
JDK 26 如何改善 G1 吞吐:写屏障同步与默认收集器路线#
摘要#
自 JDK 9 起,多数 server 配置在未显式指定收集器时会默认选用 Garbage-First(G1),以便在典型负载下优先控制 GC pause,而非单纯最大化 throughput。代价落在应用线程:每次堆上引用字段写入都会经过较重的 write barrier,并与后台 optimizer threads 共享 card table,历史上需要细粒度同步。JEP 522 已在 JDK 26 交付——引入第二张 card table、atomically swaps 两表,并借助 JEP 312 的 thread-local handshakes 在切换时对齐可见性,从而在 不新增用户必选开关 的前提下削减同步开销。更长周期的 JEP 523 则提案把「未指定收集器时一律 G1」推广到单 CPU、小内存等环境;截至 2026-05 其状态为 Proposed to Target(Release 27),尚未 Delivered。本文按机制链组织,数字与开关以 JEP / Oracle 文档为准;口述中未在 JEP 逐字出现的细节标注为 演讲者观点。

默认路径为何先选延迟,再谈吞吐#
为什么#
在线服务与交互式负载里,秒级停顿往往直接体现在尾延迟上。JEP 248 的动机写明:Limiting GC pause times is, in general, more important than maximizing throughput。因此 HotSpot 在 32/64 位 server 配置 把默认从 Parallel GC 换成 G1,用并发标记、按 region 增量回收等手段避免 Parallel 式「整堆 stop-the-world」最坏情况。副作用是:大量「零调参」进程长期运行在 G1 上,而 G1 的 mutator 路径比 Parallel/Serial 更重——这是 JDK 26 之前吞吐常被认为弱于 Parallel 的工程背景之一。
机制与约束#
- 吞吐(throughput):Oracle GC 实现与性能考量 定义为 percentage of total time not spent in garbage collection。
- 延迟(latency):同一文档强调 pause 对响应性的影响。
- G1 的暂停目标是 软目标:
java手册 对-XX:MaxGCPauseMillis=写明 JVM 会 make its best effort;Oracle G1 调优指南 选项表列出默认 200 ms 量级(以该表为准,非播客口述)。 - JEP 522 Non-Goals:不以追上 Parallel 的吞吐为交付目标。
- Parallel / Serial 仍保留:JEP 523 Non-Goals 明确 Deprecate or remove any existing collector 不是目标。
怎么做#
java -version
java -Xlog:gc=info -version # 启动时打印实际选用的 GC
jcmd <pid> VM.flags | grep -E 'UseG1GC|UseSerialGC|UseParallelGC'
吞吐敏感批处理可显式对比:
java -XX:+UseParallelGC -Xlog:gc*:file=parallel.log -jar app.jar
java -XX:+UseG1GC -Xlog:gc*:file=g1.log -jar app.jar
常见误区#
- 把「JDK 9 起默认 G1」理解成 所有 环境(含嵌入式、单核容器)——JEP 523 Motivation 仍记载:single CPU 或物理内存 < 1792 MB 时默认 Serial。
- 在未做 A/B 压测的情况下,断定「G1 一定比 Parallel 慢」或「一定更快」——应分 workload 与 JDK 小版本测量。
- 把
MaxGCPauseMillis=200当成硬 SLA——手册与调优指南均强调这是 goal,GC 仍可能在极端分配尖峰下短暂超标;容量规划应结合 P99 pause 与分配速率,而非单点默认值。

写屏障、card table 与 region:吞吐税落在哪#
为什么#
G1 将堆切成多个 region,回收时复制存活对象并维护跨区引用。若每次 pause 扫描整堆,停顿目标无法保证。于是 HotSpot 为 G1 注入 write barrier:every time an object reference is stored in a field 更新 card table,使 pause 只需处理 脏卡(JEP 522 Background)。Oracle G1 — Remembered Set 写明默认 512 B 堆块对应 1 B 卡表项。口述常举「老年代字段指向年轻代」;官方行文以 cross-region 为主,与 region 模型一致,不必把口语例子当成唯一规范表述。
相对 Parallel/Serial,G1 还需与 GC 线程 coordinate,同步既 lowers throughput and increases latency(JEP 522 Motivation)。x64 上屏障曾约 50 条指令,优化后约 12(JEP 522 Performance——OpenJDK 官方 benchmark 结论,非本机承诺)。
机制与约束#
- Post-write barrier:字段
store引用后的屏障主体;Parallel/Serial 亦有 card marking 类逻辑。 - Pre-write barrier(用于 concurrent marking、Parallel/Serial 无):演讲者观点——本次核对的 JEP 522 / Oracle 节选 未逐字写分工。
- 同 region 内写入可省略部分 remembered-set 工作:演讲者观点——公开调优文档 未给出该分支的逐句算法;若写内部架构说明,应对照 HotSpot 源码并标注版本。
- 漏标脏卡 可能导致收集集漏扫引用——属 GC 正确性风险;口述称可能 进程崩溃,JEP 522 未写 crash,宜标 演讲者观点。

