
用领域建模把 Java AI Agent 从「能跑」做到「可控」#
企业把大模型接进客服、运维或交易辅助时,最先撞上的往往不是模型智商,而是编排与契约:同一条 while 工具循环里,读库、写库、对用户说话的工具同时暴露给模型,Prompt 里写再多「先确认再转账」,schema 仍在——模型仍可能一步走错。JetBrains 开源的 Koog 面向 JVM(Kotlin/Java 一等 API),文档将 Agent 分为 Basic、Functional、Graph-based、Planner 等策略;银行演示用领域 record + 子图限工具 + 图边条件把「识别问题 → 修复 → 验证 → 调整」钉成类型安全流水线,而不是单 Prompt 包办全程。
若团队已在 Spring 生态内,可把 Koog 当作「Agent 运行时 + 编排 DSL」,通过 koog-spring-boot-starter 接入配置与 DI;需要与 Spring AI 生态互通时另有 koog-spring-ai-starter 模块,分工与 LangChain4j 的对比属 Q&A 层演讲者观点,本文以官方文档可核实 API 为主。

默认工具循环:为什么 Prompt 护栏不够#
Basic agents 的默认行为等价于:向 LLM 发请求 → 若返回 tool call 则执行并再请求 → 直到出现 assistant 文本消息。幻灯片用伪代码把这一循环写得很直白:

while (true) 在 Assistant 与 Tool.Call 之间切换
为什么:注册进 ToolRegistry 的工具会进入模型可见的 schema;「全开」带来高自由度,尾部风险(误调写操作、跳步)难以用概率表述消化。机制:循环本身确定,但每步选哪把工具由模型决定,属于非确定性分支。怎么做(反模式,仅作对照):
AIAgent.builder()
.toolRegistry(ToolRegistry.of(communication, readTools, writeTools))
.build();
常见误区:把业务阶段约束只写在 systemPrompt 里,却未收缩工具面或未拆子图——模型仍看见全部 @Tool。演讲者观点:企业场景里「最强模型也有约 0.1%–1% 失控」不可接受;该比例无官方基准,不宜当作 SLA。
从可靠性工程角度,默认策略并非「不能用」,而是缺少可审计的阶段边界:日志里只有一串 tool call,难以回答「当时是否已允许写库」。迁到图策略后,每个节点的输入/输出类型、工具子集与边条件都可进入代码评审与单测夹具——这与传统状态机的测试方式更接近。
Functional agents 用 Kotlin/Java DSL 手写同类循环,可控性高于 Basic,但仍需自行保证阶段间类型传递;若业务已是「固定 DAG + 失败回路」,Graph 往往更省胶水代码。
工具层:把副作用钉在 Java 方法上#
Koog 的 Agent 可理解为:Agent 本体 + 你的 JVM 应用(环境)+ 一个或多个模型;工具即带 schema 的 Java 方法。Annotation-based tools 要求类实现 ToolSet,方法标 @Tool 与 @LLMDescription。

AccountReadTools implements ToolSet,getLatestTransactions / 余额查询
读侧与写侧分离是后续 limitedTools 的基础:

AccountWriteTools 含 dispute、取消、转账等写操作
public class AccountReadTools implements ToolSet {
private final String userId;
@Tool
@LLMDescription("Get account balance (in USD) for the current user")
public Integer getAccountBalance() { /* ... */ }
}
常见误区:在 @Tool 里塞无关参数或返回不可序列化类型,导致 schema 生成失败;演示中的 CommunicationTools / AccountReadTools 为示例命名,非框架内置类型。另一个误区是把用户身份只写在 Prompt 里:演示在 AccountReadTools(String userId) 构造器中注入 userId,工具实现内强制按当前主体查库,比让模型自行拼接 accountId 更稳妥——这属于应用层授权,Koog 不替代 Spring Security,但工具边界应与 Principal 一致。
Banking 示例 使用同类 MoneyTransferTools implements ToolSet 模式,可作为脱离幻灯片 OCR 噪声的参照实现。
领域建模:用 record 代替冗长 Prompt#
为什么:多步子流程需要「填表才能前进」的交付物,而不是一段不可执行的愿望清单。Structured output 与节点上的 @LLMDescription 把字段语义交给 schema。机制:子图声明 withInput / withOutput 类型后,框架在工具循环中约束结构化结果;官方 Kotlin 示例多用 @Serializable + @LLMDescription,Java record 可行但不宜把演示里的 @JsonProperty 直接当作官方唯一范式。


