
The Boundaries of Enterprise RAG: Managed Pipelines, Vector Stores, and Write-Back Retrieval#
Once foundation models cross the “can answer” threshold, what usually blocks enterprises is not training another 7B model but how private data enters the index, how retrieval picks the right store, and how generation trusts only the sources it should. Google packages that chain as the managed pipeline Vertex AI RAG Engine; Weaviate has long stood on the vector storage and data modeling side. Their integration in late 2024 through early 2025 pushes the debate past “whether to do RAG” toward harder questions: whether a single-corpus document index is enough, who owns parsing and chunking, and when RAG should become a bidirectional write-back loop.
What follows is organized by engineering theme: common practice → guest claims → verifiable evidence and unproven boundaries. No single conclusion is forced.

Managed RAG pipelines: why they exist and where they stop#
Why#
In-house RAG often reimplements the same pieces: data source connectors, chunking, embeddings, index lifecycle, retrieval APIs, and context assembly for generation models. That works at small team scale; as corpora grow and compliance and IAM tighten, operations and version lock-in—especially binding embeddings to the corpus—consume disproportionate effort. Official documentation describes RAG Engine as six steps: ingestion → transformation (including chunking) → embedding → indexing (corpus) → retrieval → generation; the default vector backend is managed RagManagedDb (Spanner-based), with optional Vector Search, Feature Store, Weaviate, Pinecone, and others.
Mechanisms and constraints#
- Not a DIY vector database: product positioning is orchestration, not replacing Weaviate/Pinecone as the database. (Supported by literature/documentation.)
- Corpus bound to embedding model lifecycle: documentation states “association between your embedding model and the RAG corpus remains fixed for the lifetime of your RAG corpus”—changing embeddings usually means rebuilding the index. (Supported by literature/documentation.)
- GA timeline: release notes record 2024-12-20 RAG Engine GA; the intro blog
datePublishedis 2025-01-10. Guests say the team started around “early 2024”—no matching official statement. (Interview claim vs. release notes.)

How to implement (minimal path)#
See the RAG quickstart. If you already run Weaviate, Use Weaviate with RAG requires a one-to-one mapping between CreateRagCorpus / UpdateRagCorpus and a collection, with API keys via Secret Manager; hybrid search and dense/sparse weight tuning are supported.
Common pitfalls#
- Treating RAG Engine as “another chatbot”—the launch blog stresses embedding it as a tool for the Gemini API in existing applications. (Supported by literature/documentation; “not a chatbot” is product positioning.)
- Assuming embedding swaps are a config change—plan for corpus rebuild per documentation.
- Equating “notebook in minutes” with production optimality: guests and docs both point to manual tuning (
chunk_size,chunk_overlap, etc.); there is no AutoML-style automatic hyperparameter search yet. (See P05 later.)

External vector stores: where Weaviate sits in the pipeline#
Why#
Customers already on open-source or self-managed Weaviate face high switching cost to a cloud vendor’s managed index. The integration goal is minimal application churn, preserved schema and hybrid capabilities, and extended ingestion/retrieval on the Vertex side. (Interview perspective; aligned with Google’s dedicated page.)
Mechanisms and constraints#
| Dimension | Documented fact | Interview tension |
|---|---|---|
| Integration shape | RAG corpus ↔ Weaviate collection 1:1; customer-managed instance + Secret | “Minimal code change” remains an experience claim, not zero-config |
| Maturity | Weaviate is Preview in the vector DB comparison table; updates are not instantly synchronized | Guests describe a “shipped integration” |
| Vector DBs on GA day | 2024-12-20 release notes list Vector Search + Pinecone, not Weaviate | Timeline gap should be explicit in architecture reviews |
How to implement#
Configure schema fields per use-weaviate-db (e.g. fileId, corpusId, chunkId, chunkData). Weaviate Shared Cloud on Marketplace addresses deployment subscription—it is not the RAG Engine connector itself.
Common pitfalls#
- Treating Preview as GA for SLA commitments.
- Ignoring the dual ops boundary: ingestion on Google’s side, vectors on the customer’s side.

