
泛型代码在 JVM 上如何变快:擦除、剖析与「坠崖」之后的攀爬#
Java 泛型在语言层经过类型擦除后,运行时仍是一份共享字节码;性能能否逼近 C++ 为每种 (容器, Comparator) 静态展开的机器码,取决于 HotSpot 能否在稳定剖面下完成去虚化、内联与常量传播。本文以 median-of-three QuickSort 为标尺,梳理「好日子」与 megamorphic「悬崖」之间的机制,并说明 Hidden Class 克隆与 MethodHandles 强制内联等研究性修复思路——其中 µs 与倍数若无本地 JMH 复现,均标为讲演者观点;Project Valhalla / Project Leyden 相关表述为路线图愿景,非当前 JDK 产品承诺。

单份字节码 vs 模板展开:性能问题从哪来#
为什么:业务需要可共享的库实现(一份 sort(T[], Comparator)),又希望在热路径上接近手写 int[] 或 C++ vector<int> 全静态特化的吞吐。语言规范只保证编译期擦除,不承诺零虚调用;C++ 则走异构翻译——vector<int> 与 vector<float> 是不同类型,可各自生成代码。
机制/约束:擦除后 JVM 仍通过 invokeinterface、aastore 等字节码做接收者类型剖析;与「编译期已展开」的 C++ 模板相比,专用化发生在运行中的 C2,且受剖面宽度、内联预算约束(见后文 TypeProfileWidth)。
怎么做(概念对照):
// Java:一份泛型入口
public static <T> void sort(T[] a, Comparator<? super T> c) { /* ... */ }
// C++:每种 comparator 可独立实例化(机制见 cppreference Templates)
template<typename Cmp> void quick_sort(int* a, int n, Cmp cmp);
常见误区:把「擦除」等同于「运行时一定慢」——慢的是未形成稳定单态剖面时的虚调用与装箱路径,而非擦除本身。
基准矩阵:同一算法,不同数据与调用形态#
为什么:要把「算法相同」与「表示 + 调用形态」拆开,才能解释后续 2×–5× 乃至更大跨度的性能落差。
机制/约束:讲演者在 JDK 25 + JMH + AArch64 下,对 1000 个随机 int 排序给出近似锚点(讲演者观点):手写 IntQS/int[] ~10.5µs;QS/Integer[] 装箱泛型约慢近 3×;反射统一路径 ReflQS 在 flat int[] 上可回到 ~10µs 量级,而饱和剖面可拖到 ~70µs。C++ vector<int> 全静态特化(clang -O3)与 Java 手写 primitive 同量级;若 comparator 退化为 std::function,则类似 JVM megamorphic(讲演对比论点,未用单一规范页核实)。
怎么做(JMH 骨架):
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class SortBench {
@Benchmark public void intQS(int[] a) { IntQuickSort.sort(a); }
@Benchmark public void genericQS(Integer[] a) {
GenericQuickSort.sort(a, Integer::compare);
}
}
常见误区:只比较「是否泛型」,忽略 Integer[] 装箱带宽、以及 Comparator 实现类是否在调用点稳定。
反射数组:为 flat / boxed 统一铺路#