怎么做#
java -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xlog:gc*,safepoint -jar app.jar
java -Xlog:gc+ergo=info,gc+region=debug -jar app.jar
jcmd <pid> GC.heap_info
常见误区#
- 将 G1 变慢笼统归因于「并发 GC 线程太多」——每写一次引用 的屏障税无法靠调线程数消除。
- 把
MaxGCPauseMillis压得过低,指望吞吐不变——更激进的回收策略通常会牺牲 mutator 时间占比。

后台优化与 mutator 争用:为停顿做的工程如何反噬吞吐#
为什么#
分配与引用写入极快时,脏卡会在 pause 前堆积;若 pause 内冷启动扫描整张活动表,可能 exceed its pause-time goal(JEP 522 Background)。G1 因此用 optimizer threads optimizes the card table in the background,把部分工作前移到并发阶段,并配合 remembered set 让 pause 增量扫描。代价是:optimizer 与 mutator 必须 synchronize 以避免对同一张表的冲突更新——屏障因同步而 complex and therefore slow(同 JEP Background)。JEP 正文多用 optimizer threads;VM 旗标则含 G1ConcRefinement(见 Risks)——口语「concurrent refinement」宜与正式术语对照,避免混为同一官方名称。
机制与约束#
-XX:-G1UseConcRefinement:完全关闭优化线程(JEP 522 Risks)。-XX:G1ConcRefinementThreads=<n>:限制线程数。- 关闭 refinement 不是 JDK 26 的「提速秘籍」——通常会让脏卡堆积、pause 变长,与 JEP 动机相反。
怎么做#
java -Xlog:gc+refine=debug,gc+task=debug -jar app.jar
jcmd <pid> VM.flags | grep G1ConcRefinement
常见误区#
- 在生产环境长期
-XX:-G1UseConcRefinement「减少后台线程」——可能以吞吐假象换取更长停顿。 - 仅看 GC 线程 CPU,而忽略 mutator 在屏障上的 icache / 指令数 成本。

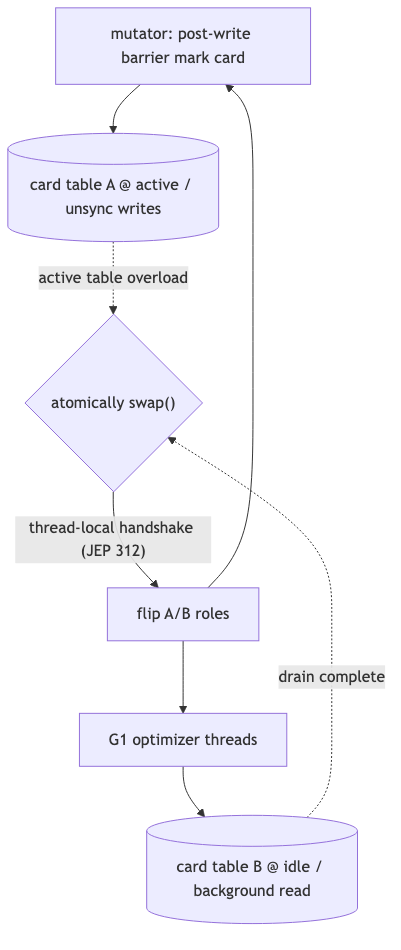
JDK 26:双 card table、表交换与 thread-local handshake#
为什么#
JEP 522 目标第一条即 Reduce synchronization overhead。核心思路:introduce a second card table;mutator without any synchronization 更新活动表;optimizer 在另一张表上工作;当 pause 前扫描活动表可能超时时,atomically swaps 两表,mutator 转到空表继续打点,optimizer 消化已满表(JEP 522 Proposal)。交换瞬间需让所有 Java 线程看到新活动表指针;方案在 Alternatives 写明采用 generic thread-local handshakes(JEP 312)——without performing a global VM safepoint。口述「不必为此 Full GC pause」与 JEP 312 方向一致;JEP 522 Proposal 未逐步描述每次 swap 的 handshake 协议,不宜写成与 JEP 正文同级的实现细节。
机制与约束#
| 项 | 来源 |
|---|---|
| 无新增用户必选开关 | JEP 522 Goals |
| 每张表约占堆 0.2% native(约 2 MiB / 1 GiB) | JEP 522 Native memory |
| 第二张表 replaces auxiliary data structure;总 native 可能更低 | 同节 |
| 重度写引用场景吞吐 5–15%;屏障 50→12 指令(x64) | JEP 522 Performance(官方 benchmark) |
| 侵入性改动带来正确性/性能回退风险 | JEP 522 Risks |
-XX:ThreadLocalHandshakes 默认 true | JEP 312 |
怎么做#
java -version # 确认 26+
java -Xlog:gc+refine*=debug,gc+start=info -jar app.jar
java -XX:StartFlightRecording=duration=120s,filename=jdk26-g1.jfr -jar app.jar
升级对照:在 相同负载、相同堆与相同 -Xmx 下对比 JDK 25 与 26 的应用吞吐(JMH / 业务压测)、gc+refine 日志与 JFR 中 jdk.GCPhasePause 分布。若业务指标几乎不变,先核对是否属于 写引用稀疏 或 已绑定 Parallel 的进程;JEP 522 Performance 的收益区间与这两类场景天然错位。
从实现视角看,双表把「mutator 写」与「optimizer 读/整理」在时间上拆到不同物理表,日常路径去掉对同一张表的锁竞争;交换则是把「pause 前必须扫完的活动表」与「仍在增长的脏卡流」切开。JEP 522 Alternatives 还提到曾考虑 OS 级原子交换等方案,最终选用 thread-local handshake 以降低平台差异——具体 handshake 回调在 Proposal 未展开,生产排障时仍以统一日志与 JFR 为主,不宜在事故报告中臆造逐步协议。
常见误区#
- 把 JEP 522 的 5–15% 当作「所有 Java 应用 guaranteed 提升」——官方表述限定在 heavily modify reference fields 类 benchmark。
- 为排障关闭
ThreadLocalHandshakes(除非明确理解 JEP 312 依赖)——可能影响交换可见性路径(需结合版本 release note)。 - 假设 JDK 26 已等于 JEP 523 的「全环境默认 G1」——后者 尚未 Delivered。

