
Java Streams, Concurrency, and HTTP Clients: Patterns That Run but Blow Up in Production#
In everyday business code, three API families are most likely to create a false sense of security: Comparator and sorting, ConcurrentHashMap and concurrent aggregation, and Stream and collection transformations. Their syntax is concise, single-threaded tests often pass, yet under high load, multithreading, or after a JDK upgrade they expose performance regressions, data loss, or connection pool exhaustion.
What makes this harder is that these problems rarely show up as compile errors: repeated Comparator allocation quietly raises P99; a containsKey race drops a record only under two-thread stress; Stream side effects are optimized away on JDK 17 but still “run normally” on JDK 8; HTTP interceptor leaks only surface in monitoring once the pool is full. Without encoding these patterns into review checklists or static rules, fix costs skew exponentially toward production firefighting.
The sections below break down mechanisms by engineering theme, give minimal fixes, and mark which conclusions come from official docs and JEP/JBS versus troubleshooting experience (labeled speaker’s view). This is not an API tour—it focuses on the overlap where code is legal, tests pass, and production can still fail.
Hot comparison paths: don’t rebuild Comparator inside compareTo#
Why#
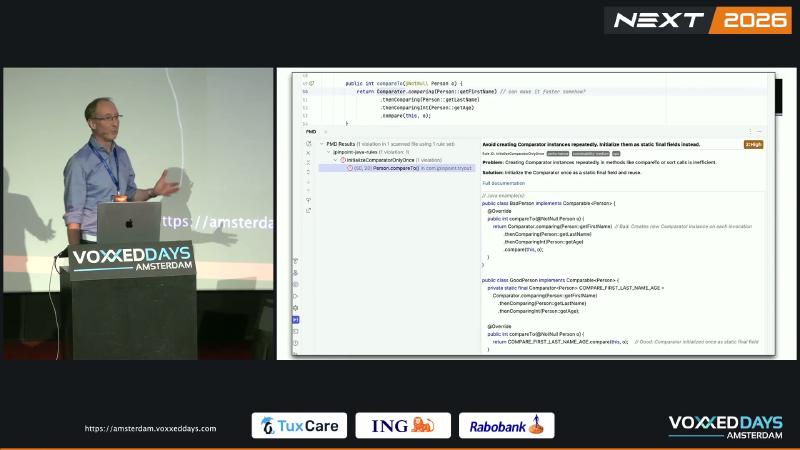
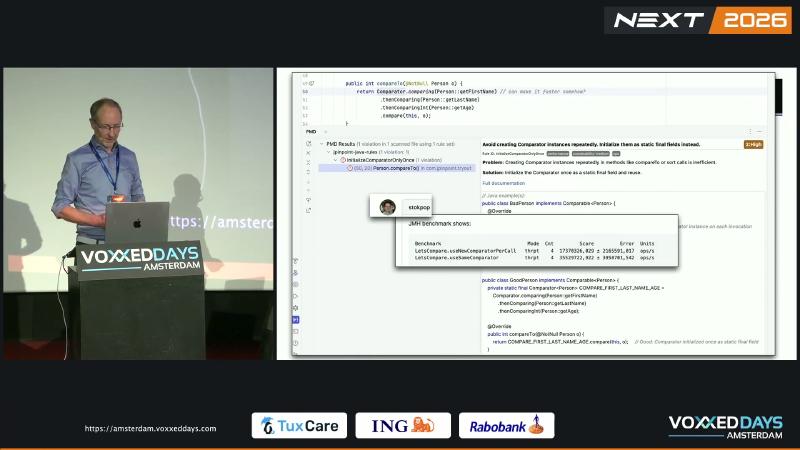
Structures such as TreeSet and Collections.sort call compareTo heavily during insert or sort. If every comparison runs Comparator.comparing(...).thenComparing(...).thenComparingInt(...), comparing and chained thenComparing allocate new objects repeatedly, adding GC and CPU overhead. The PMD jPinpoint rule InitializeComparatorOnlyOnce flags this as a performance hazard; the speaker observed roughly 2× throughput in on-stage JMH comparisons (speaker’s view—specific dataset not published).