; 2 3 oO = (no slide technical content).
Parsing and chunking: leverage in transformation, not only stacking rerankers#
Why#
Retrieval failures often come from semantically broken chunks, shredded tables, or lost heading hierarchy. One guest (Vertex PM) argues the largest lever for RAG quality today is parsing/chunking; reranking helps but is secondary. Another guest agrees parsing comes first and adds room to optimize re-indexing and embedding inference cost. (Interview opinions; Google has not published a written ranking of “parsing > rerank”.)
Mechanisms and constraints#
- Document AI layout parser: produces context-aware chunks from layout entities (headings, tables, lists).
- Reranking:
semantic-ranker-default@latestand LLM rerankers (Gemini relevance scoring) coexist—both are first-class official capabilities. - Tunable parameters: the embedding models page recommends
text-embedding-005by default; fine-tune transformations default to chunk_size 1024, overlap 256 (tokens). Guest claim of “90–95% quality, good enough first then optimize”—no official numbers. (Interview opinion.)
Anthropic Contextual Retrieval (2024-09-19) reports 49% fewer failed retrievals, 67% with reranking added—metric definitions and the Vertex layout parser cannot be numerically ported; Vertex documentation does not claim adoption of Anthropic’s scheme by the same name.
How to implement#
Enable the layout parser for PDFs and complex layouts; use fixed-size chunking for plain text first (GA release notes mention fixed-size + overlap). In evaluation, track retrieval failure rate and generation groundedness separately—do not mix Anthropic and Google stack benchmarks.
Common pitfalls#
- Deploying rerank before fixing parsing—opposite of guest priority and may inflate scores for wrong chunks.
- Treating contextual retrieval as Vertex’s default implementation—unverified.

wy is] 8 ® s.

oO 3 $ fe} oO =.
Single-corpus document model vs. enterprise multi-source reality#
Why#
Connor argues RAG Engine’s implicit model is close to “one search index + document chunks.” On the enterprise side you still have marketing spreadsheets, blogs, multiple Weaviate collections, and data-warehouse schemas side by side. (Interview opinion)
Mechanisms and constraints#
Semantic conflicts (e.g. Germany vs. Austria defining “lake/sea” differently) were traditionally pinned with schema constraints in ontology engineering; Bob argues prompt + vector retrieval can ease some ambiguity; Lewis counters that rule-style prompts pile up into “countless regexes”—precise control may still return to SQL / formal queries. (All speaker opinions.)
Lewis stresses multi-source RAG needs an intermediate reasoning stack / agentic flow for semantic mapping and pipeline choice (send everything vs. selective calls). That leaves an architecture gap vs. documentation’s single-corpus orchestration: you must build a router layer.
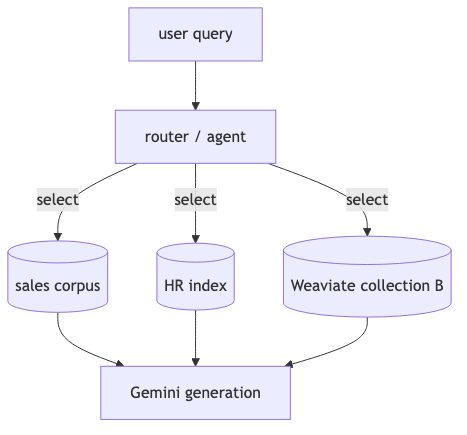
How to implement#
Create separate corpus/collection per business domain; implement intent classification + corpus routing in the application (or LangGraph / custom agent). Aligning ontology with warehouse schema remains open—do not assume RAG Engine automatically understands “table as ontology.”
Common pitfalls#
- Stuffing all tables into one corpus and expecting the model to infer joins.
- Replacing data governance with prompts—short-term effective, long-term maintenance may rival a rules engine.
One-way RAG vs. write-back: the naming gap around generative feedback#
Why#
Classic RAG: query → retrieve → generate → display—data flows one way. Bob proposes a generative feedback loop: outputs can update/delete/validate and write back to the vector store; collection-level instructions can reject, warn, or store corrected versions at ingest; Lewis links this to GAN-style dual-model critique and agent architectures. (Speaker opinions.)
Mechanisms and constraints#
Weaviate’s closest official capability is the Transformation Agent (Technical Preview; docs state “Do not use in production”): fetch → transform/enrich → write back, updating object properties in place. That is not fully the same mechanism as Bob’s ingest-gate generative feedback; the term generative feedback loops has no dedicated page found on docs.weaviate.io.
Vertex RAG Engine documentation focuses on retrieval-augmented generation and does not describe a standard path to write LLM outputs back into the corpus. For MDM (master data management): guests say ~70% automation by models would already be major progress; 100% is unrealistic—no document citation. (Interview opinion.)
How to implement#
For write-back: evaluate Weaviate’s Transformation Agent or a custom post-generate pipeline on the Weaviate side; on Vertex, still treat RAG Engine as the read path—design audit and versioning for writes separately.
Common pitfalls#
- Equating marketing generative feedback loops with GA product capability.
- Running Preview Agents in production without rollback strategy.