AccountIssueSummary record 与 @LLMDescription 字段说明
@LLMDescription("Full information about the issue with user's bank account")
public record AccountIssueSummary(
@LLMDescription("Account number of the user in the database")
String accountNumber,
@LLMDescription("Current account balance in US dollars")
Integer currentBalance
) {}
演讲者观点:「Prompt 给你 hope,domain modeling 给你 contract。」常见误区:只定义 output 类型却不限制工具,模型仍可能在一步内调用写工具。
幻灯片强调子图三要素:Input Data Type、output Data Type、Subset Of Tools——三者同时成立时,模型要在工具循环里「填齐」AccountIssueSummary 才能进入 fixProblem(输入类型从 String 变为 summary record)。这比在 Prompt 里列举 JSON 字段更可测:可对 record 做单元测试、对 schema 做快照比对,并在 CI 里回归。
若字段说明过长,优先精炼 @LLMDescription 与枚举约束,而不是退回无类型 Map;Map 会重新引入解析歧义与 silent failure。
子图:按阶段收缩工具面#
AIAgentSubgraph 为每个阶段声明输入/输出类型、.limitedTools(...) 子集、任务文案;验证步用 .withVerification(...),返回类型为 CriticResult(OCR 中的 CritiqueResult 应以官方 CriticResult 为准)。

AIAgentSubgraph.builder() + `LimitedTools(communicationTools, databaseReadTools)

withVerification
var identifyProblem = AIAgentSubgraph.builder("identify-problem")
.withInput(String.class)
.withOutput(AccountIssueSummary.class)
.limitedTools(List.of(communicationTools, databaseReadTools))
.withTask(input -> "Identify the problem with the user and formulate a problem description")
.build();
var verifySolution = AIAgentSubgraph.builder("verify-solution")
.limitedTools(List.of(communicationTools, databaseReadTools))
.withVerification(solution -> "Now verify that the problem is actually solved: " + solution)
.build();
机制约束:未列入 limitedTools 的工具对模型不可见。演讲者观点:对话步可用偏对话的模型、工具密集步可用偏 tool-calling 的模型;文档子图示例使用 llmModel 配置,幻灯片 OCR 中的 .usingLLM(...) 须在本地 Javadoc 核对后再用。
常见误区:把验证逻辑塞进普通 withTask 而不走 withVerification,失去 CriticResult 与图边的类型衔接。
识别阶段通常只挂 communicationTools 与 databaseReadTools;修复阶段才加入 AccountWriteTools——这与最小权限原则一致。验证子图产出 CriticResult 后,成功路径可把原始输入映射到 nodeFinish(文档示例使用 CriticResult::getInput 一类映射),失败路径仅传递 getFeedback 给 adjust,避免把整段对话历史手工拷贝进 adjust 的 Prompt。

图策略:类型安全的边与 verify→adjust 回路#
AIAgentGraphStrategy 用 AIAgentEdge 的 onCondition + transformed 表达分支:验证失败时把 critique 映射为 adjust 的 feedback,再连回 verify。