为什么:Project Valhalla 方向下,同一套 API 可能面对多种布局(扁平 value 数组 vs 装箱引用数组);讲演用 ReflectiveQuickSort 通过 Array.get / Array.set 统一访问,探测「一种算法、多种布局」时优化器还能走多远。
机制/约束:装箱用 4 字节 int 换 16–24 字节对象表示(指针 + 头 + 载荷)——讲演者观点,对象头与压缩指针因 VM 而异;装箱换来完整多态,但提高 footprint 与数组遍历带宽成本。primitive 数组与现行泛型擦除仍难混用(「yet…」)。


怎么做:
static void reflectiveSort(Object a, int lo, int hi, Comparator<?> cmp) {
Object pivot = Array.get(a, hi);
for (int i = lo; i < hi; i++)
if (cmp.compare(Array.get(a, i), pivot) < 0)
swapReflect(a, i, /* ... */);
}
常见误区:以为「反射一定慢一个数量级」——在 flat int[] 上,若 C2 能把 Array.get 专用成与 iaload 等价的机器码,仍可能接近手写版(讲演测量,需本地验证)。
HotSpot 的 JIT 闭环:剖析 → 去虚化 → 内联#
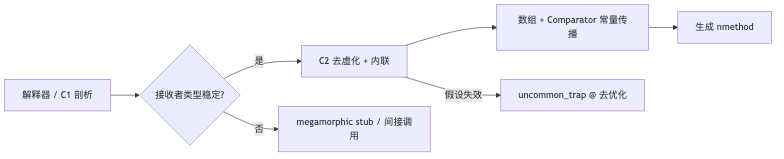
为什么:擦除后的泛型方法在字节码层仍是虚调用;要把 Comparator.compare 与数组元素访问一起常量化,通常必须先有可信的类型剖面,再内联进单一 IR 做寄存器分配与指令选择。
机制/约束:PerformanceTechniques 描述:解释器/C1 记录调用点接收者类型(常与 TypeProfileWidth 相关,JDK 25 默认宽度为 2);C2 在「历史上一种或两种类型」时做乐观检查,失败则 deoptimize 或走 vtable/itable。GraphKit::uncommon_trap 注释写明:中途退回解释器——与汇编里 b.ne uncommon_trap 对应。对泛型排序而言,数组组件类型与 Comparator 接收者类型是两条独立剖面通道:只有二者在 IR 中同时收窄,aastore/aaload 上的 store-check 消除与 compare 内联才会在同一轮优化里「对齐」;任一通道饱和,另一端即使仍单态,也可能拖住整段循环(讲演归纳,属实现层观察而非 JLS 条款)。
怎么做(利于形成单态剖面):
Comparator<Integer> cmp = Integer::compare;
GenericQuickSort.sort(keys, cmp);
常见误区:在微基准里每次换一个新的 lambda 类,却期望达到 Integer::compare 的稳定优化——接收者类不稳定会直接打断闭环。
「好日子」汇编:循环外 guard,循环内直比较#
为什么:读懂生成的 AArch64(或本机 ISA)能判断性能卡在 guard 还是热循环体。
机制/约束:当 comparator 在方法历史上仅见 1–2 种类型时,C2 可在循环外加载 cmp.class 与常量元数据比较,失败则 uncommon_trap;成功则在循环内把 compare 内联为对数组元素的 ldr/cmp(讲演汇编解读,需本机 PrintAssembly + hsdis 核对)。

怎么做:
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly \
-XX:CompileCommand=print,*QuickSort* -jar bench.jar