原生内存、小配置默认与收集器存续#
为什么#
双表带来额外 footprint,但 JEP 同时 取代 旧辅助队列/结构,部分部署总 native 未必上升。更长周期上,JEP 523 认为 G1 经多年瘦身(口述提及 marking bitmap、压缩 remembered set 等),吞吐成为相对 Serial 的最后主要差距;JEP 522 视为补齐后,可把 always select G1, regardless of the number of processors and the available physical memory 作为默认策略。口述「marking bitmap 约 2.5%」——演讲者观点,JEP 522 未出现该数字;容量规划应以 NMT / 实测 为准。
机制与约束#
- JEP 523:Release 27,2026-05 抓取为 Proposed to Target。
- Non-Goals:不废弃 Parallel / Serial;与 CMS 先例(JEP 291 废弃、JEP 363 JDK 14 移除)不能推导 Parallel「即将移除」——演讲者观点:维护多收集器有成本,未来是否下线 无定论。
怎么做#
java -XX:NativeMemoryTracking=summary -jar app.jar
jcmd <pid> VM.native_memory summary scale=MB
# 单核 / 小内存容器核对默认收集器
java -Xlog:gc=info -version 2>&1 | grep -i Using
常见误区#
- 只看 Java heap 占用,忽略 card table、marking 结构等 native 段。
- 极小堆 + 严格 cgroup 上限时忽视 +0.2% 表开销——JEP 认为通常不显著,但应实测。
- JEP 523 落地后仍假设「嵌入式默认 Serial」而不更新监控与 runbook。




