
用代码反射把 Java 内核送到 GPU:HAT 与 Project Babylon 的工程切面#
要在 JVM 里写并行计算,常见路径是 parallelStream 或结构化并发——它们仍受 CPU 线程数约束。若要把同一份业务逻辑落到 GPU 的数万线程上,传统做法是手写 CUDA/OpenCL,再用 JNI 粘合;这对 Java 团队意味着第二套语言、第二套构建,且平台绑定明显。Project Babylon 的 Code Reflection 与 HAT(Heterogeneous Accelerator Toolkit) 走另一条路:保留 Java 写法,在编译期生成可变换的 SSA 代码模型,经多阶段 IR 变换后交给可插拔后端(OpenCL、CUDA、纯 Java 顺序执行等)。
本文从工程视角拆解两条主线:(1)语义保真——在 AST 与字节码之间取得可变换的 IR;(2)设备可消费——把数组访问、过程间调用、buffer 读写模式降到后端与 FFI 能理解的 invoke 与访问类型。文中性能数字、IR 等价性等若无官方基准,一律标明边界;API 以 OpenJDK 孵化稿与 openjdk/babylon 的 code-reflection 分支为准。

为什么需要介于 AST 与字节码之间的代码模型#
AST 保留过多句法噪声,难以做跨语言 lowering;字节码则为 JVM 执行优化,丢失大量源级语义(循环变 goto、窄类型提升等)。JEP draft 8361105 与 Code Models 文章 将 code model 定位为「保真度介于 AST 与 bytecode 之间」的不可变树:元素为 operation / body / block,采用 SSA,设计受 MLIR/LLVM 风格编译器影响。仅标注 @Reflect(孵化模块 jdk.incubator.code)的方法或 lambda 会由 javac 把模型写入 class file,运行时通过 Op.ofMethod 等 API 取出根节点 CoreOp.FuncOp,再 transform 生成新模型并可回写为字节码。
机制与约束:每个 block 必须以终止 op(return、分支等)结束;操作用 %n 引用 SSA 结果。变换是「遍历旧模型 + 用 block builder 构造新模型」,模型本身不可变。
最小示例(与 JEP 8361105 示例 同族):
import jdk.incubator.code.Op;
import jdk.incubator.code.Reflect;
import jdk.incubator.code.dialect.core.CoreOp;
@Reflect
static int squareKernel(int i, int[] array) {
array[i] = array[i] * array[i];
return 0;
}
// 运行时:Optional<CoreOp.FuncOp> m = Op.ofMethod(Square.class.getDeclaredMethod("squareKernel", ...));
// m.ifPresent(f -> f.transform(transformer));
遍历与构造:对已有 FuncOp 可 elements() 流式访问 block/body/op;新建逻辑时用 Block.Builder 追加 op,并保证每个 block 以终止 op 结束。打印 SSA 文本(func @"squareit" (%0 : ...) -> { %1 = var.load ...; return %7; })是调试变换最可读的方式,与 IDE 里看到的 Java 源码并非一一逐行对应。
常见误区:把 code model 当成 AST 或反汇编 bytecode 的替代品;未标 @Reflect 时 Op.ofMethod 返回 empty,后续图构建会直接失败;在 transform 中直接修改旧节点——应始终产出新 FuncOp。
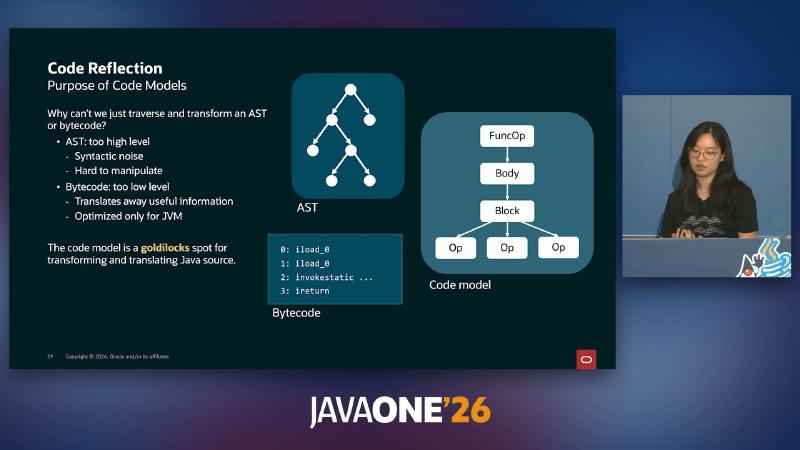



HAT 栈:Panama 内存、代码反射与可插拔后端#
