
JVM 与 Spring Boot 可观测性:三信号如何真正串起来#
生产里最常见的挫败,不是「没有监控」,而是 UI 上只有一个 HTTP 500,日志里却夹着下游 404,指标曲线又看不出是哪条调用链在抖。云原生与微服务把依赖图拉成「Death Star」式密度后,单靠进程内堆栈或单一 APM 面板往往不够:你需要 metrics 回答「有多糟、影响面多大」,logs 保留业务语义与异常栈,traces 还原跨跳时序与状态码。
Micrometer 与 Spring Boot Observability 把三条信号收进同一套 Observation 管道;Grafana 栈(Loki / Prometheus / Tempo)则在排障 UI 里把同一次请求焊回去。文章不复述会议时间线,只保留可迁移到 Boot 2.7→4 的机制与操作要点。下文按「为什么 → 机制 → 怎么做 → 误区」组织,覆盖 Boot 2.7→4 的依赖演进与埋点模型;演示拓扑来自 Teahouse 样例(公开仓库 URL 未核实),Grafana 数据源关联为可复现思路而非唯一现场布线。
为什么需要可串联的多服务样例#
单进程 demo 很难暴露 跨服务 trace、下游 404 被上游包装成 500、JDBC 与 HTTP 子 span 谁更慢 这类问题。Teahouse 用 tea-service(8090)经 HTTP 调 water-service(8091)与 tealeaf-service(8092),两侧各有 JDBC;用户从 8099 的 UI 点「泡茶」触发整条链。
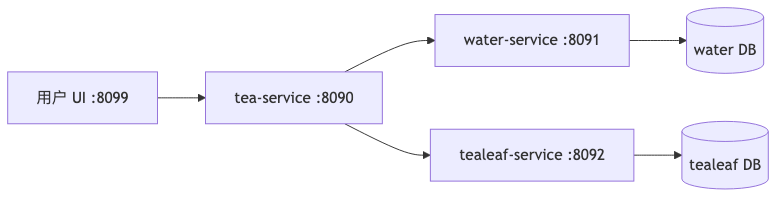
机制:每个服务独立进程、独立 spring.application.name;观测标签里的 application=tea-service 等通常来自应用名,不是框架写死的默认值(见 management.metrics.tags.*)。
怎么做:本地至少起三个 Boot 应用,并部署 OTLP/Zipkin 接收端、Prometheus scrape、Loki push 或 agent;对 GET /tea/{name} 传入 english breakfast 等组合,可稳定复现 ResourceNotFoundException 一类业务错误(日志包名 org.example.teahouse.core.error 为 现场 OCR 证据,非 Spring 产品包)。
误区:把「能 curl 通」当成「能排障」;或在未统一 spring.application.name 时混用 application 与 service.name 标签,导致 Loki 与 Prometheus 过滤器对不上同一服务。

排障顺序:日志怀疑 → 指标圈范围 → 追踪定根因#
行业常见顺序(Spring 文档描述三信号,不强制该顺序):先在 Loki 里锁定 application=tea-service 的 ERROR,再用聚合指标判断是局部毛刺还是全局故障,最后用分布式追踪还原调用链与 HTTP 状态码在各跳的真实值。
