
在 exabyte 级非结构化内容上做企业 AI:权限、检索分层与 Agent 边界#
企业把文档、合同、标书、媒体丢进 Box 一类内容云之后,真正难的不是「能不能调 GPT」,而是三件事同时成立:数据在变、谁能看见什么在变、索引与推理的账单在变。Box CTO Ben Kus 与 Weaviate 联合创始人 Bob van Luijt、Connor Shorten 在一期技术播客里,从存储与多租户权限一直谈到 RAG、embedding 经济学和 Agent——下文按工程主题重组,不按时序复述;凡未在 SEC 10-K、OpenAPI 或论文中核验的,均标为演讲者观点。
问题空间:为什么「大窗口 + 通用模型」仍不够#
行业常见论调是:context window 变大以后,RAG「几乎不需要了」。Ben Kus 的反驳(演讲者观点)针对的是企业私有库,而非公开网页问答:内容持续上传与修订;同一问题在不同用户下可见集合不同;把「全库」塞进 prompt 在成本与合规上都不现实。Bob 补充的视角更偏实现:窗口里的 token 序列在模型侧仍对应向量表示;用 Hugging Face Transformers 等栈对照 token→embedding 管线,有助于理解「窗口变大」并未消除检索前置的必要性——这是可复现的学习路径,不是 Box 产品规格。
与此同时,Box FY2026 10-K 披露:截至 2026 年 1 月 31 日,超过 10 万家付费组织(paying organizations);生成式 AI / Box AI、BYOM(bring your own model)为明确方向。Ben 在本场提到的 exabyte 级存储、数千亿至万亿对象、12 万+ 客户、数千万用户——在可访问的 10-K 中未出现 exabyte 或万亿级对象表述;迁移工具 Box Shuttle 仅描述 petabyte-scale 迁移能力。写作与选型时,宜把 SEC 数字与 CTO 口述规模分开标注。

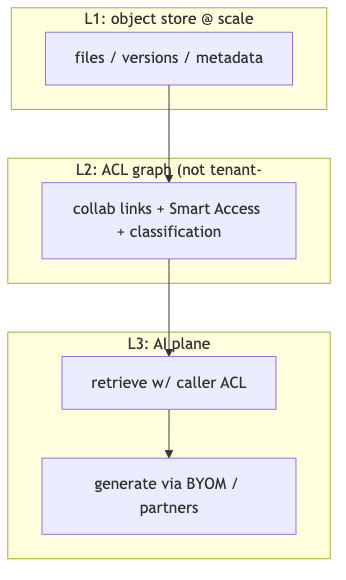
三层基础设施:存储、权限图、AI 不变量#
为什么#
非结构化内容平台的第一性约束不是 embedding 维度,而是 L1 吞吐与可靠性(百万级/秒交互量级、对象存储)、L2 协作权限(跨公司共享)、L3 AI(多模型、权限一致、快速接入新模型且不泄漏)。三者任一薄弱,上层 RAG 都会变成「能 demo、不能上线」。
机制与约束#
L2 的关键在跨租户:用户 A@客户甲分享给用户 B@客户乙时,不能简单用「按企业硬隔离 shard」解决可见性(演讲者观点)。10-K 描述 internal/external collaboration、Smart Access、共享链接与分类策略;OpenAPI 中 Hubs 按 requesting user 列出资源——与「全局多租户可见性图」的表述方向一致,但未以该术语出现在官方文档。
L3 的不变量:AI 回答不得越权。检索与生成只能使用调用者有权访问的内容;与 Azure OpenAI、Vertex AI、Claude、Bedrock 等集成时亦须保持(演讲者观点;与 Box API「不绕过 content permissions」原则一致,见 Box Developer Security)。安全文化上,Ben 强调权限与合规侧不能用「move fast and break things」——与创始人推动 AI 愿景形成张力,属组织层面取舍,非可单条引用的技术规格。
怎么做(最小示例)#
在应用层,把「用户身份 + 内容 ACL」作为检索的硬过滤器,再调向量或关键词:
# 伪代码:检索前绑定调用者可见 file_id 集合
visible_ids = box.acl.resolve_visible_files(user_id, hub_id=None)
candidates = hybrid_search(query, filter={"file_id": {"$in": visible_ids}})
常见误区#
- 把「租户 ID = 分片键」当成权限模型,忽略 B2B 外链协作。
- 在向量库侧只做 app 层过滤,却不同步 Box 权限变更事件,导致陈旧可见性。