HAT 用 Panama Foreign Function & Memory API(MemorySegment、MemoryLayout)描述堆外 buffer,用 Babylon 代码反射读取/变换 kernel 的 FuncOp,再通过 Accelerator / ComputeContext 把 NDRange 派发到具体后端。官方 HAT README 与 matmul 文章 列出的运行后端包括 ffi-opencl、ffi-cuda、java-seq(CPU 顺序,便于调试)等;构建产物形如 hat-backend-ffi-opencl-1.0.jar。PTX、SPIR-V 在 Babylon 路线文中作为 GPU 代码生成探索出现,独立 SPIR-V/HIP 运行后端在已核对 README/Config 中未列出——若听到 HIP 后端,应视为未验证扩展名。
为什么:把「写什么」与「跑在哪」解耦,避免每个项目重写 JNI + 厂商 runtime 胶水。
怎么做(仓库 code-reflection 分支可复现):
cd hat
java @.bld
java @.run java-seq life
java @.run ffi-opencl life
底层 JVM 通常需要:--enable-preview --add-modules=jdk.incubator.code --enable-native-access=ALL-UNNAMED(见 README)。
hat.java 的 bld 目标会编译 hat-core、hat-optkl、各 hat-backend-ffi-*,并触发 cmake 构建 native 封装;终端 OCR 中反复出现的 We will need jextract to create jextracted backends 指向 OpenCL/OpenGL 等需要头文件绑定的路径,与 kernel IR 算法无关,但会挡住「第一次 clone 就跑 demo」的预期。
常见误区:以为换后端只改一个字符串即可而不重建 native 依赖;忽略预览/孵化模块开关导致 Op 类找不到;把 Config 里的 PTX 选项误解为独立「PTX 后端」——它表示 CUDA 路径可传递 PTX 而非 C99 源码(见 Config 注释)。
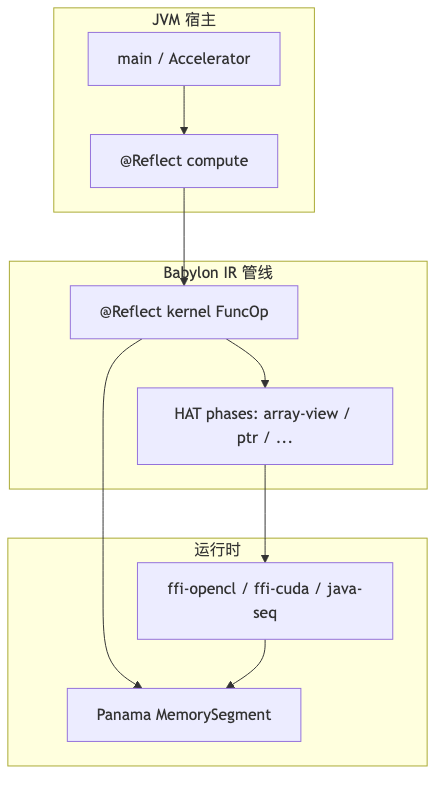
三层边界:Kernel、Compute 与宿主#
| 层 | 职责 | @Reflect(现行实现) |
|---|---|---|
| Kernel | 每线程逻辑;通过 KernelContext 的 gix/giy 等取线程坐标 | 必须 |
| Compute | 在 NDRange 上 dispatchKernel | 必须(ComputeContext 构造时 Op.ofMethod 为空会抛错) |
| 宿主 | 分配 buffer、创建 Accelerator、I/O | 通常不需要 |
演讲者观点称 Compute「通常不必标 @Reflect」——与当前 ComputeContext.java 及 Life/matmul 示例 不一致;凡走 accelerator.compute(...) 构建 compute 图的路径,Compute 入口在 code-reflection 分支上需要 @Reflect。文档强调对 compute 标 @Reflect 还便于检查可达 kernel 与数据流。
最小骨架(概念合并 README 与 Life 示例):
@Reflect static void squareKernel(int i, @RW S32Array a) {
a.array(i, a.array(i) * a.array(i));
}
@Reflect static void squareCompute(ComputeContext cc, @RW S32Array a) {
cc.dispatchKernel(NDRange.of1D(a.length()), (KernelContext kc, @RW S32Array buf) ->
squareKernel((int) kc.gix(), buf));
}
参数上的 @RO / @RW / @WO(MappableIface)表达程序员意图;自动 buffer tagger 在内联后从 invoke 推断的 AccessType 会与之对照或补充,供 FFI 决定主机侧 staging。Kernel 内应只保留可翻译的算术、分支与 buffer 访问;Control 一类宿主语义对象在 Life 示例中作为只读上下文传入,不参与设备写回。
