
语音智能体时代的架构张力:SSM、低延迟 TTS 与「端到端」是否吃掉编排链#
当 RAG、长上下文窗口与推理模型(reasoning models)同时进入生产栈,语音场景却暴露出一组更硬的约束:多模态信号能否在 ingestion 阶段完整保留、尾延迟(P99)是否压得住用户心理锚点、以及 架构创新是否必须让位于数据飞轮。Cartesia 联合创始人 Karan Goel(State Space Models / Mamba 研究背景)在公开讨论中给出的路线,与「百万 token 已商品化」的行业叙事并不重合。
下文按 可文献核对的事实、厂商文档自述 与 演讲者观点 分层书写;凡本集未出现的 MOS、WER、行业占比数字,一律不补写。目标读者是已部署过向量库或语音栈的工程师——需要能直接对照自家 SLO 与架构选项,而非节目摘要。
问题空间:Compound AI 与语音栈的硬指标#
常见生产形态仍是 ASR → LLM → TTS 的级联(compound orchestration),配合向量检索或长上下文缓存。语音智能体(voice agent)在此基础上增加 电话/实时会话 维度:用户容忍的不仅是平均延迟,更是 P99 与 首包音频(time-to-first-audio)(演讲者观点;厂商文档侧有 WebSocket 低延迟示例)。
与此同时,「Agent」在语音产品里往往指 可接电话、可定制人格的语音实体,并不等价于带 tool loop 的自主 agent 定义(演讲者观点)。高敏感通话保留人工、其余由 AI 承接的 bifurcation,是嘉宾对客服赛道的判断,未见行业统计支撑。

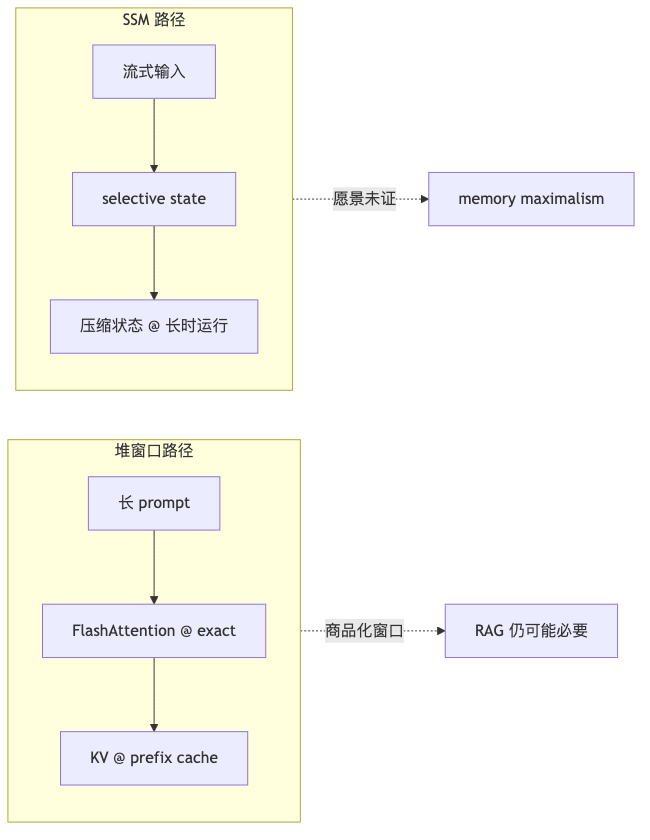
长上下文「堆窗口」与 SSM「压状态」:两条未收敛的路径#
为什么仍谈二次复杂度#
标准 Transformer 自注意力对序列长度的 per-layer 复杂度为 O(n²·d)(Vaswani et al., 2017);FlashAttention 摘要将时间与内存复杂度表述为对序列长度 quadratic,属于可核验结论。行业侧则用 Gemini 百万 token 上下文、Command R+ 128k 等证明 工程堆窗口 + exact attention 优化 已可商品化——这与「架构性突破才能做机器记忆」的立场形成张力。
机制与约束#
| 路径 | 核心机制 | 约束 |
|---|---|---|
| Exact attention 工程化 | FlashAttention 1–3 等 IO-aware 实现;Context caching 复用前缀 token | 复杂度仍为二次;窗口再大也有上限(演讲者观点) |
| SSM / Mamba 状态压缩 | 选择性状态空间;Mamba-2 SSD 声称线性 scaling | 长期推理、在线适应仍需「多次突破」(演讲者观点,无法核验路线图) |
嘉宾将 context caching 类比为 prompt 的 KV cache(Hugging Face KV cache 文档 可核对机制);Mamba 论文摘要给出相对 Transformer 的吞吐倍数,但 任务与硬件相关,不宜外推为全行业定律。嘉宾称 SSM 可在 NVIDIA GPU 上高效实现(Mamba README 要求 Linux + NVIDIA GPU);关于 AWS Trainium/Inferentia 原生 Mamba 的表述 未找到一手文档页,宜视为待补证据的市场判断。公司仍训练 Transformer 对照组以回答「哪种架构更对」(演讲者观点)。
怎么做(核对复杂度,而非站队)#
# 从 arXiv 源码核对 Self-Attention 复杂度表(P01)
curl -sL "https://arxiv.org/src/1706.03762v7" -o /tmp/attn.tar.gz
tar -xzf /tmp/attn.tar.gz -C /tmp/attn && grep 'O(n^2' /tmp/attn/why_self_attention.tex
常见误区#
- 把 窗口变大 等同于 范式改变——FlashAttention 解决的是 exact attention 的 wall-clock,不改变渐近阶(文献 + 演讲者观点)。
- 把嘉宾「近似 attention 通常不如 exact」 过度简化——论文批评的是部分近似方法在 wall-clock 上不占优,并非所有任务上近似都更差(核验报告边界)。
从 SSM 研究公司到先做 TTS:Sonic 与生产约束#
