
检索嵌入的工程取舍:从 Arctic Embed 看榜单、训练与生产约束#
向量检索的质量,往往在「换 embedding」这一环就被决定大半——至少 Snowflake 与 Weaviate 两侧工程师在公开讨论里都把话说得很直。本文围绕 Snowflake Arctic Embed 系列(含 Arctic Embed 2.0 技术报告)梳理:榜单该怎么读、对比学习预训练与 fine-tune 各自解决什么、Matryoshka 表征学习(MRL)如何落到十亿级索引,以及 多语基准与专有分布之间的裂缝。数字优先对齐 arXiv 与官方 README;内部基准、成本估算与部分体感结论标为「演讲者观点」,并标明无法独立复现的边界。
问题空间:RAG 里 embedding 站在哪一环#
为什么:检索增强生成(RAG)与 agent 工具链里,常见路径是 query → 稠密(或混合)检索 → 重排 → 上下文拼装 → LLM。embedding 把文本压成固定维向量,索引侧用 HNSW 等近似最近邻结构做召回。一旦向量语义与业务问法错位,后面的 cross-encoder 重排只能「在错误候选里排序」。
机制/约束:Snowflake 将 Arctic Embed 用于自研 Cortex Search 并与开源权重对齐;Weaviate 在 Cloud Embeddings 模型列表 中提供 Snowflake/snowflake-arctic-embed-m-v1.5、Snowflake/snowflake-arctic-embed-l-v2.0 等托管选项。产品侧动机是:第三方 embedding API 的限流、维度与计费模型,与向量库索引参数强耦合。
怎么做(最小示例):在 Weaviate 中指定 vectorizer 为托管 Arctic 模型时,collection 的 vectorIndexConfig 维度须与模型输出一致;若计划用 MRL 截断,需在入库与查询两侧约定同一前缀维(见下文)。
常见误区:把「换更大 LLM」当成检索质量主杠杆。演讲者观点(Snowflake 内部早期搜索调参):调 synonym、融合、reranker 有收益,但 换 embedding 的影响往往最大——该主张 无法 用公开 Cortex Search A/B 表核实,宜作假设而非定理。

榜单素养:MTEB、BEIR 与 MIRACL 各量什么#
为什么:选型时工程师常扫 MTEB leaderboard。MTEB 覆盖分类、聚类、检索等八类任务;全任务平均分 与「你的系统是否只做 passage retrieval」并不等价。Snowflake 团队反复强调:若业务是 BEIR 式同任务检索,应盯住 MTEB Retrieval(常记为 MTEB-R)上的 nDCG@10,而非平均分。
机制/约束:
| 基准 | 典型指标 | 分布特点 | 读榜时注意 |
|---|---|---|---|
| BEIR | nDCG@10 等 | 异质零样本 IR,跨域 | 最初为证跨域泛化;社区现常混用 MS MARCO、NQ 等训练集(演讲者批评:易变成「在测集上拟合」) |
| MTEB-R | nDCG@10 | 与 BEIR 有重叠的检索子集 | Arctic 论文主报此列 |
| MIRACL | nDCG@10,18 语 | Wikipedia 段落 | 2.0 作者自述训练亦用到 MIRACL 相关数据;不宜 当唯一多语真理 |
怎么做:评估脚本对齐论文口径——例如 Arctic Embed 2.0 Large 全维 MTEB-R 0.556,256 维截断 0.547(Table 1,约 98.4% 保留)。口语里的「98% recall」在文献中实为 MTEB-R nDCG@10 相对全维分数的保留率,不是 recall@k。
常见误区:
- 用 MIRACL 18 语均分选模型,却部署在新闻、工单、代码库等 域外 语料——2.0 在 CLEF 等域外集上相对 MIRACL 的差距,论文用语是 suggesting potential overfitting,非指控作弊。
- 1–2 分的榜单差距未核对 prompt 模板、池化、归一化 是否与论文一致(演讲者观点:apples-to-oranges 很常见)。
预训练:E5 式对比学习与 batch 工程#