a / 3 =x / } Weaviate(无架构幻灯,仅为访谈画面)。
RAG 与大上下文:对立命题各自成立的条件#
为什么#
企业 RAG 的收益被归纳为(演讲者观点):最新数据 + 权限过滤后的上下文 + 生成——而不是单纯扩大 token 窗口。这与行业对 RAG 的常规定义(检索增强生成)相容,但 Ben 的论证重点是 ACL + 动态库,属场景判断。
机制与约束#
Bob 将技术栈演进概括为:向量库 → RAG(embedding 做候选)→ Agent(生成结果可回写)(演讲者/产品方观点)。Ben 回忆 ChatGPT / GPT-3.5 API 达到「可生产」前后(约 2022 末–2023 初,宜与公开 API 时间线交叉核对)是企业认真投入内容的拐点;并主观认为早年惊艳的 GPT-3.5 Turbo 相对 GPT-4.1、Gemini 2.5、Claude 3.7 等在企业用例上已差距巨大——说明模型迭代本身是平台风险,而非一次性选型。
怎么做#
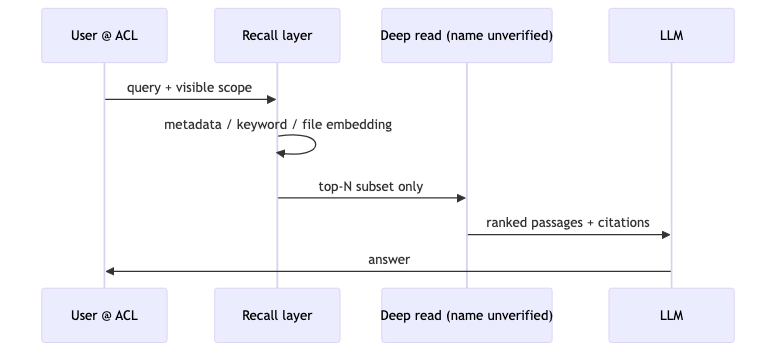
权限感知的 RAG 最小闭环:
query → (metadata/keyword/粗向量) recall@K
→ ACL filter
→ rerank / optional "deep" read
→ LLM w/ citations
常见误区#
- 把「128k/1M 窗口」当成可替代增量索引的方案,忽略日更文档与撤销授权。
- 不做引用粒度(文件 vs 段落),导致答案无法审计到具体 chunk。

tabs tH Wilts 等噪声及画面元素,无可读幻灯标题。

「找文件」与「找答案」:双粒度 embedding#
为什么#
企业搜索长期混淆两件事:定位哪份材料 vs 定位材料里的哪段。AI 时代必须拆开,否则 recall 不足或 embedding 数量爆炸(演讲者观点)。
机制与约束#
- 文件级:哪份 PPT、哪份计划书——适合导航式查询。
- 段落/页级:财报中的收入或风险段——适合问答式查询。
Connor(Weaviate)将 ColBERT(Khattab & Zaharia, SIGIR 2020)作为长 PDF 的参考路线:多向量 + late interaction,相对固定 500-token 粗分块更细——论文机制已核验;Ben 未声称 Box 已上线 ColBERT。Ben 对「一页五段是否只要五个向量」的回答是:视查询类型而定,非固定五(演讲者观点)。
ColBERT 核心(文档侧):查询与文档独立编码,通过 late interaction 做细粒度相似度,文档表示可预计算——适合长文档,但存储侧往往是多向量/文档,与下文成本节直接相关。
怎么做#
对同一 file_id 维护两级索引(概念示意):
{
"file_id": "f_123",
"file_vector": "[...]",
"chunks": [{"page": 3, "span": "...", "vector": "[...]"}]
}
查询路径:先 file_vector 或元数据缩小候选,再对子集做段落级向量或 ColBERT 式重排。
常见误区#
- 全库段落级预计算 embedding——Ben 称在 Box 规模下成本可达「数年客户付费总和」量级(演讲者观点,无公开账单)。
- 忽视「短段落 + 高维 float32」时,向量体积可超过原文(见下一节)。