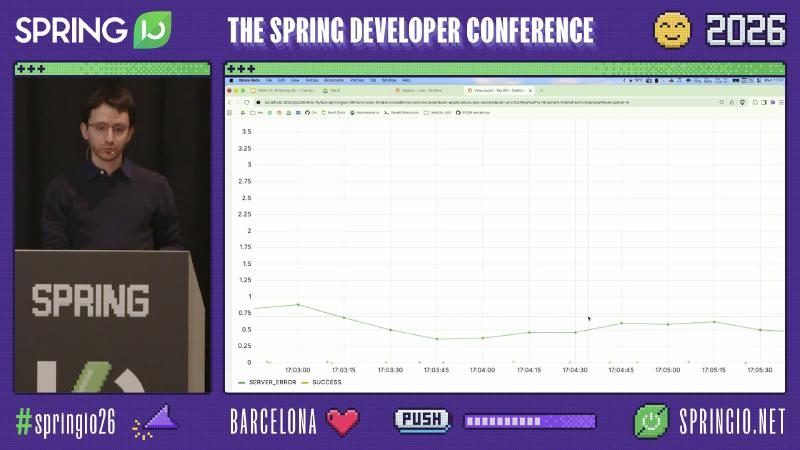
Micrometer 默认 HTTP 服务端观测名为 http.server.requests;导出到 Prometheus 后常见 http_server_requests_seconds_count。outcome 标签来自 HttpStatus.Series:2xx 为 SUCCESS,5xx 系列为 SERVER_ERROR(DefaultServerRequestObservationConvention 源码)。
sum(rate(http_server_requests_seconds_count{
application="tea-service",
outcome="SERVER_ERROR"
}[$__rate_interval]))
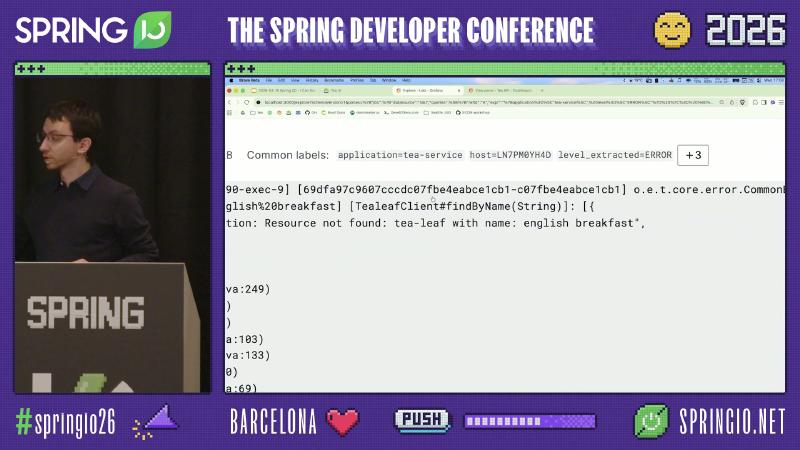
典型 ERROR 行会同时出现 [tea-service]、[http-nio-8090-exec-*] 与方括号内的 trace 片段(如 69dfa97c9607cccdc@7fbe4eabce1cb1),以及 Feign/HTTP 客户端方法名 [TealeafClient#findByName]。把该 ID 复制到 Tempo Explore 的 queryType":"traceql" 查询框,即可从「怀疑 tea-service」切换到「看见 tealeaf 先 404」。
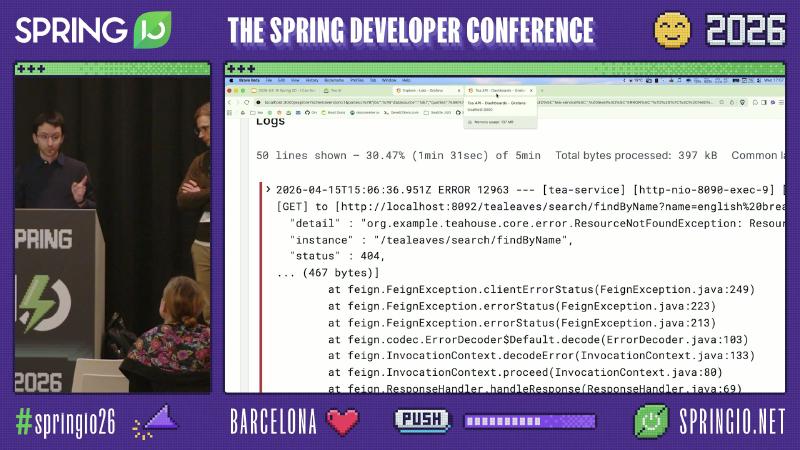
怎么做(最小 Loki 过滤思路):{application="tea-service"} |= "ERROR" 或 level_extracted="ERROR"(标签名取决于 pipeline,演示栈用了 level_extracted)。确认时间窗与 Prometheus [$__rate_interval] 对齐,避免「日志有、曲线平」的错觉。
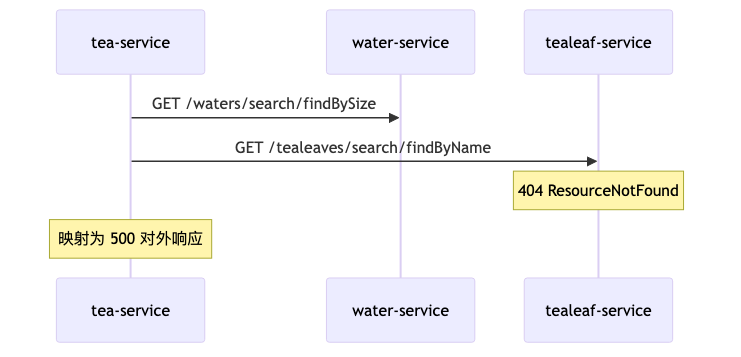
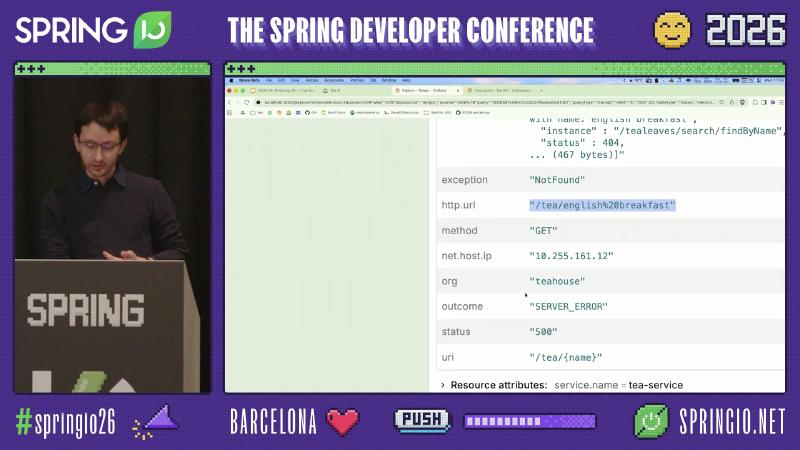
误区:看到 tea-service 返回 500 就改 tea-service。演讲者观点:tealeaf-service 可正确返回 404,而 tea-service 将客户端错误映射为 500——属应用错误处理反模式,非框架缺陷;span 上可能出现非标准 status: 599 与 outcome: SERVER_ERROR 并存(演示/OCR 现场值,非 HTTP 标准)。修复方向应是 传播或保留下游 4xx,并在指标上区分 CLIENT_ERROR 与 SERVER_ERROR,而不是关掉追踪。
日志关联:把 trace ID 写进每一行#
为什么:多副本、多服务下,仅靠时间戳与 message 无法对齐同一次用户请求。
机制:Spring Boot Tracing — Logging Correlation 写明:使用 Micrometer Tracing 时,默认在日志中包含 correlation ID;MDC 键为 traceId、spanId,格式可通过 logging.pattern.correlation 调整。