常见误区:把 uncommon_trap 当成「异常」——它是投机失效时的正常去优化路径,频繁触发才会拖垮吞吐。
Megamorphic 悬崖:剖面饱和之后发生什么#
为什么:插件式 comparator、多租户共用排序内核、或基准里轮换多种 Comparator 实现,会让同一调用点见到多种接收者类型;优化器失去「该赌哪一种」的信号。
机制/约束:讲演将「≥3 种 comparator 类型」描述为饱和剖面,热循环退化为间接调用与大量 spill/setup(幻灯称可比良性路径多 10×+ 指令/迭代——讲演者观点)。相对干净单态,幻灯给出约 2×–5× 的 megamorphic 惩罚区间(讲演者观点,未独立验证)。HotSpot Wiki 同时记载:inline cache 在见到第二种 receiver 时也可能进入 megamorphic 状态并使用 vtable/itable stub——与「第三种饱和」的口语可能指不同子系统(TypeProfileWidth vs IC 状态机),阅读汇编时宜以本机剖面为准。关闭 -XX:UseTypeProfile 会让 C2 更依赖其它路径收集类型信息,讲演用它证明「调用方常量传播」可以部分替代剖面,但该开关默认开启,产品环境不应随意关闭。


怎么做(实验上刻意制造饱和,非生产写法):
Comparator<Integer>[] variants = {
Integer::compare, Comparator.reverseOrder(), (a, b) -> a - b
};
for (var c : variants) GenericQuickSort.sort(copy(arr), c);
常见误区:认为 int[] 一定比 Integer[] 更安全——讲演指出在 bimorphic 布局剖面下,flat primitive 数组可能出现比饱和更陡的 cliff(「flat data is Valhalla challenge」——讲演者观点),Valhalla 时代需要 per-layout 的 code species,而不能假设 primitive 恒赢。
结构性约束:一份优化包与未来的 species#
为什么:若同一 Java 方法在任意时刻只有roughly 一份优化机器码(讲演对现状的描述,未能找到逐字官方文档),则 int/long/Short 等多类型剖面会挤进同一份 nmethod,放大污染。
机制/约束:Valhalla 项目页列出 Parametric JVM——在运行时对泛型类/方法参数化做专用化与优化;讲演用语 species 指「QuickSort::<Integer>sort 路由到仅服务 Integer + 特定 comparator 的算法副本」,属愿景,无现行 Java 语法。JEP 515 与 JEP 483 则让 Leyden 训练运行可把剖析与代码写入 AOT cache——方向与「保留动态编译成果」一致,但不等价于任意 C++ 式模板均持久化。


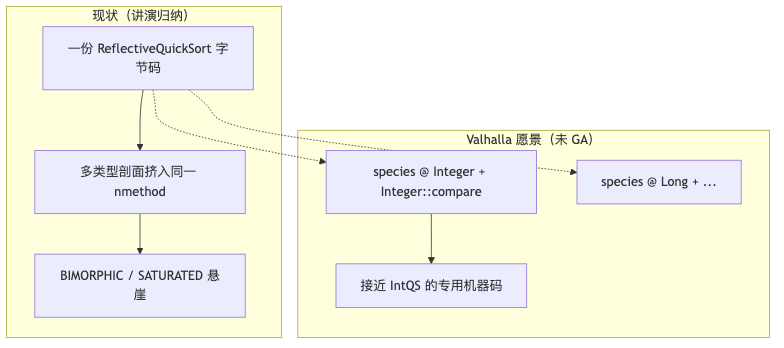
常见误区:把 Leyden AOT 当作「一次训练,永久 C++ 速度」——仍受训练覆盖路径、缓存失效与后续去优化策略约束。
修复原型 A:Hidden Class 克隆换干净剖析#
为什么:在不能立刻改 VM 支持 per-callsite species 时,库层可用新类身份隔离已被污染的 MethodData。
