → VLM → edit JS/TS → npm test
Common pitfalls#
- Reading Multimodal 12% vs 6% as “multimodal near human”—absolute scores remain low; HF split totals 612 (102 dev + 510 test) vs paper 617 vs site 517 “with visual elements”—cite sources explicitly.
- Fine-tuning Python pipeline prompts and expecting zero-change transfer to React hooks—matches guest warning to tear down Python-specific scaffolds.

sequenceDiagram
participant I as Issue @ screenshot clues
participant A as SWE-Agent M
participant X as Xvfb @ Chrome
participant H as Harness
I --> A
A --> X: reproduce UI
X --> A: pixel observations
A --> H: patch
H --> H: FAIL_TO_PASS + visual tests
Human in the loop: autonomous bugfix vs collaborative copilot#
Why#
Production accountability stays with people; “fully automatic merge” and “daemon that only summarizes stack traces” are different product promises.
Mechanisms and constraints#
Speaker opinion (John Yang, ReAct lineage): some want to direct the agent step by step, others want the agent to suggest while humans write; near-term answers vary by scenario. “Eventually everything is agentic” coexists in the same conversation with “collaboration is highly scenario-specific”—tension unresolved.
Monitoring/diagnostic daemons: not necessarily auto-editing code (speaker opinion), avoiding unattended patches nobody owns.
How to do it (minimal example)#
# Tiered rollout
L0: read-only — summarize trace, hypothesize root cause, list likely files
L1: suggested patch — human review then apply
L2: auto PR — tests green required + human approve + rollback plan
Common pitfalls#
- Selling SWE-bench resolved as “unattended on-call”—benchmark excludes on-call rotation, incident comms, cross-team coordination.
- Ignoring cost: speaker opinion SWE-agent ~$2+ per fix, pipeline
$0.4–0.5 or lower (leaderboard experience at the time)—no official fixed price; leaderboard JSON shows per-instance **$0.19–$3+** variance by model and steps (not verifiable as constants).

If you are shipping this#
- Pin the evaluation contract first: choose split (Full / Verified / Multimodal), harness version, and Docker capability; use the evaluation guide to understand resolved—do not substitute retrieval metrics.
- Make an explicit agent vs pipeline trade-off table: need online tests?, per-run dollar cap?, is target language Python-only?; when moving to JS/frontend, plan to remove Python-specific parsers (Multimodal lesson).
- Invest in ACI before stacking models: output shape for search/read-file beats another 405B; align with ACI docs for summarized tool returns.
- Treat environment as first-class: align with official 2024-06 containerization timeline; if you hear “Docker only in 2025”, use README for internal postmortem, not external marketing.
- Tier human-in-the-loop in the product: from read-only diagnosis to auto PR; regress on Verified subset before chasing Full scores.
References and further reading#
- SWE-bench paper (arXiv:2310.06770) — task definition, 2,294 instances, test acceptance
- SWE-bench OpenReview (ICLR 2024) — venue and review info
- SWE-bench site and leaderboard — subsets and submission
- SWE-bench original (original.html) — data collection and Fail-to-Pass
- SWE-bench Verified — 500 human-reviewed subset
- SWE-bench GitHub README — Docker migration and Verified timeline
- SWE-bench evaluation guide — Docker requirements and resolution metric
- Hugging Face: princeton-nlp/SWE-bench — Oracle / BM25 settings
- SWE-agent paper (arXiv:2405.15793) — ACI and pass@1 12.5%
- SWE-agent ACI design doc — search and file viewer constraints
- SWE-bench Multimodal paper — JS, visual tests, Xvfb
- Hugging Face: SWE-bench_Multimodal — public splits and fields
- OpenAI: Introducing SWE-bench Verified — OpenAI collaboration context (HTTP availability may vary)
- Berkeley BAIR: Compound AI Systems — pipeline-style multi-component framing
- ReAct paper (arXiv:2210.03629) — reasoning-and-action agent lineage
- Anthropic: Computer Use docs — independent read for Multimodal analogy


