
开放模型上生产:Java 团队的 LangChain4j 集成路径#
把生成式 AI 放进已有 Spring 服务,难点往往不在「能不能调通一个 ChatCompletion」,而在能否用同一套 Java 代码在本地 Ollama、团队自托管的 OpenAI 兼容端点,以及 Azure AI Foundry 托管推理之间切换,同时把工具调用、RAG 与基本质量门禁做成可观测、可回滚的管线。下文按工程能力块组织:集成层、本地运行时、演示服务、RAG 与评测、容量延迟、托管迁移与安全——论断尽量绑定 LangChain4j 文档、Ollama API、JEP 444 与可复现命令;未在公开文档中复核的数字与案例标注为演讲者观点。
演示源码可通过 aka.ms/opengenai 获取(HTTP 301 至 gen-ai-with-open-models)。仓库按 Demo 1(本地推理 + 工具调用)与 Demo 2(RAG + 评测)拆分脚本,便于在 JavaOne 现场逐段复现;生产落地时则应把「能跑通」与「能上线」拆开:前者验证集成面,后者补齐持久化、鉴权、护栏与 SLO。

统一集成层:LangChain4j 与 OpenAI 兼容端点#
为什么#
Java 团队若沿用「每个模型一个 SDK」,换端点就要改业务层。演讲中的做法是:用 LangChain4j 的 OllamaChatModel、OpenAiChatModel 与同一套 AiServices、@Tool、EmbeddingModel / EmbeddingStore,把 Python 样例里的 base_url + api_key 迁到 Bean 配置。演讲者观点:切换 Ollama、vLLM 或云端时「尽量不改业务 Java」——实际仍需改 baseUrl、apiKey、modelName 等 Bean,而非零 diff。
机制与约束#
- Ollama 集成 默认
http://localhost:11434;OpenAI 兼容路径 为/v1/chat/completions。 @Tool属于 LangChain4j function calling(Tools 教程),与 MCP 是不同协议层;混用概念会导致架构图画错边界。- 演示仓库
OllamaConfig中temperature为0.7;要点草案写0.2以利 grounded 回答——二者不冲突,属可调超参。
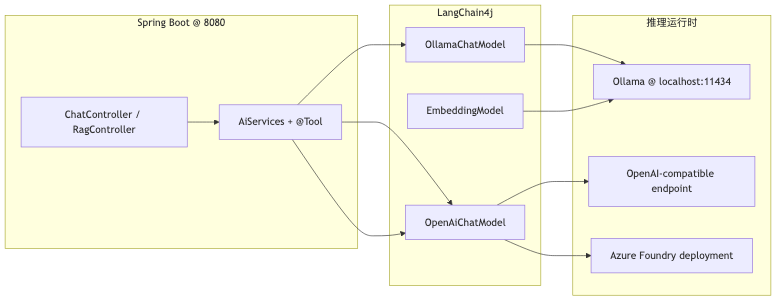

OllamaChatModel.builder()、@Tool 与 AiServices.builder。
怎么做#
OllamaChatModel chat = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3.1:8b")
.temperature(0.7)
.build();
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"llama3.1:8b","messages":[{"role":"user","content":"hello"}]}'
常见误区#
- 把
