
死后 JVM 崩溃分析:用 jcmd 读 core,而不是重学一套工具#
HotSpot 进程一旦以 SIGSEGV 等方式退出,运维手里通常有两类工件:JVM 写的 hs_err_pid*.log,以及操作系统写的 core dump(Windows 上常见为 minidump)。前者像「案发现场摘要」,后者才是完整内存镜像。多年来,要在 core 里看到 Java 线程、堆、类元数据,往往得走 Serviceability Agent(SA) 或 jhsdb 这条独立链路;而线上排障早已习惯 jcmd 的子命令。 JEP 528: Post-Mortem Crash Analysis with jcmd 的目标,是把 同一套诊断命令 延伸到 Linux core / Windows 死后环境,通过 process revival 映射崩溃时的 VM 状态,而不是再维护一套 Java 层的镜像实现。
截至 JDK 24/25 的 Oracle jcmd 手册,Synopsis 仍只描述对 存活 PID 的附着;jcmd core.1234 …、-L、-c 等语法以 JEP 正文为准,落地前应以你实际使用的 JDK 构建验证。JEP 状态为 Candidate,目标 Release 27——下文能力边界以 JEP 与可复现命令为主,演讲中的分支名、平台细目等单独标注。
在线排障里,JMX(JConsole、JMC)、JFR、JDI/JVMTI 与统一 JVM 日志各自覆盖监控、录制与断点场景;它们依赖 进程仍存活或可连。一旦 JVM 已死,上述通道大多失效,剩下 hs_err + core + 原生调试器 + SA/jhsdb。JEP 528 要补的,是其中 Java 级视图 这一段与 jcmd 对齐,而不是再发明第四种 CLI 方言。


图:JDK 可服务性工具谱系中,jcmd 承担本地 attach 与 Thread.print / GC.heap_dump 等子命令——死后扩展意在延续这一入口。
图:会议标题与 JEP 528 入口——死后诊断被定位为 jcmd 的扩展,而非全新 CLI。
崩溃工件:文本摘要与内存镜像各管什么#
为什么:生产事故里最先需要的是「能转发、能全文检索」的线索;但 hs_err 给不出可遍历的堆图,也无法替代「某对象在崩溃瞬间是否仍被引用」这类问题。
机制/约束:JEP 528 Motivation 将分工写得很清楚:HotSpot 在致命错误时写出 hs_err_pidXXX.log(失败线程栈、已加载库、VM 版本等);OS 将进程地址空间保存为 core dump。Windows 上演讲常用 minidump 一词;JEP 正文仍以 core dump 统称,未规定 Windows 文件格式细节(属 OS/运维范畴)。
怎么做:
# 收集(Linux 示例)
cp hs_err_pid*.log /case/run-20260517/
cp core.* /case/run-20260517/
ls -la /case/run-20260517/
# 目标侧:允许生成 core(依发行版固化到 runbook)
ulimit -c unlimited
常见误区:只留 hs_err 就关闭工单——许多 Metaspace / 堆 / 锁 问题需要 core 上的 GC.* / VM.*;反过来,只拷 core 却不留 hs_err,会丢掉 JVM 自报的 错误类型、编译线程、VM 参数 等上下文。

图:hs_err 为文本摘要;core/minidump 为 OS 级内存镜像——死后分析通常两者都要。
原生调试器够不到 Java 语义#
为什么:gdb / WinDbg 擅长 库、符号、原生栈;崩溃若发生在 JIT 代码、解释器、GC 屏障 附近,工程师更需要 哪条 Java 线程、锁谁持有、堆顶是什么。
机制/约束:JEP 明确:用 gdb 分析 core 时,无法把 JVM 内部结构直接解释成应用级 Java 状态;解码某个 oop 的 class 需要手工读对象头(参见 JEP 450 对象头)。JEP Alternatives 同时强调:原生调试器仍是 JDK 排障的必要组成部分——jcmd 不是要取代 gdb 的任意地址检视。
怎么做:
gdb /path/to/java core.1852094
# 同一 core,JEP 目标语法(GA 可能尚未支持):
/path/to/jdk/bin/jcmd core.1852094 Thread.print
常见误区:在 ?? () 帧上纠结「缺符号」却忽略 Java 栈;或期望 WinDbg 单独给出 java.lang.Thread.State——那是 JVM 诊断层的事。

