
Query Agent on a Vector Database: Auditable Retrieval and Two Ways to Ask Your Data#
After teams wire RAG to a business datastore, they quickly hit repetitive work: turning natural language into collection routing, hybrid retrieval, property filters, aggregations, and deciding whether to generate an answer with citations. General agent frameworks can orchestrate those steps, but each one requires wiring Weaviate APIs yourself, handling schema drift, and retrying on empty results. Weaviate Query Agent takes a different path—making an “agent that calls Weaviate” a database-side capability, with Ask Mode and Search Mode as two entry points. This article separates what is checkable in documentation from what remains product or interview claims, without assuming one mode replaces all custom RAG.


Problem space: Chat RAG, general agents, and a natural-language interface to the database#
Why Query Agent deserves its own discussion#
A common pattern is vector retrieval plus LLM generation, or an n8n-style DAG chaining steps. The former often exposes only a “final paragraph,” with no visibility into actual filters and limits during audits; the latter is flexible, but Weaviate-specific operators (multi-collection, aggregations, hybrid parameters) must be maintained by hand. Query Agent is positioned closer to agent-first data access (speaker opinion): specialized in reading schema and issuing reproducible Weaviate queries, not general task planning. That aligns with the macro picture in Compound AI (“multiple models + retrieval + tools”), but the implementation boundary is narrower—unverified whether it can replace heterogeneous orchestration across Slack, warehouses, and other systems.
Mechanisms and constraints#
- Runtime: Documentation targets Weaviate Cloud (Sandbox available for trials); whether self-hosted support is equivalent depends on the current version notes (not reproduced in this article’s environment).
- Billing granularity (product page, verified 2026-05): Ask is roughly 4 requests/query, Search roughly 1 request/query—using Search as a “retrieval API” is often cheaper, but that does not mean retrieval quality automatically beats a hand-tuned
hybrid(see evaluation boundaries below). - GA timeline:
weaviate-agentsv1.0.0 shipped 2025-09-16 (GitHub Release); first package v0.3.3 was 2025-02-28, roughly consistent with the interview’s “~March 2025 preview, ~six months of feedback,” not a precise calendar.

How to do it (minimal example)#
from weaviate.agents.query import QueryAgent
from weaviate.classes.agents.query import QueryAgentCollectionConfig
qa = QueryAgent(
client=client,
collections=[
QueryAgentCollectionConfig(name="Jeopardy", views=["default"]),
],
)
# Ask: answer + provenance + audit fields
ask_resp = qa.ask("Which category appears most often?")
# Search: retrieval only, no final_answer
search_resp = qa.search("questions about European history", limit=10)
(Full connection, Auth, and inference API keys: Usage — Instantiate.)
Cloud console vs SDK responsibilities#
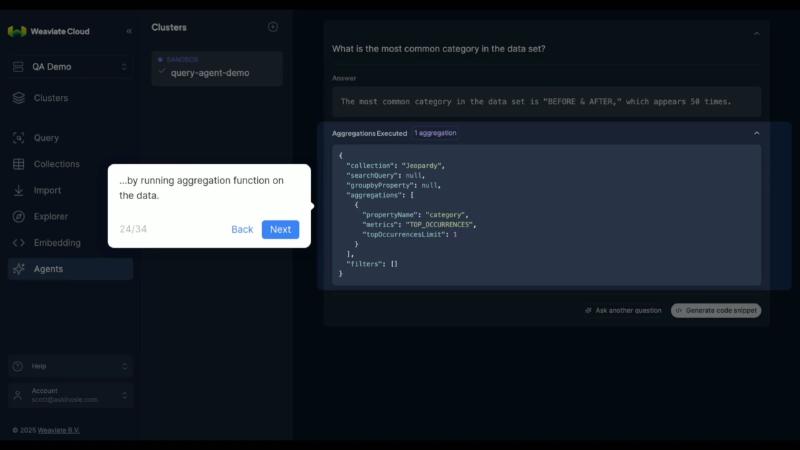
Verified direction: Weaviate Cloud provides an Agents page to pick collections, vectorization modules, and system prompts, and to try queries in a natural-language box (see ocr_pick_004). That is a zero-code smoke path for product and data stakeholders; production should still use the weaviate-agents SDK and align the same question between the console and ask/search searches output so “demo works” does not diverge from the pipeline. Aggregation JSON shown in the console (e.g. TOP_OCCURRENCES) should match SDK aggregations semantics, but UI field names were not checked field-by-field against OpenAPI.
