
Agentic 主题建模:嵌入管线、LLM 与人在环内的工程权衡#
大规模语料库上的「主题」早已不是 LDA 词袋时代的专属问题。向量检索、RAG 与 Agent 工具链把文档级 embedding推上主舞台,但运营侧仍需要可浏览、可过滤、可迭代的主题层元数据——既能支撑分析师读报告,也能在百万文档场景里充当粗筛索引。近期讨论里常把 agentic topic modeling 与 TopicGPT、BERTopic 并置;若剥离播客叙事,核心张力其实是三条路线的取舍:静态嵌入聚类、LLM 维护主题表并分派,以及人在环内用自然语言 steer 粒度。下文按工程主题组织,证据以官方文档与论文为准;未在一手来源出现的数值与产品吞吐,标注为演讲者/主持人观点。
问题空间:主题在 RAG 栈里扮演什么角色#
为什么:纯文档 embedding 检索在语义上已经很强,但用户往往还要回答「这批投诉主要在抱怨什么」「过去一季度新增了哪些议题」——这需要介于全文与单句之间的中层结构。主题层若做得好,可作为向量库上的元数据分区或两阶段检索的第一跳;若做得差,则引入错误先验,比不用更糟。
机制/约束:「主题」本身没有唯一形式——可以是 BERTopic 的 c-TF-IDF 关键词列表,也可以是 TopicGPT 式的自然语言标签与描述。演讲者观点:呈现形式高度主观,不存在放之四海而皆准的「正确主题」。
怎么做:在架构上把主题产出与下游消费解耦——先明确消费者(分析师 UI、检索 router、评估流水线),再选表示(词权重 vs LLM 摘要 vs 层次树)。
常见误区:把「主题」等同于「LLM 生成的一句标题」;缺少可比分数时,人眼会过度信任流畅表述(见后文评估一节)。
模块化嵌入管线:可替换的 building blocks#
为什么:Embedding 模型、聚类器与降维算法迭代很快;若主题建模绑死单一栈,每次换 SentenceTransformer 或换密度聚类器都要重写流水线。
机制/约束:BERTopic 算法页 将流程表述为 five steps:Embeddings → Dimensionality Reduction → Clustering → Tokenizer → c-TF-IDF(class-based TF-IDF)→ 可选 Representation。各步可替换;arXiv:2203.05794 摘要亦写明:对文档嵌入聚类,再以 class-based TF-IDF 生成主题表示。
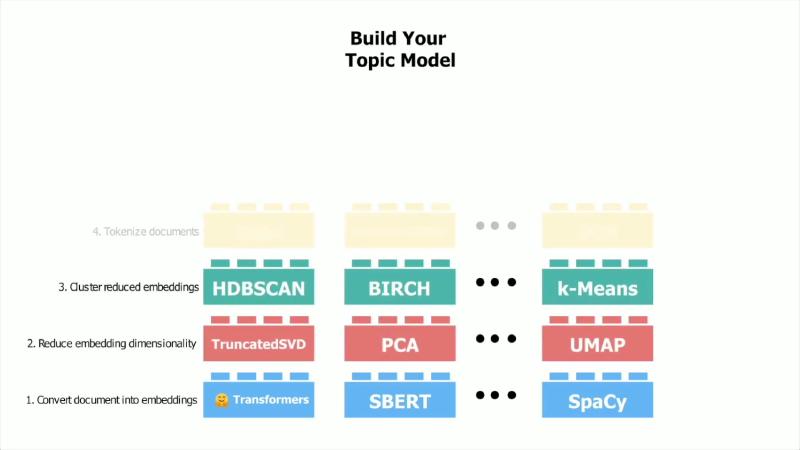
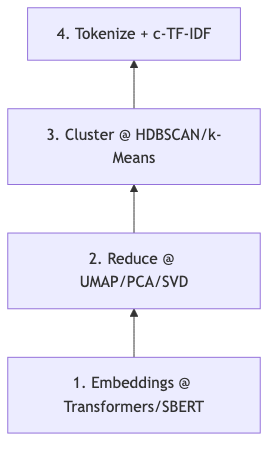
怎么做(最小示例,与官方默认一致):
from bertopic import BERTopic
from umap import UMAP
import hdbscan
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric="cosine")
hdbscan_model = hdbscan.HDBSCAN(min_cluster_size=15)
topic_model = BERTopic(umap_model=umap_model, hdbscan_model=hdbscan_model)
topics, probs = topic_model.fit_transform(docs)
常见误区:把展示用 2D 散点图当成聚类真实空间。官方示例使用 n_components=5;5–10 维为嘉宾经验区间,非 UMAP 文档规定的默认值(UMAP parameters)。2D DataMapPlot 适合叙事,解释簇组成时应回到高维空间、词权重与样本文档。
LLM-native 主题发现:TopicGPT 与 TnT-LLM#
为什么:聚类 + c-TF-IDF 的主题词偏「统计显著」,不一定符合业务话术;LLM 可直接产出可读标签与层级 taxonomy。
机制/约束:
- TopicGPT(arXiv:2311.01449):prompt 框架,用 LLM 发现 latent topics(自然语言标签 + 描述),README 含