Y je} = re} ® =.
2 a. = fe] © =.
Grounding: Search, enterprise corpus, and parametric knowledge#
Why#
Enterprise RAG should be conservative and auditable: facts from external sources, not possibly stale parametric memory. A consumer precedent is Gemini’s Grounding with Google Search—for public, up-to-date web knowledge.
Mechanisms and constraints#
- RAG Engine and Gemini: native tool integration (blog: “natively integrated with Gemini API as a tool”). (Supported by literature/documentation.)
- Lewis’s vision: the model routes to sales corpus / HR index the way it “knows” when to Search—no Google public training card or enterprise multi-corpus auto-routing spec. (Interview opinion.)
- Suppressing parametric knowledge: example “Alphabet Q4 2023 revenue”—public or in weights, but the enterprise wants internal context only; guests propose system instruction + contrastive SFT-style behavior and call their own approach naive, not final. (Cannot verify as official capability.)
How to implement#
Combine RAG corpus retrieval + grounding configuration + explicit system instruction (forbid unreferenced claims). For multiple sources, implement an explicit router—do not assume the model picks the right store on its own.
Common pitfalls#
- Bolting on RAG without handling the model “thinking it knows”—retrieval may succeed while parametric knowledge still leaks in.
- Writing Lewis’s training ideas up as shipped Gemini features.

a ie} = lo} ® =.

Graphs, ontology, and multi-vector: conceptual bridge, not default architecture#
Why#
The semantic web invested heavily in ontology and KGMs; guests (including a former KG practitioner) lean toward vector stores + embeddings + LLMs to bypass strict entity–relation modeling at scale; Lewis still allows “graph structure possible, but traversal may be reinvented by LLMs.” (Speaker opinions.)
Mechanisms and constraints#
Weaviate named vectors: Collections can have multiple named vectors; queries must specify the target vector. Connor’s analogy “multiple vectors per object ≈ multiple edges in a graph” is a conceptual analogy, not an official definition. The vector DB comparison table lists Weaviate built-in graph capabilities (cross-references)—a different mechanism from named vectors.
How to implement#
For relation-dense domains, experiment with multi-vector + cross-reference; do not abandon warehouse schema governance before verifying retrieval benefit.
Common pitfalls#
- Using multi-vector as a substitute for joins and lineage documentation.
- Underestimating schema.org-level ontology work as “embeddings are enough.”