常见误区:只给 kernel 标 @Reflect 却省略 compute;在 compute 里写重型 I/O 并期望被设备翻译;把「不必标 Reflect」的口语当成现行 API 合同。
数组视图:把 array.load 降到 buffer 的 invoke#
设备后端天然理解「对某接口的 getter/setter 调用」,而不是 Java 二维数组的连续 array.load 链。HAT 用 array view 阶段(HATArrayViewPhase)在 SSA 上匹配 JavaOp.ArrayAccessOp.ArrayLoadOp / ArrayStoreOp,把索引 conv 为 long,再替换为对 hat.buffer.*(如 S32Array::array(long):int)的 invoke。
为什么:程序员侧可写 cellGrid.cell(idx) 或 matmul 中的 array(i),IR 侧统一为可分析的 invoke,与 Interface Mapper 一致。
机制:对 2dArray[kc.gix][kc.giy],未变换前 code model 会展开多步 pointer/array load(演讲者观点:维数越高链越长)。变换需识别「哪一次 load 产出最终标量」,沿 operand 收集下标(幻灯片 entry.transform + switch on ArrayLoadOp)。



幻灯片中的变换伪代码与 JavaOp 密封层次一致:先 case ArrayLoadOp,沿 %12、%14 等 operand 回溯,判定「第二次 load 才返回 int 标量」这类模式,再用 core reflection 解析正确的 getter 签名,把后续使用点改接到新的 %r = invoke ... 结果上。Store 路径对称处理。若跳过 conv,长索引在设备侧可能与 layout 假设不一致。
常见误区:以为接口名在所有 buffer 类型上统一叫 array()——Life 的 CellGrid 生成代码用 cell(long),与 F32Array.array(long) 并存;以具体 Iface 映射为准;在 transform 里硬编码设备 API 字符串而非走 Iface 映射表。
HAT dialect 与多维 IR 压缩#
在 array view 之后,HAT 引入自定义 op(如 HATPtrOp)组成 HAT dialect,由 HATPhase 多阶段执行(含 memory、vector 等)。演讲者观点:经 array view 与 pointer 折叠后,设备端生成代码可与未使用 view 时语义等价——未在本文环境中运行 IR diff 验证。
怎么做(变换入口形态,与 JEP FuncOp.transform 一致):
entry.transform(entry.funcName(), (bb, op) -> {
switch (op) {
case JavaOp.ArrayAccessOp.ArrayLoadOp alop -> {
// 识别最终标量 load,收集下标,发射 pointer / invoke
}
default -> { /* copy or fold */ }
}
});
KernelCallGraph 在 inline 之后调用 HATTier.transform(HATTier.KernelPhases, ...),把 array view、memory、vector 等阶段串成固定管线,而不是让应用代码随意拼 phase。对维护者而言,新增一种设备目标通常是加 backend 模块 与 lowering,而不是 fork 整条 Java 前端。
常见误区:在 transform 中手写设备代码字符串;应在 IR 层完成语义保留的 lowering,再交后端;跳过 phase 顺序导致 pointer op 折叠在 array view 之前执行。
内联与 buffer 标注:过程间追踪降为单遍#
主机–设备 buffer 拷贝 往往贵于 kernel 本身。HAT 需要每个参数的 read-only / write-only / read-write(AccessType)以缩小传输。Kernel 若调用 helper(buf),跨调用的形参–buffer 映射会很快变复杂。