@Tool当成 MCP Server 暴露——二者可并存,但语义与运维边界不同。 - 假设换云厂商时 Java 业务类完全不动:至少配置类与鉴权头会变。
- 在
AiServices接口上堆过长@SystemMessage,却不用MessageWindowChatMemory控制窗口——长对话会挤占留给 RAG context 的 token(AiServices 教程 中的 memory 组件可按需启用)。
本地运行时:Ollama 与演示模型组合#
为什么#
在接云端账单与合规评审之前,用本地 Ollama 复现延迟、量化与工具调用行为,成本可控。演示固定组合:llama3.1:8b(对话)、mistral:7b(可切换)、nomic-embed-text(嵌入),与 演示 README 一致。
机制与约束#
- CLI
ollama pull/ollama list对应 RESTPOST /api/pull、GET /api/tags(Ollama API)。 - Linux 官方安装为
curl -fsSL https://ollama.com/install.sh | sh;字幕中的apt-get install ollama未在官网核实。 - GPU/显存由 Ollama 调度属演讲者观点;量化标签(如 Q4)见各模型卡片,无统一「质量-内存」对照表。
## Demo 1: Local Inference + Tool Calling 与 Production-Ready GenAI with Open Models for Java Teams。
怎么做#
ollama pull llama3.1:8b
ollama pull mistral:7b
ollama pull nomic-embed-text
ollama list
application.yml 中 ollama.base-url: http://localhost:11434,chat-model / embedding-model 与上一致(application.yml)。
常见误区#
- 未
pull嵌入模型就调/ingest——RAG 链路会在嵌入步骤失败。 - 把演示
mistral:7b当成生产默认——应按自有 benchmark 重选(见选型幻灯)。 - 在笔记本上同时跑 70B 全精度与大型 Spring 堆——即使 JVM 未 OOM,节点仍可能因 Ollama 常驻权重而 swap(演讲者观点:模型内存多在 heap 外)。
选型幻灯还强调六步:定义任务类型(chat / RAG / code 等)→ 设定延迟与内存上限 → 用自家数据 benchmark → 评估 GGUF Q4/Q5/Q8 量化 → 比较「7B @ 50 tok/s」与「70B @ 5 tok/s」谁更符合 SLA → 固定模型版本并准备回滚配置。公开榜单只能作初筛,不能替代领域数据上的回归。

Spring Boot 最小可运行集成#
为什么#
Java 21 + Maven 的 Spring Boot 应用给团队一条可复制的联调入口:构建、启动、用 curl 打 REST,再叠工具与 RAG。
机制与约束#
- pom.xml:
java.version21,Spring Boot 3.4.x。 server.port: 8080,入口OpenModelsDemoApplication。- OCR 中