机制/约束:JEP 371 的 Lookup.defineHiddenClass 从 classfile 字节派生不可被常规发现加载的类;讲演实验:读取模板 ReflectiveQuickSort.class → 定义 hidden class → MethodHandle 调用,使优化器对新类重新积累单态剖面,称可将 ~70µs 拉回 ~12µs 量级(讲演实验,Javadoc 未承诺剖析隔离)。限制:嵌套类/多 classfile 难克隆、浪费 code cache(讲演坦诚)。
怎么做:
byte[] tpl = Sort.class.getResourceAsStream("ReflectiveQuickSort.class").readAllBytes();
Class<?> species = MethodHandles.lookup().defineHiddenClass(tpl, true).lookupClass();
MethodHandle sort = MethodHandles.privateLookupIn(species, MethodHandles.lookup())
.findStatic(species, "sort", MethodType.methodType(void.class, Object.class, Comparator.class));
sort.invokeExact(array, comparator);
常见误区:把演示当成框架默认能力——hidden class 不可作普通 API 类型链接,且克隆不能解决所有嵌套/helper 类依赖。
修复原型 B:MethodHandles 强制内联与类型传播#
为什么:当 callee 剖面已饱和,可在调用方用更窄的 MethodType 与常量 comparator 驱动 C2 做类型传播,弱化对 UseTypeProfile 的依赖(讲演实验)。
机制/约束:asType 收窄为 Integer[]、insertArguments 绑定 comparator、dropArguments 保持签名;讲演称配合 hidden class 触发的 MH customization(forceCustomize——非公开 API,本地 JDK 未找到该符号)与 -XX:InlineSmallCode=1g(java 手册 条目:控制可被内联的已编译方法体积,默认 2500,演示值生产慎用)可在 -XX:-UseTypeProfile 下仍达 ~24–28µs(IterQS/Integer[],讲演观点)。

怎么做:
Class<?> ac = Integer[].class;
MethodHandle mh = baseMh.asType(methodType(void.class, ac, ac, Comparator.class));
mh = MethodHandles.insertArguments(mh, 1, comparator);
mh = MethodHandles.dropArguments(mh, 1, Comparator.class);
// forceCustomize(mh); // 讲演实验 helper
java -XX:-UseTypeProfile -XX:InlineSmallCode=1g -jar force-inline-demo.jar
java -XX:+PrintFlagsFinal -version 2>&1 | grep -E 'InlineSmallCode|UseTypeProfile'
常见误区:在生产环境关闭 UseTypeProfile 或把 InlineSmallCode 拉到极大——会改变全局内联启发式,与讲演可控微基准不是同一回事。
旅程总览:坠崖、攀爬与 C++ 的「不完整动态」#
为什么:架构选型要在「静态瀑布构建」与「静态—动态反馈环」之间权衡;JVM 保留 classfile 主副本 + 在线 JIT,C++ 则在 comparator 类型不可见时缺乏等价的重编译与剖析框架(讲演论点)。