图:原生栈里 JVM C++ 符号可见,JIT/解释路径常解析为 ?? (),无法直接对应 Java 方法。
从 SA 双轨维护到单一 jcmd 入口#
为什么: HotSpot Serviceability 中的 SA 能在 运行进程与 core 上暴露 Java 堆与 HotSpot 结构,但 JEP Motivation 指出其实现 brittle、dated,需随 VM 演进持续维护。在线场景里,jcmd 经 Attach API 已承载 Thread.print、GC.heap_dump 等;死后若再维护 jhsdb + SA 平行实现,成本高且易漂移。
机制/约束(部分为演讲者观点):演讲提到 SA 与 HotSpot 源码 约 13 万行 级镜像同步、ZGC 支持不足等——JEP 未给出行数或 ZGC 细节。JEP Goals 是聚焦 jcmd、降低对 jhsdb/SA 的维护投入,并非 立即移除现有工具。
怎么做(统一入口示意):
# 存活 JVM(GA 已支持)
jcmd <pid> Thread.print
# 死后(JEP 528 目标)
jcmd core.1852094 Thread.print
常见误区:在 JEP 落地前假设 jstack/jmap 已废弃——它们仍广泛存在于旧 runbook;死后分析应规划迁移到 jcmd + core,而非混用多套脚本且版本不一致。
Core revival:映射内存,复用既有 DCmd#
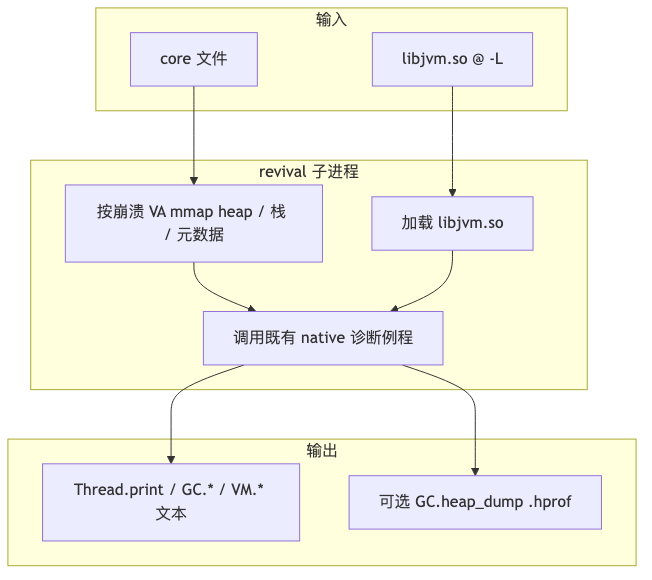
为什么:若死后诊断重写一套「Java 镜像」,将与 HotSpot 内部结构强耦合;JEP 选择 子进程 revival:把 core 按原虚拟地址 映射回来,使 指针仍有效,再调用与 live Attach 相同的 native 诊断实现。
机制/约束:Reviving a core dump 规定:
jcmd启动子进程,mmap core,恢复 Java heap、元空间、线程栈 等;- 在原地址加载崩溃时的
libjvm.so(Windows 为jvm.dll,演讲用语); - 不执行 Java 代码、不触发 GC;可调用解释数据结构的 native JVM 函数;
- 事后分析只需 core + 崩溃 JVM 二进制;不必 加载业务
.so全集(跨机搬运友好)。
OpenJDK jmm.h 中的 ExecuteDiagnosticCommand 与 live 路径一致;幻灯中的 DCmd::parse_and_execute 为实现层说法,非 JEP 正文符号。
怎么做(sandbox 试验构建,分支名未在公开 openjdk/jdk 验证,属演讲者口径):
# 需 JEP 528 实现所在的 JDK 构建
build/*/images/jdk/bin/jcmd -L /prod/jdk/lib/server/libjvm.so ./core.1852094 Thread.print
常见误区:以为 revival 会 继续跑业务线程——子进程只是 只读重演内存布局;在 core 上执行 GC.run、JFR.start 等 运行态 命令不符合 JEP Non-Goals / Future Work(Java 实现的 DCmd 与 revival 不兼容)。

图:live 路径上 jcmd → Attach API → DCmd::parse_and_execute;死后改为对 revival 子进程中的 VM 映像发同类命令。