logging:
pattern:
correlation: "[${spring.application.name:},%X{traceId:-},%X{spanId:-}] "
include-application-name: false # 与 correlation 联用时避免应用名重复
传播层默认对齐 W3C traceparent / B3(由 bridge 决定);下游 water-service、tealeaf-service 若也在 classpath 上有 tracing,则 同 trace 下各服务日志共享 traceId,仅 spanId 随当前 span 变化。
怎么做:升级自 Sleuth 时对照 Logging Correlation IDs 把 %X{traceId} 写入 logging.pattern.level 或 correlation 块;结构化 JSON 日志应把 traceId/spanId 提成字段,便于 Loki | json 解析。
误区:以为「开了 Actuator」就等于「日志带 trace」——需 classpath 上有 tracing 与采样/导出配置;无 exporter 时仍可能在日志里看到 ID,但 span 未必进入 Tempo(见后文追踪依赖一节)。另一误区是 只打 traceId 不打 spanId,在并行 span 场景下仍难以对齐单个子操作。
分布式追踪:Tempo 里看清 HTTP 与 JDBC#
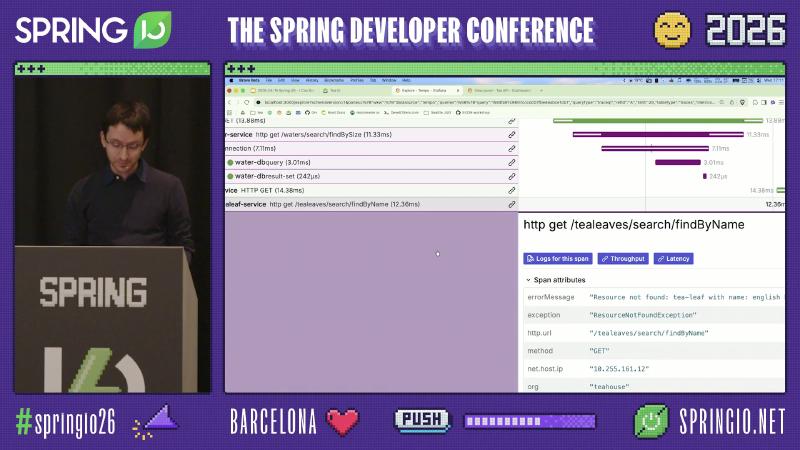
在 Grafana Explore 选择 Tempo 数据源,用 TraceQL 或 trace ID 打开 tea-service: http get /tea/{name},可展开 make.tea、下游 HTTP、water-dbquery / tealeaf-dbresult-set 等子 span,并对比各跳 http.url、exception、status。
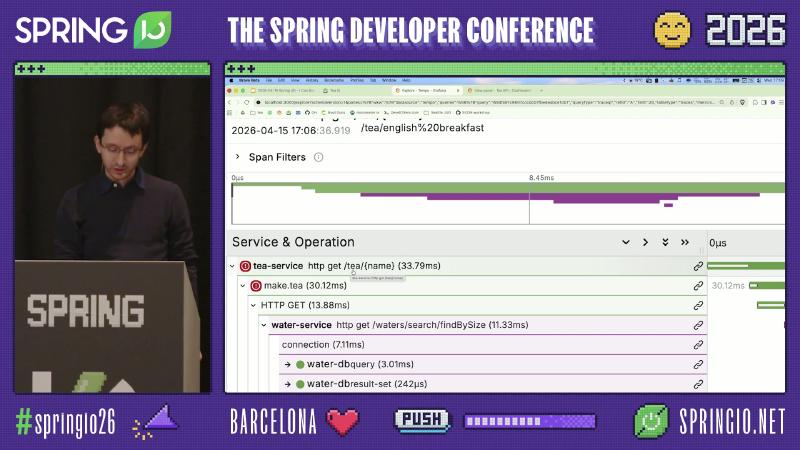
Grafana Tempo 的 Node graph 适合一眼看 fan-out;展开树可见 connection、water-dbquery、tealeaf-dbresult-set 等命名,对应 JDBC 与连接池观测(常由 datasource-micrometer 等集成产生,具体 span 名为演示应用)。Span attributes 中的 db.name=tealeaf-db 可把慢查询定位到库实例。
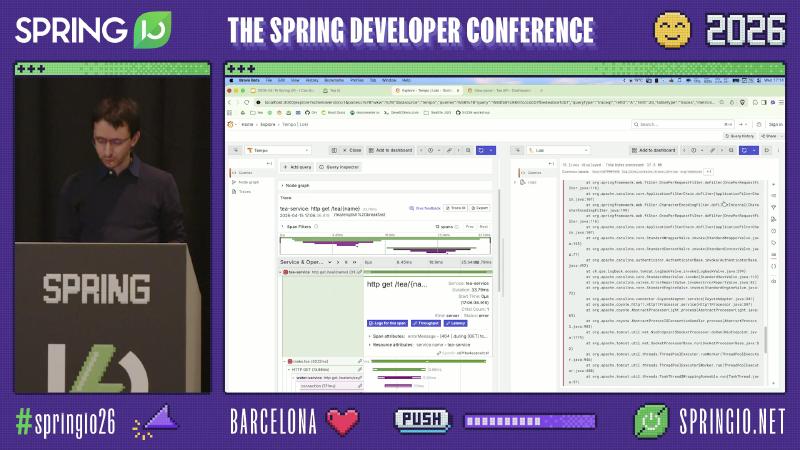
