
Agentic RAG:当检索管线长出「规划与工具环」#
工程团队把 RAG 从 demo 推到生产时,常卡在三个张力:延迟(用户要秒级答案)、可控性(失败要能定位)、覆盖(单一向量库装不下 Slack、Web、数仓)。2024 年前后,Weaviate 等厂商用 Agentic RAG 命名一类方案:在检索之上叠加 LLM 的 plan → act → observe 环,用 function calling 选工具、决定是否继续取数。本文把公开文档、论文与一线访谈中的可核对部分和仍属架构猜想的部分分开写——不给出「一种架构统治一切」的结论。

问题空间:Agent、Compound AI 与 RAG 的交界#
为什么要在 RAG 旁再谈 Agent#
Weaviate 官方博客 将 agent 描述为:具备角色与任务、使用 tools 与 短/长期 memory、能 plan, act, and adapt 的 LLM 系统。这与 Lewis 等人定义的 RAG 模型结构(parametric + non-parametric memory)不是同一层抽象:前者是编排语义,后者是生成架构。混用名词时,团队容易在评审里争论「算不算 agent」,却忽略真正要定的:终止条件、工具边界、观测粒度。
机制与约束:开放环 vs 固定流水线#
一种实现是 function calling loop:模型读工具返回 → 再决定任务是否完成(访谈中常称 agent)。另一种是 compound AI system:prompt 与工具顺序写死在 pipeline 里。二者名称在业界可互换,边界仍模糊(演讲者观点)。选型上,固定流水线通常更易测延迟与回归;开放环更灵活,但失败模式是「多轮空转」或「过早停止」。
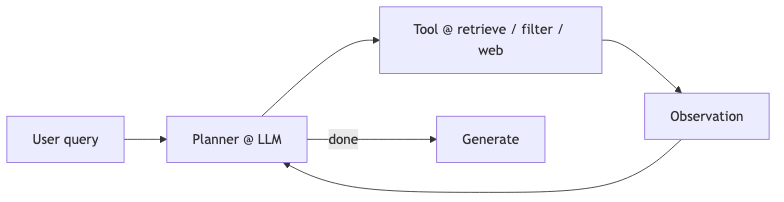
怎么做(最小示例)#
在 OpenAI 兼容栈上,把向量检索注册为一个 tool,由模型决定是否调用——与博客所述 “tool use, multi-step retrieval, and validation” 方向一致:
tools = [{"type": "function", "function": {
"name": "search_weaviate",
"description": "Hybrid search over internal docs",
"parameters": {"type": "object", "properties": {"query": {"type": "string"}}},
}}]
# 循环:completion → 若有 tool_calls → 执行 → 把结果塞回 messages
常见误区#
- 把「能调 API」等同于「有自主性」——未注册的数据源(如 Slack)不会被模型自动访问;博客 明确需 “use an API to retrieve … from Slack channels”。
- 用名词争论代替 SLO:应先定 p95 延迟与最大 tool 轮次。
Vanilla RAG 与 Agentic RAG:单次检索 vs 多步验证#
为什么单次管线会不够用#
Weaviate FAQ(页面 JSON-LD)写明:“Vanilla RAG is typically one-shot retrieval with limited tool access”;正文对比 agentic 侧具备 “retrieve, evaluate, re-retrieve, and validate”。常见痛点:一次语义检索拿不到带时间/对象约束的片段(例如「2024-01-10 与某人的会话」),或库内过时需补 Web。
| 维度 | Vanilla(文档/访谈归纳) | Agentic(文档/访谈归纳) |
|---|---|---|
| 检索次数 | 通常一次 | 可多步、可重检索 |
| 工具 | 有限 | Web、Slack API、数仓等需显式注册 |
| 查询 | 难自动 metadata filter | NL → filter + semantic(agent 行为为访谈观点) |
机制:文档支持什么、访谈补充什么#
已核实:外部工具含 “web searches”;agent 可 “routing/looping logic”。未在博客字面出现:「向量库不够才触发 Web」的条件分支(演讲者观点)。
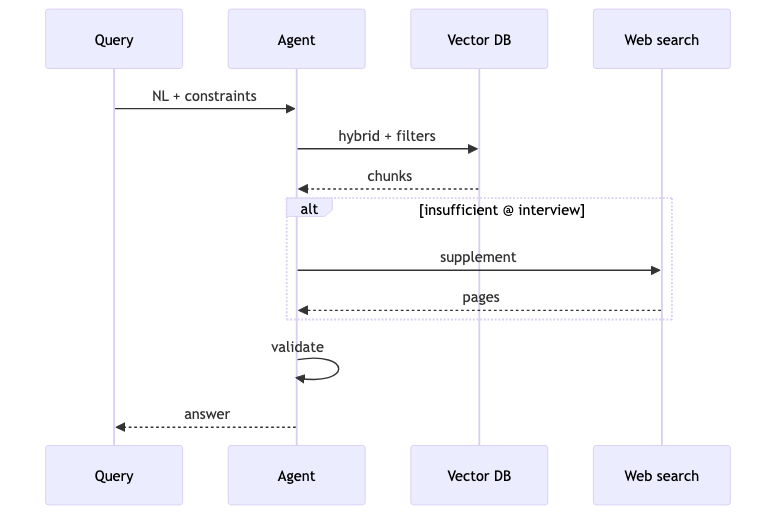
怎么做#
Weaviate Filters 支持按属性包含/排除对象;Python v4 示例:
filters = Filter.byProperty("round").equal("Double Jeopardy!")
由 agent 把自然语言时间戳解析为 Filter.byProperty("timestamp").greater_than(...) 是合理产品路径,但具体 NL→filter 行为未见于 Agentic RAG 博文正文——部署前应在你方 schema 上写集成测试。
常见误区#
- 把 Lewis et al. 的 RAG 模型等同于「retrieve-augment-generate 三步管线」——论文讨论的是密集检索 + 生成器,非产品管线术语。
- 以为 hybrid search 问法只会命中博客 chunk(访谈演示路径,非文档保证)。
规划范式:CoT、ReAct 与 Tree of Thoughts#
为什么规划方式决定成本曲线#
ReAct 论文 摘要指出:模型以 interleaved 方式生成 reasoning traces 与 task-specific actions,并把推理与行动从「分话题研究」拉到一起。相对地,Tree of Thoughts 强调 “considering multiple different reasoning paths” 与 backtracking——在 Game of 24 等任务上相对 CoT 有显著增益(论文报告 CoT 4% vs ToT 74%,任务域特定)。
机制:文献原词 vs 口语二分#
| 主张 | 证据 |
|---|---|
| ReAct 交错推理与行动 | ReAct 摘要 已核实 |
| CoT 易幻觉、ReAct 可借环境反馈纠错 | ReAct 摘要 已核实 |
| 「CoT = 初始拆解,ReAct = 迭代 loop」 | 访谈归纳,论文未用该标签 |
| ToT 在线 RAG 过重 | 演讲者观点;无 RAG 延迟基准 |
主持人在 function schema 强制 thought 字段 ≈ ReAct | 无法核实(无公开 schema) |
两篇工作作者列表均含 Shunyu Yao(arXiv 元数据可核对)。嘉宾推测 OpenAI o1 的中间步骤展开「像 ReAct」,并提到 ReAct 作者流向 OpenAI——嘉宾自述 “it could be a theory”(未证实)。
怎么做#
ReAct 提示轨迹常见 Thought / Action / Observation 三段;生产上也可在每次 tool call 前要求 rationale 字段——与 ReAct 精神相近,但不等于论文算法复现。
常见误区#
- 在 RAG 场景默认上 ToT/MCTS:搜索树前期成本高;访谈倾向 ReAct「错了再改」 更轻(无 benchmark 数字)。
- 把 RL 类比(action = function call,next state = 工具返回)当成已验证的 RAG 训练方案——目前多是启发式架构讨论(演讲者观点)。
多 Agent:编排、并行与异构模型#
为什么单 Agent 扛不住多域知识#
Weaviate 博客 设 Multi-agent RAG Systems 专节,指出单 agent 局限。访谈中的主流形态(演讲者观点):顶层 orchestrator 并行调度子 agent,按 collection/主题/工具切分;子 agent 可绑更小 LLM(如 Llama 3 8B 管单库,GPT-4o/o1 做综合)。博客 HTML 未出现 “parallel” 字样,仅 “orchestrate its components”——并行调度属访谈架构建议。
与 DSPy 的类比:多角色类似 signature 限定「只做这一块」(非形式等价)。点名 OpenAI Swarm 时需注意:README 写明项目 已由 OpenAI Agents SDK 取代,属 experimental/educational——2024-11 录制语境可能仍讨论 Swarm。
怎么做#
逻辑上三层即可落地验证:
- Router agent:分解子问题(可参考 LlamaIndex Sub Question Query Engine——文档写 “breaks down the complex query into sub questions”)。
- Worker agents:各绑定一工具集 + 一 collection。
- Synthesizer:合并子答案并做一致性检查。
常见误区#
- 多 agent = 多份完整系统提示词堆叠 → 成本与冲突指数上升,需共享 trace id。
