
Synthetic Data: Boundaries of Data Fabrication in RAG, Agents, and Evaluation#
Vector stores, retrieval agents, and offline evaluation sets all eventually run into the same engineering question: when real labels are scarce, privacy-bound, or long-tail sparse, what mechanism should you use to fill the gap—and is the distribution you synthesize worth trusting? In the Hugging Face / Argilla ecosystem, distilabel, the Synthetic Data Generator (SDG), Persona, DEITA, and related research lines discuss LLM-driven synthetic data pipelines—from instruction augmentation to preferences to queryable datasets on the Hub. Visual material is a three-way remote interview; no readable architecture diagrams or results tables appear on screen; quantitative claims and API behavior below follow papers, dataset cards, and official documentation unless marked as speaker view.

Problem space: where synthetic data sits in the stack#
Why: RAG needs query–passage–answer or chunk-level labels; agents need tool traces, multi-turn dialogue, failure recovery samples; evaluation needs held-out, reproducible input variants. Real logs often carry PII, skewed distributions, or simply lack a “gold answer.” Synthetic data is often framed as the LLM version of data augmentation (Ben’s opening formulation—speaker view), but in engineering you must at least separate: are you augmenting a training set, rewriting evaluation inputs, or distilling another model’s behavior?
Mechanisms/constraints: David proposes a four-layer taxonomy—augmentation, effective prompting, reformation/rewriting, distillation/synthesis (completions on a model or domain distillation)—guest framework, not an industry-standard taxonomy. This aligns with the Llama 3.1 Model Card narrative of “25M+ synthetically generated” in the fine-tuning stage and LLM-based classifiers for data filtering: synthesis + filtering is already in mainstream release pipelines, but that does not mean pre-training corpora are predominantly synthetic (partially verifiable).
Common pitfall: equating “synthetic” with “ask GPT to generate a few more rows”; stacking volume without defining a target distribution (SFT / DPO / RAG retrieval eval) often hits a quality wall at scale—David says 10-row trial runs look fine; ~100 rows often force pipeline changes or a larger model (speaker view, not a universal threshold). For RAG, synthesizing queries without touching chunk boundaries and citation constraints can inflate eval scores: the model may learn the question distribution, not whether the index recalls the right passage—split retrieval hit rate from generation faithfulness.
Post-training shapes: instruction, preference, and critique#
Why: Self-Instruct expands 175 seed instructions via rewriting to ~52k instructions, then uses the GPT-3 API (paper wording; colloquially “ChatGPT”) for completions before SFT—scale figures match the README. Later, UltraFeedback starts from existing prompts, has multiple models each produce several responses, then GPT-4 gives fine-grained feedback—flow verified.
Mechanisms/constraints: David summarizes post-training data as an instructions → preferences → critiques pipeline (speaker synthesis). UltraFeedback’s official four dimensions are instruction-following, truthfulness, honesty, helpfulness; guests once listed helpfulness, conciseness, effectiveness—helpfulness overlaps; the latter two have no official one-to-one mapping; when writing, prefer the UltraFeedback README.
How to proceed (minimal): fix a seed prompt set → multi-model sample completions → judge (GPT-4 or local classifier) scores per dimension → export preference pairs for TRL DPO/ORPO.
Common pitfall: “more preference data is always better”; David suggests taking the difference in helpfulness (etc.) between two completions—pairs with too small a gap should not enter DPO (speaker heuristic, not an UltraFeedback official rule)—near-ties the model cannot learn waste budget.


Persona-driven synthesis: diversity, not a knowledge carrier#
Why: Persona Hub (correct ID: 2406.20094, not the mistaken 2407.17308 link) extracts Text-to-Persona from the web, then Persona-to-Persona generates related personas (e.g., clerk → customer) and conditionally generates instruction–response pairs; the paper claims up to billion-scale persona coverage (abstract). Ben stresses: ~50-word persona descriptions cannot replace extractable domain knowledge; they mainly add variety; the same long document + different personas can shift instruction/response distributions (speaker view).
Mechanisms/constraints: the paper treats persona as a distributed lens on knowledge; guests emphasize variety and covering low-exposure sections of a document (asking the same doc for QA directly tends to stick to popular passages—speaker view). Hold both tensions side by side rather than picking one. Deduplication: the Persona Hub paper states embedding cosine similarity > 0.9 filtering plus MinHash threshold 0.9—verified.
Persona-to-persona is not “vector crossover”: the host once analogized crossing two personas in a batch; David clarifies it is one persona as seed, LLM generates the interaction partner, consistent with the paper’s Persona-to-Persona interpersonal relationships—literature/interview aligned.
How to proceed (minimal): pick a corpus (e.g., RedPajama v2 or fineweb-edu) → distilabel Text-to-Persona → conditional QA generation → embedding dedup → push to Hub. Ben’s example: on Weaviate docs, an LM can synthesize structure such as schema from unstructured content (speaker view)—this does not contradict “persona does not supply domain knowledge”: knowledge still comes from the document; persona only changes who is asking and from what angle.
Common pitfall: assuming persona-guided synthesis will unify all synthetic paths. Ben denies; paraphrase, keyword injection, and raw seeds still coexist (speaker view). Paraphrase eval sets skew toward robustness testing; training-side diversity can come from Persona Hub and similar mechanisms, not only rewriting eval inputs (speaker view).