AIAgentGraphStrategy.builder() 与 transformed(CriticResult :: getFeedback)
var graph = AIAgentGraphStrategy.builder("banking-support")
.withInput(String.class)
.withOutput(AccountIssueSolution.class);
graph.edge(graph.getNodeStart(), identifyProblem);
graph.edge(identifyProblem, fixProblem);
graph.edge(fixProblem, verifySolution);
graph.edge(AIAgentEdge.builder()
.from(verifySolution)
.to(adjust)
.onCondition(v -> !v.isSuccessful())
.transformed(CriticResult::getFeedback)
.build());
graph.edge(adjust, verifySolution);
return graph.build();
为什么:把银行业务固化为可编译检查的状态机,避免运行时字符串胶水。常见误区:边的 from/to 类型不相容——应在 builder 阶段让编译器拦住。
Key features 提到 LLM switching and seamless history adaptation;子图共享 LLM 上下文(subgraphs overview)。「缩小工具集时自动修正历史 tool call」未在已查阅文档中找到等价表述,标为演讲者观点/待验证。
跨节点业务数据可放入 AIAgentStorage,与 LLM transcript 的托管分开理解:前者是领域状态,后者由框架在子图间传递并在换模型时做 history adaptation(官方表述,非「re-explain」字面算法)。自定义 guardrail 可用 Custom nodes 的 AIAgentNode.builder,与图策略正交。

graph.edge(adjust, verifySolution) 形成验证回路
Planner:路径搜索与手写图的取舍#
当分支组合爆炸、手写边成本高时,可用 GOAP planner:声明 precondition、belief(状态副作用)与 goal,由 A* 在运行时选路径——规划器本身不用 LLM 选路(各 action 的 execute 内仍可调 LLM)。

AIAgentPlannerStrategy + identify-problem action

Java 文档入口多为 Planners.goap(...),与幻灯片 AIAgentPlannerStrategy.builder 语义接近但构造 API 名以 Javadoc 为准。Planner agents 明示可控性弱于手写图——适合探索型编排,不适合强合规固定流水线。
为什么可能选 Planner:业务动作库稳定、前置条件可形式化,但具体顺序随用户输入变化。机制:GOAP 在离散 action 空间做 A*,不用 LLM 选边,降低「跳步」概率;代价是运行时路径不如图策略可预测,审计时要记录 planner 选中的 action 序列。常见误区:把 LLM 放进 precondition 字符串里却不固化 belief 更新,导致搜索空间与实际状态脱节。

precondition / belief / execute 与 identify-problem action
嵌入 Spring:执行器、会话与记忆#
Spring Boot 集成 可注入 MultiLLMPromptExecutor 做 provider fallback;配置前缀为 ai.koog.<provider>.*(非演示草案中的 koog.models)。多轮对话安装 ChatMemory.Feature + ChatHistoryProvider 的 store/load,配合 agent.run(message, sessionId)。
ai.koog.openai:
api-key: ${OPENAI_API_KEY}
@PostMapping("/support")
String support(Principal principal, @RequestBody String request) {
return agent.run(request, principal.getName());
}
常见误区:把 ChatMemory 当成崩溃恢复——它通常在 run() 成功后 存消息;与下图的 Persistence 不同。
安装示例(以官方为准):
AIAgent.builder(promptExecutor, model, toolRegistry, strategy)
.install(ChatMemory.Feature, cfg -> cfg
.historyProvider(jdbcHistoryProvider)
.windowSize(50))
.build();
依赖 ai.koog:agents-features-memory(≥ 0.7.0)。Postgres/JDBC 需自行实现 ChatHistoryProvider;若已用 Spring AI 的 ChatMemoryRepository,可走 spring-ai starter 适配。常见误区:windowSize 过小导致用户刚说过账号又被截断;过大则成本与延迟上升,需配合下文历史压缩。
持久化:图节点 checkpoint 与 ChatMemory 分工#
Agent persistence 在图节点执行后 checkpoint:消息历史、最后成功节点、storage 等。Functional agents 文档写明 No state persistence,与「仅图/节点策略适合断点续跑」一致。