Mechanism and constraints#
Oracle Javadoc does not mandate static final, but the API contract is that each comparator chain call returns a new instance. Sorting algorithms may invoke the same comparator on the order of O(n log n) times, so small allocations amplify. Rule documentation recommends promoting the comparator to a reused static final field on hot paths such as compareTo and sort callbacks.
What to do#
// Bad: new chain on every compareTo
public int compareTo(Person o) {
return Comparator.comparing(Person::getFirstName)
.thenComparing(Person::getLastName)
.thenComparingInt(Person::getAge)
.compare(this, o);
}
// Good: static reuse
private static final Comparator<Person> BY_NAME_AGE =
Comparator.comparing(Person::getFirstName)
.thenComparing(Person::getLastName)
.thenComparingInt(Person::getAge);
@Override public int compareTo(Person o) {
return BY_NAME_AGE.compare(this, o);
}
Common misconceptions#
- “Method-reference lambdas are already fast enough”—the bottleneck is repeated allocation, not the lambda itself.
- “We only sort once, so it doesn’t matter”—if
compareTosits on a continuousTreeSetinsert path, cost accumulates. - One-off, local comparators can be acceptable in specific cases (the rule doc also notes may be acceptable), but when reuse is possible, default to reuse.
- Using micro-benchmarks as an exemption—if the comparator appears on a hot path (cache key sorting, real-time risk-rule matching), confirm with a profiler before deciding.
ConcurrentMap: thread-safe container ≠ atomic compound operations#
Why#
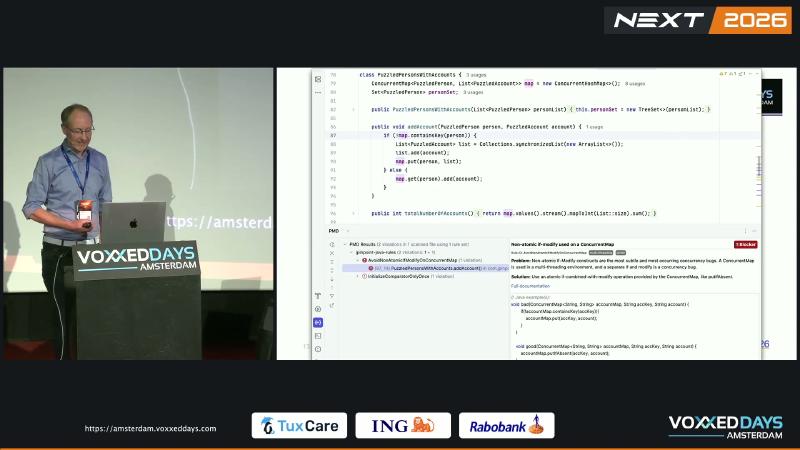
ConcurrentHashMap guarantees thread safety for individual operations like put and get, but if (!map.containsKey(k)) { map.put(k, v); } is classic check-then-act: the two steps can be interleaved by scheduling, both threads may decide the key is absent, each calls put, and the later write overwrites the earlier—losing accounts or sublists. In the speaker’s demo, six accounts total in single-threaded runs became unstable counts such as 3 or 5 under two threads (speaker’s view).
Mechanism and constraints#
ConcurrentMap.putIfAbsent documentation states the semantics are equivalent to if (!containsKey) put else get, except that the action is performed atomically. Likewise, computeIfAbsent merges “check + create” into one atomic step.

What to do#
// Bad: non-atomic if-modify
if (!map.containsKey(person)) {
List<Account> list = Collections.synchronizedList(new ArrayList<>());
list.add(account);
map.put(person, list);
} else {
map.get(person).add(account);
}
// Good: atomic create, then append
map.computeIfAbsent(person,
p -> Collections.synchronizedList(new ArrayList<>()))
.add(account);
Common misconceptions#
- “We use
ConcurrentHashMap, so we’re thread-safe”—only single operations are guaranteed; compound logic still needs atomic APIs. computeIfAbsentonly solves entry creation; if the value is a shared mutable collection,addon the list still needs synchronization or a thread-safe container (the example usesCollections.synchronizedListtogether with atomic map creation).- Assuming
putIfAbsentis fully equivalent toget+put—return semantics differ; read the docs before choosing. - Hand-rolling check-then-act inside
synchronizedblocks—works but coarse lock granularity; prefer the map’s built-in atomic methods and use locks only to protect internal value structure.