argilla/FinePersonas-v0.1 generates ~21 million personas on fineweb-edu, tagged distilabel; clustering subset FinePersonas-v0.1-clustering-100k offers 177 clusters for enterprises to pick personas by theme—dataset card verifiable; “engineering cluster” is a usage example (speaker view).
Pipeline engineering: distilabel, caching, and stateful execution#
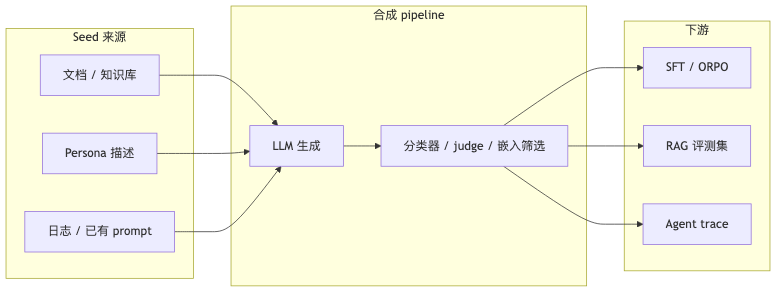
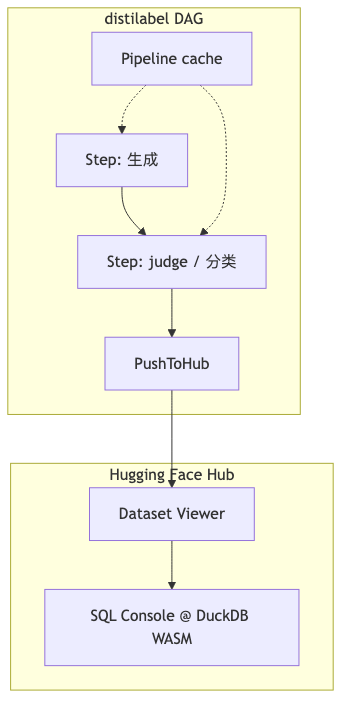
Why: synthetic pipelines are often DAGs: generate → score → filter → write Hub; restarting from scratch on mid-run failure is unacceptable cost.
Mechanisms/constraints: distilabel docs support Ray scheduling vLLM (including tensor_parallel_size), PushToHub streaming rows to disk—components verified. Navigation includes Pipeline cache; “cache keyed by pipeline config parameters, resume from last step on failure” is guest description—parameter-key wording not located in accessible doc body this pass; check source or release notes. Weaviate Transformation Agent stresses workflow persistence, resume from step N on failure (host product narrative—speaker/host view), a different durability model from distilabel’s DAG cache—choose based on cross-session, cross-service orchestration needs.
How to proceed (minimal):
# Conceptual sketch: distilabel Step chain + PushToHub (API per official docs)
from distilabel.pipeline import Pipeline
# pipeline.add_step(...).add_step(PushToHub(repo_id="org/synth-rag-v1"))
# pipeline.run(parameters={"num_rows": 1000})
SDG README defaults MAX_NUM_ROWS=1000; task types include Text Classification, SFT, RAG—verified. Guests say 500–1000 rows is enough to start trial runs (speaker view; 500 is not the doc default).
Common pitfall: a smooth small demo does not imply linear scale to tens of thousands (see 10 vs 100 rows above). Also: the SDG repo notes maintenance focus has shifted to aisheets—product lifecycle, without changing the fact it was distilabel + Gradio-based.