808@为识别噪声,实际端口 8080。
mvn clean package -DskipTests、mvn spring-boot:run。
怎么做#
mvn -q -DskipTests clean package
mvn -q spring-boot:run
curl -sS "http://localhost:8080/chat?message=ping"
常见误区#
- 跳过
ollama serve只起 Spring——LLM 调用会连不上11434。 - 在 CI 里跑完整 Demo 却不预留 GPU/CPU 与模型拉取时间。
- 把
-DskipTests当作长期策略——演示可以跳过测试,上线前应恢复针对 Controller 与 ingest 路径的契约测试。
Tomcat 在 8080 监听、context path '/' 与 OCR 中 Started OpenModelsDemoApplication 日志一致,说明这是一个标准 Spring MVC 外壳,而非独立 CLI;团队可把同一 JAR 部署到 K8s,只需把 ollama.base-url 换成集群内 Service 名称。
对话与工具调用:从 /chat 到 /chat/tools#
为什么#
先验证纯生成(/chat),再让模型在需要时调用确定性后端(/chat/tools),把「必查库存」从幻觉风险里拆出去。
机制与约束#
- ChatController:
@GetMapping("/chat"),@Qualifier("chatAssistant")注入,chatAssistant.chat(message)。 - 工具路径:
@GetMapping("/chat/tools")→toolAssistant;InventoryTools 用@Tool+@P("Product SKU"),Map模拟库存(JDK-21→ 150),非外部 ERP。
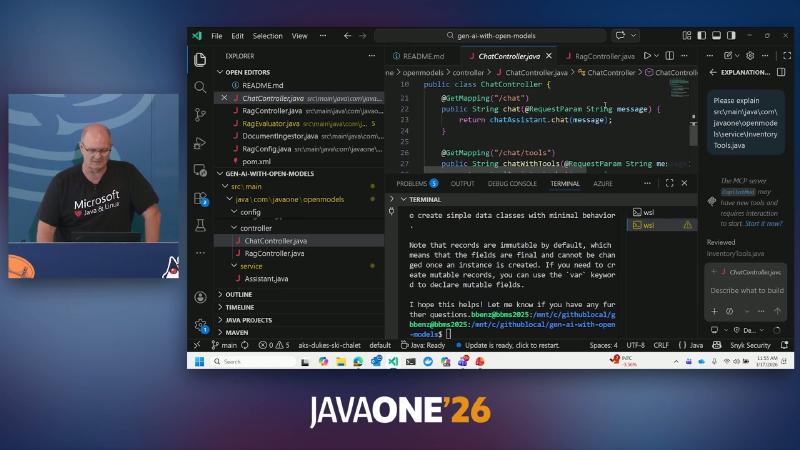
public class ChatController 与 @GetMapping("/chat")。
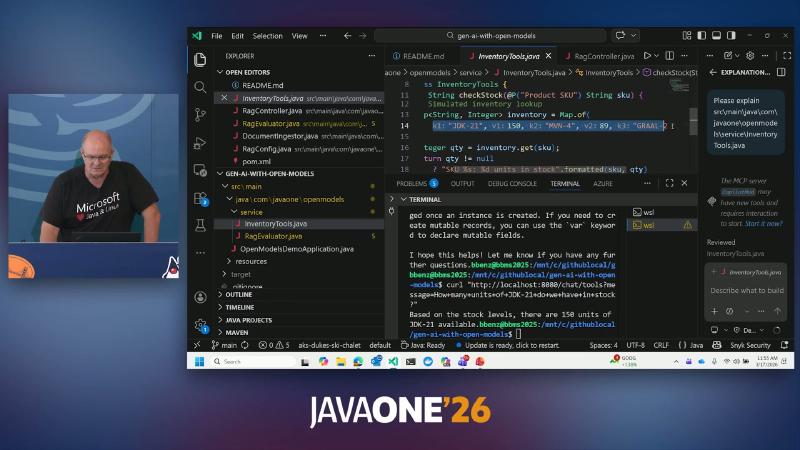
InventoryTools 中 String checkStock(@P("Product SKU")。
怎么做#
curl "http://localhost:8080/chat?message=What+is+the+Java+record+keyword?"
curl "http://localhost:8080/chat/tools?message=How+many+units+of+JDK-21+in+stock?"
@Tool("Look up current stock level for a product by SKU")
String checkStock(@P("Product SKU") String sku) {
return Map.of("JDK-21", 150).getOrDefault(sku, 0) + " units";
}
常见误区#