Stream side effects: forEach into external collections and the illusion of “working” functional code#
Why#
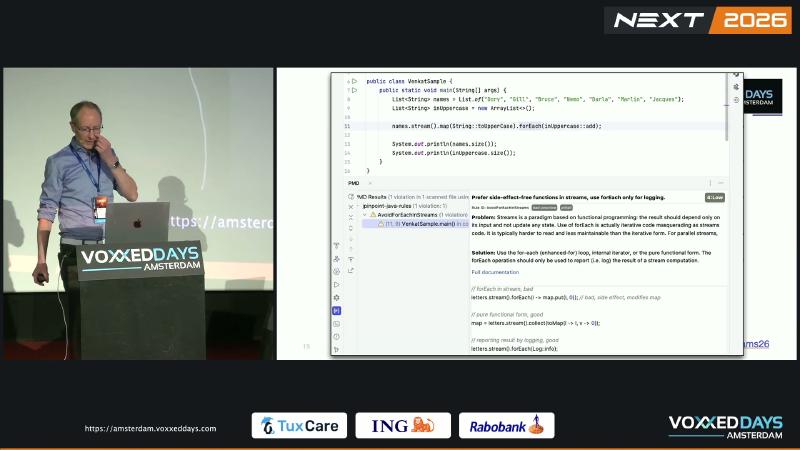
names.stream().map(String::toUpperCase).forEach(externalList::add) stuffs imperative side effects into a declarative pipeline, hurting readability and conflicting with the side-effect-free style advocated in the java.util.stream package SideEffects documentation. PMD jPinpoint AvoidForEachInStreams marks it as iterative code masquerading as streams code, recommending collect / toList() or a plain enhanced-for instead.
Mechanism and constraints#
Stream intermediate and terminal operations do not guarantee the order or number of executions you imagine; with parallelism, side effects also introduce data races. The rule wording is stricter than Javadoc: forEach should be used only for logging/reporting (citing Effective Java Item 46). Oracle docs allow harmless debug side effects like println, but discourage using forEach for aggregation.
What to do#
// Bad
List<String> out = new ArrayList<>();
names.stream().map(String::toUpperCase).forEach(out::add);
// Good
List<String> out = names.stream()
.map(String::toUpperCase)
.toList();
Common misconceptions#
- “
forEachis a terminal operation too, same ascollect"—semanticallyforEachis for consumption,collectfor reduction; choose the latter for aggregation. - Treating
peekas a universal debug tool—peekcan also be optimized away (see next section). - When imperative logic is needed, enhanced-for is often clearer than “fake Stream” code.
Stream.count() and pipeline elision: side effects are not guaranteed to run#
Why#
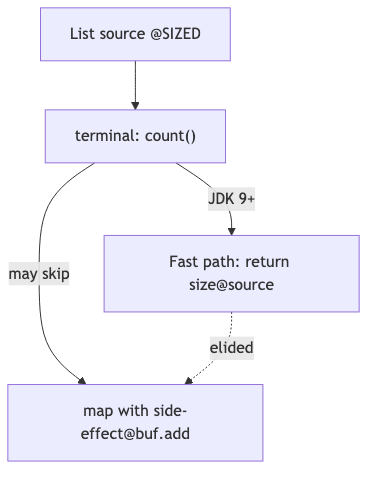
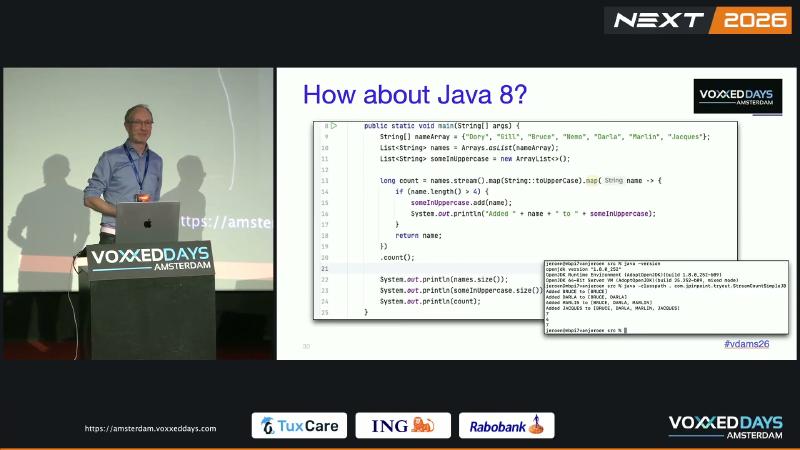
When the source collection size is known and intermediate map does not change element count, the API Note on Stream.count() states the implementation may skip executing the entire pipeline and compute the count directly from the source. Side effects in intermediate steps—such as list.add(name) inside map—may be skipped. Typical puzzle: seven names uppercased, those longer than four should go into buf; audiences often guess buf.size()==4, but on newer JDKs buf is often empty and count==7 (speaker demo).