Ben’s practice: DSPy offline prompt optimization, then freeze into distilabel; deep in-library integration “light enough to skip” (speaker engineering trade-off). distilabel stresses reproducible fixed prompts; DSPy suits consistency optimization across APIs and models—orthogonal to DSPy program-level optimization narrative; composable, not mutually exclusive.
Quality and diversity: DEITA, classifiers, and “weak end-to-end, strong parts”#
Why: after synthetic row counts explode, quality, complexity, and diversity often conflict; feeding everything into SFT/DPO is not always optimal.
Mechanisms/constraints: DEITA (correct ID: 2312.15685) ranks on a complexity × quality scalar (paper evol score (s = q \times c)), then Repr Filter preserves diversity in representation space (threshold τ in appendix ~0.8–0.9)—verified; interview “2D mapping” is a semantic approximation, not strict wording. Ben says WizardLM end-to-end is not a strong role model, but prompt evolution, embedding diversity filtering, and similar steps are reused in later work (speaker assessment); DEITA README shows DEITA-7B beating WizardLM-13B on some metrics under a 6K SFT data budget—“not strong” needs benchmark and data-volume context, not blanket inferiority.
HF trains educational-content classifiers for SmolLM2 etc. (0=commercial, etc., 1=textbook-grade)—David says heavier than pure entropy/diversity (speaker view). SDG iteration uses whether downstream fine-tune improves to validate pipeline usefulness (speaker practice); causality needs controlled experiment design.
Common pitfall: rejecting an entire method chain from one benchmark score; ignoring reusable stepwise tricks. Image preference pipeline (LMSYS-style prompt → complexity evolution → FLUX dual images → Argilla binary choice → ~15k rows → DPO/ORPO) is guest project narrative; visible Hub repo metadata today is n<1K, README placeholder—~15k not confirmed on public cards; cite with unverified boundary. Mid-run NSFW in prompts and generated images needs preference + safety classifier + human sweep (speaker project lesson).
Hub data stack: from generation to SQL filtering#
Why: synthetic data that cannot be versioned, queried, and exported in training formats is just temporary JSON.
Mechanisms/constraints: HF Datasets Viewer SQL Console is driven by DuckDB WASM; filter from Data Studio and export Parquet/CSV—verified. David describes ~50k–100k row scale SQL for approximate nearest-neighbor-style vector retrieval; remote ANN index capability boundaries were as-of Hub at interview time (speaker view; 2026 changes not re-checked).
How to proceed: after generation PushToHub → open Data Studio → SQL filter (e.g., score_chosen - score_rejected > 0.3) → export for TRL / transformers / sentence-transformers training.
Common pitfall: treating SQL Console as production vector database; it excels at batch filtering and exploration, not online ANN service.


Unresolved conclusions: open disagreements#
| Topic | Common practice | Guest emphasis | Evidence boundary |
|---|---|---|---|
| Does persona carry knowledge? | Persona as “role-play” augmentation | variety > knowledge; document is knowledge seed | Tension with Persona Hub paper wording |
| Paraphrase | Rewrite eval sets for robustness | Training diversity also via Persona/keyword paths | Speaker view |
| Productizing prompt optimization | Online prompt edits inside agents | HF side favors self-trained models + owned data; Weaviate on RAG optimization as a service | Host/guest view |
| DSPy × distilabel | In-library integration | Offline optimization + versioned injection suffices | Speaker engineering trade-off |
| Synthetic for pre-train | Post-train only | Llama 3, SmolLM2, etc. already use synthetic + classifier filtering | Llama 3.1 card partially verified |
No need to force a single “best practice”; objective function (gains, coverage, safety, cost) should drive pipeline components. Agent-trace synthesis without structured tool name, arguments, and observations makes step-level attribution hard later; eval that only paraphrases user questions without changing tool availability and environment state mostly tests wording robustness, not planning—design separate dataset schemas rather than one JSONL template.
If you are shipping this#
- Write down seed types first: knowledge from documents/RAG corpus vs persona/paraphrase only for distribution spreading; when mixing, tag source in metadata for failure tracing.
- Use correct papers and official dimensions: UltraFeedback four feedback dimensions; Persona Hub and DEITA cite 2406.20094, 2312.15685.
- Validate small before scaling: 500–1000 rows (SDG default cap 1000) through distilabel DAG + Hub export, then use downstream task metrics (classification, RAG, SFT loss) before adding budget; drop preference pairs with too-small score gaps.
- Choose pipeline durability separately: cross-failure resume → stateful workflow (e.g., Transformation Agent path); reproducible, cacheable batch → distilabel + Ray/vLLM, cross-check Pipeline cache docs and version.
- Safety and dedup before publish: image/open-domain text synthesis assumes NSFW and near-duplicates will appear; Persona 0.9 threshold and DEITA Repr Filter are starting points, not finish lines.
References and further reading#
- Self-Instruct: Aligning Language Models with Self-Generated Instructions (arXiv:2212.10560)
- UltraFeedback: Boosting Language Models with High-Quality Feedback (arXiv:2310.01377)
- UltraFeedback official README (GPT-4 four-dimension labeling)
- Scaling Synthetic Data Creation with 1,000,000,000 Personas — Persona Hub (arXiv:2406.20094)
- What Makes Good Data for Alignment? — DEITA (arXiv:2312.15685)
- DEITA project README (includes WizardLM comparison table)
- distilabel documentation home
- distilabel: Ray and vLLM scaling guide
- Synthetic Data Generator announcement blog
- argilla/synthetic-data-generator Space
- FinePersonas v0.1 dataset card
- Hugging Face Hub: Datasets SQL Console (DuckDB WASM)
- Llama 3.1 Model Card (synthetic fine-tuning data and classifier filtering)
- ModernBERT paper (arXiv:2412.13663)
- TRL: preference optimization training docs