- 工具返回自由文本却不校验 SKU——模型仍可能编造未查询的商品。
- 在 system prompt 里塞用户可控指令而不隔离——增加 prompt injection 面(生产需输入护栏,见后文)。
- 为「省事」只暴露
/chat而不做工具路由——库存、工单、定价类问题应走确定性后端;演示中/chat/tools与/chat分离正是为了对比幻觉与 grounded 工具结果。
InventoryTools 返回形如 "SKU %s: %d units in stock".formatted(sku, qty) 的字符串(OCR 可见 formatted 片段),便于模型把工具输出复述给用户,同时保持数据源在 Java 侧可控。
RAG:摄取、问答与启发式评测#
为什么#
企业文档型问答需要「答案有据可查」:先 chunk + 嵌入 + 检索,再生成;更换模型或分块策略后,用自有 golden set 做回归,避免只靠肉眼试 prompt。
机制与约束#
- DocumentIngestor:
FileSystemDocumentLoader、DocumentSplitters.recursive,rag.chunk-size: 500、chunk-overlap: 50,EmbeddingStoreIngestor写入 in-memory store。 POST /ingest返回documents_ingested、embedding_model、store(演示为 3 份docs/样例)。GET /ask经 RagConfig 的EmbeddingStoreContentRetriever+ragAssistant;样例问虚拟线程时,java21-features.txt 与 JEP 444 一致——事实来自文档,表述由 LLM 组织。- RagEvaluator:3 条
EvalCase,computeFaithfulness等为关键词重叠启发式(源码注释Simple keyword overlap metric),非 RAGAS 等行业基准;OCR 中context_precision≈0.27等为单次演示跑分,不可外推。
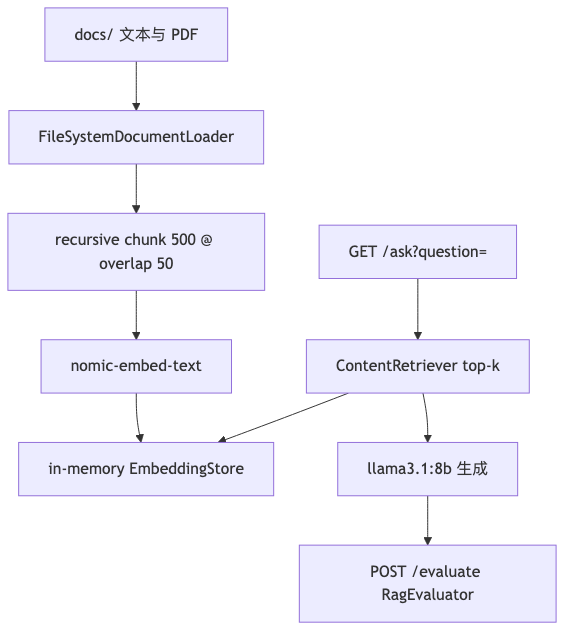
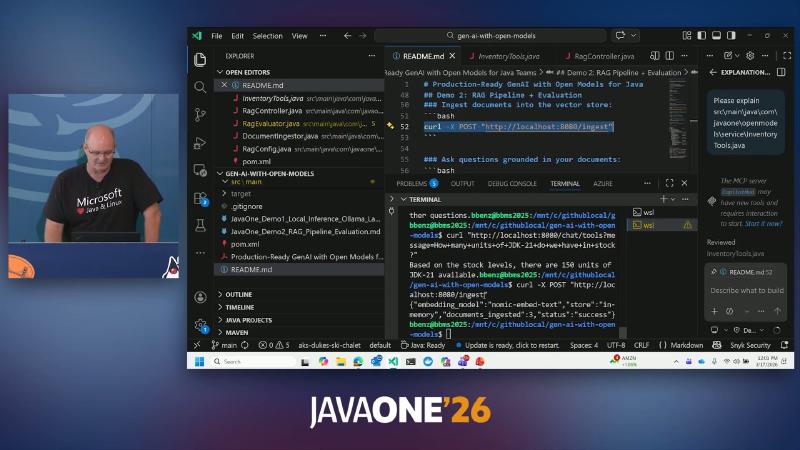
## Demo 2: RAG Pipeline + Evaluation 与 ### Ask questions grounded in your docume。
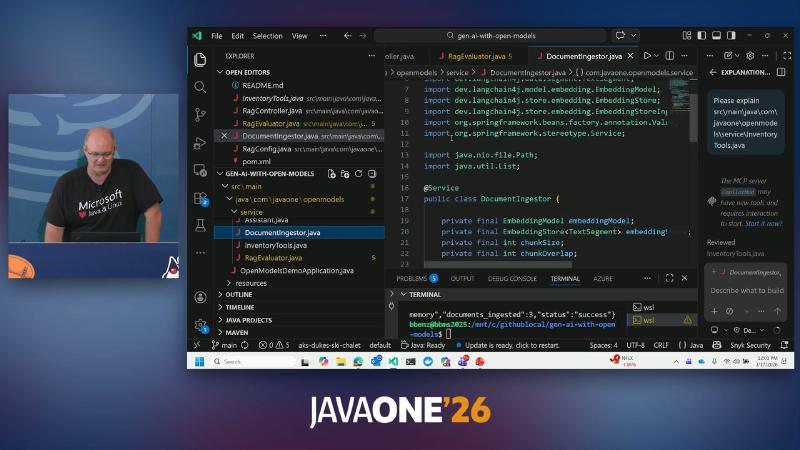
DocumentIngestor.java 与 import dev.langchain4j.model.embedding.EmbeddingModel。
public class RagEvaluator 与 faithfulness / context precision 相关逻辑。
怎么做#
curl -X POST "http://localhost:8080/ingest"
curl "http://localhost:8080/ask?question=What+are+virtual+threads+in+Java+21?"