install(Persistence.Feature, ...) 与 enableAutomaticPersistence
var agent = AIAgent.builder()
.graphStrategy(graphStrategy)
.install(Persistence.Feature, config -> {
config.setStorage(storageProvider);
config.setEnableAutomaticPersistence(true);
})
.build();
| 维度 | ChatMemory | Persistence |
|---|---|---|
| 保存内容 | 对话消息 | 执行状态(含图节点路径) |
| 典型场景 | 同一用户多次 /support | 长链路、Pod 驱逐后续跑 |
| 保存时机 | run 成功后 | 每节点后(可自动) |
可观测性与历史压缩#
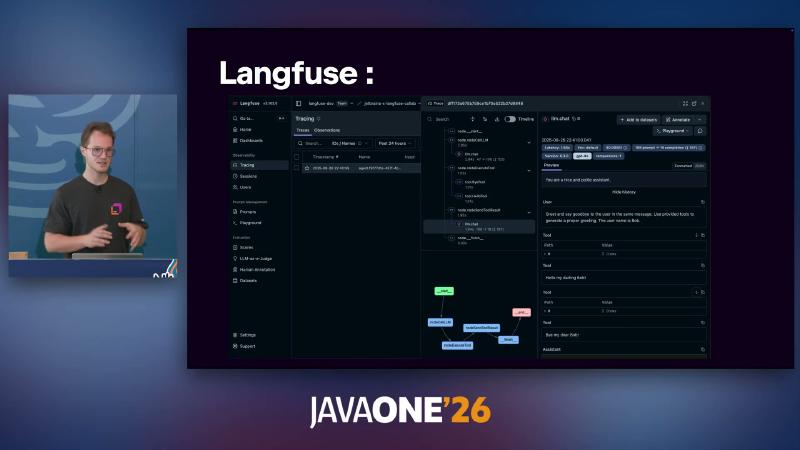
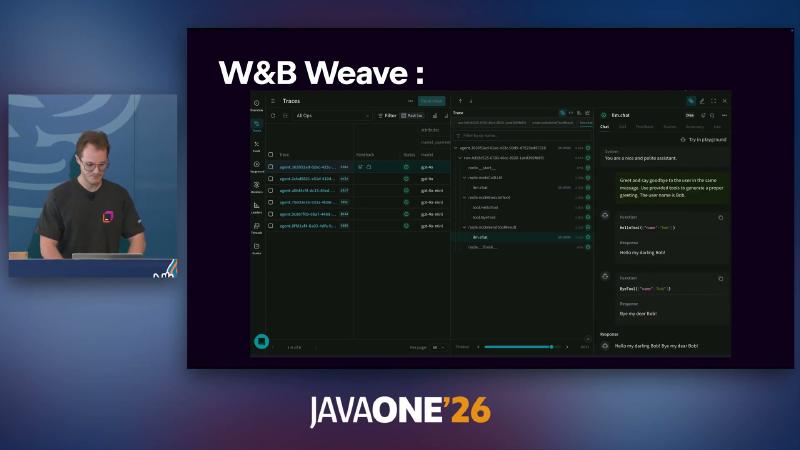
安装 OpenTelemetry 特性 后,可对接 SpanExporter 或 Langfuse、W&B Weave、Datadog 等(文档已含 Datadog exporter,与演讲中「计划中」表述可能因时间线而异)。
长对话可在图中插入 AIAgentNode.llmCompressHistory(...),策略如 Chunked(n) 或 FactRetrievalHistoryCompressionStrategy(非 OCR 中的 RetrieveFactsFromHistory)。