generate_topic_lvl1、refine_topics、assign_topics等,generation 与 assignment 分离。 - TnT-LLM(arXiv:2403.12173):two-phase — 阶段一生成/refine label taxonomy,阶段二用 LLM 标注训练轻量分类器做规模化 assignment。
演讲者观点:对全库逐文档反复调用 LLM 浪费;更稳妥的是 embedding 预聚类 + LLM 做引导或顶层摘要。若推理成本趋近零,全库 LLM inspector 在逻辑上说得通——届时 embedding 可能退居可视化与层次分析(条件性前瞻,未有 benchmark)。
怎么做:将 LLM 主题表导出为标签向量 y,接入 BERTopic 监督/半监督路径(见下节),而非推倒重来。
常见误区:认为 TopicGPT 与 BERTopic 结构不可对接;嘉宾主张可把 TopicGPT 主题扔回 BERTopic 做推断与可视化(访谈工作流,能力上由 Supervised / Semi-supervised 支持)。
Assignment 与 Generation 解耦#
为什么:全库 LLM 重写表示层成本高;而「把 10 万文档分成 200 簇」与「给 200 簇各写一句人话标题」的计算形态不同。
机制/约束:BERTopic 先 assignment(聚类),再 generation(c-TF-IDF 与可选 Representation models)。TopicGPT / TnT-LLM 亦显式区分 topic generation 与 assignment。演讲者观点:表示层迭代只触及主题数级体量,相对全库 LLM 便宜——「~1% 数据量」为量级直觉,无一手公式,不宜写成论文数据。
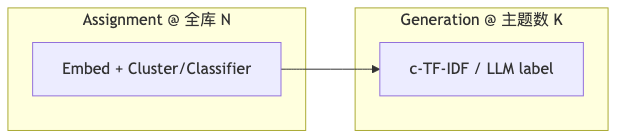
怎么做:固定 assignment 后,仅替换 representation_model 或重跑 c-TF-IDF,避免重算 UMAP/HDBSCAN。
常见误区:端到端一次 prompt 搞定分派与命名,导致无法单独评估「分派对不对」与「名字好不好听」。
「Agentic」:工具调用、人在环内与粒度#
为什么:企业场景里最大摩擦往往不是算法,而是粒度——太粗漏掉子议题,太细无法对接检索 Agent。
机制/约束:本集语境下的 agentic topic modeling ≈ 工具调用 + human-in-the-loop + 自然语言 steer,非通用 Agent 框架的形式化定义(访谈观点)。演讲者观点:流程仍是 user-driven;再强的模型也不会自动猜中你想要的粗细。主持人补充:选择自由度太高反而 choice overload——人更擅长在有限选项里选(例如「合并 Topic 3 与 7」「只要 12 个顶层主题」)。
怎么做:把 Agent 接口设计成提议-确认循环:系统输出候选主题与样本文档 → 用户用结构化指令合并/拆分/重命名 → 再触发半监督重聚类或仅重跑表示层。
常见误区:把「能调 API 的 LLM」等同于「会自动收敛到业务满意主题」;忽略层级主题与单层检索 Agent 的对接成本——演讲者观点:检索场景可忽略层次,用细粒度主题元数据即可;主持则认为层次会增加与查询 Agent 的接口复杂度(双方均未给出统一结论)。
聚类选择:HDBSCAN、k-means 与参数试错#
为什么:密度聚类能发现任意形状并标噪声,但超参不透明;k-means 固定 K,便于与 LLM 对比邻簇。
机制/约束:HDBSCAN min_cluster_size 表示「仍视为簇的最小 grouping 规模」,增大倾向更大、更少的簇,但簇总数仍需实验——不是直接的「我要 K 个主题」旋钮。演讲者观点:min_cluster_size 难先验,是企业部署主要摩擦;有人改用 k-means + 事后密度过滤(偏好陈述,HDBSCAN 文档未讨论)。
怎么做:
import hdbscan
clusterer = hdbscan.HDBSCAN(min_cluster_size=30, min_samples=10)
labels = clusterer.fit_predict(reduced_embeddings)
对 k-means,可让 LLM 阅读相邻簇关键词差异以辅助选 K(访谈思路,未核实 k-LLM-means 等方法细节)。
常见误区:递归对 HDBSCAN 子簇再聚类即可得到稳定层次——嘉宾认为子簇参数敏感,实践中难维护(演讲者观点)。
