
Java 生态里的 Agentic AI:三套框架如何用同一业务讲清编排差异#
企业把 LLM 接进 Java 服务时,真正的分歧往往不在「能不能调 OpenAI」,而在 谁决定下一步:应用代码、框架 DSL,还是模型在工具集合里自路由。Spring I/O 2026 上,Timo Salm 与 Sandra Ahlgrimm 用同一个 AI 营养周计划 场景,在 Spring AI、LangChain4j 的 langchain4j-agentic 与基于 Spring AI 的 Embabel 之间做横向对照。下文把该对照提炼为可落地的选型与实现要点;现场对比表与主观评价属演讲者观点,公开文档未逐格背书的部分会单独标明。
从 RAG 到 Agentic:工具面与协议层#
LLM 应用通常沿能力阶梯演进:独立模型与提示工程 → RAG 接地业务数据 → 工具调用与代码解释器 → 多模态输入 → 编排、记忆、规划 与标准化工具协议。Agentic 阶段的关键变化是:在工具/RAG 路径变多时,路由决策更多交给模型,应用侧则需提供可预期的工具契约与观测。
Model Context Protocol (MCP) 由社区以开放标准形式维护(现行治理见 LF Projects 托管说明),用于把数据源、工具与工作流以统一方式接到 AI 应用;Agent2Agent (A2A) 则面向跨厂商 agent 互操作。Java 团队若已用 Spring Boot,Spring AI 的 MCP 注解与 Starter 能把 @McpTool 等方法暴露为 MCP 工具,而不必为每个集成重写一套 RPC 形状。

为什么:Java 后端往往已有安全、事务与可观测栈;若每个 Copilot 集成各自定义 tool schema 与传输层,联调成本会指数上升。MCP 把「工具长什么样」从业务代码里抽出一层;A2A 则回答「多个自治 agent 如何互发任务与结果」——二者互补,而非二选一。
怎么做(最小 server 侧):在 Spring Boot 中启用 MCP Server Starter 后,用 @McpTool 标注现有 service 方法,由框架生成 JSON schema 并挂到 MCP 端点;客户端侧用 McpClient 拉取工具列表再交给 ChatClient 的 tool calling 循环(详见 MCP Overview)。
常见误区:把「接了 MCP」等同于「已是可控的 agent 系统」。协议解决的是连接标准化;任务分解、校验环、成本上限仍要在应用或框架层显式建模。另:对外表述 MCP 时,宜区分「早期由 Anthropic 推动」与「现行 LF Projects 治理」(以 governance 页 为准),避免与托管主体混淆。
Workflow 与 Pure Agent:先定编排哲学#
Anthropic 的工程文 区分两类系统:Workflows 通过预定义代码路径编排 LLM 与工具;Agents 则由 LLM 动态决定过程与工具使用。企业场景里,可预测、可测试、延迟与 token 成本更可控的通常是 workflow;pure agent 适合步骤无法事先穷举的开放任务,但需要更强护栏与测试投入(演讲者观点,与 Anthropic 文内经验判断一致)。