怎么做:Boot 3+ 典型为 spring-boot-starter-actuator + micrometer-tracing-bridge-brave(或 OTel bridge)+ Zipkin/OTLP reporter;Boot 4 可改用 spring-boot-starter-opentelemetry 或 spring-boot-starter-zipkin,并配置 management.opentelemetry.tracing.export.otlp.* 或 management.tracing.export.zipkin.*。采样率示例:
management:
tracing:
sampling:
probability: 1.0 # 演示环境;生产请下调
误区:只盯根 span 耗时——make.tea(约 30ms 量级,演示 OCR)下并行/串行的 HTTP 与 DB 子 span 才暴露「慢在水库还是茶叶库」。另一误区是 用 UI 上的 500 推断所有下游也是 5xx——应读各 client span 的 http.status_code。
追踪 → 日志:按 trace ID 拉全链路#
Grafana 文档 说明:点击 「Logs for this span」 时,过滤依据是 trace ID,而非当前 span ID;Tempo 与 Loki 两侧都需配置(如 tracesToLogsV2、derived fields、${__trace.traceId})。
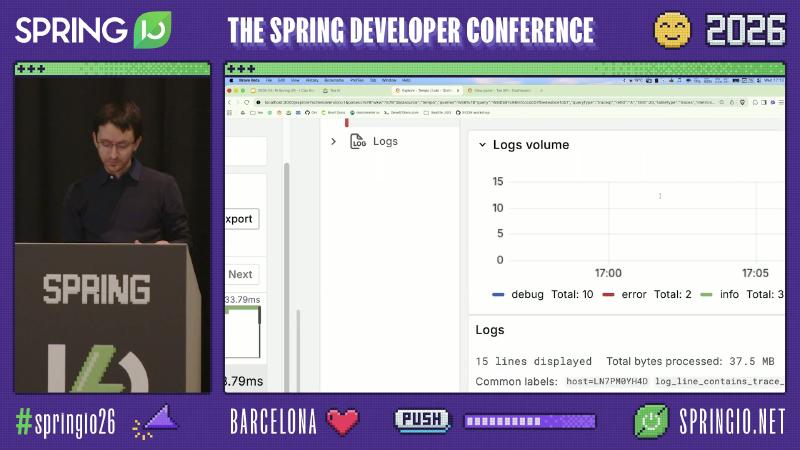
怎么做:在 Tempo 数据源 YAML 中配置 tracesToLogsV2,Loki 侧配置 derived field 指向 Tempo;日志行需包含 trace ID 字符串(或由 agent 解析 JSON 字段)。演示中 Explore 同时出现 debug Total:10、error Total: 2 等日志量统计,便于判断是 单服务噪声 还是 全链路边界服务都在报错。
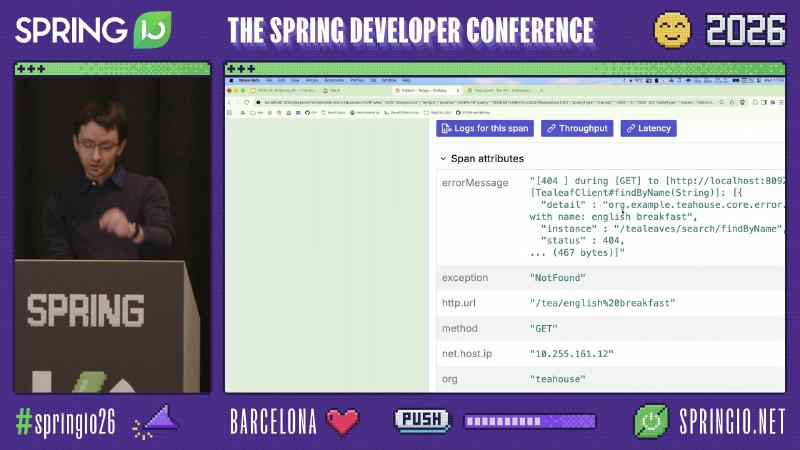
误区:UI 文案含 “span” 就以为只拉当前 span 的日志——实际是全 trace 参与服务的日志卷;未配置关联时按钮不可用或结果为空(现场 demo 布线,生产需自建)。也不要在 Loki 里只按 container 名过滤却省略 trace ID,否则多副本下仍会串线。
指标 ↔ 追踪:低基数标签与 Exemplar#
Spring Boot Observability:低基数 key 同时进入 metrics 与 traces;高基数(如用户输入)仅进入 traces。因此 span 与 PromQL 可在 application、outcome、exception 等维度对齐。
Exemplar 让聚合曲线上的某个点携带 trace ID,在 Grafana 中跳回 Tempo。Prometheus 需启用 exemplar 存储;Micrometer 在集成 tracing 时可提供 SpanContext(Metrics — Prometheus Exemplars)。
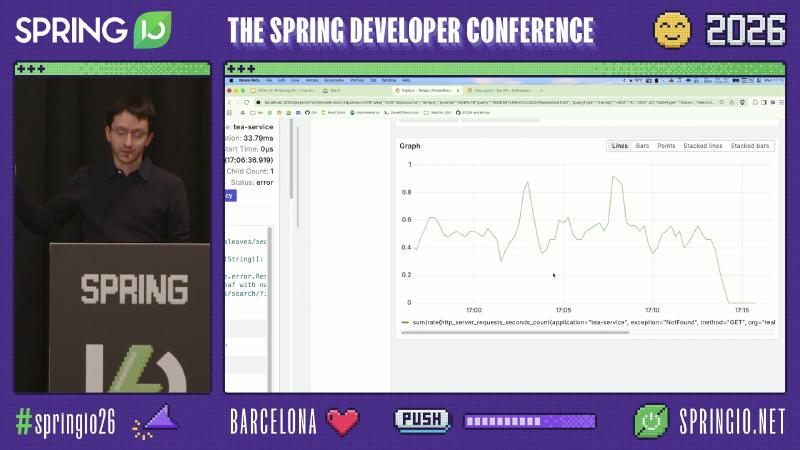
sum(rate(http_server_requests_seconds_count{