AIAgentNode.llmCompressHistory()
var compressHistory = AIAgentNode.llmCompressHistory("compress")
.withInput(AccountIssueSolution.class)
.compressionStrategy(new FactRetrievalHistoryCompressionStrategy(/* concepts */))
.build();
演讲者观点:事实检索式压缩在 JetBrains 内部基准约 6–8% 提升;无公开复现协议,不宜写进 SLA。
可观测性侧,Langfuse 除 Trace 外还有 Prompt Management、Dataset 等(见演示截图);生产环境建议把 traceId 与业务 sessionId 关联,便于从客服工单反查一次 Agent run。OpenTelemetry 导出配置可参考 Langfuse 文档中的 LANGFUSE_PUBLIC_KEY / LANGFUSE_SECRET_KEY 环境变量,而非硬编码密钥。
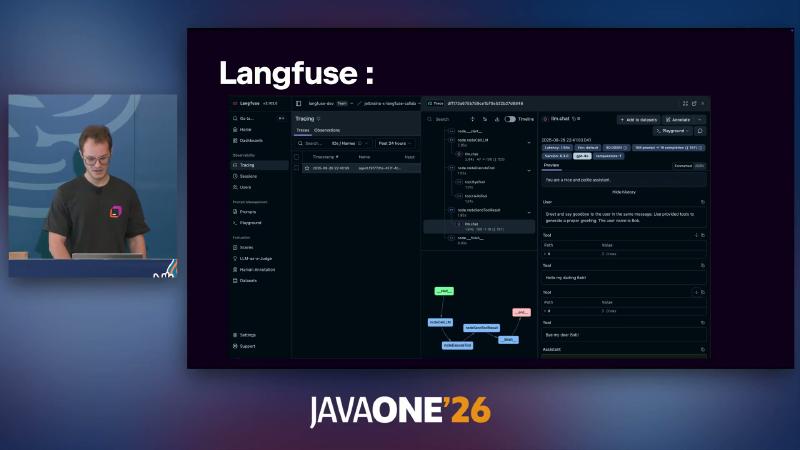
压缩节点通常插在「修复」与「验证」之间:graph.edge(fixProblem, compressHistory); graph.edge(compressHistory, verifySolution);,在上下文触顶前用领域相关输入(如 AccountIssueSolution)抽事实,比整段原文截断更不易丢账号号等关键字段——仍须对压缩结果做抽检,因 LLM 摘要本质有损。
策略选型(简表)#
| 策略 | 控制力 | 适用 |
|---|---|---|
| Basic | 低 | 原型、内部工具 |
| Functional | 中 | 代码即流程、可测试 DSL |
| Graph | 高 | 合规流水线、显式回路 |
| GOAP Planner | 中(路径动态) | 分支多、愿牺牲固定拓扑 |
与 Spring AI、LangChain4j 的分工对比属 Q&A 演讲者观点,本文不展开竞品矩阵。
落地检查清单(基于文档归纳):(1)写操作是否只在后期子图 limitedTools 出现;(2)验证是否走 withVerification + CriticResult 边;(3)多轮 HTTP 是否使用 sessionId + ChatMemory;(4)长流程是否启用 Persistence 而非仅聊天记忆;(5)生产是否接通 OpenTelemetry 导出;(6)API 符号以 api.koog.ai 与依赖版本 Javadoc 为准,幻灯片 OCR 中的模型常量名会随版本变化。
Koog 在 JetBrains 内部产品场景「battle tested」后再开源——具体产品线与规模属演讲者观点;技术选型仍应以你方合规要求下的图策略试验、故障注入与回放为准。若你正从 Python 编排迁回 JVM,优先复用现有事务边界与数据源连接,把 Koog 子图当作应用服务内的一层「有类型的用例步骤」,而不是旁路脚本——这样领域 record 与仓储层类型才能同源,减少 DTO 重复与漂移。
参考与延伸阅读#
- Koog 产品页(JetBrains)
- Key features — Java API 与能力清单
- Basic agents — 默认工具循环
- Annotation-based tools — ToolSet 与 @LLMDescription
- Custom subgraphs — limitedTools 与 Java 示例
- Custom strategy graphs — AIAgentEdge 与条件边
- GOAP agents — 规划器与 Java Planners.goap
- Spring Boot 集成 — MultiLLMPromptExecutor
- Chat memory — sessionId 与 windowSize
- Agent persistence — checkpoint 语义
- OpenTelemetry support — SpanExporter 安装
- Langfuse exporter 配置
- History compression — 压缩策略 API
- Banking 示例 — 端到端领域建模