| 维度 | Workflow(预定义路径) | Pure Agent(模型自路由) |
|---|---|---|
| 可测性 | 高:步骤边界清晰 | 低:路径非确定 |
| 成本/延迟 | 相对易封顶 | 易随轮次膨胀 |
| 适用 | 营养计划、审批流、ETL 式 AI | 探索性研究、开放域助手 |
常见误区:为「显得先进」默认上 fully autonomous agent。若业务步骤可画成流程图,应优先 workflow,仅在子步骤内局部使用模型决策。
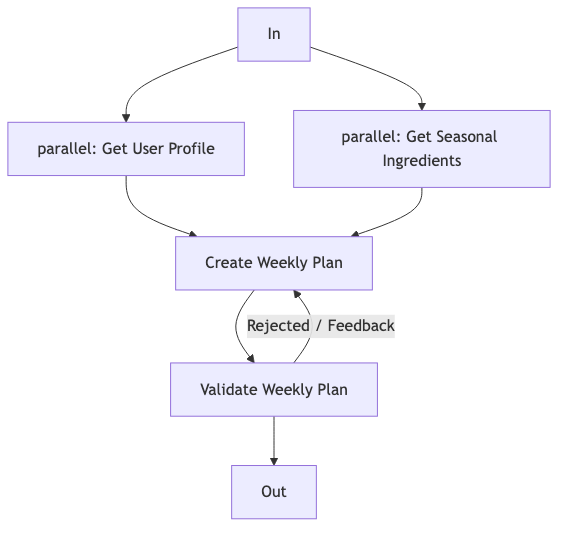
营养周计划:Parallelization + Evaluator–Optimizer#
对照 Demo 刻意组合两种 Anthropic 归纳的 workflow 模式(名称以官方为准):
- Parallelization:并行获取用户档案与时令食材;
- Evaluator–Optimizer:生成周计划 → 按过敏/热量等规则校验 → 不通过则带反馈重试。


为什么:单次 prompt 很难同时满足结构化输出与硬约束;分阶段调用便于插入程序化校验与可观测 span。
机制/约束:每一轮 LLM 调用都消耗 context;校验失败时的反馈会叠加进后续 prompt,需设 maxAttempts / maxIterations 防止成本失控(三框架实现均体现此约束,属演讲者观点)。
怎么做(逻辑骨架,三实现共用):
Phase1: parallel(fetchProfile, fetchSeasonalIngredients)
Phase2: createWeeklyPlan(profile, ingredients, request)
Phase3: loop until nutritionRulesPass(plan) or maxAttempts
营养 Demo 的 UI 侧要求用户勾选一周餐次、填写国家 ISO 码与「30 分钟内完成」等约束;生成结果需带食材克数、营养表与烹饪步骤——这类强结构 + 硬规则场景,正是 evaluator–optimizer 比单次 call().content() 更划算的地方。
常见误区:把「校验」也全部交给同一个 LLM 自评,而不保留可执行的规则函数(如钠含量、过敏原枚举);或在 parallel 阶段共享可变对象而不做线程安全隔离。
Spring AI:手写并行 + Advisor 校验环#
并行阶段:演示级 Workflow.parallel,非框架 API#
Spring AI 参考文档 中未出现 Workflow.parallel;现场 Workflow.java 是用 CompletableFuture 与固定线程池封装的演示工具类,语义上就是「标准 Java 并发跑两个 Supplier」(演讲者口播与文档检索结论一致)。
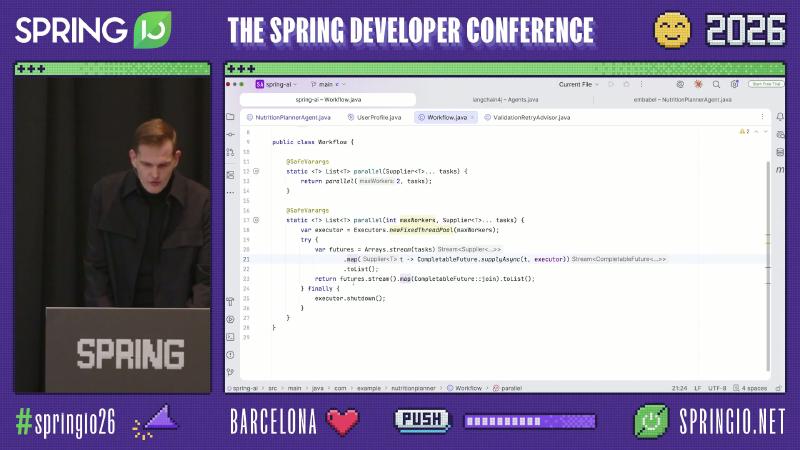
// 演示仓库工具类 + Spring AI ChatClient(非 Spring AI 内置 API)
var result = Workflow.parallel(
() -> fetchUserProfileForUser(name),
