
Compound AI:当「一次 LLM 调用」不够用时#
生产里的 AI 应用很少停在 chat.completions 单轮调用上。Berkeley BAIR 对 Compound AI System 的定义把重点放在多个可交互组件——多次模型调用、检索器、外部工具、业务逻辑——共同完成一项任务;文中引用的企业调研还提到约 60% 的 LLM 应用含 RAG、约 30% 含多步链。与此同时,「Agent」产品形态、DSPy 式 workflow、o1 带动的逐步采样,都在争夺同一套工程预算。
Baseten 开发者关系负责人 Philip Kiely 在一场约一小时的访谈里,从结构化输出与推理栈讲到多模型编排与部署粒度,并反复把 compound AI 描述成「建系统的方式」,而非某个 SKU。下文按工程主题整理可落地的机制与边界;凡未在官方文档或论文中核对的数字,均标明来源。
问题空间:从 RAG 到 Agent,争的是同一条流水线#
常见做法:用向量库 + 生成模型做 RAG,或用带 function schema 的 ReAct 循环做 Agent;评测分别指向检索质量(MRR、nDCG)或开放任务(如 WebArena)。
另一种视角(演讲者观点):compound AI 是节点与边组成的图——模型、API wrapper、人工审核(HITL)、普通代码都是节点;「Agent」只是用这种图做出来的一种产品形态,与固定步骤的 workflow 并列,并不自动减少底层部署单元。
证据与边界:BAIR 文支持「多组件系统」框架,但未在术语层面区分 Agent / Workflow。主持人提到的 Alto(面向 compound 查询 的流式与并行编排)与 Agent Workflow Memory(用 workflow 轨迹做 in-context 学习)在公开摘要里与「分组件扩展」方向一致,但访谈未展开实现细节,正文不引用其具体指标。

结构化输出:约束解码 vs 事后清洗#
为什么#
多模型流水线里,上下游 schema 不一致会直接变成集成债务:ASR 文本格式、工具 JSON、向量库写回字段,任一环节输出非法结构都会触发重试、降级或静默丢数据。
机制与约束#
Outlines 将生成建模为有限状态机上的转移;arXiv:2307.09702 通过词表 index 与 allowed_tokens 在每一步屏蔽非法 token,文档称结构保证发生在 during generation 且 adds little overhead。outlines-core 的 Index::new 对应「由 schema/regex 编译一次、多次复用」。
演讲者观点:Baseten 在 model server 层集成 Outlines,稳态可达接近 100% schema 合法且 tokens/s 与无约束接近;首次为复杂 schema 编译 state machine 可能需 10–20+ 秒(更复杂则更久),适合 schema 固定的批量场景(如向量库 generative feedback loops),不适合每条请求动态换 schema。
部分可核对:论文支持 FSM 与低开销方向,不等于吞吐持平或 10–20s 冷启动——后者未见于公开 README,实施前需自测。
怎么做(minimal example)#
# 概念示意:固定 schema 时编译 Index,推理阶段逐步 mask
from outlines import models, generate
model = models.transformers("meta-llama/Llama-3.2-3B-Instruct")
generator = generate.json(model, YourPydanticModel) # 编译一次
out = generator("Extract entities from: ...") # 多次复用
备选路径:自然语言生成 → 第二次 LLM 清洗;或 OPRO 类 prompt 搜索。主持人认为 constrained generation「在赢」;演讲者观点提醒可能影响 reasoning 等能力,需 A/B。
常见误区#
- 把「解析失败再 prompt 一次」当成免费重试——延迟与成本会线性叠加。
- 在每条请求不同 schema 的场景硬上编译缓存,冷启动会主导 P99。
- 忽视 DSPy Assertions 一类运行时约束(文档注明 Assert 已 deprecated,宜转向
Refine/Suggest)与解码约束的分工:前者偏程序语义,后者偏 token 级保证。
语音与多模态:专家模型链 vs 单一「全能模型」#
为什么#
GPT-4o 类内置多模态把 ASR、推理、TTS 收进一个接口,部署故事简单;但在实时语音、区域延迟敏感的场景,流水线 specialist 仍常见。
机制与约束#
Whisper 的 transcribe() 使用 sliding 30-second window(文档支持,verified)。长音频必须分块、并行转写、再拼接——这是模型/产品边界,不是可选优化。