策略(KernelCallGraph 与演讲一致):先 SSA.transform,再循环 Inliner.inline 直到无更多可内联 InvokeOp;对 内联后的单一 FuncOp 跑 BufferTagger;最后执行 HATTier.KernelPhases。
内联约束:callee 含多个 return 时不能直接拼接——需在 callee 模型内合并为单一 return block,把 return 换成 branch(官方 Inliner Javadoc 同述)。


Buffer tagger 规则(已核对源码逻辑):
- 有返回值的 getter
invoke→ 读(RO 或升级为 RW) - void setter
invoke→ 写 - 同一 buffer 先读后写 → RW


内联器处理 return 的典型流程(与孵化模块 Inliner 一致):遍历 callee body 的 op;若遇退出当前方法的 ReturnOp,先 compute 汇合多个 return 块,必要时新建带 block parameter 的 return block,再把原 return 替换为 branch;否则把 op append 到 caller 的 Block.Builder。这样 buffer tagger 看到的是单一、线性的 invoke 序列,而不是跨函数的虚调用图。
BufferTagger.getAccessList 返回与 内联后入口 block 形参 顺序对应的 AccessType 列表,供 optkl/FFI 映射到 OpenCL/CUDA 参数修饰。getter 带返回值记读;void setter 记写;同一 IfaceValue 先读后写升为 RW;isReference 等路径避免把「仅传递引用」误判为读。
常见误区:手工在每个参数写 @RW 却与 IR 实际访问矛盾;未内联 helper 就期望 tagger 跨调用边传播;不同 SSA 槽(如 %4 与 %5)代表不同 buffer 实例,不能合并。
运行时:HAT=MINIMIZE_COPIES 与后端选择#
Config.MINIMIZE_COPIES(别名 MC)通过环境变量 HAT 或系统属性读取,注释标明主要作用于 FFI 路径以减少拷贝。演示中 Game of Life 用 java-seq 极慢,ffi-opencl 明显加速;再设 HAT=MINIMIZE_COPIES 时主讲称相对前一 OpenCL 运行约 2×——演讲者现场演示观点,无官方 benchmark 表。
export HAT=MINIMIZE_COPIES
java @.run ffi-opencl life
注意:hat.java 帮助里曾出现 -DHAT=MINIMIZE_BUFFERS 字样,与 Config 不符;以 MINIMIZE_COPIES 为准。
演示终端在 java @.run java-seq life 时可能打印 Java backend received computeContext(该字符串未在本次核对的源码快照中定位)。java-seq 的价值是在同一套 @Reflect kernel 上验证 IR 与逻辑,而非性能基线;OpenCL 再配合 MINIMIZE_COPIES 才检验「标注 → 少拷贝」。
常见误区:在 java-seq 上期待拷贝优化;minimizeCopies() 面向 FFI;把演示倍速当作通用 SLA;使用帮助里的 MINIMIZE_BUFFERS 拼写。
Game of Life:同一规则,两种表面语法#
Conway B3/S23 在 HAT 示例 life/Main.java 的 ComputeLife 中实现:lifePerIdx 统计八邻域后
((count == 3) || ((count == 2) && (cell == ALIVE))) ? ALIVE : DEAD
演示可先写 val(cellGrid, ...) 辅助访问,再改为更接近直觉的 cellGrid.cell(...) / array view;演讲者观点称重编译后行为一致,说明变换管线吸收语法差异。仓库当前以 cell(long) 与嵌入的 codeLifePerIdx OpenCL 片段对照为主,未在源码中并排保留两套等价路径供 diff。
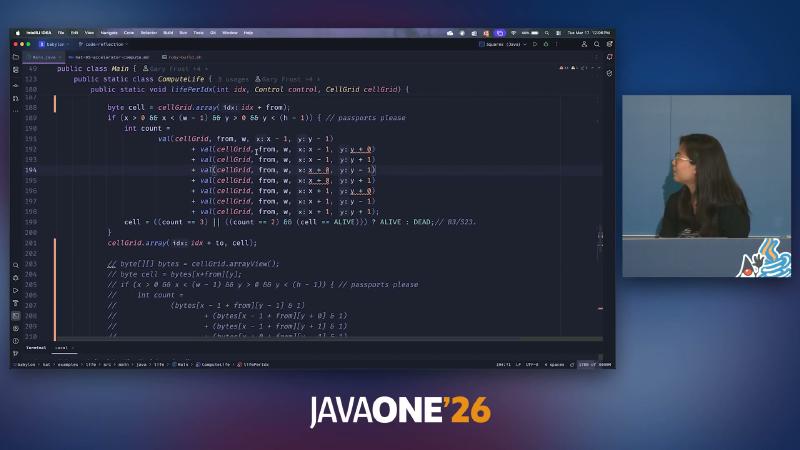