oO is} > 5 ® =.
Tuning, cost, and the “AutoML-shaped” gap#
Why#
Production token cost pushes fine-tune / distillation; guests also cite third-party trends: RAG adoption rising, prompt engineering and fine-tuning cooling—Menlo report original text not verified (403). (Interview relay, cannot verify.)
Bob’s view: once base models are “good enough,” fine-tuning’s commercial value falls; the enterprise’s first question is how to use their own data. (Speaker opinion.)
Mechanisms and constraints#
Lewis’s vision: an LLM suggests chunking/embedding on the corpus, batch-runs trials (e.g. 10 configs), picks the best—like AutoML, but RAG Engine has no such API today. (Interview + documentation agree on the negative.) Anonymous case: million-scale manuals, threshold change, ~one week to rerun the pipeline—no third-party corroboration.
Connor mentions DSPy as an optimization framework—not built into Google.
How to implement#
Iterate with manual fine-tune-rag-transformations and offline eval; reserve distillation for high-volume, fixed-template queries. Bob’s 20% document sample to infer re-index quality for the other 80%—research idea, no paper.
Common pitfalls#
- Waiting for official AutoML for RAG before shipping—roadmap uncommitted.
- Skipping eval sets to save retrieval cost.

© 5 = 5 ® =.
© 8 = 5 ® =.
Agents, workflows, and evaluation: when you do not need an “omniscient agent”#
Why#
With multiple pipelines and corpora, something must reason which pipeline to run or call in parallel. MDM menu-style automation: guests say models following human menus hit ~70%; the rest needs experience. (Interview opinion.) Lewis calls MDM a hard problem still not overturned ~2.5 years into the GenAI wave.
Mechanisms and constraints#
Agent (open tools, looping decisions) vs. workflow (fixed DAG) depends on failure cost, explainability, and latency budget. RAG Engine offers embeddable capability blocks, not a full automatic MDM replacement for BPM.
Evaluation should cover retrieval hit rate, citation faithfulness, write-back consistency (if any), cost per query—not generation fluency alone.
How to implement#
- Low ambiguity, single corpus: workflow + RAG tool is often enough.
- Multi-source, needs disambiguation: agent + explicit router + human-in-the-loop.
- Write-back scenarios: define audit logs and approval gates separately.
Common pitfalls#
- Adopting an agent for optics without tool boundaries or stop conditions.
- Replacing retrieval-layer failure analysis with thumbs up/down.

2 He = 5 ® =.
If you are shipping this#
- Lock the data model first: partition by business domain into corpus/collection; accept embedding–corpus lifecycle binding and plan rebuild windows—not hot-swap assumptions.
- Spend budget on transformation: prioritize layout/context-aware chunking and ingestion quality; rerank as a second layer; use metrics matched to your stack (do not copy Anthropic’s 49%/67% verbatim).
- Multi-source needs your own router: RAG Engine + Weaviate (Preview integration) orchestrates a single chain—it will not do sea/lake-level semantic mapping or MDM for you.
- Split write-back and MDM paths: read via RAG Engine; write via Weaviate Transformation Agent (or custom) as experimental until out of Preview.
- Grounding in two layers: retrieval context + instruction forbidding unreferenced claims; if the model “knows” public facts that conflict with internal policy, you need product-layer strategy—not retrieval alone—Lewis’s training suppression is unsupported in official docs; validate in POC.
References and further reading#
- Vertex AI RAG Engine overview
- Vector database options (including Weaviate Preview)
- Use Weaviate with RAG
- RAG quickstart
- Data ingestion
- Using embedding models (text-embedding-005, etc.)
- Fine-tune RAG transformation parameters
- Document AI layout parser
- RAG retrieval and reranking
- Introducing Vertex AI RAG Engine (product blog)
- Generative AI release notes (2024-12-20 GA)
- Grounding with Google Search
- Weaviate data concepts: named vectors
- Weaviate Transformation Agent
- Anthropic: Contextual Retrieval
- DSPy (prompt and weight optimization framework)