application="tea-service",
exception="NotFound",
method="GET"
}[$__rate_interval]))
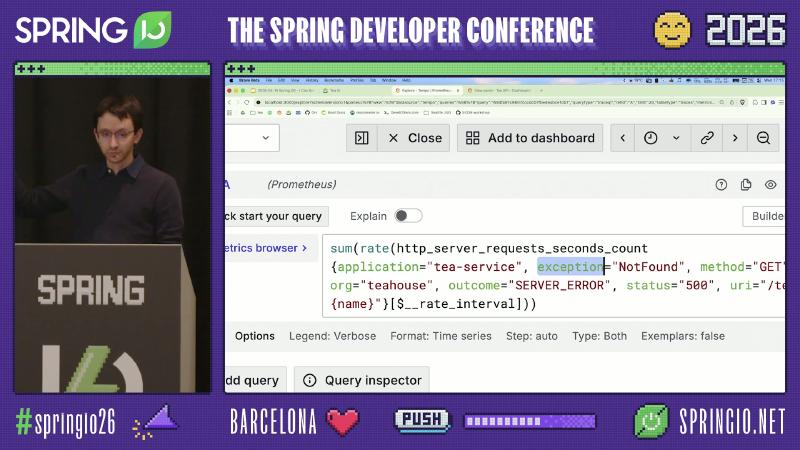
Exemplar 回跳的前提链可拆成三层(缺一则演示中「从曲线点进 Tempo」不可用):
- 应用:Micrometer Prometheus registry 导出 exemplar,且 tracing 提供
SpanContext(Boot 文档 Prometheus Exemplars)。 - Prometheus:启用 exemplar 存储,抓取 OpenMetrics 格式(feature flag 文档)。
- Grafana:Prometheus 与 Tempo 数据源关联,面板开启 Exemplars(演示面板曾显示
Exemplars: false,需手动打开才有钻取入口)。
未验证边界:演示栈使用 Prometheus exemplar;路线图称 Boot 4.1 / Micrometer 1.17 将加强 OTLP registry 的 exemplar(1.17.0-RC1 发布说明 仅有 RC 级信息)。exception=NotFound 标签是否默认出现在 http.server.requests 上,取决于错误是否被 Observation 记录为低基数 key——未在本文逐条核对每个异常类型的默认标签。
日志栈:Boot 2 / 3 / 4 的共同点与可选增强#
spring-boot-starter-logging(SLF4J + Logback)在各主版本一致;Logging 特性 写明默认 Logback。换 spring-boot-starter-log4j2、接入 Logbook、开启 Tomcat access log 均为可选:
server:
tomcat:
accesslog:
enabled: true
误区:升级 Boot 主版本就重写日志 API——通常只需核对 correlation 与 appenders;GC 日志、Jetty access log 等按容器与运维需求单独加。Access log 记的是 边缘入口(Tomcat 见到的原始请求),与应用日志中的 trace 关联互补,但不能替代 MDC 里的 traceId——两者应通过时间戳与 X-Forwarded-* 头在需要时人工对齐,或统一由 service mesh 注入 trace 头。
Micrometer 指标:维度化模型与可插拔 Registry#
Micrometer 提供与后端无关的 Timer/Counter API,经 micrometer-registry-prometheus 等导出。Boot 4 另提供 spring-boot-starter-micrometer-metrics(是否避免引入完整 Actuator Web 端点需自行核对依赖树,要点中为部分核实)。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