为什么音频成了「最简单」的 testbed#
Cartesia 源自 Stanford Chris Ré 组脉络;公司博客 Announcing Sonic(datePublished 2024-05-31)写明基于 state space models (SSM) 发布 Sonic,并自建 state space model inference stack。嘉宾口述首发约在 2024 年 6–7 月,与博客 相差约一个月(可能为 API 公测或记忆偏差,未核验)。
反直觉之处在于:公司因 SSM 与「近乎无限上下文」愿景成立,却先商业化 TTS——嘉宾解释为多模态长记忆的 音频 testbed,且 TTS 是音频子问题中最「简单」的一块(演讲者观点)。
机制:四目标拉扯#
文档与博客侧面支持的多目标包括(非独立 benchmark):
- 表现力(naturalness、emotion 等,见 Sonic 3.5 文档)
- 极低延迟(博客自称 model latency 135ms——厂商自述)
- 可控性(volume / speed / emotion;自然语言精确描述音频仍不成熟,演讲者观点)
- 发音可靠性(地址、电话号等;文档有 拼写/拆读指南,未核验嘉宾列举的全部实体类型)
本集 未给出 MOS、WER、RTF 分位数;博客中的 NISQA 分数 ≠ 标准 MOS。
怎么做(最小集成)#
# 伪代码:流式 TTS 关注首包与分位延迟,而非仅 mean
# 需在自家网络下实测 TTFA / P99(指标定义见厂商示例)
import cartesia # 以 docs.cartesia.ai 当前 SDK 为准
client = cartesia.Client(api_key="...")
for chunk in client.tts.bytes(model_id="sonic-3", transcript="...", stream=True):
play(chunk) # 记录 time_to_first_audio, p99_turn_latency
常见误区#
- 把 135ms model latency 直接当作 语音智能体 P99(嘉宾强调 P99,但未给毫秒数;指标定义可能不同)。
- 认为 TTS「只是读稿」——生产投诉往往集中在 罕见词、号码、专有名词(演讲者观点)。
级联栈 vs 端到端多模态:信号在何处断裂#
为什么级联仍占主流#
级联 能工作且相当 impress(演讲者原话方向)——Cartesia 同时提供 STT 与 TTS 也说明厂商覆盖组件化栈。主持熟悉 LangChain、DSPy、STORM 等 分解式推理链;嘉宾并不否定 search & planning(「ML 只有 learning + search」),但认为 tone、emotion、prosody 在 ASR 文本化后不可逆丢失,共情回应受限(演讲者观点;本集无消融实验)。
机制对比#
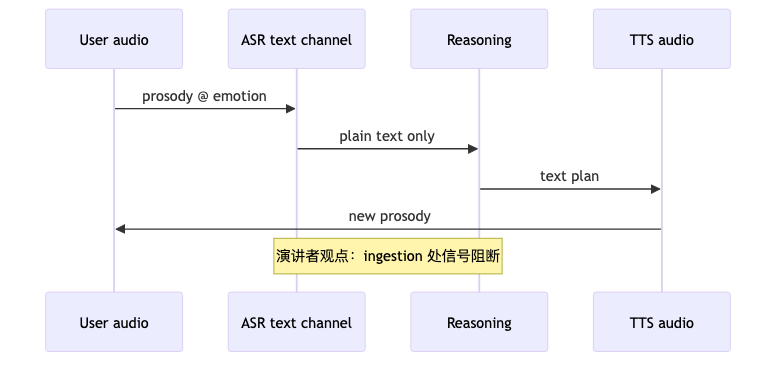
端到端愿景是 单一 API 背后 ingest + respond(多模态),语音交互「像人一样」(演讲者观点)。未决问题:端到端是否会 取代 编排链,还是 吸收 显式工具调用 / DB 搜索——嘉宾未给出产品路线图细节。
怎么做#
- 若坚持级联:在 ASR 侧保留 置信度、说话人、韵律特征 等元数据传入 LLM(工程补偿,不能等价于 原始波形)。
- 若评估端到端:用 同一剧本 对比「情感指令是否被遵守」,勿只用文本 BLEU/WER。
常见误区#
- 因级联「好用」就认定 永远不会被替代——嘉宾押注的是 模态损失 + 延迟锚点(用过极快系统后 4–5× 主观落差,演讲者观点,无量化研究引用)。
- 把 Vapi + Cartesia 集成(Vapi 文档 可核对)当作 端到端已成熟 的证据——仅为编排商集成 TTS。
RAG、Pull/Push 与「记忆极大主义」的自相矛盾#
为什么长上下文杀不死 RAG#
嘉宾自称 memory maximalist:理想是 一次 warmup 灌满上下文、不必 RAG;同时承认 just-in-time 信息仍必要(演讲者观点)——与「RAG 被长上下文杀死」的流行叙事相反。
主持侧引用 RETRO(检索 + 生成,参数量约为 GPT-3 的 1/25 而性能可比)与 Fusion-in-Decoder(检索 passage 注入解码器)。需注意:主持口述「8B ≈ 175B」无法在 FiD 摘要中找到;RETRO 摘要表述为与 GPT-3 / Jurassic-1 可比 且 25× fewer parameters,不宜写成逐字 8B/175B 对标(核验边界)。