- 把 CrewAI/AutoGen 点名当作 Weaviate 官方推荐栈(本期无实测数据)。
记忆:Letta、向量库与「记忆算工具还是本体」#
为什么 RAG 不够装下「身份与职位变更」#
Letta(前身 MemGPT)面向 hierarchical memory 与 “virtual context management”,支持跨会话 remember/reflect/evolve。访谈区分:短程在 prompt(含 tool 返回);长期由 Letta 在对话中更新(「身份/职位变更」场景为演讲者观点)。相对 DSPy 优化 prompt/权重,Letta 更偏运行时 记忆块 演化(Memory 概念文档 有 Archival memory、Context hierarchy 等目录——具体写入机制需读专文)。
未决架构(演讲者观点,2024-11 语境):向量库作 长期记忆存储 还是 被 agent 调用的 tool?主持人倾向对 agent 内部记忆再做 Agentic RAG;Weaviate × Letta 集成仍待完善。
常见误区#
- 把所有历史消息塞进向量库就算「长期记忆」——缺少分层与淘汰策略会拖垮检索质量。
- 假设 Letta 与 Weaviate 已一键打通(产品集成未完成)。
可观测性与评测:Trace 先于「感觉还行」#
为什么 Agent 系统必须先可追踪#
Agent 链路慢、步骤多;没有 “still running” 信号,运维与用户都会误判卡死。Arize Phoenix 文档写明通过 OpenTelemetry 接收 OTLP trace,并支持 LLM-as-a-judge evaluators。Google Vertex AI Agent Builder 文档含 Observability、Unified Trace Viewer 等方向——与播客提到的「分解步骤 UX」部分核实(具体 UI 未逐帧对照)。
机制:观测量的最小集合#
建议每条用户请求至少记录:plan_id、tool_name、latency_ms、retrieved_ids、token_usage、final_stop_reason。这与博客强调的 “validation” 闭环一致——否则无法回答「错在检索还是生成」。
常见误区#
- 只盯答案 BLEU/ROUGE,不看 哪一步 tool 返回为空。
- 把 Demo 里的步骤条当成生产级 trace(访谈 UX 观点)。
LLM-as-Judge 与「More Agents」:论文能支持什么#
为什么法官模型不可靠(访谈侧)#
嘉宾认为业界 高估 LLM-as-judge:temperature 常未配置、同 prompt 多次漂移(工程观察,无一手论文)。主持人转述 Nils Reimers 观点:用 OpenAI 评 Cohere 会有 模型偏见;GPT-4o 能嗅出同族文风(二手引述,未复现)。
More Agents Is All You Need(arXiv:2402.05120)#
已核实:提出 sampling-and-voting(AgentForest 代码库),任务含 GSM、MATH、MMLU、Chess、HumanEval 等;性能与 task difficulty(固有难度、推理步数、先验概率等维)相关。
无法核实 / 与访谈不一致:
| 访谈表述 | 论文实际 |
|---|---|
| ~25 次采样 | 分析中出现 sampling 40 times 等,无通用「25」推荐 |
| easy/hard 化学/物理题 | 全文 无 chemistry/physics 关键词 |
| 难题上多采样对 judge 无效 | 论文 非 LLM-as-judge 设定 |
| judge 场景 ~20 次更稳 | 访谈观点 |
引用该文时勿写成化学/物理 easy-hard,除非另找来源。嘉宾认为 agent 数量 边际递减(演讲者观点;论文讨论 scaling,非 judge 专用曲线)。
常见误区#
- 把「多次采样判分」等同于 HumanEval 的 pass@k 而不读任务定义。
- 用单一法官模型评跨厂商栈却不做 对照人工标注。
长任务、合成数据与 Generative Feedback Loop#
为什么有些 workload 宁可等数小时#
问答型 hybrid search 适合 秒级 RAG;STORM(“researches a topic and generates a full-length report with citations”)与多层 DSPy 流水线(访谈归纳为 research→outline→content→title)属于 慢路径——多步工具、自检、引用。访谈中的 GFL(generative feedback loop):agent 在 Web + Weaviate 间循环产 合成数据/标注,且 autonomy 可能优于「只做 RAG 生成」(无对照实验;Weaviate Agentic RAG 博客无 GFL 字样)。