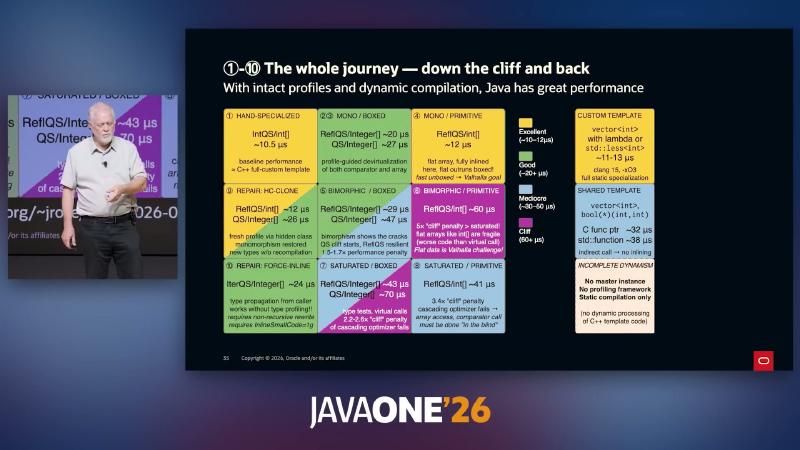
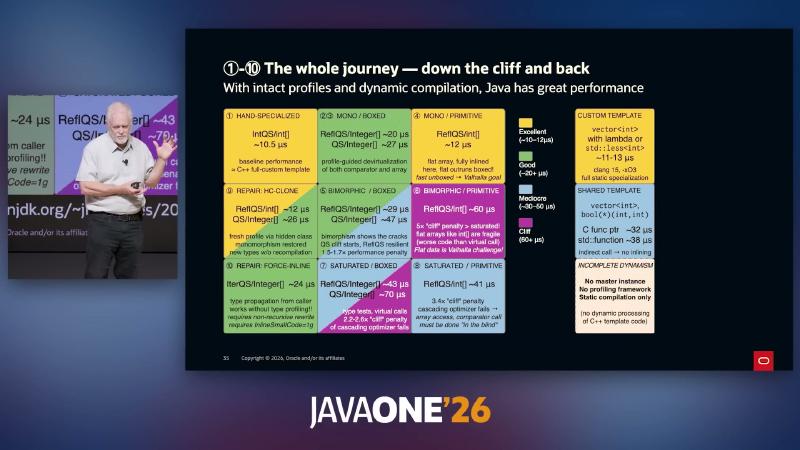
机制/约束:在剖析完整时,Java 可达 HAND-SPECIALIZED / MONO 区(~10.5µs,对标 C++ custom template);沿 BIMORPHIC → SATURATED 下滑出现约 1.5–6× cliff;HC-CLONE 与 FORCE-INLINE 为讲演两种「爬回」原型。作者材料 Dynamic/Static interplay PDF 可访问(HTTP 200),但图中 µs 仍应以本地 JMH 为准。
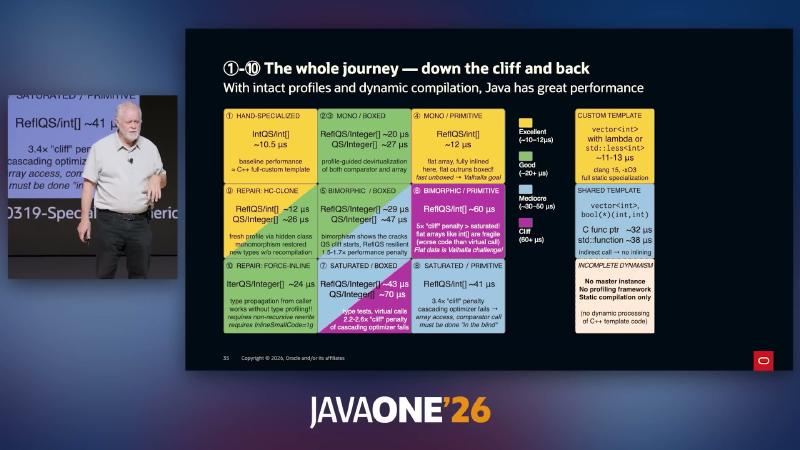

| 区域(讲演标签) | 典型条件 | 近似耗时(讲演) |
|---|---|---|
| HAND-SPECIALIZED | int[] + 稳定比较器 | ~10.5µs |
| MONO / PRIMITIVE | 反射 + flat int[] | ~10–12µs |
| MONO / BOXED | Integer[] + 单态剖面 | ~20µs |
| SATURATED | 多种 comparator 类 | ~70µs 量级 |
| REPAIR: HC-CLONE | hidden class 刷新剖面 | ~12µs(反射路径) |
| REPAIR: FORCE-INLINE | MH 类型传播 | ~24–28µs |
常见误区:用单次微基准结论指导多租户线上排序——应用层拆分 comparator 策略、隔离热路径类加载器,往往比依赖 VM 自动「猜对」更可靠。
工程可操作的诊断顺序(不依赖讲演专用开关):先用 -XX:+PrintCompilation 确认热点是否由 C2 编译;若吞吐异常,再对可疑方法打开 PrintAssembly 查看循环外是否存在类检查 guard、循环内是否仍为 invokeinterface。混合多种 Comparator 实现类做 A/B 时,应固定预热轮次与堆大小,避免把尚未稳定的剖面当成回归——这与 JMH 要求 fork、预热的原因一致,但线上服务还需关注类加载顺序与 JIT 队列延迟,二者不能简单等同。
参考与延伸阅读#
- JLS §4.6 类型擦除
- JLS §4.8 原始类型与擦除补充
- OpenJDK Project Valhalla(含 Parametric JVM 方向)
- Valhalla 设计笔记:同构 vs 异构翻译
- OpenJDK Project Leyden
- JEP 483:Ahead-of-Time Class Loading & Linking
- JEP 515:Ahead-of-Time Method Profiling
- JEP 371:Hidden Classes
- JEP 401:Value Classes and Objects (Preview)
- HotSpot Wiki — PerformanceTechniques(剖析、内联、去优化)
- HotSpot Wiki — PrintAssembly(汇编诊断)
- HotSpot Wiki — RangeCheckElimination(数组范围检查优化)
java.lang.reflect.ArrayAPI 文档java.lang.invoke包概览- OpenJDK JMH README
- John Rose — Dynamic/Static interplay(PDF,2025-08)
- cppreference — C++ 模板