为什么:通用句向量若只做 token-level MLM,检索对齐不足。E5 路线用弱监督 InfoNCE + in-batch negatives 在 query–document 对上预训练;Arctic 1.0/2.0 自述 closely replicates 该范式,README 称约 4 亿 预训练样本对。
机制/约束(可核对部分):
- Batch size:2.0 报告 32,768,32×H100 数据并行(§2 / Appendix);访谈口语「约 32k」与文献一致。
- Source stratification(1.0 §4.4):每个 minibatch 仅含单一数据源;Table 5 在 batch 16,384 下 stratify Yes → 46.96 vs No → 43.74 nDCG@10(MTEB-R 子集)。2.0 将 不同语言子集 也视为 source。文献引用 prior work 亦有 single-source minibatch——宜称「Arctic 系统 ablation」,而非全球首创。
- 负样本:预训练主要靠 大 batch 随机 in-batch negatives(演讲者观点);精细 hard negative 策展主要在 fine-tune 阶段才关键。
怎么做(概念级):复现实验时先固定 stratify 开关与 batch 规模,再谈换 backbone;聚类式预训练另有 预印本 2407.18887,但主报告认为收益小于 stratify。
常见误区:把访谈中「4k→8k→16k 持续提升」直接当作 2.0 正文曲线——1.0 Table 5 有 4,096 vs 16,384 两点;完整三点曲线 未 在已公开正文找到,更可能来自内部或对 E5/BGE 的转述。Modal 整段预训练 约 2,000 美元 为 访谈估算,无法复核。
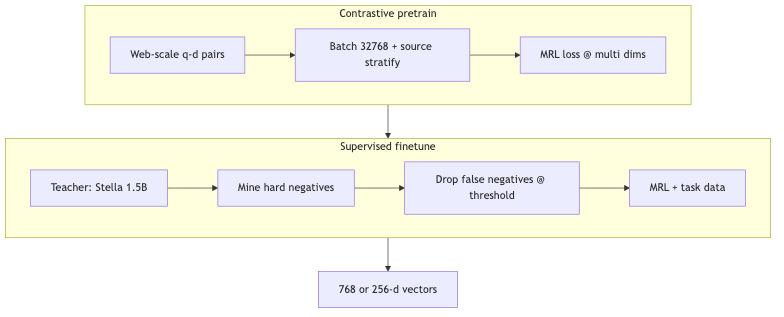
Fine-tune 2.0:Teacher、假负样本与 curriculum 的负结果#
为什么:预训练给出通用几何;领域检索常靠 fine-tune 拉近 query–正例、推远 hard negatives。
机制/约束(2412.04506 §2.4,已核实):
- Teacher 模型:英语用
stella-en-1.5B-v5(HF:dunzhang/stella_en_1.5B_v5),对比较弱gte-large-en-v1.5;多语侧用multilingual-e5-large等。 - 假负样本过滤:沿用 NV-Retriever(勿与 NV-Embed 混淆)——候选负例若得分 高于已知正例的某百分比阈值(Figure 2 扫描 95%–99%)则丢弃,避免把真相关文档当负例训练。
- Curriculum learning:正文写明 random data ordering produced comparable or better results;与 1.0/1.5 时代「课程式 hard negatives 约 +0.5 MTEB-R」形成反差。
演讲者观点:换更强 单一 teacher 的收益,可比拟 fine-tune 阶段「10× 缩放定律」量级;相对 NV-Embed 式多 teacher ensemble,团队选 运维简单的单 teacher(ensemble 增益在对方论文中亦有限——对比性陈述,非本文复现)。
怎么做:自建 fine-tune 管道时,至少实现 (1) teacher 打分挖掘 negatives,(2) 按 known-positive 分数比例过滤假负例,(3) 用固定随机序作 ablation baseline,再考虑 curriculum。
常见误区:在 2.0 上继续堆 curriculum,却未同步升级 teacher 与阈值——可能白做工。引用硬负样本流程时请链 NV-Retriever (2407.15831)。
MRL 与生产:维度、内存与指标口径#
为什么:Matryoshka Representation Learning (MRL) 训练时强制向量 前缀子向量 在各截断维下仍可用,以便在索引侧用 256 维 换 约 4× 存储与 HNSW 内存,而尽量保留排序质量。
机制/约束:
- 2.0:MRL 贯穿 contrastive pretraining 与 finetuning 优于仅在 fine-tune 加 MRL;后者又优于「无 MRL 直接截断」(§2.5)。Large 模型 768→256 维保留约 98% MTEB-R nDCG@10;对比 Google text-embedding-004 截断后约 94%(2.0 正文引用第三方,非直接复刻 Gecko 全文口径)。