误区:在 Prometheus 里直接搜 http_server_requests 却忘了 Micrometer 侧原名是 http.server.requests——属导出命名转换,不是埋点丢失。
追踪依赖演进:Sleuth、Micrometer Tracing、Boot 4 Starter#
| 时代 | 典型组合 |
|---|---|
| Boot 2.7 + Spring Cloud | Spring Cloud Sleuth(核心已迁至 Micrometer Tracing) |
| Boot 3 | Actuator + micrometer-tracing-bridge-brave | bridge-otel + Zipkin/OTLP reporter |
| Boot 4 | spring-boot-starter-zipkin 或 spring-boot-starter-opentelemetry 单 starter |
迁移指南(Wiki) 仍值得对照包名与配置前缀变化。
升级检查清单(避免只改 Boot 版本号):
- Starter:
micrometer-tracing-bridge-brave+zipkin-reporter-brave→spring-boot-starter-zipkin;或 OTel bridge + OTLP exporter →spring-boot-starter-opentelemetry。 - 配置前缀:
management.tracing.export.zipkin.*与management.opentelemetry.tracing.export.otlp.*不要混用却未删旧键。 - 与 Observation 集成:文档中的
TracingAwareMeterObservationHandler仍负责把 trace 上下文绑进 metric/exemplar。
演讲者观点(未在 Boot 4 官方文档逐条核实):OTel Logback/Log4j appender 在 JVM 侧仍不稳定,Boot 4 无完整 OTel logging starter。无 exporter 时日志里仍可能出现 trace/span ID,但 后端无 span——精确条件取决于是否引入 tracing starter 与采样(management.tracing.sampling.probability)。
Observation API:一次埋点,多路输出#
自 Micrometer 1.10 / Boot 3.0 起,micrometer-observation 在「为一次操作计时」层面统一 metrics 与 tracing,避免同一业务路径写三套埋点。

Observation observation = Observation.start("my.operation", registry);
try {
// business work
} catch (Exception ex) {
observation.error(ex);
throw ex;
} finally {
observation.stop();