() -> fetchSeasonalIngredients(request));
var userProfile = (UserProfile) result.getFirst();
var seasonalIngredients = (SeasonalIngredients) result.getLast();
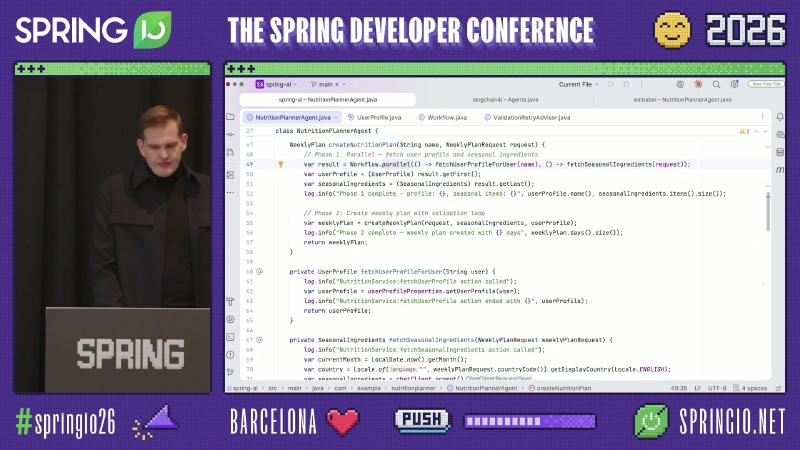
MCP 入口可用 @McpTool 暴露同一业务能力,并与 Spring Security 集成(从 SecurityContextHolder 取当前用户再委托内部方法——演讲演示逻辑)。
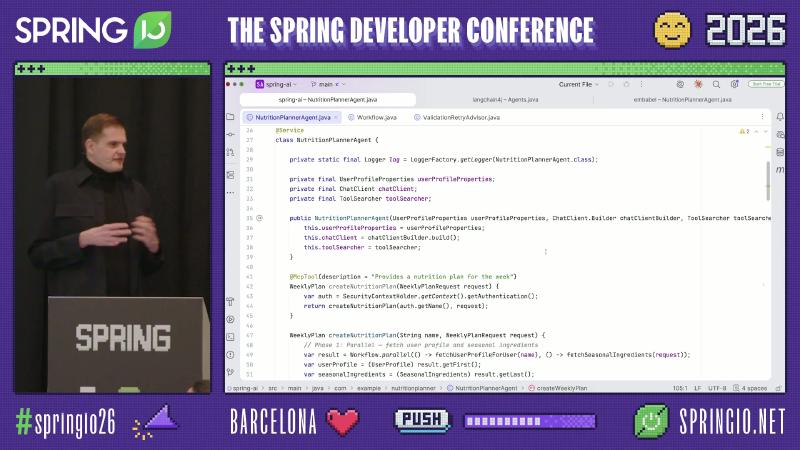
Evaluator–Optimizer:Recursive Advisors#
Spring AI 的 Advisor 链可拦截 ChatClient 调用。官方 StructuredOutputValidationAdvisor 在 JSON schema 校验失败时通过 callAdvisorChain.copy(this) 重试。现场 ValidationRetryAdvisor 是演示类名,模式相同:对 WeeklyPlan 做业务规则校验,失败则把反馈送回模型。
// 演示思路;生产可优先 StructuredOutputValidationAdvisor.builder()
var advisor = new ValidationRetryAdvisor<>(
WeeklyPlan.class,
plan -> validateWeeklyPlan(plan, userProfile));
WeeklyPlan plan = chatClient.prompt()
.advisors(advisor)
.user(/* ... */)
.call()
.entity(WeeklyPlan.class);
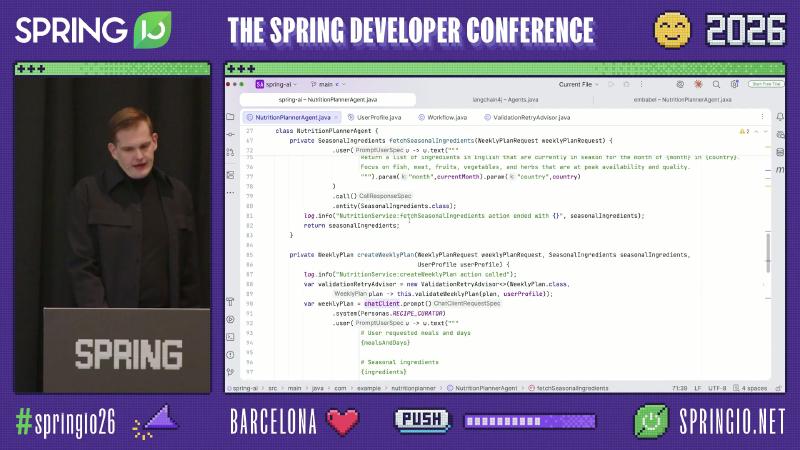
为什么选 Advisor 链:营养计划校验失败时,需要把业务反馈(例如「周三钠超标」)送回模型重生成,而不是简单重试同一 prompt。ChatClient 的 advisor 与 ToolCallAdvisor 共用同一调用链,便于在 Micrometer / OpenTelemetry 里对齐 span,避免在校验逻辑里再手写一套 HTTP 客户端。
机制/约束:Recursive Advisor 通过 CallAdvisorChain.copy(after) 复制 downstream;StructuredOutputValidationAdvisor 针对 JSON schema,演示里的 ValidationRetryAdvisor 则针对 WeeklyPlan 领域规则——二者可叠加,但要注意 maxRepeatAttempts 与总 token 预算。演讲提到 Spring AI 内部 structured output 已采用类似重试环(演讲者观点),与公开文档描述方向一致。