Common pitfalls#
- Treating “two lines of code” as zero config: collection lists, vectorization modules, and Cloud credentials still need explicit setup (speaker opinion: “two lines” is marketing shorthand).
- Assuming Query Agent equals a “general autonomous agent”—capabilities outside Weaviate query/aggregation are not in scope.
- Validating only in the console without putting
searches/aggregationsin CI—regressions in routing or filters go unnoticed.
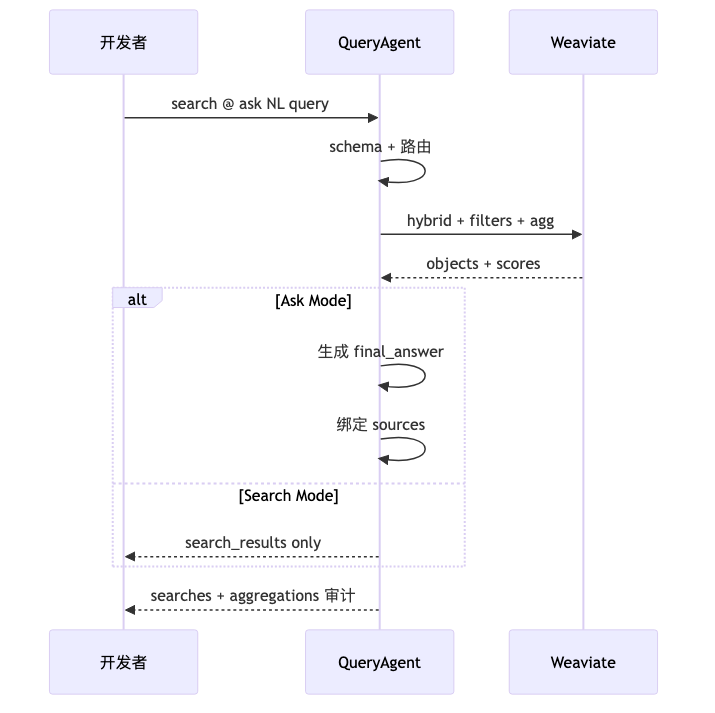
Ask Mode vs Search Mode: same natural language, different objective functions#
Why GA split into two modes#
Early run paths leaned end-to-end: route → multi-path retrieval → expansion → write answer (speaker opinion). Integrators often dropped the generated answer and used only sources / search results for their own agent—product feedback directly drove Search Mode (Usage states retrieval only, no answer generation). Ask targets “a paragraph plus citations for end users”; Search targets “high-quality IR; generation stays in my stack.”
| Dimension | Ask Mode | Search Mode |
|---|---|---|
| Output | final_answer + sources + audit fields | search_results (QueryReturn) |
| Per docs | Includes answer generation | No answer generation |
| Typical integration | Chat, report summaries | Own LLM, ranking, rerank-then-generate |
| Quality claim (interview) | Grounded answer + object-level references | Should show perceptible gain vs bare hybrid (no public uplift table, see evaluation section) |
Mechanism: what is in the Search pipeline#
Verified (documented example JSON): Search responses can include filters (e.g. price < 100) and rerank_score in metadata, indicating reranking signals. Interview supplement, not step-by-step in docs: query decomposition, term expansion, overfetch then cross-encoder/listwise rerank (speaker opinion). Search Mode gains therefore likely come from filter-narrowed candidate sets + compound IR pipeline, not new BM25/vector kernels—different from “just use a bigger embedding model.”
How to do it#
Multi-turn dialogue in GA uses a ChatMessage list (Conversational queries); from v1.0.0 run is deprecated in favor of the V2 API (Release v1.0.0). The interview says alpha lacked native chat and users used workarounds—no official changelog line-by-line match; timeline narrative only.
Common pitfalls#
- Assuming Search is always “stronger” than Ask—docs only separate responsibilities; they do not guarantee Search beats your tuned
hybridon every dataset. - Expecting
final_answeron the Search path—readSearchModeResponse.search_resultsinstead.