- Weaviate Resource Planning:HNSW 索引须驻内存;
vectorCacheMaxObjects限制缓存向量数。十亿规模下,用 7B 级 embedding 换 2× 质量、却吃掉内存预算,往往不如 MRL 降维 + 可选 PQ 重打分(演讲者观点:全精度向量有时仍须保留,因不知查询将用哪段前缀维)。 - 演讲者观点(未公开表):MRL 截断后 recall@k 掉得慢、nDCG@10 掉得多——「低维仍找得到,但排序更噪」。论文 未 用 recall@k 对照,写作时应分开表述。
怎么做:索引维数 d_index=256,查询与文档 同一截断;若启用量化索引,可对候选集做磁盘重打分,再回全维向量精排(产品实现因栈而异)。
常见误区:把「98% 保留」理解成 recall@10 不变。另:在 仅完成约 30% 计划预训练 后就做 MRL fine-tune 会变差——属 Puxuan 开发经历(访谈观点);文献方向一致但无「30%」公开表。
多语:迁移、过训练与「omnilingual」幻觉#
为什么:企业语料常混合英、中、日、西语;单模型多语可避免「英语一套、多语一套」的运维分裂。行业默认多语会 牺牲英语 MTEB;Arctic Embed 2.0 报告英语 MTEB-R 与强英语基线接近(Table 1:2.0-M 0.554 vs 1.0-M 0.549),但团队自述 「为何单模型不伤英语」仍未完全弄清(访谈观点)。
机制/约束(部分可核对):
- Figure 3 / §4.1:对比预训练步数增加时,未出现在预训练语料的语言(如 zh、ja)在 MIRACL 上可出现 负向跨语迁移(例:zh finetune 后 nDCG@10 相对变化 -13.3% 等,以论文图注为准)。结论句:prolonged contrastive pretraining does not always enhance cross-lingual transfer。
- Figure 4:向预训练 加入中文数据可提升英语 MTEB-R——针对的是「非目标语 over-training」风险,而非「中文必然伤害英语」。
- MIRACL vs 专有集:Puxuan 称团队有 未公开 训练外评测集,观察到多种开源多语模型 MIRACL 很强、专有集明显变差(不可验证)。Luke 缓和:不宜直接指控过拟合,但 Wikipedia 分布与 Gecko 等商业模型对比时,~100M 开源档在 MIRACL 均分上可显著更高,而英语 MTEB-R 可能落后 2–5 分(访谈 + 第三方表,未在本环境复算 Gecko 全表)。
怎么做:客户仅中英时,应用 客户域 hold-out 集评估,而非只报 MIRACL;若预训练语料不含日语,应监控日语 query 是否因 过长预训练 退化。演讲者估计「预训练时长可减半仍 pretty decent」——无文献比例结论。
常见误区:把 multilingual 当成 omnilingual;MIRACL 18 语均分不能代表工单、法规、代码注释等分布。
架构分岔:单向量 HNSW vs ColBERT / SPLADE / 重排#
为什么:多向量(ColBERT)、稀疏(SPLADE)与 cross-encoder 重排在理论上可抬高上限,但带来存储、延迟与工程复杂度。
机制/约束(多为访谈观点,无 Arctic 公开消融表):
- Snowflake Cortex Search 面向 大规模单向量 + HNSW;Luke 称 ColBERT 更强但 实现与存储成本高。
- 在已有强 dense 神经检索后,再叠 SPLADE 的边际收益 常不明显(立项前内部实验,未公开)。
- Weaviate 路线:模块化 向量库 + 可选托管 embedding,规避单一黑盒搜索栈。
怎么做:默认路径选 单向量 + 可选 cross-encoder 重排;仅在召回率瓶颈且团队能承担索引复杂度时引入 ColBERT 类方案。
常见误区:榜单 7B 级 embedding 直接上生产——eval 泄漏、推理成本与 HNSW 内存可能不划算。演讲者「hot take」:若预训练就能达到 fine-tune 级 hard negative 质量,7B 训练作业可能显得浪费——强烈主观,勿当共识。