怎么做:并行用 Java 并发或 Spring @Async;校验环优先 StructuredOutputValidationAdvisor.builder(),业务规则再包一层自定义 CallAdvisor。若暴露 MCP,保持「HTTP 控制器」与「@McpTool 入口」调用同一编排方法,避免双份逻辑漂移。
常见误区:在文档中写成「Spring AI 内置 Workflow.parallel」;或把 Demo 的 ValidationRetryAdvisor 当成 GA 类型。当前 2.0.0-M6 仍为里程碑,路线图中的 tool search 等能力未在本次文档抓取中核实,不宜写成已 GA。另:把 advisor 链写得过深导致单次用户请求触发数十次嵌套 LLM 调用——应在设计评审时显式列出「最坏情况调用次数」。
LangChain4j-agentic:声明式 sequence / loop#
langchain4j-agentic 模块(教程标明 experimental)通过 @Agent、AgenticServices.agentBuilder、sequenceBuilder、loopBuilder 把子 agent 与校验环装配为流水线,减少手写编排。
var validationLoop = AgenticServices.loopBuilder()
.subAgents(nutritionGuard, reviserAgent)
.maxIterations(3)
.exitCondition(scope -> {
var r = scope.readState("validationResult", null);
return r != null && r.allPassed();
})
.build();
var planner = AgenticServices.sequenceBuilder(Agents.NutritionPlanner.class)
.subAgents(seasonalAgent, weeklyPlanCreator, validationLoop)
.outputKey("weeklyPlan")
.listener(/* AgentListener / AgentMonitor */)
.build();
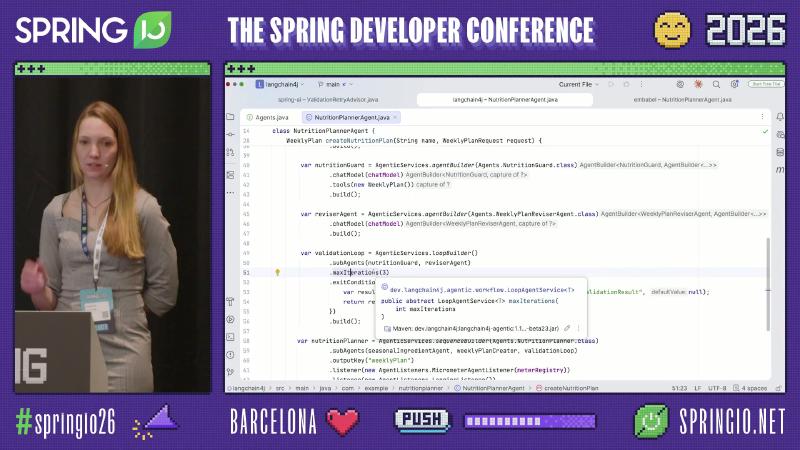
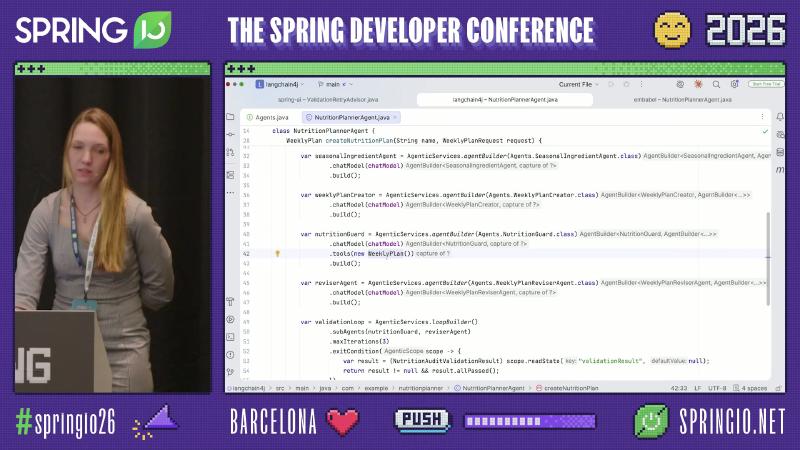
为什么:当步骤图稳定、子 agent 边界清晰时,DSL 比散落的手写循环更易读,也便于在 AgenticScope 里共享状态。
机制/约束:maxIterations(3) 直接封顶 token;exitCondition 必须可判定,避免死循环。现场 OCR 中的 MicrometerAgentListener 未在上游仓库找到同名类,官方提供的是 AgentListener / AgentMonitor(未能核实是否为 Demo 包装)。
为什么:Timo 在 Spring AI 分支里手写 parallel 与 loop,而 LangChain4j 侧用 builder 表达同一图——若团队已熟悉 LangChain4j 的 AiServices,agentic 模块能把「子 agent = 带 @Agent 的方法」这一心智延续下去,并把 AgenticScope 当作跨步骤的键值存储。