README 模型表列 turbo 相对 large 约 ~8× 速度,脚注写明在 A100 上测英语转写,real-world speed may vary。演讲者观点将其表述为 real-time factor 并提及 T4/A10/L4——GPU 清单与 RTF 口径未在 README 中给出,写作时应写「相对 large 的 README 相对速度」,勿直接等同 RTF。
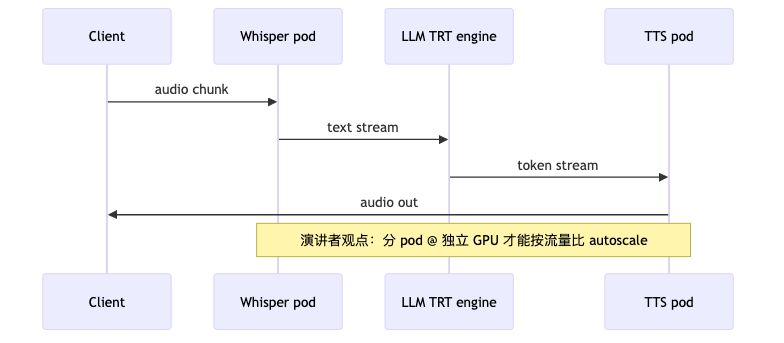
典型链:Whisper → 流式 LLM → TTS(Piper、Coqui、Rime 等)。演讲者观点:同区域部署、避免公网 hairpin、DNS/集群内路由,可把端到端压在亚秒级;编排不当则轻易到 3–4 秒。
怎么做#
音频流 → chunk@30s → Whisper Turbo (并行) → 拼接文本 → LLM (stream) → TTS → 音频流
↑ 同 VPC / 同 AZ,避免跨区回环
常见误区#
- 假设「一个 Realtime API」一定比三模型链贵或慢——取决于流量形态、区域与是否愿意投入编排。
- 忽视 ColPali 一类「向量库直接检索 PDF 图像」与「图→文本再 RAG」的路线分歧;访谈未给出定量对比,属工程选择。

推理栈:prefill/decode、MoE、TensorRT-LLM 与 Truss#
为什么#
Compound 系统的瓶颈往往在最慢节点的 GPU 利用率,而不是 API 层 QPS。
机制与约束#
Prefill vs decode(部分 verified):NVIDIA 推理优化文 将 prefill 描述为可饱和 GPU 利用的并行阶段,decode 为 memory-bound、受 HBM 带宽主导。演讲者观点进一步把 prefill 归为 compute(FLOPs)主导——比官方表述更细,长 context 时两者可能同时吃紧。
MoE(部分 verified):Switch Transformers 强调每样本 sparsely-activated。演讲者观点:batch 推理时不同请求可能激活不同 expert 子集,batch 内往往趋向激活全部 expert,MoE 相对 dense 的带宽优势会缩水——属工程归纳,缺论文逐字定理。
TensorRT-LLM(部分 verified):Core Concepts 说明通过 build_engine 编译,TensorRT 会为 available GPU 选择 kernel;in-flight batching 即 continuous / iteration-level batching。演讲者观点:Baseten 内测部分场景优于 vLLM——无公开表格,不可当作通用结论。换 GPU 通常应 rebuild engine(强推断,文档未写死一句 “must rebuild”)。
Truss(演讲者观点):Truss 用 Python + YAML 打包模型服务,对标 Ray Serve、BentoML;Philip 自述非 Docker 专家,靠 Truss 降低 serving 门槛。快速原型仍可用 vLLM 搭 OpenAI-compatible 端点。
怎么做#
# truss 极简示意(结构因版本而异)
model_name: my-llama
python_version: py311
resources:
accelerator: A10G
常见误区#
- 在 batch 流量下按 MoE「单请求稀疏」估算成本。
- 未为 TensorRT engine 规划 GPU 型号锁定 的 CI/CD。
- 把 Agent「一个入口」等同于「一个 autoscaler」——见下一节。


Agent、工具调用与评测:图相同,产品不同#
为什么#
WebArena 类 benchmark 奖励开放循环(「任务完成了吗?」);固定五步写博客流水线则更像 workflow,可显式并行,类似写 forward pass(主持人归纳)。
机制与约束#
Function calling 下沉:Llama 3.2 MODEL_CARD 给出 BFCL V2 Tool Use:1B acc 25.7、3B acc 67.0(bf16 行),3B 接近 Llama 3.1 8B 的 67.1。表头为 Tool Use 而非 exact 短语 “function calling”,正文宜写 BFCL 工具调用能力。
工具选择与执行分离(演讲者观点):倾向 function selection——LLM 只选工具与填参,执行在 compound 图外层。主持人补充 Gorilla 与 GraphQL/text-to-SQL 场景下参数格式化仍是难点。
搜索式 ensemble:主持人问 o1 式「每步采样 N 次再集成」是否成主流;演讲者观点野外更常见的是多模型拼多模态,而非大规模 repeat inference ensemble。
Meta Agent Search:Automated Design of Agentic Systems 用搜索发现 agent 设计;演讲者观点客户项目多为能力驱动(加长音频、加模态),架构常由模型能力边界倒推,再对弱项加校验步骤,而非先搜索拓扑。
怎么做#