Mechanism and constraints#
Java SE 21’s SideEffects section is explicit: “behavioral parameters are always invoked” does not hold—implementations may elide operations (or entire stages) when proven not to affect the result. OpenJDK JDK-8067969 introduced the SIZED Stream count() optimization in JDK 9 (fixVersions: [9]). Java 8’s count() Javadoc lacks the “may choose to not execute the pipeline” wording, and package-summary has no elide paragraph; the same code on 8 is more likely to run intermediate steps, but side effects should not be relied on even on JDK 8.
What to do#
List<String> buf = new ArrayList<>();
long count = names.stream()
.map(String::toUpperCase)
.map(name -> {
if (name.length() > 4) buf.add(name); // not guaranteed to run
return name;
})
.count();
// On newer JDKs: buf may still be empty, count == names.size()
When you need both counting and collection, split explicitly or use collect/teeing; do not treat count() as a trigger to “run the pipeline while we’re at it.”
JDK version differences and reproducibility#
Compare buf.size() and intermediate println counts for the same class on different JDKs:
/usr/libexec/java_home -v 1.8 --exec java -classpath . com.example.StreamCountSimple
/usr/libexec/java_home -v 21 --exec java -classpath . com.example.StreamCountSimple
Unverified boundary: whether JDK 8 updates backported this optimization was not confirmed in release notes; CI should cover the target runtime JDK—a green dev machine on JDK 8 does not imply the same behavior on production JDK 21.
From a specification standpoint, Arrays.asList(...).stream().peek(System.out::println).count() is the canonical counterexample in Javadoc: peek does not change element count, so terminal count() can read source size directly. If your business map only performs filtering transforms (no change in stream length), it falls in the same optimization category. When side effects are truly needed, use terminal operations that do not promise fusion (such as collect) or an explicit for-loop—encode execution count in semantics rather than betting on implementation.
Common misconceptions#
- “It ran locally, so side effects definitely execute”—the spec allows elision, and implementations differ across versions.
- “Using
parallelStreamprevents optimization”—parallelism only adds race risk; it does not guarantee side effects. - Mutating external state in
filter/map—PMDAvoidSideEffectsInStreamscatches this too.