机制/约束:parallelBuilder 与 sequenceBuilder 在 AgenticServices 中并列;loop 的 exitCondition 读取的 state 需由子 agent 写入(如 validationResult)。模块开篇即声明 experimental,API 可能在 minor 版本间变动。
怎么做:把「时令食材 agent」「周计划 agent」「校验 + 修订 loop」拆成独立 @Agent 方法,再用 sequenceBuilder 串联;观测优先接官方 AgentListener / AgentMonitor,若需 Micrometer 指标再自行包装 listener(现场 MicrometerAgentListener 未能核实为上游类名)。
常见误区:忽略 experimental 声明直接上生产;exitCondition 未处理 readState 默认值导致过早退出;在 loop 内调用未设上限的 reviser agent 导致 token 账单失控(演讲强调 maxIterations(3) 与成本关系,属演讲者观点)。
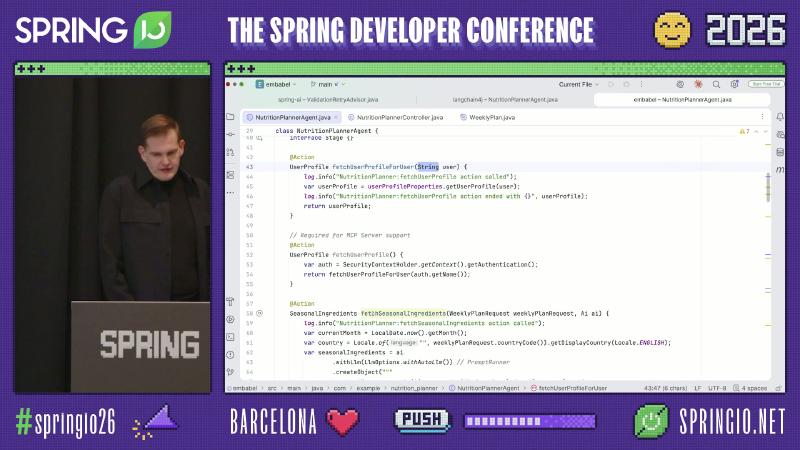
Embabel:规划器 + 领域类型 + 渐进工具暴露#
Embabel 构建于 Spring 生态之上(README 写明 JVM/Spring),用 @Action、@Agent 等把方法注册为 agent 步骤;默认规划为 GOAP(Goal Oriented Action Planning),每步后可重规划(README)。演讲口播 A* 与公开 README 默认算法不一致,实现细节应以仓库为准。
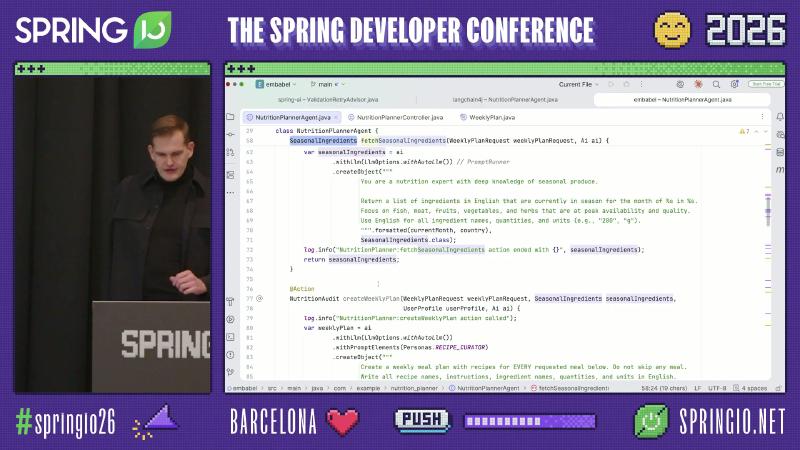
@Action
SeasonalIngredients fetchSeasonalIngredients(
WeeklyPlanRequest request, Ai ai) {
return ai.withAutoLlm()
.createObject(prompt.formatted(month, country),
SeasonalIngredients.class);
}
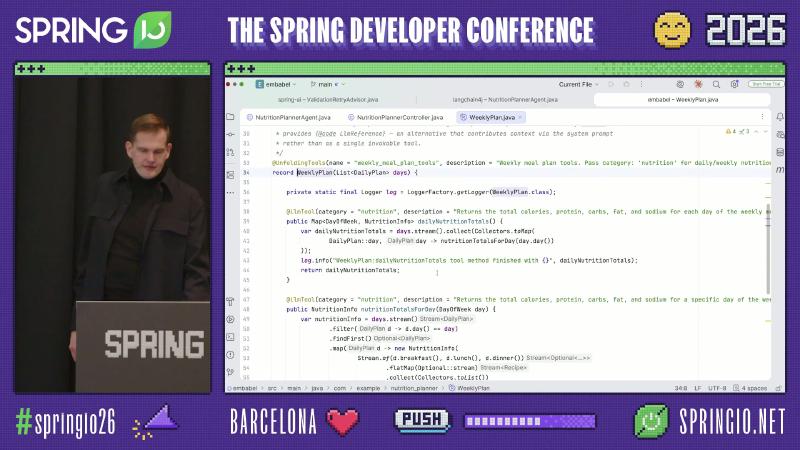
@UnfoldingTools:按 category 缩小工具 metadata#
当 MCP/业务工具数量大时,一次性注册会撑爆 context。Embabel 的 @UnfoldingTools 与带 category 的 @LlmTool 实现渐进披露:先暴露入口工具,再按 category 展开(与 Spring AI 路线图中提及的 tool search 不同机制,对比属演讲者观点)。
统一入口:AgentInvocation#
HTTP、MCP 或 Shell 可通过 AgentInvocation 触发同一 agent run:
@PostMapping("/plan")
WeeklyPlan create(@AuthenticationPrincipal Principal p,