Auditable responses: queries, aggregations, and partial answers#
Why an audit trail beats “a block of Markdown”#
Compliance and debugging need answers to: which collection was queried, which filters and limits were used, whether aggregation ran. Weaviate puts agent-issued searches and aggregations in the response (Inspect responses) so you can manually replay the same query via REST or the client. Ask mode also has is_partial_answer and missing_information (AskModeResponse source)—explicit incomplete coverage, slightly more controlled than silent hallucination.
Mechanisms and constraints#
sources:object_id+collection(docs Sources section)—object-level provenance, not a full-text sentence-level citation protocol.- Aggregation metric names (e.g.
TOP_OCCURRENCES) match console demo JSON; full field set follows runtime OpenAPI/JSON (not field-matched to OpenAPI here). - Two-stage citations (first
final_answer, then a separate citation step): Charles Pierse speaker opinion; public docs only promisesources, not step count or a separate citation agent (client source has nocitationsymbol).
How to do it#
print(ask_resp.searches) # includes queries, filters, collection
print(ask_resp.aggregations) # doc example: No Aggregations Run when none
print(ask_resp.is_partial_answer, ask_resp.missing_information)
for s in ask_resp.sources or []:
print(s.collection, s.object_id)
Citations decoupled from generation: engineering implications#
If a two-stage pipeline holds (speaker opinion), behavior is closer to: first synthesize an answer over retrieval results, then bind objects into sources, rather than “footnotes while writing” in one step. For evaluation, measure retrieval recall (do searches cover ground-truth objects?) and attribution accuracy (do sources support key claims in final_answer?) separately. Healthcare and compliance interviews suggest heavier citation sub-agents or multi-round checks—not offered as built-in GA modes in docs.
Common pitfalls#
- Treating
sourcesas proof the answer is correct—the interview is explicit that citations are not a silver bullet; “weak but present” references can occur. - Equating
sourceswith paper attribution metrics—no reported nDCG, faithfulness, etc. (evaluation gap, see below). - Ignoring
is_partial_answeron Ask—the user sees fluent text while the system already declared insufficient information.
Schema introspection, property descriptions, and structured filters#
Why schema documentation becomes cheap leverage#
Pure semantic retrieval suits descriptions like “summer beach shoes”; price ranges, dates, enums fit explicit filters (shared in the conversation, consistent with Weaviate Filters). On startup, Query Agent analyzes collections and property descriptions (Overview — Query Agent context). Long-neglected description fields become zero-shot hints for routing and filter generation: e.g. a country field documented as ISO 3166-1 alpha-2 reduces filters written as Ireland instead of IE (speaker opinion, aligned with docs).
Mechanism#
The client model exposes typed filters: INTEGER, TEXT, BOOLEAN, TEXT_ARRAY, DATE, UUID, etc. (KnownFilterType). The interview claims structured output rejects invalid operator combinations before execution to cut retries; docs say the agent generates filters, not “zero retry” or “must reject before run.” Another interview point: you cannot know in advance whether a filtered query is non-empty—empty results still need runtime handling.
How to do it#
Document semantics and encodings on key schema properties:
{
"name": "country_code",
"dataType": ["text"],
"description": "ISO 3166-1 alpha-2 country code, e.g. IE for Ireland"
}
Common pitfalls#
- Expecting stable routing on empty collections or missing descriptions—test “cold start” and ambiguous fields.
- Applying text-to-SQL intuition directly: vector DB filters differ from SQL optimizer assumptions.
Multi-collection: routing, federated retrieval, and “semantic joins”#
Why “pick one collection” is not enough#
The product page and README mention cross-collection routing (product page). The interview observes that semantically related collections such as contracts / customers without explicit FKs need multi-store queries with interleaved results (speaker opinion); official docs do not use the word interleaved. The guest’s semantic joins means associating intent at runtime from schema metadata—complementary to, not a replacement for, SQL joins (unverified one-to-one mapping to specific GraphQL queries).
Mechanism#
- At construction:
QueryAgent(client, collections=[...]); at runtime passcollectionsorQueryAgentCollectionConfig(includingviews) toask/search. - For single-table use cases, still narrow the collection list explicitly to avoid routing drift.