}
Boot 文档亦推荐 Observation.createNotStarted(...).observe(...) 风格——API 形态不同,语义一致。框架内置的 HTTP 服务端/客户端、DataSource 等已走 Observation;业务代码在 make.tea 一类路径上应用 Observation.start("make.tea", registry) 才能出现 与日志、指标同名的自定义 span。TracingAwareMeterObservationHandler 把 trace 与 timer 绑在一起,是 exemplar 与「指标—追踪同标签」的枢纽。
全局低基数标签可用 management.observations.key-values.* 注入环境、区域等;高基数请用 .highCardinalityKeyValue(...) 显式标注,避免误入 Prometheus。
注解路径(需 management.observations.annotations.enabled=true 与 AspectJ):
@Observed(name = "tea.make")
@ObservationKeyValue(key = "tea.name", expression = "#name")
public TeaRecipe makeTea(String name) { /* ... */ }
误区:把用户 ID、商品全名等高基数维度塞进 @ObservationKeyValue 且期望进 Prometheus——会炸 cardinality。
自定义 ObservationHandler#
Spring Boot 自动配置 metrics 与 tracing 的 handler,并将容器中 ObservationHandler Bean 注册到同一 ObservationRegistry(Tracing 与 Observation 集成)。

@Bean
ObservationHandler<MyContext> myHandler() {
return new MyObservationHandler();
}
适合挂审计、业务结构化日志等副作用,而无需 fork 框架内置的 HTTP 观测。实现 ObservationHandler 时注意 只处理你关心的 Context 类型,并在 supportsContext 中收窄范围,以免拖慢每次 HTTP 请求。
误区:在 handler 里再开一条独立的 Brave/OTel tracer 手动建 span——会与内置 tracing handler 重复,导致双 span 或标签分裂。
三信号对照:何时用哪一种#
| 信号 | 擅长回答 | 在 Teahouse 场景中的典型入口 |
|---|---|---|
| Logs | 异常类型、参数、业务措辞 | Loki {application="tea-service"} |= "ERROR" |
| Metrics | 错误率、饱和度、回归对比 | http_server_requests + outcome / exception |