@RequestBody WeeklyPlanRequest request) {
var invocation = AgentInvocation.builder(agentPlatform)
.build(WeeklyPlan.class);
return invocation.invoke(Map.of(
"user", p.getName(),
"request", request));
}
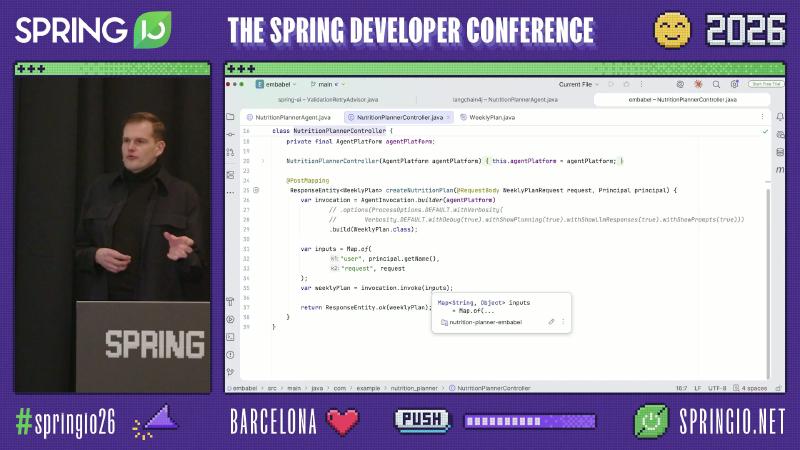
为什么:手写 if/else 决定「先拉 profile 再生成计划」在步骤增多时难维护。Embabel 用 GOAP 根据当前 state 与 @Action 方法签名推断下一步;方法参数缺失时规划失败,相当于把前置条件检查从 prompt 挪到类型系统(演讲者演示口径)。
机制/约束:README 写明规划步骤 可插拔,且每步后可 replan;这与纯 prompt 编排不同。Ai 封装 Spring AI 的 ChatClient 能力,createObject 负责结构化抽取。工具暴露方面,@UnfoldingTools 先给模型一个「门控」工具,再按 category 展开 @LlmTool,减轻一次性注册上百 MCP 工具时的 metadata 压力。
怎么做:每个外部能力一个 @Action;需要 LLM 的子步骤注入 Ai ai;领域返回值(UserProfile、SeasonalIngredients、WeeklyPlan)驱动后续步骤是否可执行。HTTP 层用 AgentInvocation 统一触发,MCP/Shell 走同一 AgentPlatform(MCP 细节未能用官方页逐条核对营养 Demo)。
常见误区:把对比表「全绿」当生产成熟度;演讲明确 Embabel 尚未 GA(演讲者观点)。把口播 A* 直接写进架构文档——公开 README 默认 GOAP,应以仓库为准。调用 LLM 用 ai.withAutoLlm()(Ai.kt),勿误写 LlmOptions.withAutoLlm()。
三框架如何分工(概念矩阵)#
| 框架 | 典型定位 | 编排表达 | 成熟度提示(2026-05 文档快照) |
|---|---|---|---|
| Spring AI | LLM 集成、Advisor、MCP/A2A | 代码 + Advisor 链;并行需自建 | 1.1.x 参考 + 2.0.0-M6 |
| LangChain4j-agentic | 社区 agentic DSL | sequence / loop / parallel builders | 模块 experimental |
| Embabel | Spring 之上的高阶 orchestration | 类型驱动步骤 + 规划器 | SNAPSHOT / 非 GA(演讲者观点) |

现场幻灯片对 LangChain4j 的 MCP 格标注 No HTTP Server(未能核实是否涵盖 Quarkus 社区扩展或仅指核心库 HTTP server)。选型时应按「需要的 MCP 传输形态(stdio / HTTP)」自行验证,而非照搬单色格。
怎么做(选型 checklist):