c-TF-IDF:簇对比度与可读分数#
为什么:LLM 单行标签缺少跨主题可比分数,分析师难以判断「这个词有多属于本主题」。
机制/约束:ClassTfidfTransformer 将每个簇视为一个「类文档」,做 l1 归一化词频 × IDF,突出本簇相对其他簇的独特词;论文称 class-based variation of TF-IDF(arXiv:2203.05794)。演讲者观点:可类比简易「对比学习」;反对词云——字号误导人类对权重的感知,故 BERTopic 可视化不提供 word cloud(产品行为与口述一致,官方页未逐字写「反对词云」)。
怎么做:向 UI 暴露 term score 排序列表,而非仅用面积编码的词云。
常见误区:见到流畅 LLM 主题名即停止阅读代表文档。
评估:自动化 coherence 与「用户想要的主题」#
为什么:需要离线指标筛模型,但神经/嵌入主题模型上经典 topic coherence 可能与人类判断脱节。
机制/约束:
- Are Neural Topic Models Broken?(arXiv:2210.16162):神经主题模型在稳定性、与人类类别对齐上可能逊于经典 LDA。
- Is Automated Topic Model Evaluation Broken?(arXiv:2107.02173):自动化 coherence 与 topic rating / word intrusion 不一致。
- Revisiting Automated Topic Model Evaluation with LLMs(arXiv:2305.12152):LLM 评判与人工相关性更强于部分传统自动指标。
播客口述论文题 “are neural topic modeling evaluation metrics broken?” 未命中上述精确标题,写作应引用 arXiv 题名。画面叠印 ProxAnn: Use-Oriented Evaluations… 方向与「面向用途」评估一致;与 O’Reilly Hands-On Large Language Models(Jay Alammar & Maarten Grootendorst)为不同出版物。

演讲者观点:coherent + diverse 仍可能不是业务关心的维度;须叠加用户约束(最少主题数、必须覆盖某类、禁用某些词)。
常见误区:单一 NPMI/coherence 排行榜选型;不做人工读文档与任务导向评测(use-oriented)。

检索加速:两阶段与 IVF 类比#
为什么:百万文档 × 全库向量 ANN 成本高;若文档已带主题 ID,可先缩小候选集。
机制/约束:演讲者观点:先对主题 embedding 检索 Top-K 主题,再在相关主题内做文档级检索;语义信息可能与纯 embedding 重叠,但速度是明确收益。主持人口头估算约 5% 文档进入二阶段——无 benchmark,无法核实。与 FAISS IndexIVF 的粗量化类似;Weaviate 向量索引 文档列的是 HNSW / flat 等,非以 IVF 为主表述——类比对象需写明。
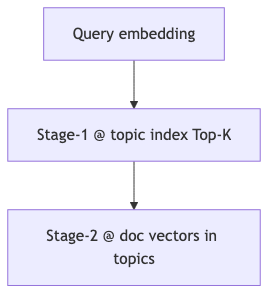
怎么做:为主题标签/描述单独建 embedding 索引;文档对象写入 topic_id 元数据;二阶段 recall 用 held-out 查询集测。
常见误区:未测二阶段召回损失即上线;把 5% 当作普适加速比。
混合管线:Supervised 与 Semi-supervised BERTopic#
为什么:已有 TopicGPT 标签或业务 taxonomy 时,不必再让 HDBSCAN 「重新发现」一遍。
机制/约束:
- Supervised BERTopic:skip 降维,用分类器替代聚类,再对标签跑 c-TF-IDF。演讲者观点:称「hack」,但简单有效。
- Semi-supervised:用部分标签做 semi-supervised UMAP,再 HDBSCAN;
fit(docs, y=...),未标注可用 -1。 - Serialization:
safetensors不保存聚类/降维权重,推理可基于 topic embeddings;Dynamic Topic Modeling 可在不重跑聚类下对各时间片滑 c-TF-IDF。