How to do it#
qa = QueryAgent(
client=client,
collections=[
QueryAgentCollectionConfig(name="Meals", views=["default"]),
QueryAgentCollectionConfig(name="RecoveryArticles", views=["default"]),
],
)
qa.ask("High-protein dinners under 600 kcal last week and recovery tips")
Common pitfalls#
- Multi-collection does not mean automatic ER modeling—without schema descriptions, federated results can be noisy.
- Expecting deterministic SQL-style joins—agent routing is probabilistic; eval is required.
Evaluation, BEIR, and uplift not yet published#
Why “better than pure hybrid” cannot be a fixed number#
The interview claims Search Mode has published gains over pure hybrid, and Connor Shorten mentions experiments on BEIR (speaker opinion). As of 2026-05, searches of docs.weaviate.io/agents/**, the product page, and common blogs found no public table with BEIR subsets, nDCG@k, Recall@k, or comparisons to hybrid (α, limit, rerank or not). BEIR itself stresses zero-shot, heterogeneous collections; until metrics (nDCG@10, MRR, etc.) align with Weaviate hybrid API parameters, only oral claims apply—do not write “improved by X%.”
Partially verified: pipeline pieces (filter, decomposition, expansion, rerank) are common industry combinations; not verifiable: specific uplift and experiment config links.
Suggested self-test checklist (reproducible)#
On your collections, fix 20–50 gold questions, each recording: expected collection, whether a filter should appear, expected top-k object ids. Compare three paths: (1) hand-written hybrid; (2) QueryAgent.search; (3) optional Ask. Log filters and rerank_score distributions in searches, not only LLM answer BLEU. If Search wins mainly on “price/date constrained” subsets, gains likely come from constrained retrieval, not vector semantics alone—consistent with the interview on Search Mode mechanics (speaker opinion).
Common pitfalls#
- Treating marketing “better than hybrid” as a guarantee on your data—A/B on your schema with fixed
alpha,limit,targetVectors. - Comparing BEIR headline scores across vendor slides—meaningless when subsets and preprocessing differ.
- Scoring only end-to-end QA F1 without saving
searcheslogs—you cannot tell “wrong route” from “hallucinated generation.”
MetaBuddy and boundaries: case study, tenants, future direction#
MetaBuddy (structured fitness/nutrition data: meals, nutrition, exercises) was named by Charles Pierse as an early user to stress filters, date filters, aggregations, and cross-collection questions (speaker opinion; no third-party case write-up or audit data, cannot verify business outcomes). Tenants (tenants) were mentioned in client conversation with no implementation detail. Future directions include longer-running Research / reSearch and memory (interview; client v1.2.0 Research mode exists but names do not match the interview exactly)—not GA commitments.
The interview tension—“agents are easy to start, ~80% of time on edge cases” vs market “production agent in a week” (speaker opinion). If your eval culture is weak, Query Agent only shortens Weaviate query authoring, not task-level regression testing.
The host once teased an eval hot take at the end; the published episode ends at MetaBuddy / future direction with no dedicated eval segment—the BEIR and self-test sections above are engineering suggestions to fill that gap, not show conclusions.
If you are shipping this#
- Pick a mode first: end users need readable answers → Ask plus check
sourcesandis_partial_answer; you already have a generation stack → Search, treatsearchesas logs. - Invest in schema: write
descriptionand valid value ranges for filter fields; smoke in Sandbox (Usage) with “Ask me something about your data,” then move to the SDK. - Contract-test responses: assert
filters/aggregationsshape on key questions, not onlyfinal_answertext. - Baseline your own hybrid: fixed-parameter comparison; do not rely on unlinked BEIR numbers.
- Plan cost and rounds: Ask bills at 4× requests; multi-turn
ChatMessageamplifies calls—set gateway budgets and timeouts.
References and further reading#
- Query Agent overview (docs.weaviate.io)
- Query Agent usage: Ask, Search, conversational queries, Inspect responses
- Query Agent product page and pricing
- weaviate-agents-python-client README
- v1.0.0 GA: deprecate run, V2 API, conversational context
- AskModeResponse / SearchModeResponse source
- Weaviate in 2025 (Query Agent GA framing)
- Weaviate hybrid search
- Weaviate property filters
- Weaviate aggregations
- RAG original paper (Lewis et al.)
- BEIR benchmark paper
- Compound AI Systems (BAIR)
- Retrieval quality and RAG overview (Weaviate blog)
- PyPI: weaviate-agents release history