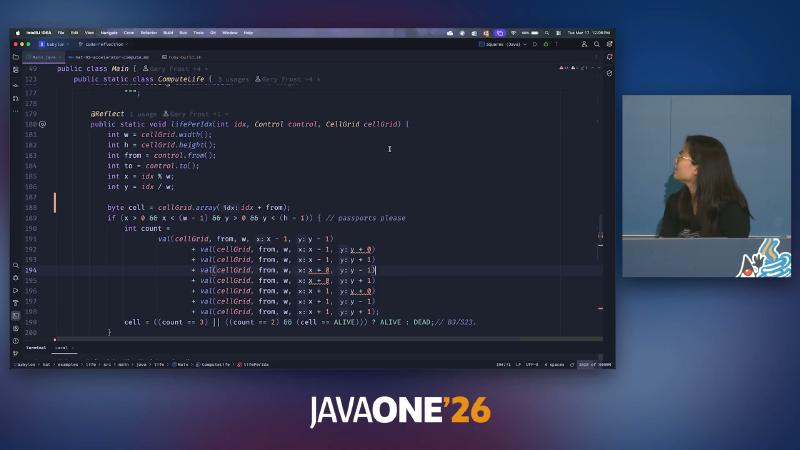
life(KernelContext kc, ...) 在 NDRange 上对每个 gix 调用 lifePerIdx;八邻域读取在源码层可展开为大量 cellGrid.cell(...) 或 val(CLWrapCellGrid, ...) 字符串(与嵌入的 codeLifePerIdx 对照),编译后应收敛为同一套设备访问模式。演讲者观点称两种写法重编译后行为一致——若你要验证,应在本地对两种源码各跑一次 golden 网格比对,而不是依赖幻灯片口述。
IDE 中可见 ComputeLife 嵌套类、@Reflect 与 hat-05-accelerator-compute.md 文档并列,说明示例同时服务「Accelerator 计算模型」教学与 IR 实验;生产集成应锁定依赖的 Babylon JDK 构建,而非系统默认 JDK。
常见误区:把 val(...) 当成运行时函数留在设备路径上;在 kernel 内保留无法内联的 JDK 类库调用;未重建 hat-example-life-1.0.jar 就切换 array view 语法。
收束:代码反射在 HAT 中的位置#
HAT 不是「把 Java 编译成 CUDA 字符串」的玩具,而是一条可核对的工程链:@Reflect 门槛 → SSA FuncOp → array view / HAT dialect → 内联 + buffer tagger → 可插拔 FFI 后端,底下是 Panama 的内存模型。对团队而言,价值在于用同一套 Java kernel 源码做 CPU 调试(java-seq)与 OpenCL/CUDA 加速,并用 MINIMIZE_COPIES 把 IR 上的 RO/RW 事实接到传输层——前提是接受孵化 API、预览特性与本地 native 构建成本。
若你正在评估是否引入这条栈,可按以下顺序自检:(1)本地 Babylon JDK 能否加载 jdk.incubator.code;(2)java @.bld 是否生成所需 hat-backend-ffi-*;(3)java-seq 能否跑通目标示例;(4)再切 ffi-opencl 与 HAT=MINIMIZE_COPIES 做传输层对比。前三步失败时,优先查 jextract/cmake,而不是改 kernel 算法。
未验证边界速览:≈2× 加速仅演示口述;HIP 后端、Java backend received computeContext 日志串未在已抓取源码定位;array view 与无 view 设备代码等价为演讲者观点;Compute 可不标 @Reflect 与现行 ComputeContext 冲突。生产采纳前应在目标 JDK 分支上对照 JEP 与 openjdk/babylon 标签自行跑通 hat 示例与测试(如 TestArrayView 一类)。
参考与延伸阅读#
- Project Babylon 项目页
- JEP draft 8361105:Code reflection (Incubator)
- Code Models — 代码模型与 SSA 设计说明
- JEP 454:Foreign Function & Memory API
- Optimizing GPU Programs from Java using Babylon and HAT(matmul)
- openjdk/babylon —
code-reflection分支 HAT 目录 - HAT README — 构建、后端与完整示例
- ComputeContext.java — compute 图与
@Reflect硬性要求 - KernelCallGraph.java — 内联与 buffer 标注顺序
- Inliner.java — 多 return 合并为 branch
- BufferTagger.java — 基于 invoke 的 RO/RW/WO 推断
- HATArrayViewPhase.java — array.load 到 invoke 的变换阶段
- Config.java —
MINIMIZE_COPIES环境变量语义 - life/Main.java — Game of Life 示例源码
- JavaOp.ArrayAccessOp — 孵化模块中的数组访问 op