对固定流程:用显式 DAG + 无依赖步骤并行;有依赖或超长步骤再用队列 + async/webhook(Baseten async inference)。Weaviate generative feedback loops(对集合批量跑 LLM 写回属性)适合 schema 固定 + 批量;与 Philip 强调的「无依赖子任务不要串行队列」一致。
常见误区#
- 用 WebArena 分数指导确定性流水线的产品决策。
- 以为单个 Agent 服务能减少 Whisper / LLM / TTS 的独立 endpoint 数量(演讲者观点:仍须分别部署与扩缩,例如 2× Whisper + 3× Llama + 1× TTS)。
- 把模型弱项(拼写、计数、数学)全塞回微调;BAIR 强调 system design 常比单纯 scale 更快迭代,演讲者观点 外围 regex/检索/算术代码往往更省。

可靠性:校验、队列与人在回路#
为什么#
Compound 系统的失败往往是级联:检索漏了、JSON 歪了、工具超时了,最终都表现为「模型胡说」。
机制与约束#
外围校验(部分 verified):BAIR 列举 filtering outputs、verify facts 等控制手段。DSPy 的 Assert/Suggest 在失败时可 backtrack(Assert 已 deprecated)。
演讲者观点:若目标是 100% 格式合规,有时 regex 包裹 比继续堆 RL 更省;「verifying is easier」在访谈中为口头概括,未定位到单一论文标题。
队列 vs 并行:有依赖 → task queue + webhook;无依赖 → 并行。HITL 可接 Slack + HumanLayer 等(主持人举例)。
常见误区#
- 把所有步骤塞进 FIFO 队列「求稳」,拖慢可并行的段落。
- 只做生成端约束,不做业务事实校验(RAG 仍须 citation / 二次检索验证)。
未收敛的分歧(刻意并存)#
| 主题 | 常见实践 | 访谈中的另一强调 | 你怎么选 |
|---|---|---|---|
| 系统 vs 产品 | 买一个 Agent 平台 | Compound 是构图方式;Agent 是产物之一 | 先画数据流与 SLA,再贴标签 |
| 多模态 | 单一 frontier 多模态 API | 同区域 specialist 链 | 量延迟方差与$/分钟 |
| 输出约束 | Instructor / 二次 LLM | Outlines 类解码约束 | schema 是否固定、能否摊销编译 |
| 部署 | 单 K8s Deployment | 每模型独立 GPU 与 autoscaler | 看流量比是否随时间漂移 |
| 弱项 | 继续 SFT / RLHF | 外围代码与 regex | 失败是否可形式化 |
若你要落地#
- 先画 compound 图:标出每个节点的输入/输出 schema、超时、重试策略;再决定叫 Agent 还是 workflow。
- 固定 schema 的批量写回(向量库 generative、ETL):评估 Outlines 或同类 constrained generation,并为 schema 编译做冷启动预算(自测 P99,勿照搬 10–20s)。
- 语音/多模态:按 Whisper 30s 窗口 设计分块;README 的 turbo ~8× 仅作相对 large、A100 的参考,上线前在你的 GPU 与语种上复测。
- 推理:原型用 vLLM;极致吞吐再评估 TensorRT-LLM engine + in-flight batching,并把 GPU 型号 锁进构建流水线。
- 扩缩:按节点流量比配置独立副本(Whisper vs LLM vs TTS),避免 monolith autoscaler;无依赖步骤默认并行,队列只保护有状态或顺序敏感的边。
参考与延伸阅读#
- BAIR — Compound AI Systems(定义与 RAG/多步链统计)
- arXiv:2307.09702 — Efficient Guided Generation for LLMs(Outlines 论文)
- Outlines — 生成期结构保证
- outlines-core — Index 与 FSA API
- OpenAI Whisper — 30 秒滑动窗口与 turbo 速度表
- NVIDIA — LLM Inference Optimization(prefill/decode)
- TensorRT-LLM — Core Concepts
- TensorRT-LLM — In-flight Batching
- vLLM 项目
- Baseten Truss — 模型打包与部署
- Llama 3.2 MODEL_CARD — BFCL V2 Tool Use
- arXiv:2307.13854 — WebArena
- arXiv:2305.15334 — Gorilla
- arXiv:2403.04311 — Alto
- arXiv:2408.08435 — Automated Design of Agentic Systems