Weaviate 角标;OCR 无完整 ColBERT 字样,不宜臆造幻灯术语。
Embedding 经济学与分层检索#
为什么#
Ben 的早期账单经验(演讲者观点):存储与快速检索 embedding 的开销可超过计算本身;在 exabyte 内容旁再挂 exabyte 级向量不现实。Bob 给出可复现估算:1500 维 × float32 ≈ 6000 bytes(约 5.86 KiB):
dims = 1500
bytes = 1500 × 4 # float32
# → 6000 bytes
短文本 chunk 若逐段全量索引,存储侧出现 10×–100× 于原文 并不罕见(演讲者观点;精确倍数取决于 chunk 大小、量化与是否多向量)。
Weaviate 侧,Bob 提到从「全内存」走向 disk-backed flat index、vector cache、超阈值转 HNSW 的 dynamic index(见 Weaviate Vector Indexing)。口语中的 「warm storage」在官方文档中无同名产品;正文宜写 flat index / disk-backed,避免写成已核验的产品名。
机制与约束#
Ben 描述的高层检索管线(演讲者观点;「Deep Search」未在 Box OpenAPI v2025.0 中命中,不得写成已公开 API):
- 缩小 recall:元数据、关键词、预计算 embedding(含文件级)等。
- 对小子集做更贵分析:称为 Deep Search 的 AI 重排/深读(命名未核验)。
- 必要时再算段落级 embedding;部分场景查询时计算优于全量预计算。
行业常见的 two-stage retrieval(cheap recall → expensive rerank)与上述叙事弱关联,但不能等同 Box 实现。
怎么做#
分层检索伪流程:
candidates = cheap_recall(query, top_k=500) # file-level + BM25
scored = deep_rerank(query, candidates[:50]) # 演讲者所称 Deep Search;实现各异
context = embed_on_demand(scored[:10]) # 按需段落向量
常见误区#
- 大客户要求「先把 30PB 全索引」——双方都应质疑;与「先 recall 再深算」相反(演讲者观点)。
- 只优化 embedding 计算 GPU,却忽视向量存储与索引账单。

We hs Oy Tas 等噪声及 Weaviate 角标。

Weaviate : == fC = A(无账单或维度幻灯)。
Agent、Workflow 与「复制粘贴税」#
为什么#
Workflow / RPA 适合步骤固定、单元能力弱的流程(演讲者观点)。Agent 在 Ben 的工作定义里(刻意不教条):目标驱动、有一定自主性、能代表用户执行多步——复杂度可分查询、变换、更重度的 transformational 等层级。Weaviate 产品侧的 query / transformation / personalization 三类 agent 是另一套产品分类,只能类比,不能划等号。
企业价值案例:RFP。RAG 把「10 人×小时」压到约 1 小时,但人工在 Hub 与问卷间 copy-paste 仍重;完整 Agent 链(检索→变换→Box Doc Gen 所述 2025 年 2 月 GA)才接近「团队替我干活」(演讲者观点;RFP 指标与端点未在 OpenAPI 核验)。
Hubs:OpenAPI 存在 GET /hubs,按 requesting user 列出 Hub,可作为跨文件 RAG 容器的技术锚点。Box × Weaviate agents 集成由 Bob 称已发布(访谈观点);宜以 Weaviate Agents 文档 与双方新闻稿为准补链。
机制与约束#
Box 平台叙事:理解内容(AI)+ 生成内容(doc gen);Agent 串检索、变换、写回文档。与纯聊天机器人的差别在副作用:写文件、填表、跨 Hub 编排——失败模式从「答错」扩展到「写错、泄露、越权写」。
怎么做#
RFP 类工作流(概念层):
Hub(历史标书) → retrieve Q&A pairs → draft answers
→ human review gate → doc_gen(新文档)
常见误区#
- 把单次 RAG 问答当成 Agent,忽略状态、工具调用与写回。
- Agent 上线后不保留人工审批门,在受监管行业不可接受。