Pull vs Push#
| 模式 | 行为 | 嘉宾倾向 |
|---|---|---|
| Push | 系统预塞 context / 检索结果 | 当前主流 RAG |
| Pull | 模型按需索取信息 | 更理想的交互(演讲者观点) |
主持希望 MCTS 式推理能 call the whole database;嘉宾对 embedding 注入中间层 无明确观点(自称非 RAG 专家)。这与 Weaviate 代表的 向量检索基础设施 形成互补而非替代关系——两套叙事可并存。
怎么做#
- 长文档:组合 Gemini context caching(或 vLLM prefix caching)+ 增量检索,勿假设「窗口够大就不用索引」。
- 评测:除 needle-in-haystack,增加 时效性事实 与 权限边界 case(本集未讨论基准)。
常见误区#
- 把嘉宾的 maximalism 当成 产品承诺——其后立刻承认不现实。
- 忽视 Pull 仍需要 检索接口与权限模型,只是调用方从编排器变成模型策略。
推理时钟、Test-Time Compute 与「投诉优于基准」#
机制#
更快 inference clock → 同等 wall-clock 内更多 reasoning reps / 搜索步(演讲者观点)。Let’s Verify Step by Step 支持对 intermediate reasoning step 做 process supervision,与「分步推理」方向一致,不等于 OpenAI o1 产品机制(o1 一手页本次未抓取,宜标为访谈推断)。
o1 类 讨论常落在:显式生成 token 再喂回 vs 隐式 latent 搜索——嘉宾对后者 不清楚(演讲者观点)。
数据飞轮与 many-shot#
嘉宾强调 生产投诉 优于抽象 eval(演讲者观点)。架构创新公司仍投数据;SSM 甚至 反过来决定 该收集何种数据(演讲者观点)。
Many-Shot In-Context Learning 显示数百示例可持续提升;嘉宾事先不知 many-shot 术语,但认同与 长序列、loop 内改进 相关——弱相关于嘉宾口中的 in-loop meta-learning(权重更新),勿混为一谈。
常见误区#
- 用公开 leaderboard 替代 认真用户的抱怨——适合早期信号,不能替代合规与偏见审计。
- 把 many-shot 当成 在线学习已实现——论文是 in-context,非持久权重更新。

若你要落地#
- 先定义延迟指标:在同一地区/网络下测 TTFA、P99 轮次延迟,区分厂商 model latency 与智能体端到端;勿直接引用 135ms 充当 SLO。
- 级联栈加元数据:ASR 输出附 confidence / 说话人 / 韵律摘要,缓解但 不能替代 端到端多模态实验(需自建情感剧本集)。
- 长上下文 + RAG 并联:静态知识用 prefix cache;动态事实用检索;为 Pull 预留工具 schema,即使当前模型不会主动调用。
- 评测分层:TTS 用 罕见实体发音表 + 用户投诉聚类;推理用 step-wise 校验;勿混 MOS 与 NISQA。
- 架构叙事保持假设清单:SSM 生产路径(Cartesia 博客)与 FlashAttention 长窗口 可共存——用业务指标选栈,而非论文立场选 religion。
参考与延伸阅读#
- Attention Is All You Need — Vaswani et al.
- FlashAttention — Dao et al.
- FlashAttention GitHub
- Mamba: Linear-Time Sequence Modeling — Gu & Dao
- Mamba-2 / State Space Duality — Dao & Gu
- Announcing Sonic — Cartesia 博客
- Cartesia 文档总览
- Sonic 3.5 模型说明
- Gemini 长上下文
- Gemini Context caching
- RETRO — Borgeaud et al.
- STORM — multi-perspective writing agent
- Many-Shot In-Context Learning
- Let’s Verify Step by Step — process supervision
- vLLM Automatic Prefix Caching 设计