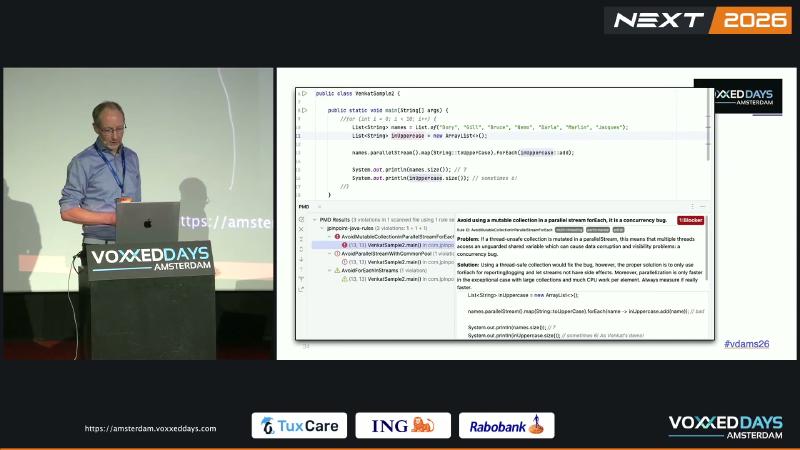
parallelStream and non-thread-safe mutable collections#
Why#
parallelStream() uses ForkJoinPool.commonPool() to split work in parallel. parallelStream().forEach(mutableArrayList::add) lets multiple threads write to ArrayList simultaneously—documentation states it is not synchronized and structural modification requires external synchronization. Intermittently missing elements (6 instead of 7) is a deterministic concurrency bug, not an “occasional glitch.” Speaker’s view: teams have caused intermittent production issues by adding a few characters and parallel right before launch.
Mechanism and constraints#
PMD AvoidMutableCollectionInParallelStreamForEach describes multiple threads access an unguarded shared variable. Parallel streams are worth considering only for large collections, heavy per-element CPU work, and measured speedup (AvoidParallelStreamWithCommonPool advises Always measure if really faster).
What to do#
// Bad
names.parallelStream()
.map(String::toUpperCase)
.forEach(inUppercase::add);
// Good: no shared mutable state
List<String> inUppercase = names.parallelStream()
.map(String::toUpperCase)
.toList();
Common misconceptions#
- “Small data, parallel is faster”—task split/merge overhead often cancels gains.
- Shared
ConcurrentHashMapfor accumulation—single operations are safe, but compoundget+putcan still lose updates; useConcurrentHashMapatomic merge APIs or concurrentcollectcollectors. - Default common pool contending with business thread pools—especially risky for IO-heavy workloads.
- Assuming
toList()is unsafe under parallelism—JDK 16+toList()returns an immutable list; collection is coordinated by the Stream framework, fundamentally unlike hand-writtenforEachadds.
Spring ClientHttpRequestInterceptor: must close() before throwing#
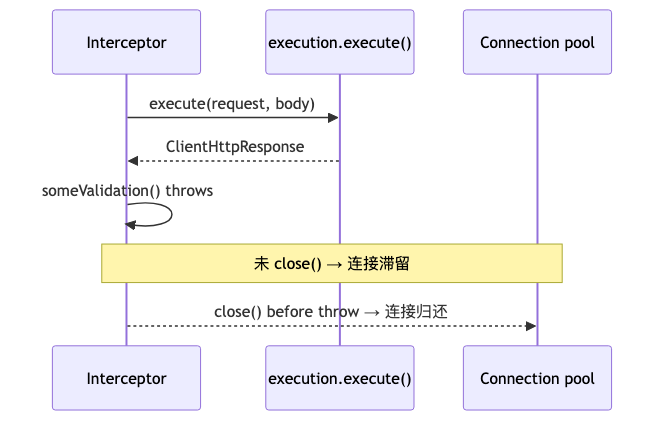
Why#
In ClientHttpRequestInterceptor.intercept(), after execution.execute() returns a ClientHttpResponse, throwing on validation failure without response.close() may prevent the underlying HTTP connection from returning to the pool, eventually causing pool exhaustion and hung requests. Speaker’s view: multiple troubleshooting sessions and one payment-related outage traced to this. Spring Javadoc: if the interceptor throws an exception after receiving a response, it must close the response via ClientHttpResponse.close().
Mechanism and constraints#
ClientHttpResponse documentation: must be closed, typically in a finally block. ClientHttpRequestExecution has only execute(HttpRequest, byte[])—there is no cancel() or similar alternative release path. PMD rule HttpInterceptorNotReleasingOnException flags missing close as connection leak risk.
The resource chain roughly: execute borrows from the pool → response body is tied to this thread → on the normal path the caller consumes and closes; if the interceptor throws while the connection is “borrowed but not returned” and skips close(), the pool still considers it occupied, new requests block waiting, showing up as timeouts or thread pile-ups. Rule documentation explains the mechanism; Spring interface docs only state the close obligation, not pool internals—but the obligation itself is a hard contract.