怎么做:
# 已有外部 labels(如 TopicGPT 输出)
topic_model = BERTopic(umap_model=None, hdbscan_model=your_classifier)
topic_model.fit(docs, y=labels)
topic_model.save("model_dir", serialization="safetensors")
半监督:对已知主题文档传入 y,让 UMAP supervised 引导流形,再聚类。
常见误区:以为 supervised 会「修正错误标签」——它假定 assignment 已给定,只重建表示与推断接口。

未收敛的分歧(不必强行统一)#
| 轴 | 常见做法 | 嘉宾/讨论中的另一极 | 证据状态 |
|---|---|---|---|
| 主路线 | Embed → UMAP → HDBSCAN → c-TF-IDF | 全库 LLM TopicGPT 式分派 | 嵌入路线有 官方文档;全库 LLM 成本论点为访谈 |
| 层次 vs 单层 | 层次 BERTopic / TopicGPT lvl2 | 单层 + 细粒度元数据服务检索 | 双方观点,无实验对比 |
| 评估 | NPMI / coherence | LLM-as-judge + 人工 | 见 2107.02173、2305.12152 |
| Agent 定义 | 固定 DAG workflow | Tool use + human-in-the-loop | 访谈观点 |

若你要落地#
- 先定消费者:分析师读报告、检索 router、还是离线评估——再选「词权重主题」还是「LLM 标签主题」,避免端到端黑箱。
- 默认走模块化 BERTopic:
n_components=5起步(官方示例),2D 图只作叙事;用 c-TF-IDF 分数 + 样本文档做 QA,而非只看 LLM 标题。 - LLM 放在 generation 或引导:TopicGPT/TnT-LLM 产出
y后,用 Supervised/Semi-supervised 接入;全库反复 assign 前先做成本估算。 - 评估叠加任务约束:在 coherence 批判 与 LLM 评判 之外,增加「必须覆盖类」「最少主题数」等业务规则;引用论文用精确 arXiv 题名。
- 检索二阶段先测 recall:主题 Top-K 与文档 ANN 的级联需 held-out 查询验证;勿采用未核实的 5% 文档比例作为容量规划依据。
参考与延伸阅读#
- BERTopic 官方文档 — 模块化主题建模入口
- BERTopic 算法总览 — 五步管线与默认组件
- BERTopic 论文 arXiv:2203.05794 — class-based TF-IDF 与聚类流程
- TopicGPT arXiv:2311.01449 — Prompt 式主题发现与分派
- TnT-LLM arXiv:2403.12173 — 两阶段 taxonomy 与轻量分类器
- Supervised BERTopic — 外部标签跳过聚类
- Semi-supervised BERTopic — 标签引导 UMAP 再聚类
- BERTopic safetensors 序列化 — 推理不保存降维/聚类权重
- UMAP 监督降维 —
y与target_metric - HDBSCAN 参数选择 —
min_cluster_size语义 - Are Neural Topic Models Broken? arXiv:2210.16162 — 神经主题模型稳定性与对齐
- Is Automated Topic Model Evaluation Broken? arXiv:2107.02173 — coherence 与人工评判不一致
- Revisiting Topic Model Evaluation with LLMs arXiv:2305.12152 — LLM-as-judge 与人工相关性
- ProxAnn arXiv:2507.00828 — 面向用途的主题模型评估
- Hands-On Large Language Models(O’Reilly) — Jay Alammar & Maarten Grootendorst 合著