"POUR eR 噪声与 Weaviate 角标。

weirs “iy ire 及 Weaviate。

云与模型:文档可核对部分 vs 口述#
| 主题 | 可核对(示例) | 访谈口径(未完全核验) |
|---|---|---|
| 托管 | 10-K:substantial majority 外包至 GCP,备选 alternative providers | 「100% hyperscaler 多云」 |
| AI 合作 | Azure OpenAI、Vertex AI、Claude、Amazon Titan(Bedrock)等 | 与权限不变量绑定(推断) |
| 客户规模 | >100,000 paying organizations(FY2025/2026) | 12 万+、数千万用户 |
| 存储规模 | Shuttle petabyte-scale 迁移 | exabyte 平台总存储 |
若你的架构决策依赖托管拓扑或精确规模,以 10-K 为准;播客提供的是超大规模内容平台上的工程权衡样本。

<> Awe 与 Weaviate;画面为访谈三分屏,非时间线图幻灯。
若你要落地#
- 先建 ACL 感知的 recall,再谈段落 embedding:文件级 + 元数据 + 关键词缩小候选;段落向量或 ColBERT 式多向量放在第二阶段,并算清
dims × sizeof(float)与索引开销。 - 把「RAG 已死」改写成场景命题:动态库 + 权限边界下,检索仍是硬需求;大窗口用于压缩多段证据,不替代可见性求解。
- 权限与审计一等公民:检索过滤、生成引用、写回操作同一
user_id;定期对账 ACL 变更。 - 产品命名与官方 API 对齐:勿把访谈中的 Deep Search、warm storage 直接写进对外设计文档;Weaviate 侧用 flat index / vector cache 等文档术语。
- Agent 从消除「复制粘贴税」的场景切入:Hub + 检索 + 人工门 + doc gen,比「全自动投标」更可交付。
参考与延伸阅读#
- Box FY2026 Form 10-K(截至 2026-01-31) — 付费组织数、GCP 托管、Box AI / Doc Gen、模型合作
- Box FY2025 Form 10-K — 同比口径对照
- Box OpenAPI v2025.0 — Hubs 等 REST 面
- Box Developer 文档入口 — 安全与集成指南
- Box Developer — Security 原则 — API 不绕过内容权限
- ColBERT 论文(arXiv 2004.12832) — 多向量 + late interaction
- Retrieval-Augmented Generation 综述(Lewis et al., 2020) — RAG 基线概念
- Weaviate — Vector Indexing 概念 — flat / HNSW / dynamic index
- Weaviate — vector-index 配置参考 —
vectorCacheMaxObjects等 - Weaviate Agents 介绍 — Agent 产品能力边界
- Hugging Face Transformers 文档 — token 与表示层学习路径
- Google Cloud — Vertex AI 文档 — 10-K 提到的合作方向之一
- Azure OpenAI 服务文档 — 企业模型托管选项
- Anthropic Claude 文档 — 第三方模型集成参照
- Amazon Bedrock 用户指南 — Titan 等模型接入
本文重组自 Box × Weaviate 技术对谈中的工程观点,并与 SEC 10-K、OpenAPI、ColBERT 论文及 Weaviate 官方文档交叉核对;冲突处以文档为准。播客画面为三分屏访谈,插图不含可引用的架构幻灯文本。