图:helper 从 core 映射 Java Heap、线程栈 等于崩溃 VA;helper 自身 libc 可与生产不同地址,不影响 JVM 结构解读。
Thread.print:锁与 safepoint 的可信度#
为什么:死后最先要回答的往往是 谁阻塞谁、崩溃线程卡在何处。
机制/约束:JEP 将 Thread.print 列入死后 26 个可用命令之一(相对 live 约 57 个)。输出含 java.lang.Thread.State、BLOCKED (on object monitor)、_at_safepoint 等,与 live 线程转储 同类。
怎么做:
jcmd core.1852094 Thread.print > threads-at-crash.txt
# 与事故前 live 抓取对比(若有)
diff threads-live.txt threads-at-crash.txt
常见误区:把死后输出里的 cpu=0.95ms 当作性能数据——演讲者观点:对已死进程 CPU 时间无意义;JEP 示例行仍含 cpu= 字段,规范未定义 core 上该字段语义,分析时应忽略。

图:jcmd core.1852094 Thread.print 中 Thread-2 为 BLOCKED (on object monitor),HotSpot 侧 _at_safepoint,栈顶 Threads$ThreadRunnable.runnableMethod2。
堆诊断:GC.heap_info、GC.heap_dump、GC.class_histogram#
堆布局与 hprof 导出#
为什么:hs_err 里堆地址需要人工拼接的时代,导出 .hprof 往往依赖 SA 脚本;统一 jcmd 可降低 runbook 碎片。
机制/约束:JEP 死后列表含 GC.heap_info、GC.heap_dump。GA 手册对 live 的语义: GC.heap_info 报告布局;GC.heap_dump 生成 .hprof(filename、-all 等选项)。core 上是否支持这些选项的组合,以实现为准。
怎么做:
jcmd ./core.1852094 GC.heap_info
jcmd ./core.1852094 GC.heap_dump /tmp/postmortem.hprof
常见误区:认为 GC.heap_dump 会触发 GC——在死后 revival 中 不发生 GC;导出的是 崩溃瞬间冻结的堆图。
类直方图#
为什么:需要快速判断 byte[]、某业务类 是否在崩溃时异常膨胀,而不立刻开 MAT。
机制/约束:GC.class_histogram 在 GA 中标记 Impact: High(与堆大小相关);死后输出为 crash site 快照,#instances / #bytes 列与 live 格式一致。模块后缀如 (java.base@27-internal) 来自演示 JDK,非规范固定字符串。
怎么做:
jcmd core.1852094 GC.class_histogram | head -40
常见误区:用直方图做 引用链分析——它只有 按类聚合;引用链仍需 heap dump 或 JEP Future Work 中的 任意对象检视(演讲称规划中的 VM.inspect,JEP 未使用该符号名)。
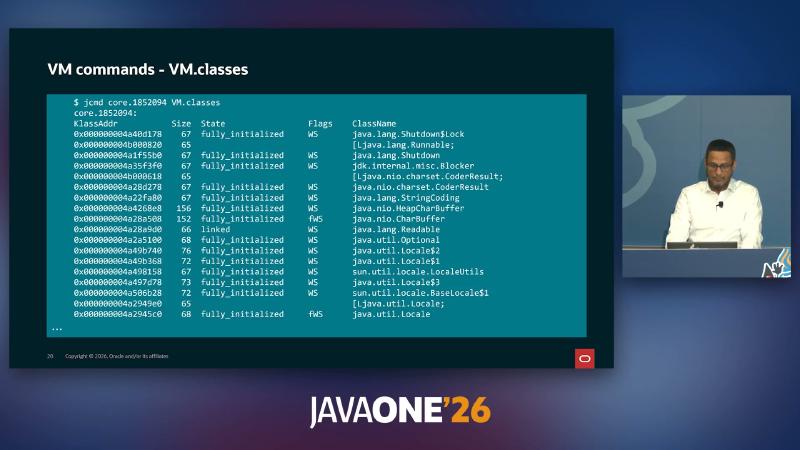
图:VM.classes 表头含 KlassAddr Size State Flags ClassName;示例行 fully_initialized、java.lang.Shutdown、jdk.internal.misc.Blocker 等。
Metaspace 用量#
为什么:Metaspace OOME 或 class space 压力类崩溃,需要在死后核对 used / committed / reserved 与 shared classes。
机制/约束:JEP 含 VM.metaspace;手册列有 basic、show-loaders、by-chunktype 等选项。默认输出粒度 以实现为准。
怎么做:
jcmd core.1852094 VM.metaspace > meta-at-crash.txt
常见误区:只盯 used 忽视 reserved——与 hs_err 对照时,两者可能讲述 提交 vs 预留 的不同侧面;应以 VM.metaspace 易扫读行为主、hs_err 为交叉验证。