主持人提出「套娃 GFL」:写论文式任务需把代码/实验结果写回库,agent 自身再依赖 GFL 管理中间态(架构提案,非产品承诺)。嘉宾强调 human-in-the-loop、可「拔电源」——呼应 2023 Auto-GPT 文化下的抵触(演讲者观点)。
常见误区#
- 用 chatbot 延迟预期衡量 STORM 类报告系统。
- 把四层 DSPy 当作论文规定阶段(访谈演示归纳;DSPy 论文强调 compiling declarative LM calls 与 self-improving pipelines,未规定该四段博客程序)。

Techniques for Building Better Agent Systems、evaluate_agents(、type="AI"、scope="Agent Systems"、Erika Cardenas、Arize / LlamaIndex / AutoGen 等标识(非本期中段架构幻灯)。
若你要落地#
- 先钉工具清单与隐私边界:只注册允许访问的数据源;用 Filters 写清 schema,再让 planner 生成 filter——并为 NL→filter 写回归用例(博客未保证 agent 自动解析)。
- 设定 loop 预算:最大 tool 轮次、p95 延迟、停止条件(空结果、重复查询、置信度阈值);在 Phoenix 或 OTLP 后端落 trace。
- 分层选型:秒级问答走 one-shot / 轻 hybrid;多步调研走 ReAct + 验证,慎上 ToT 除非你有离线算力与评测集证明收益。
- 评测分开两层:检索(MRR、nDCG)与端到端(人工 + 抽样);若用 LLM-as-judge,固定 temperature、记录法官模型版本,勿照搬 More Agents 的化学/物理叙事。
- 多 agent 先串行验证再谈并行:博客未承诺 parallel;异构小模型子 agent 是成本优化方向,需用你自己的 QPS 与质量曲线证明。
参考与延伸阅读#
- Weaviate — What Is Agentic RAG? — Agentic vs vanilla、multi-agent、tool loop 主锚
- Weaviate — 查询 Filters — 属性过滤 API 与示例
- Lewis et al. — Retrieval-Augmented Generation (arXiv:2005.11401) — RAG 奠基工作(模型层定义)
- ReAct — Synergizing Reasoning and Acting (arXiv:2210.03629) — 交错推理与行动
- Tree of Thoughts (arXiv:2305.10601) — 多路径与回溯
- LlamaIndex — Sub Question Query Engine — 子问题分解检索
- OpenAI — Function calling 指南 — tool schema 与循环集成
- DSPy — Compiling Declarative LM Calls (arXiv:2310.03714) — 声明式流水线与优化
- MemGPT — arXiv:2310.08560 — 分层记忆与虚拟上下文
- Letta — GitHub — MemGPT 后继项目
- Letta — Memory 概念 — Memory blocks / Archival memory
- STORM — stanford-oval/storm — 带引用的长报告生成
- More Agents Is All You Need — arXiv:2402.05120 — sampling-and-voting / Agent Forest
- Agent Forest — GitHub — 论文参考实现
- Arize Phoenix — LLM Traces — OTLP 与 OpenTelemetry
- Google Cloud — Vertex AI Agent Builder 概览 — Agent 平台与可观测性
产品能力与论文结论随版本变化;访谈中的并行编排、NL→filter 触发链、GFL 与 o1–ReAct 推测等,部署前请在自有数据与 trace 上复测。