信任边界:「懂模型」还是「懂提供方」#
为什么:开源权重与托管 API 是否一致,影响 RAG 供应链审计。
机制/约束:Snowflake 宣称 Cortex Search 与开源 Arctic Embed 共用同一模型族;Weaviate Cloud Embeddings 列表含 Arctic 型号。Charles 一侧论点:提供方 自用同一 embedding 做生产检索,比单看 MTEB 分数更能建立信任——属 产品伦理与组织行为,非可复现定理。
常见误区:只看 leaderboard 选模型,不读 训练数据与评测集重叠(2.0 对 MIRACL 的自述即一例)。
若你要落地#
- 评测对齐业务:以 MTEB-R / 自有域 nDCG@10 为主指标;若有多语,加 域外 集(新闻、工单),勿仅用 MIRACL Wikipedia。
- 维度与索引一并设计:若采用 Arctic 2.0 Large 的 256 维 MRL 前缀,在 Weaviate(或其它 HNSW)入库前固定
d,并核对 HNSW 内存规划;口语「recall 保留」请改写为 MTEB-R nDCG@10 保留率。 - Fine-tune 抄作业顺序:teacher 挖掘 → NV-Retriever 式假负例过滤 → 随机序 baseline;在 2.0 设定下 不必 优先 curriculum。
- 多语预训练监控:对 未进预训练语料的语言 画学习曲线,防止「训越久越好」;必要时缩短 contrastive pretrain(访谈建议)并以客户域验证。
- 托管 vs 自托管:用 Weaviate Embeddings 模型页 或 Snowflake-Labs/arctic-embed 锁定版本与维度;变更模型时 全量重嵌入,勿假设旧向量可混用。
参考与延伸阅读#
- Arctic-Embed(arXiv:2405.05374) — 1.0 技术报告:对比预训练、source stratification、batch ablation
- Arctic-Embed 2.0(arXiv:2412.04506) — MRL、多语迁移、teacher 与假负例、curriculum 负结果
- Snowflake-Labs/arctic-embed(GitHub) — 权重、推理示例与 README 训练规模
- MTEB: Massive Text Embedding Benchmark(arXiv:2210.07316) — 任务族与 leaderboard 定义
- BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation(GitHub) — 零样本 IR 基准包
- MIRACL 多语检索项目站 — 18 语 Wikipedia 检索说明
- Text Embeddings by Weakly-Supervised Contrastive Pre-training(E5, arXiv:2212.03533) — Arctic 预训练范式来源
- Matryoshka Representation Learning(arXiv:2205.13147) — MRL 原始方法
- NV-Retriever: Improving Text Embedding Models with Effective Hard-Negative Mining(arXiv:2407.15831) — 假负例阈值策略
- NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models(arXiv:2405.17428) — 与 Retriever 论文区分阅读
- Gecko: Versatile Text Embeddings Distilled from Large Language Models(arXiv:2403.20327) — 商业嵌入与截断对比语境
- Embedding And Clustering Your Data(arXiv:2407.18887) — 聚类式预训练探索(非主路径)
- Weaviate 向量索引概念 — HNSW 与索引类型
- Weaviate 资源与 HNSW 内存 — 「索引须驻内存」原文
- Weaviate Cloud Embeddings 模型列表 — 含 Snowflake Arctic 型号