- 已深度使用 Spring Boot、要以最小依赖接 LLM + MCP → 优先评估 Spring AI + 手写 workflow;
- 希望用 Java DSL 表达 subagent / loop,且接受 experimental → LangChain4j-agentic;
- 需要 GOAP 式步骤前置条件与渐进工具暴露,并愿跟踪 SNAPSHOT → Embabel(仍建议与 Spring AI 能力对照)。
观测与测试(横切):三实现都能挂 Micrometer 一类指标,但抽象层不同——Spring AI 在 advisor / ChatClient 链;LangChain4j 在 AgentListener;Embabel 在 AgentPlatform 与 invocation 生命周期。Deterministic workflow 的单元测试应断言步骤顺序与校验分支,而非 LLM 原文;对模型输出宜做 schema + 业务规则双层断言(与 P04 演示思路一致)。现场矩阵对 Testing、Observability 多标黄/绿混色,反映的是当时快照,不是长期路线图(演讲者观点)。
常见误区:用现场矩阵替代自家 PoC;忽略 LangChain4j MCP 教程 与 Spring AI MCP 文档在「客户端/服务端」角色上的差异;在 Embabel SNAPSHOT 与 Spring AI 2.0-M6 混用时未锁定 BOM 版本。Koog(JetBrains)等框架未在本次材料中展开,不宜据单场会议推断「Java 只有三家可选」。
同一营养周计划在代码形态上呈现三种答案:Spring AI 把编排留在 Java + Advisor,框架提供 LLM/MCP 基座;LangChain4j-agentic 用 builder 表达 sequence/loop;Embabel 用规划器与类型驱动步骤,并内置渐进工具暴露。没有绝对更优,只有与团队技能栈、可接受实验性、以及「workflow 占比」是否匹配的选择。若你已在生产使用其中一套,更务实的路径往往是在现有栈上补齐 parallel 与 evaluator–optimizer 两环,再按需评估是否引入更高层 DSL——而不是一次性迁移到对比表全绿的列。
参考与延伸阅读#
- Anthropic — Building effective agents
- Model Context Protocol — 入门
- Model Context Protocol — 治理与托管
- Agent2Agent (A2A) — 什么是 A2A
- Spring AI 参考文档(1.1.x)
- Spring AI 2.0.0-M6 文档索引
- Spring AI — Advisors API
- Spring AI — Recursive Advisors
- Spring AI — MCP 概览
- Spring AI — @McpTool 服务端注解
- LangChain4j — Agents and Agentic AI
- LangChain4j — agents.md 源码
- LangChain4j — MCP 教程
- Embabel Agent — README
- Embabel — @UnfoldingTools 源码