ORACLE / Lu S S =a 含识别噪声)。
诊断路径:从「用的谁」到「换表是否生效」#
以下路径面向 已运行 JDK 26+ 的生产或预发实例,按成本从低到高排列。
步骤 1 — 确认收集器与版本
java -version
java -Xlog:gc=info -version
jcmd <pid> VM.flags | grep -E 'UseG1GC|UseSerialGC|UseParallelGC|MaxGCPauseMillis'
如何读输出:-version 首行应含 26(或更高);-Xlog:gc=info 在启动阶段通常打印 [gc] Using G1 或 Using Serial 等。若未显式 -XX:+UseG1GC 却看到 Serial,优先对照 JEP 523 所述 < 1792 MB / 单 CPU 启发式,而非假定 JEP 522 未生效。
步骤 2 — 观察 refinement 与 pause 是否「脏卡积压」
java -Xlog:gc+refine=debug,gc+ergo=info,gc+pause=info -jar app.jar
# 或对已运行进程(需启动时已开统一日志或动态附加,视部署而定)
如何读输出:gc+refine 中若长期出现 refinement 跟不上、或 pause 日志显示 card 扫描占比异常升高,应怀疑 关闭 refinement 或 分配+写屏障产脏速度 超过 optimizer 能力——这与 JEP 522 要解决的「pause 前表过大」属于同一问题族。JDK 26 后若吞吐仍差,先排除 非 G1、再排除 负载本身写引用极稀疏(此类 workload 可能看不到 JEP 522 宣称的 5–15% 区间)。
步骤 3 — JFR 对比升级前后
java -XX:StartFlightRecording=duration=300s,filename=before.jfr -jar app.jar
# 升级 JDK 26 后同负载
java -XX:StartFlightRecording=duration=300s,filename=after.jfr -jar app.jar
如何读输出:在 JDK Mission Control 或 jfr print 中对比 jdk.GCPhasePause 分布、应用线程 CPU 与 GC 子系统 CPU;mutator 吞吐提升往往体现在 GC 时间占比下降 或 同等 GC 开销下更高业务 QPS,而非单一 pause 数字。
步骤 4 — Native footprint(可选)
java -XX:NativeMemoryTracking=summary -jar app.jar
jcmd <pid> VM.native_memory summary scale=MB
如何读输出:关注 GC 或 Internal 段在 JDK 26 前后差异;双表理论增加约 0.2% × 2 的卡表存储,但 auxiliary 结构退役可能抵消——以 diff 为准。
步骤 5 — 容器与小内存启发式(JEP 523 预演)
在 1 vCPU、≤1.5 GiB 的 Pod 中分别启动:
java -Xlog:gc=info -version
java -XX:+UseG1GC -Xlog:gc=info -version
对比两次 Using 行。JEP 523 落地前,第一次可能仍为 Serial;若业务已验证 G1 可接受,应在镜像或 JAVA_TOOL_OPTIONS 中 显式 -XX:+UseG1GC,避免误以为「升级 JDK 26 即自动全环境 G1」。JEP 523 落地后,runbook 应改为「默认 G1,极小 footprint 可显式 Serial 回退」。
生产部署注意点#
| 维度 | 建议 |
|---|---|
| 版本 | JEP 522 仅 JDK 26+ G1 默认路径生效;JDK 25 及以下无此双表实现。 |
| 开关 | 无需为新行为添加必选参数;勿在生产长期 -XX:-G1UseConcRefinement 除非有明确排障记录。 |
| 期望管理 | 5–15% 来自官方 benchmark 的 heavily modify reference fields;CPU 绑定、少写引用的服务可能接近 0% 体感。 |
| 内存 | 极小堆、cgroup 硬顶环境请用 NMT 实测;JEP 认为额外 footprint 通常可接受,非合同保证。 |
| 默认收集器 | JEP 523 未交付前,小配置仍可能 Serial;升级监控与启动脚本中的 Using 检测。 |
| 回退 | 吞吐仍不足可试 -XX:+UseParallelGC(批处理);极小嵌入式可 -XX:+UseSerialGC——与 JEP 523 Non-Goals 一致。 |
| 风险 | JEP 522 Risks 承认侵入性改动可能引入正确性或性能回退;灰度 JDK 26 时保留收集器切换与堆 dump 预案。 |
| 观测成本 | -Xlog:gc+refine=debug 与 JFR profile 设置会抬高开销,仅用于短期诊断窗口,不宜常开。 |
| 文档版本 | 本文 Oracle 链接以 Java 21 文档域为例(与核验时一致);JDK 26 行为以 JEP 522 与对应发行版 release note 为准,手册印刷值可能随 GA 微调。 |
灰度时建议固定三板斧:(1) 启动日志确认收集器;(2) 同负载 JDK 25/26 或「升级前后一周」JFR 抽样;(3) 对写引用密集服务单独看 mutator CPU 与 gc+refine,避免仅凭全局 P99 pause 否定吞吐收益。
参考与延伸阅读#
- JEP 522:G1 以减少同步提升吞吐(JDK 26,Delivered)
- JEP 523:未指定收集器时一律默认 G1(Proposed to Target,Release 27)
- JEP 248:JDK 9 起 server 配置默认 G1
- JEP 312:Thread-Local Handshakes(无全局 VM safepoint 的按线程回调)
- Oracle G1 调优指南:region、Remembered Set、512B card
- Oracle:收集器实现与吞吐/延迟定义
- Oracle:可用收集器选型总览
java命令手册:-Xlog、收集器开关、MaxGCPauseMillis、NMT、JFR- JEP 291:JDK 9 废弃 CMS
- JEP 363:JDK 14 移除 CMS
- OpenJDK HotSpot G1 源码树(
src/hotspot/share/gc/g1) - Unified JVM Logging 标签说明(
-Xlog:help) - Native Memory Tracking 使用说明
- OpenJDK JDK 26 Release Notes(收集器变更条目)