Client-side fix#
// Bad: throw on validation failure without close
public ClientHttpResponse intercept(HttpRequest req, byte[] body,
ClientHttpRequestExecution exec) throws IOException {
ClientHttpResponse response = exec.execute(req, body);
someValidation(response); // may throw
return response;
}
// Good: release before throw
public ClientHttpResponse intercept(HttpRequest req, byte[] body,
ClientHttpRequestExecution exec) throws IOException {
ClientHttpResponse response = exec.execute(req, body);
if (!response.getHeaders().containsKey("X-Some-Header")) {
response.close();
throw new IOException("validation failed");
}
return response;
}
Server and wiring (minimal context)#
// Register interceptor
@Bean
RestTemplate restTemplate(List<ClientHttpRequestInterceptor> interceptors) {
RestTemplate rt = new RestTemplate();
rt.setInterceptors(interceptors);
return rt;
}
// Server: return header under validation for integration testing interceptor behavior
@GetMapping("/api/account")
ResponseEntity<String> getAccount() {
return ResponseEntity.ok()
.header("X-Some-Header", "ok")
.body("balance");
}
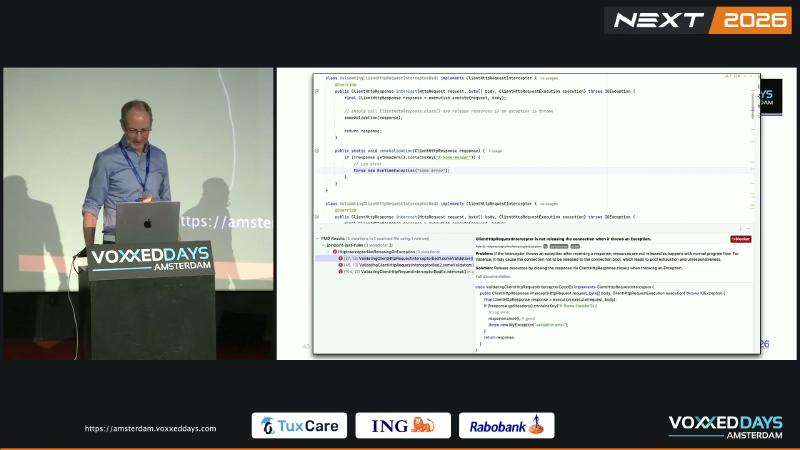
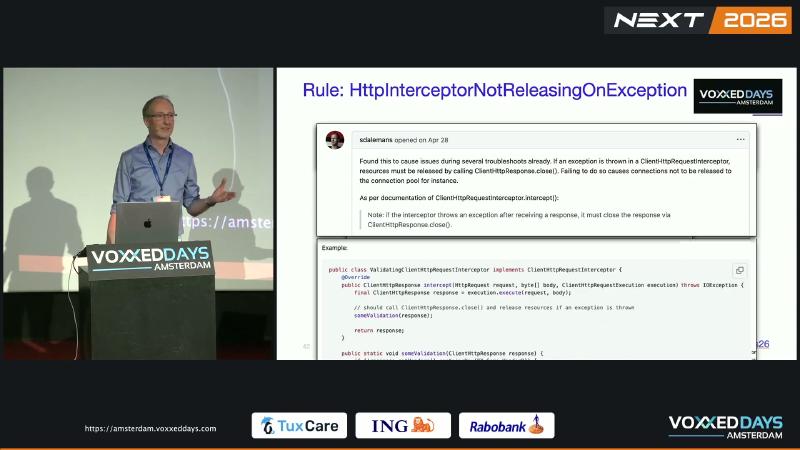
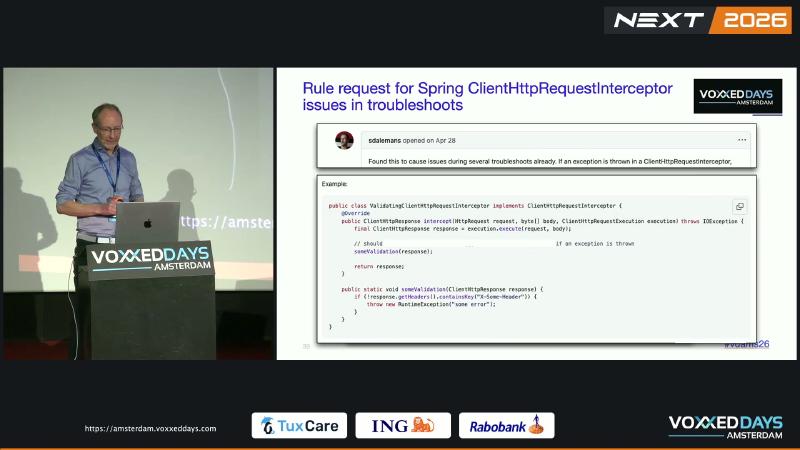
Common misconceptions#
- “Exceptions trigger framework cleanup, so we don’t need to worry”—Spring puts the close obligation in the interceptor contract.