图:Metaspace used 72K, committed 192K, reserved 1114112K;497 classes (492 shared) 及 chunk 级 Non-Class / Class 分段。
CLI:-L、-c 与 help 的匹配规则#
为什么:core 常被拷到笔记本分析;jcmd 版本 与 崩溃 JVM 版本 可能不同,但 libjvm.so 必须对齐。
机制/约束(JEP post-mortem environments):
-L /path/to/libjvm.so:指定崩溃 JVM 的二进制;-c ./core:参数为 core 文件,避免与 main class 名 冲突;- 分析用
jcmd可与崩溃 JDK 不同版本,但须能加载 崩溃时的 JVM 二进制; - 死后环境须与崩溃点 相同 OS 与 CPU 架构。
演讲者观点:jcmd <core> help 只列出 core 可用子集(JEP 用「57 中有 26 个」描述范围,未单独定义 help 过滤算法);OL9/RHEL9 上与生产一致的 libc.so 映射可降低 revival 失败率——非 JEP 条文。
怎么做:
jcmd -c ./core.1852094 help
jcmd -L /opt/jdk-prod/lib/server/libjvm.so ./core.1852094 Thread.print
常见误区:笔记本装了 JDK 21 的 jcmd,却用 JDK 17 的 core 却不传 -L 指向 17 的 libjvm.so;或把 core 拷到 不同架构 的机器上分析。

图:死后接口从 jcmd <pid> 扩展为对 $COREFILE 执行 help 与子命令。
能力边界与交付节奏#
为什么:避免对 未 GA 能力过度承诺,也避免用 jcmd 替代 所有 原生调试。
机制/约束:
| 主题 | JEP / 事实 | 演讲者补充 |
|---|---|---|
与 gdb 关系 | Non-Goals:不能替代原生调试器 | WinDbg 场景类比 |
| 运行态命令 | 死后 无 JFR.start/JFR.stop 等 | GC.run 亦不在死后列表 |
| 任意对象检视 | Future Work:inspect arbitrary Java objects | 口语 VM.inspect,无 JDK 27 排期承诺 |
| 平台 | Goals:Linux + Windows;Future Work:macOS | 细化为 x64 / AArch64 三元组 |
| 状态 | Candidate,Release 27,JDK-8328351 | sandbox 分支 jcmd_core_process_revival 未在公开 GitHub 检出 |
怎么做(边界自检):
jcmd core.1852094 help | rg -i jfr # 预期无 JFR.start/stop
常见误区:在 core 上找 JFR.start;或认为 jcmd 能 inspect 任意地址的对象——当前应使用 gdb/jhsdb,直至 Future Work 落地。

图:JEP 528 将 broad selection of jcmd commands 带到 Linux x64 / Linux aarch64 / Windows x64;工程状态为向 code review 推进(幻灯口径)。
建议的死后排查顺序#
若你维护的是 HotSpot 崩溃 runbook,在 JEP 528 可用后,可按「先廉价、后沉重」收敛证据链:

- 读
hs_err:信号、问题线程、VM 版本、-XX:参数。 Thread.print:锁、Java 栈、safepoint。VM.metaspace/VM.classes/VM.classloader_stats:元空间与类加载器。GC.class_histogram:对象组成是否异常。- 需要 MAT 时
GC.heap_dump。 - VM 原生缺陷或
jcmd无法覆盖的地址,再用gdb。
参考与延伸阅读#
- JEP 528: Post-Mortem Crash Analysis with jcmd — 死后
jcmd的权威范围、revival 机制与 26 个命令列表 - JEP 528 — Reviving a core dump — 子进程映射、禁止执行 Java/GC
- JEP 528 — jcmd in post-mortem environments —
-L、-c、跨版本与 OS/CPU 约束 - JEP 528 — Non-Goals — 不替代
gdb、不运行 Java 代码 - JEP 528 — Future Work — 任意对象检视、class dumping、与 JFR 的边界
- JDK-8328351 — JEP 528 跟踪 Issue
- Oracle JDK 24
jcmd手册 — live 子命令语义(Thread.print、GC.*、VM.*) - Oracle JDK 24
jhsdb手册 — 现有 core 分析入口对照 - HotSpot Serviceability — Serviceability Agent 与工具生态
- HotSpot Serviceability — Serviceability Agent — SA 能力与维护背景
- JEP 450: Compact Object Headers — 原生调试器手工解码 oop 时的对象头参考
- OpenJDK
jmm.h— ExecuteDiagnosticCommand — Attach 路径上的诊断命令派发 - Wikipedia: Core dump — OS 级 core 概念
- Java SE Troubleshooting Guide — Oracle 官方排障总览
- Unified JVM Logging — 与死后分析互补的运行期日志



{kind=link}