| Traces | 跨服务顺序、每跳状态码、DB 子 span | Tempo tea-service: http get /tea/{name} |
三者不是替代关系:指标缩小时间窗与服务范围,追踪锁定 trace,日志补齐异常栈与业务上下文。Observation 模型的价值在于 同一次 Observation.start 可同步驱动其中两条(metrics + trace),日志则通过 MDC 挂接。若你只能先落地一种信号,优先 日志 correlation + 追踪导出(否则指标再全也无法落到具体请求);若已有 Prometheus 却缺 tracing,则先补 exporter 与采样,再谈 exemplar 钻取。
库作者与路线图:Convention、OTLP、语义约定#
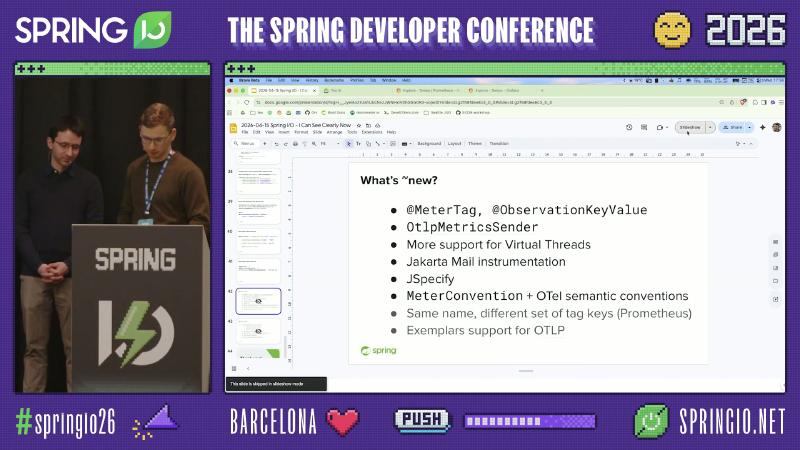
近期方向包括:@MeterTag、OtlpMetricsSender 抽象、MeterConvention 与 OpenTelemetry Semantic Conventions 对齐、虚拟线程与 Jakarta Mail instrumentation 等(幻灯片摘要,未逐条对照发布说明)。
演讲者观点:OTel 语义约定不会「装依赖就全自动切换」,仍需显式 Convention 配置。Prometheus 侧可能出现 同名 metric、不同 tag 集合 的行为变化,升级 Micrometer 时需读 release note。对库维护者而言,@MeterTag 与 @ObservationKeyValue 的分工在于:前者偏向已有 @Timed/MeterRegistry 体系,后者服务 Observation/Tracing 统一管道——新库优先 Observation + Convention,可减少后端切换时的重命名成本。
参考与延伸阅读#
- Spring Boot — Observability(总述)
- Spring Boot — Tracing(含日志 correlation)
- Spring Boot — Metrics(含 Prometheus Exemplars)
- Spring Boot — Logging 特性
- Spring Boot — Starters 列表
- Spring Cloud Sleuth 参考与迁移说明
- Micrometer — Observation components
- Micrometer — Prometheus registry
- Micrometer — OTLP 与 OtlpMetricsSender
- Micrometer Tracing — Sleuth 3.1 迁移 Wiki
- Grafana — Tempo 数据源
- Grafana — Configure trace to logs
- Prometheus — Exemplars storage feature flag
- OpenTelemetry Semantic Conventions
- OpenMetrics — Exemplars 规范