curl -X POST "http://localhost:8080/evaluate"
常见误区#
- 把演示
/evaluate分数当作 SLA 合同指标。 - chunk 过大导致 context 稀释,过小导致语义破碎——需按文档类型调
chunk-size/overlap。 - 生产仍用 in-memory store——重启即失索引;应换持久化向量库(演示未覆盖)。
- 混淆 faithfulness(答案是否忠于检索片段)与 answer relevance(答案是否切题)——
RagEvaluator对二者分别用启发式打分;若要对外报告,应改用 RAGAS、DeepEval 等框架并固定数据集版本。
POST /evaluate 返回的 average_latency_ms、source_accuracy 等字段适合作为变更前后对比的门禁,而非绝对质量承诺。更换 llama3.1:8b 为其他开放权重后,应重新 ingest 并跑一遍 evaluate,观察 faithfulness 与 context precision 是否同向变化。
容量、延迟与节点规划#
为什么#
「JVM 调优完成」不等于节点稳定:Ollama 模型权重常驻 RAM,通常在 heap 外,仍与 -Xmx 争用同一台机器;K8s 缩容到零会换来冷启动 TTFT(演讲者观点)。
机制与约束#
- Ollama Modelfile 参数
num_ctx、keep_alive;API 支持stream(Ollama API)。 - 幻灯列举:Streaming、Prompt caching、KV-cache / num_ctx、Batch、Model warmup、Right-size context、Hardware matching(量化 CPU vs 全精度 GPU)。

怎么做#
# 容量草表(单侧运维,演讲者观点)
节点 RAM 128Gi − JVM -Xmx 24Gi − Ollama resident ~60Gi − OS/cache ≈ 余量
@Component
class LlmWarmup implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) {
chatAssistant.chat("ping");
}
}
常见误区#
- 只看 tokens/s 不看 TTFT——交互式聊天首 token 更敏感。
- 盲目增大
num_ctx——上下文越长,单次推理越慢(官方参数表可证存在 trade-off)。 - 未开 streaming 却让前端干等整段 JSON——用户感知的「卡顿」往往来自首 token,而非总耗时;LangChain4j Ollama 集成文档含 streaming 示例,可与 Spring
SseEmitter或 WebFlux 组合。
MoE(Mixture of Experts)类模型在幻灯中与量化、TTFT 并列介绍:总参数量大但每步只激活子集专家,适合在延迟预算内追求能力上限。演讲者观点:托管侧(Foundry NIM)与自建 vLLM 的 MoE 运维复杂度高于稠密 7B/8B,选型时应把弹性与回滚算进总成本。
托管迁移:Azure AI Foundry 与 OpenAI 兼容 REST#
为什么#
本地验证后,可把同一 LangChain4j 调用面指向 Azure AI Foundry 上托管的开放权重部署(演示幻灯为 NVIDIA Nemotron-3-Super-NIM-microservice),由平台承担 GPU 与弹性(ACA/AKS/KEDA 等为 Azure 通用能力,未与演示仓库绑定验证)。
机制与约束#
- Azure 聊天补全形态:
POST https://{endpoint}/openai/deployments/{deployment-id}/chat/completions?api-version=...(Azure OpenAI REST);api-version必须以部署页为准——草案中的2024-05-01-preview与当前 Learn 示例(如2024-10-21)可能不一致。 - Java 侧可用
OpenAiChatModel(自定义baseUrl)或 AzureOpenAiChatModel(deploymentName)。 - 幻灯/OCR 描述 Nemotron 120B 总参 / 12B active、LatentMoE、MTP、NVFP4——本次未能从 Microsoft Learn 全文复核;正文引用门户模型卡为准。Hugging Face 上同名仓库链接在核验时返回 404,写死参数量有风险。
怎么做#
curl "$FOUNDRY_ENDPOINT/openai/deployments/$DEPLOYMENT/chat/completions?api-version=$API_VERSION" \
-H "api-key: $AZURE_API_KEY" \
-H "Content-Type: application/json" \
-d '{"messages":[{"role":"user","content":"hello"}]}'
OpenAiChatModel.builder()
.baseUrl(System.getenv("FOUNDRY_BASE_URL"))
.apiKey(System.getenv("AZURE_API_KEY"))