- “We only log, we don’t throw, so we’re safe”—if the body was read and the response is not forwarded, still close per client implementation docs.
- Confusing rule name
HttpInterceptorNotReleasingOnExceptionwith the older nameHttpInterceptorNotReleasingConnectionException(actual name on the pmd7 branch).
Encoding troubleshooting lessons in static analysis: PMD jPinpoint and shift-left prevention#
Why#
The pitfalls above slip through code review easily: code “runs,” unit tests lack coverage, JDK versions differ from production. The open-source rule set PMD-jPinpoint-rules distills years of performance and failure analysis into PMD 7 rules covering comparator allocation, concurrent maps, Stream side effects, parallel mutable collections, HTTP interceptors, and more—integrable via IntelliJ PMD plugin, Maven maven-pmd-plugin, and Sonar. Speaker’s view: production incident user impact and troubleshooting cost far exceed fixing in CI; the methodology is load test, code scan, incident → rule feedback loop (README also states distilled from analyzing performance problems and failures).
What to do#
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-pmd-plugin</artifactId>
<configuration>
<rulesets>
<ruleset>jpinpoint-rules.xml</ruleset>
</rulesets>
</configuration>
</plugin>
Newer rules (such as InitializeComparatorOnlyOnce) live on the pmd7 branch; when integrating, pick versions against the repo README and releases.
Common misconceptions#
- “Too many rules, turn them all off”—enable progressively by category, prioritizing concurrency and resource-leak rules.
- Scanning only the master branch old ruleset—pmd7 includes newer HTTP, Comparator, and related rules.
- Treating static analysis as the only defense—combine with integration tests and load tests on the target JDK; rules cannot cover all runtime semantics.
- Expecting rules to replace code review—static analysis should reduce escape rate, not replace understanding of the business concurrency model.
Suggested rollout order#
If resources are limited, enable in batches by risk priority: first HTTP interceptor close and ConcurrentMap non-atomic if-modify (data and availability); then parallel stream mutable collections and Stream side effects (concurrency and JDK migration); finally Comparator static reuse (performance). When introducing each rule category, allow a week to burn down existing warnings—avoid a one-shot flood that makes the team disable rules.
References and further reading#
- Comparator — Java SE 21 API documentation
- ConcurrentMap.putIfAbsent — atomic semantics
- ConcurrentMap.computeIfAbsent — atomic creation pattern
- java.util.stream package SideEffects — side effects and optimization boundaries
- Stream.count() — API Note on pipeline elision
- OpenJDK JDK-8067969 — SIZED Stream count optimization
- ArrayList — non-thread-safe documentation
- ForkJoinPool.commonPool — default thread pool for parallel streams
- ClientHttpRequestInterceptor — contract to close on exception
- ClientHttpResponse — response body must be closed
- PMD-jPinpoint-rules — rule set repository and integration guide
- jPinpoint JavaCodePerformance — performance and concurrency rule documentation
- jPinpoint JavaCodeQuality — Stream and code quality rules
- Stream.count() — Java SE 8 documentation for comparison
- java.util.stream SideEffects — elide wording from Java SE 9 onward