.modelName(System.getenv("DEPLOYMENT_NAME")) // 以部署名为准
.build();
常见误区#
- 把 Foundry deployment name 写成 Hugging Face repo id。
- 忽略
api-version查询参数——Azure 与裸 Ollama 本地 API 的版本策略不同(见下表)。 - 认为「上云就不用关心开放权重合规」——Foundry 强调模型溯源(演讲者观点:相对 Hugging Face 自选权重需自评 license 与安全),法务与数据驻留仍需单独评审。
演示未包含 Foundry 分支的 Spring Profile;落地时常见做法是 application-local.yml 指向 Ollama,application-prod.yml 注入 FOUNDRY_BASE_URL 与 AZURE_API_KEY,并对同一 Assistant 接口做金丝雀流量对比延迟与成本。
| 端点族 | 版本机制 |
|---|---|
| Azure OpenAI / Foundry | URL 查询 api-version |
Ollama 原生 /api/* | 文档未要求 api-version |
Ollama OpenAI 兼容 /v1/* | 客户端形态兼容 OpenAI |
开放模型的安全层#
为什么#
从 Hugging Face 等渠道拉取的权重通常不带商业 API 那套强制内容过滤;把未审查模型直接暴露给终端用户,合规与品牌风险由应用方承担。
机制与约束#
- 幻灯建议:Input guardrails(注入、PII、话题黑名单)→ Model → Output guardrails(毒性、事实性、格式)→ Human review。
- LangChain4j 提供 ModerationModel 与
OpenAiModerationModel;演示仓库未实现护栏 Controller——属生产扩展。 - Llama Guard 等为可选本地方案,演示代码未验证。

怎么做#
public String safeChat(String user) {
if (moderation.isViolating(user)) {
throw new ResponseStatusException(HttpStatus.BAD_REQUEST);
}
String out = llm.generate(user);
return moderation.isViolating(out) ? "[blocked]" : out;
}
常见误区#
- 只在输出侧做 moderation——越狱 prompt 已进入模型上下文。
- 无 flagged 日志与人工升级队列——安全层不可运营。
- 把 OpenAI Moderation API 当作唯一方案——离线或主权云场景可改用
ModerationModel的其他实现或 Llama Guard 类本地分类器,但需自行维护模型版本与误杀率。
开放权重与托管 API 的差异在于:过滤责任默认在应用方。幻灯中的 input/output guardrails 与 LangChain4j ModerationModel 是同一思路的工程化——先拦截再生成,再拦截再返回,可疑样本进入人工复核队列,而不是仅在前端展示免责声明。
收尾:资料入口与证据边界#

https://aka.ms/opengenai 与议题「Production-Ready GenAI with Open Models for Java Teams」。
已核实(可对照仓库与官方文档):LangChain4j + Ollama 集成模式;演示端点 /chat、/chat/tools、/ingest、/ask、/evaluate;JEP 444 与样例文档一致性;Azure REST 形状与 LangChain4j 双集成类。
演讲者观点或未复核:AT&T 等降本案例、Foundry 目录模型数量、128Gi 容量草表、Nemotron 精确架构参数在 Learn 上的正文、护栏在生产环境的具体 SLA。
若你已在本地跑通 Demo 1/2,下一步通常是:持久化向量库、用真实 benchmark 替换 RagEvaluator 启发式、按节点 RAM 预算选定量化档,并在 Foundry 部署上用门户给出的 api-version 做金丝雀。整条路径的核心收益,是把「模型端点」变成可替换的配置,而不是散落在各 Controller 里的硬编码 URL。
参考与延伸阅读#
- 开放 GenAI 演示资料(aka.ms)
- gen-ai-with-open-models 演示仓库
- LangChain4j 文档首页
- LangChain4j Ollama 集成
- LangChain4j Tools(Function Calling)
- LangChain4j RAG 教程
- LangChain4j Azure OpenAI 集成
- Ollama 模型库
- Ollama OpenAI 兼容说明
- Ollama HTTP API(GitHub)
- Ollama Modelfile 参数
- JEP 444: Virtual Threads
- Microsoft Foundry 文档
- Azure OpenAI REST API 参考
- Spring Boot 3.4 参考文档


